
By Ali Haydar
Over the past few years, serverless architecture has become very popular. This is largely because it has removed the burden of managing infrastructure, such as servers, storage, databases, scalability, and so on.
When people first started using the term "serverless," it created some confusion in the industry. Some people jokingly wondered how they could run apps without servers.
Well, the servers still exist, but their management and operation are handled on your behalf by the cloud provider.
Using serverless architecture enables organisations and engineers to focus on what's important – building great, performant, and cost-effective applications that stand out in the market.
How Do You Test Serverless Architecture?
While serverless introduced a lot of simplicity into the process of building and shipping software, some challenges can come into play around testing.
First of all, testing locally is complex because serverless apps are dependent on cloud services. This is true for both unit and integration tests, where you need mocking and stubbing services to make sure that the application is working correctly.
Even though this might be a bit of additional work, it provides a better way to test in isolation, and your pipelines will start failing because of issues in your code, not the dependencies.
Second, integration tests are more diffiuclt and important as there are multiple services/components integrated together. This increases the risk of creating configuration/setup bugs in addtion to the potential existing code defects.
So what are we supposed to test? How do we test our app on both the unit and integration levels?
How can we make sure our app will work properly in a live environment, given that we've mocked other services while developing on our local?
And how can we test the interaction with the cloud services (AWS services in this case) without having to test the service itself?
This article aims to answer these questions to help you effectively test your serverless apps. So let's get started.
What are we building?
AWS offers a set of serverless services (services that run in the cloud, on hardware and systems that we do not manage). This post will cover a few of them:
- Lambda (Cloud Function)
- API Gateway
- DynamoDB
As this post focuses mainly on testing serverless applications, we will use an app that I previously developed as an example. This app returns a list of fake publicly listed companies.
The architecture will look like this:

Feel free to have a look at the demo application running in AWS (please excuse the UI design).
The app has a front end that makes restful API calls to the backend. These calls go through the API Gateway to the Lambda, which queries the DynamoDB for publicly listed companies and returns the result.
All the backend code lives under the api folder. We will start looking at each component in isolation, and then we will test the integration. To get started, clone the repository here.
Let's test the app.
Unit Testing the App
As I mentioned earlier, we have three components on our backend: DynamoDB, Lambda, and API Gateway. In this section, we will cover how to unit test these components.
How to Run Unit Tests on DynamoDB
The infrastructure code to build the DynamoDB looks like this:
Resources:
CompaniesTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: companies
AttributeDefinitions:
- AttributeName: CompanyId
AttributeType: S
- AttributeName: CompanyType
AttributeType: S
KeySchema:
- AttributeName: CompanyId
KeyType: HASH
- AttributeName: CompanyType
KeyType: RANGE
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
Tags:
- Key: author
Value: ali
CompaniesTableReadOnlyAccessPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
Description: Policy for Read only companies table
ManagedPolicyName: companies-readonly-access
Path: /
PolicyDocument:
Version: 2012-10-17
Statement:
- Sid: CompaniesReadOnlyAccess
Effect: Allow
Action:
- 'dynamodb:Scan'
- 'dynamodb:GetItem'
- 'dynamodb:Query'
Resource:
- !GetAtt CompaniesTable.Arn
By navigating to AWS CloudFormation and uploading the template, we will provision a DynamoDB table, mainly with "CompanyId" and "CompanyType" fields which form a primary key. We'll also have an IAM policy that allows us to access the table.
So is there anything to test here?
The DynamoDB schema is mainly defined based on access patterns. This is how we create the primary key, decide on the hash key and the sort key, and so on.
For example, if a field (or combination of fields) is not a primary key, we won't get the record unless we define a secondary index on that field. So we should pay attention to our business use cases when we test the setup of the Dynamo DB.
Keep in mind that we are not testing the functioning of DynamoDB itself here (AWS has done an excellent job there). Rather, we are testing how we interact with it.
