By ric0
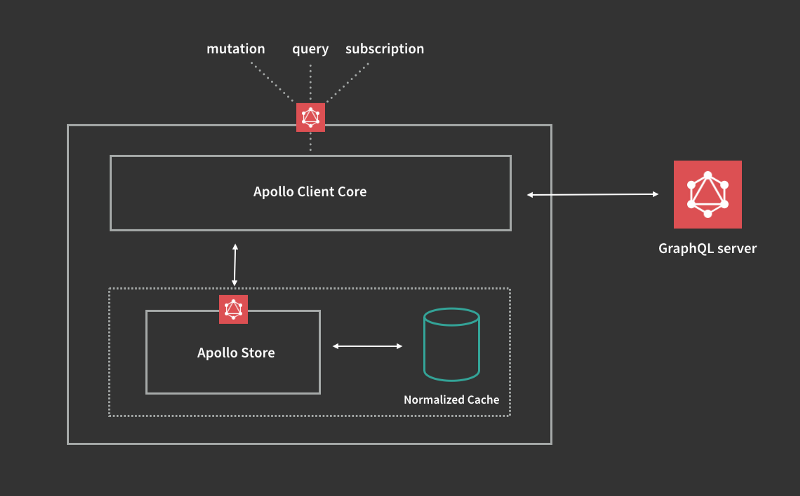
The Apollo Client and its cache
The Apollo Client is used to fetch data from any GraphQL server. The client is small, yet flexible with many awesome features of which the most appreciated one might be the automatic cache updates that come with the client.
Basically, the Apollo Client automatically inspects the queries and mutations’ traffic on your behalf and uses the latest version of the data it sees in a response so that the local cache is always up to date.
A simple update
Let’s, for example, have a query that asks for all articles:
query articles { articles { id title published author { name } }}
We get this data back:
{ data: { articles: [ { id: '6543757061', title: 'Does It Pay to Be a Writer?', published: true, author: { name: 'John Doe', } }, { id: '6543757062', title: 'The Genius of Insomnia', published: true, author: { name: 'Mike Kinski', } } ] }}
Later we modify the title of the article with id “6543757061”:
// MUTATIONmutation updateArticle($id: ID! $title: String) { updateArticle(id: $id, title: $title) { id title published author { name } }}
// _update-article.js...this.props.mutate({ mutation: UPDATE_ARTICLE, variables: { id: '6543757061', title: 'I am a new title', },});...
Result:
articles: [ { id: '6543757061', title: 'I am a new title', published: true, author: { name: 'John Doe', } }, { id: '6543757062', title: 'The Genius of Insomnia', published: true, author: { name: 'Mike Kinski', } } ]
After the mutation succeeded, our cache gets updated automatically because of 2 reasons:
- we included the article id in the mutation response
- we included the title in the response
Indeed if the id field on both results matches up, then the title field everywhere in our UI will be updated automatically.
Basically, you should make your mutation results have all of