It is possible to navigate to AWS, add some items, then make sure they're visible and filterable on the AWS console. Is that enough? This accessibility pattern will happen programmatically. In real life, the Lambda function (next section) will try to access the database.
I usually write a small bash script that gets executed after provisioning the table and checks whether the access patterns are working correctly. For example:
#!/bin/bash
# Insert a record into the dynamoDB table
aws dynamodb put-item \
--table-name companies \
--item '{
"CompanyId": { "S": "COMPANY#4" },
"CompanyType": { "S": "PRIVATE" },
"Details": { "M": {
"name": { "S": "Awesome Company" },
"revenue": { "S": "1000000" }
} }
}' \
--return-consumed-capacity TOTAL \
--return-item-collection-metrics SIZE
# Query the added record from the table
RESULT=$(
aws dynamodb get-item \
--table-name companies \
--key file://key.json \
--return-consumed-capacity TOTAL
)
echo $RESULT
### OUTPUT ###
# {
# "Item": {
# "Details": {
# "M": { "name": { "S": "Kousa" }, "revenue": { "S": "1000000" } }
# },
# "CompanyType": { "S": "PRIVATE" },
# "CompanyId": { "S": "COMPANY#4" }
# },
# "ConsumedCapacity": { "CapacityUnits": 0.5, "TableName": "companies" }
# }
# parse the name and verify it's correct
NAME=$(jq -r '.Item.Details.M.name.S' <<< "$RESULT")
echo $NAME
if [ "$NAME" = "Awesome Company" ]; then
echo 'The item was retrieved correctly.'
exit 0
else
echo 'Something went wrong. Double-check the schema or the query.'
exit 1
fi
# Delete the added item
aws dynamodb delete-item \
--table-name companies \
--key file://key.json
There is some additional work, though, on top of writing the bash script, including the following:
- When should we execute the script?
- Will it be executed against a test DB as well? Is it risky?
- What if the database is already being used (for example, we've added an index to the table)?
- The execution of this script relies on having AWS credentials fed as environment variables – probably they're already part of the CI/CD pipelines
- Has this covered the testing of the IAM policy that allows access to the table?
Is writing this kind of test valuable? It's something to consider on a case-by-case basis. Mostly, we need to weigh the benefits of automating the testing of the infrastructure configuration vs the time we spend on developing and maintaining these tests.
For example, suppose we use this table for multiple purposes across multiple teams. In that case, it might be worth having the table infrastructure code and tests live in a separate repository, where we execute the tests before any changes to the table are deployed to production.
We don't want to break any functionality that might be dependent on this table. To not cause interruptions in the test environment or damage the table data because of new changes, we can provision a temp table with the changes in AWS, run our tests, and only update the test database if these tests pass.
To summarise all this, our CI/CD pipeline does the following:
- Provision a new temp table on the AWS test environment (without touching the real test DB)
- Run the bash tests on the temp table
- On Success, delete the temp table and update the actual test table
- On Failure, delete the temp table and stop further changes
How to Run Unit Tests on Lambda
Looking at the original code, it doesn't appear ideal as it includes all of the logic within the handler of the Lambda (that's a big function doing multiple things):
const { DynamoDB } = require('@aws-sdk/client-dynamodb'); // importing library from aws-sdk that allows the interaction with dynamodb
const { unmarshall } = require('@aws-sdk/util-dynamodb'); // importing unmarshall function, which converts a DynamoDB record into a JavaScript object
exports.lambdaHandler = async (event, context) => {
try {
console.log('here is the event received', event);
const dynamodb = new DynamoDB({ region: 'us-east-1' }); // creating a new instance of DynamoDB
const params = {
TableName: 'companies',
};
// if no query parameter was passed to the function, then update the dynamodb params to query all companies
if (!event.queryStringParameters) {
params.ExpressionAttributeValues = {
':companyType': {
S: 'PUBLIC',
},
};
params.FilterExpression = 'CompanyType = :companyType';
}
// if the companyId query paramater was passed, then update the dynamodb params to filter according that company exactly
else {
params.ExpressionAttributeValues = {
':companyId': {
S: `COMPANY#${event.queryStringParameters.companyId}`,
},
};
params.FilterExpression = 'CompanyId = :companyId';
}
const results = await dynamodb.scan(params); // get the results from dynamodb according to the previously set params
console.log('results', results);
let unmarshalledResults = [];
// unmarshall every record returned (convert it into a JS object)
for (const item of results.Items) {
const unmarshalledRecord = unmarshall(item);
unmarshalledResults.push(unmarshalledRecord);
}
console.log('unmarshalled results', unmarshalledResults);
return {
statusCode: 200,
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
},
body: JSON.stringify(unmarshalledResults),
};
} catch (e) {
console.error('something went wrong', e);
return {
statusCode: 500,
body: 'Something has gone wrong, please contact the support team',
};
}
};
Note that using the scan operation on DynamoDb requires careful thought in a production environment, as it operates on the entire table. This might cause performance issues or consume the read capacity that is reserved for the table.
So what is this code doing?
It would be good to separate the concerns for better testability, so we'll create a new function that handles the interaction with DynamoDb and gets the lambda handler to call it as needed.
So we take out the piece that queries DynamoDB and converts the results to a JS object. The new file and function look as follows:
const { DynamoDB } = require('@aws-sdk/client-dynamodb');
const { unmarshall } = require('@aws-sdk/util-dynamodb');
const dynamodb = new DynamoDB({ region: 'us-east-1' });
const scanAndFilterData = async (params) => {
const results = await dynamodb.scan(params);
console.log('results', results);
let unmarshalledResults = [];
for (const item of results.Items) {
const unmarshalledRecord = unmarshall(item);
unmarshalledResults.push(unmarshalledRecord);
}
console.log('unmarshalled results', unmarshalledResults);
return unmarshalledResults;
}
module.exports = { scanAndFilterData }
The Lambda handler will only handle receiving the event and passing it through to the function that interacts with the database.
How to Unit Test the Code
Unit testing the scanAndFilterData function requires mocking the @aws-sdk libraries we're using. Otherwise, we will also be covering the libraries themselves in our tests, and we do not want that.
In addition, this might add some complexity around accessing the DynamoDB table, which will happen automatically by the library (for example, we would need to handle credentials as part of the tests). So we either have to stub the DynamoDb or mock the functions that interact with it.
const { scanAndFilterData } = require('../dynamoDbData');
jest.mock('@aws-sdk/client-dynamodb', () => {
return {
DynamoDB: jest.fn().mockReturnValue({scan: jest.fn().mockReturnValue({Items: ['item1', 'item2']})})
}
})
jest.mock('@aws-sdk/util-dynamodb', () => {
return {
unmarshall: jest.fn().mockReturnValue('test')
}
})
describe('scanAndFilterData', () => {
it('should scan the dynamoDB table and unmarchall the returned records', async () => {
const mockedDynamoDBInstance = require('@aws-sdk/client-dynamodb').DynamoDB;
const params = 'test'
const result = await scanAndFilterData(params);
expect(mockedDynamoDBInstance.mock.results[0].value.scan).toHaveBeenCalledWith(params);
const mockedUnmarshall = require('@aws-sdk/util-dynamodb').unmarshall;
expect(mockedUnmarshall).toHaveBeenNthCalledWith(1, 'item1');
expect(mockedUnmarshall).toHaveBeenNthCalledWith(2, 'item2');
expect(result).toEqual(['test','test']);
})
})
Side note: notice that we are testing the code instead of the behaviour. It took me a while to change my mindset and see it this way when I started writing unit tests.
This is different from E2E tests, which are usually more about behaviour. Basically, we look at every line of code and verify in our tests that it's written correctly (for example, a function has been called).
But we can still mix both code and behaviour tests. We can decide the style of tests on a case by case basis – I often tend to test the code when it has dependencies and test the behaviour when the function is pure.
Similar to how we tested the scanAnFilterData function, we shall test the lambda handler function. The tests would look like this (note that the tests are not complete but enough to get the idea across):
const { lambdaHandler } = require("../app");
jest.mock('../dynamoDbData', () => {
return {
scanAndFilterData: jest.fn()
};
})
describe('lambda handler', () => {
it('should only filter by compay type and return the result accordingly', async ()=> {
const event = {}
const result = await lambdaHandler(event);
const mockedScanAndFilterData = require('../dynamoDbData').scanAndFilterData
expect(mockedScanAndFilterData).toHaveBeenCalledWith({"ExpressionAttributeValues": {":companyType": {"S": "PUBLIC"}}, "FilterExpression": "CompanyType = :companyType", "TableName": "companies"});
})
it('should filter by passed company ID and return the result accordingly', async ()=> {
const event = {queryStringParameters: {companyId: '1'}};
const result = await lambdaHandler(event);
const mockedScanAndFilterData = require('../dynamoDbData').scanAndFilterData
expect(mockedScanAndFilterData).toHaveBeenCalledWith({"ExpressionAttributeValues": {":companyId": {"S": "COMPANY#1"}}, "FilterExpression": "CompanyId = :companyId", "TableName": "companies"});
})
})
How to Run Integration Tests on the App
We have skipped testing the API Gateway component in isolation, as we will cover it in the integration tests.
We'll split the integration tests into two parts: Full flow testing and Lambda integration testing.
Full flow testing
Full flow testing is API testing that covers the API Gateway, the Lambda, and the DynamoDB table.
We can use any tool(s) to perform these tests (like Postman, a combination of Mocha/Chai/Cucumber, and so on). Below are a few scenarios:
- Get all public companies:

- Get the details of a single public company:
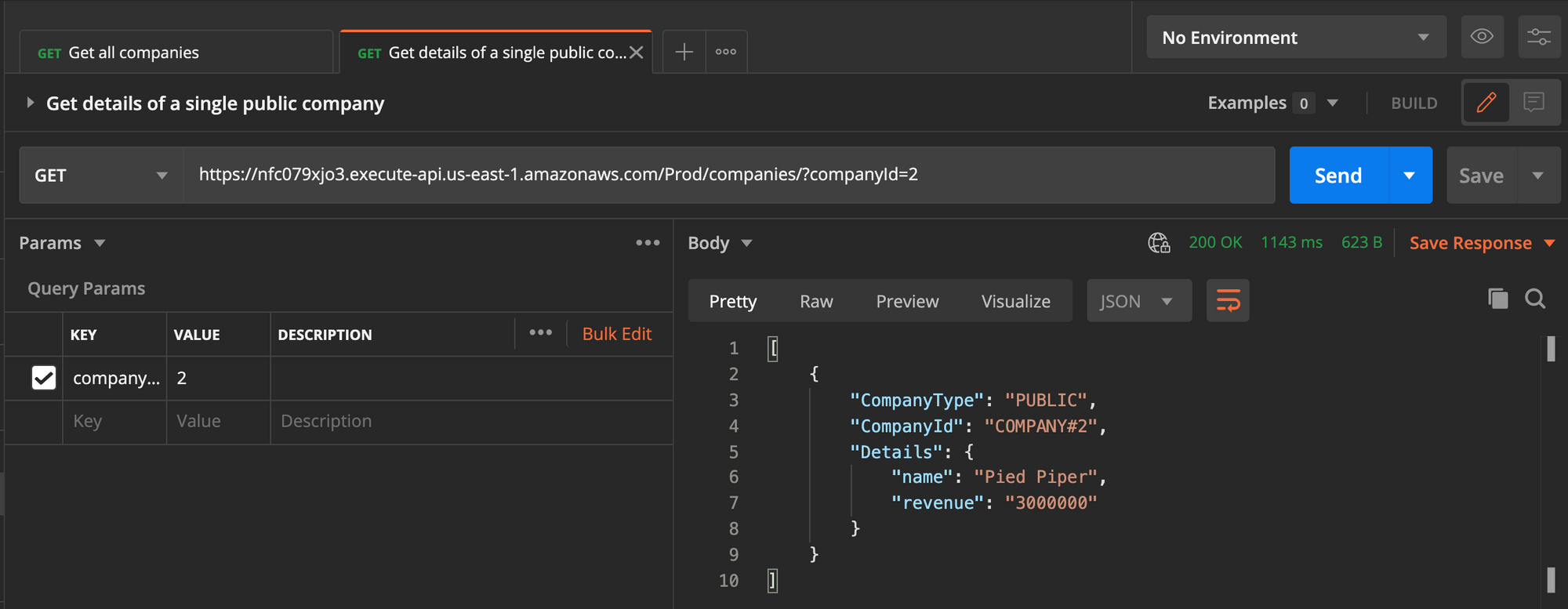
- Get the details of a single private company:
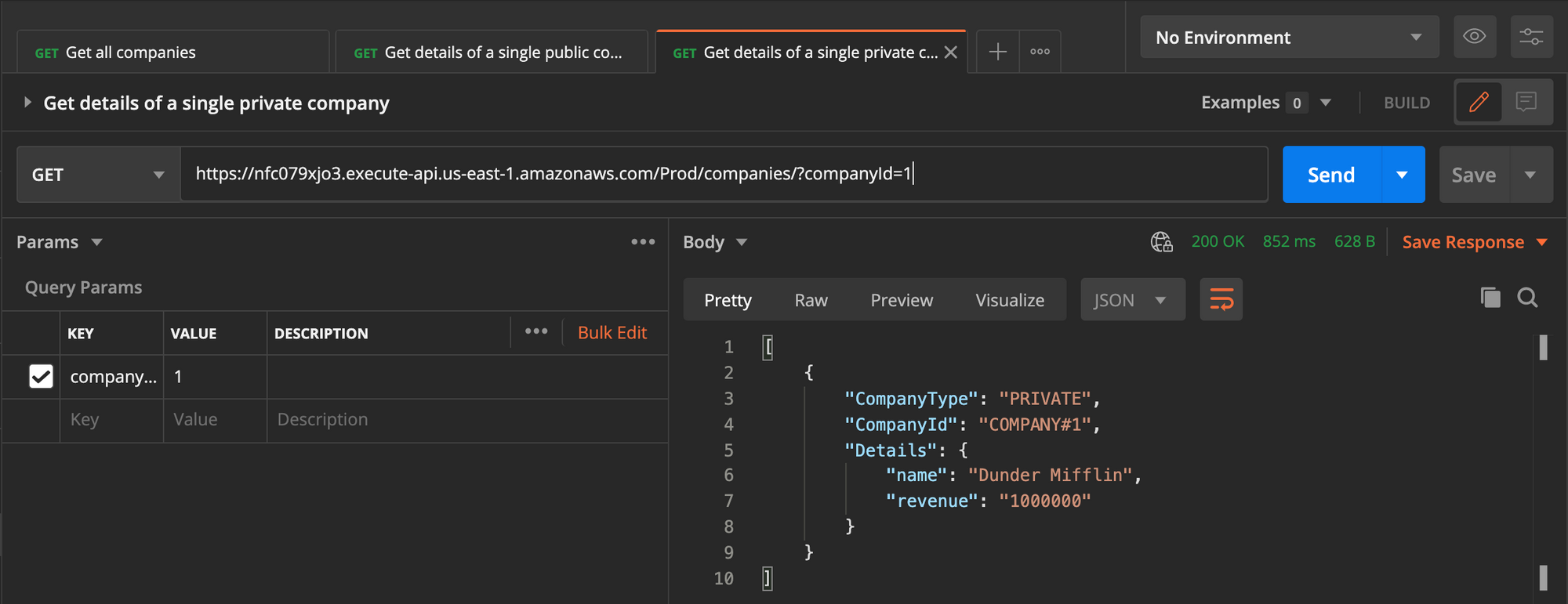
The last scenario shows a security bug, where the user can get the info of a private company by selecting a random ID in the path parameter of the request.
Personal opinion – I would rather have the API tests built as part of the code rather than using external tools such as Postman.
Postman provides excellent utility for API testing. But managing the collections and requests outside of the same repository or version control isn't convenient for collaboration across a team and wouldn't encourage developers to write this kind of test.
To execute these tests, we need to have an environment that's properly configured and includes the necessary data. Different teams would use a variety of approaches to create the data:
- Have the data always available in the environment, assuming we're just retrieving data.
- Have an API that creates the data and another one that deletes the data. We could rely on these APIs to prepare and clean up the data as part of our tests. That's my preferred approach as it removes any reliance or assumption on existing environments and data.
I look at this set of tests as E2E tests, as they cover functionality and hide any internal integration between the three components in our project.
Some people would disagree, as this does not cover the frontend of the app we're testing, which is a good point.
Still, another approach is to add some UI tests in isolation, some contract tests, and combine them with these API tests to cover the entire system's functionality.
Lambda Integration Testing
This section will address the Lambda deployment and how we can control the traffic to reach a safer deployment. This comes hand in hand with testing the integration of the Lambda with other services (that's DynamoDB in this case).
We'll be looking into traffic shifting using the "CodeDeploy" service, relying on the lambda "Before Traffic" and "After Traffic" hooks.
These traffic hooks are separate lambda functions that run sanity checks before and after, shifting traffic to the new version of the Lambda we've implemented. This will help avoid any downtime and interruption after deployment.
The hooks allow us to decide whether the deployment should pass or fail. Pre-traffic hooks enable us to test the newly deployed Lambda before it's been used (before any traffic shifting). A snippet of code looks like this:
exports.handler = (event, context, callback) => {
const deploymentId = event.DeploymentId;
const lifecycleEventHookExecutionId = event.LifecycleEventHookExecutionId;
const functionToTest = process.env.NewVersion;
// Create parameters to pass to the updated Lambda function that
// include the newly added "time" option. If the function did not
// update, then the "time" option is invalid and function returns
// a statusCode of 400 indicating it failed.
const lambdaParams = {
FunctionName: functionToTest,
InvocationType: "RequestResponse",
};
const lambdaResult = "Failed";
lambda.invoke(lambdaParams, function (err, data) {
if (err) {
console.log(err, err.stack);
lambdaResult = "Failed";
} else {
const result = JSON.parse(data.Payload);
if (result.statusCode != "400") {
console.log("Validation succeeded");
lambdaResult = "Succeeded";
} else {
console.log("Validation failed");
}
var params = {
deploymentId: deploymentId,
lifecycleEventHookExecutionId: lifecycleEventHookExecutionId,
status: lambdaResult, // status can be 'Succeeded' or 'Failed'
};
codedeploy.putLifecycleEventHookExecutionStatus(
params,
function (err, data) {
if (err) {
console.log("CodeDeploy Status update failed");
console.log(err, err.stack);
callback("CodeDeploy Status update failed");
} else {
console.log("CodeDeploy status updated successfully");
callback(null, "CodeDeploy status updated successfully");
}
}
);
}
});
};
In this code, we invoked the main function and updated the status to Failed if the status code is different from 400. This is just an example – we could do any checks in this case, like validating the response returned from the database, and so on.
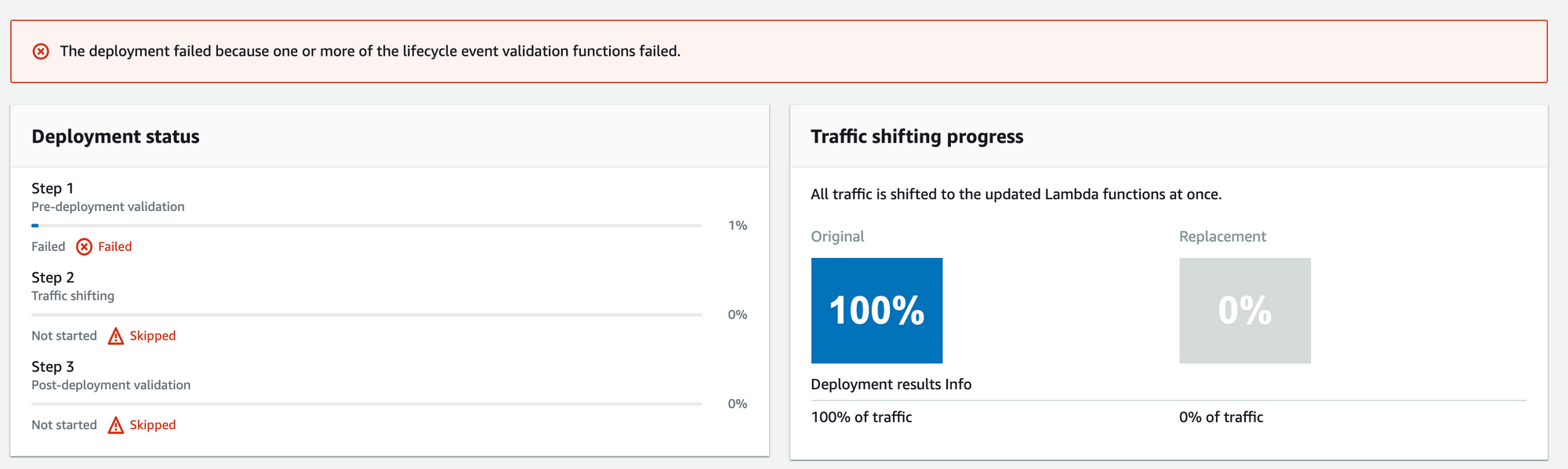
Once we get the response we need (or not), we notify CodeDeploy to update the status using codedeploy.putLifecycleEventHookExecutionStatus. If the status is a failure, then "Code Deploy" stops any future traffic shifting and keeps the original Lambda:
Similarly, in the "After Traffic" hook, we can do the necessary checks after the traffic is redirected to the new version. I usually use the After Traffic hooks to test the API using a library such as axios, which is very similar to what we tested in Postman. The code looks like this:
exports.handler = (event, context, callback) => {
const deploymentId = event.DeploymentId;
const lifecycleEventHookExecutionId = event.LifecycleEventHookExecutionId;
let lambdaResult = "Failed";
axios
.get(
"https://nfc079xjo3.execute-api.us-east-1.amazonaws.com/Prod/companies"
)
.then(function (response) {
if (response.data.length == 2) {
lambdaResult = "Succeeded";
}
})
.catch(function (error) {
console.log("An error occured", error);
})
.then(function () {
const params = {
deploymentId: deploymentId,
lifecycleEventHookExecutionId: lifecycleEventHookExecutionId,
status: lambdaResult, // status can be 'Succeeded' or 'Failed'
};
codedeploy.putLifecycleEventHookExecutionStatus(
params,
function (err, data) {
if (err) {
// Validation failed.
console.log("AfterAllowTestTraffic validation tests failed");
console.log(err, err.stack);
callback("CodeDeploy Status update failed");
} else {
// Validation succeeded.
console.log("AfterAllowTestTraffic validation tests succeeded");
callback(null, "AfterAllowTestTraffic validation tests succeeded");
}
}
);
});
};
Will this be enough to replace the API tests?
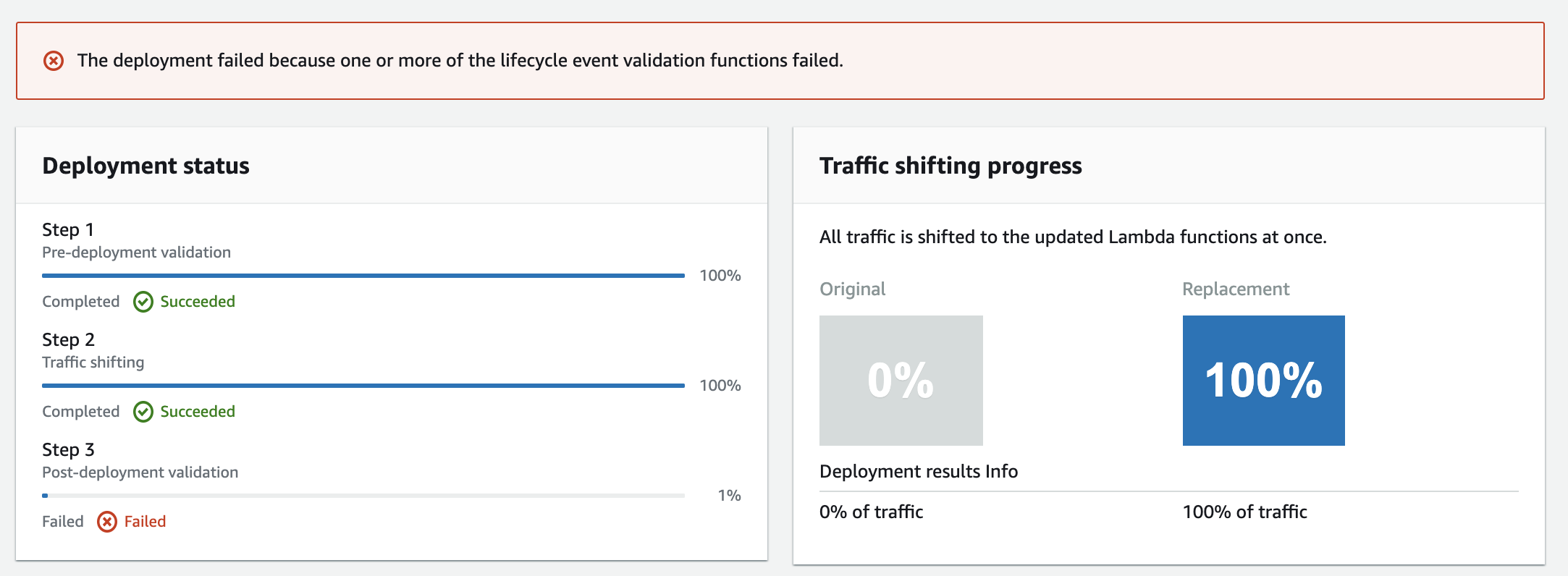
Upon a failure in the after hook, CodeDeploy will rollback the previous version of the Lambda.
Conclusion
It is crucial to make sure that the apps we are developing are high quality. Testing is one of the ways to confirm this.
As per the testing pyramid, write tests as much as possible to cover the base (unit tests), test the integration, and finally cover your full flow with E2E tests.
In a serverless app, testing is still the same, with some additional tweaks around integration testing and deployment. This configuration enables traffic shifting and might make a significant difference in keeping your customers happy.
You might still want to test your app on a local environment. There are tools such as localstack that help with that.
How are you testing your serverless apps?
References
https://docs.aws.amazon.com/whitepapers/latest/serverless-architectures-lambda/welcome.html
https://www.serverless.com/framework/docs/providers/aws/guide/testing/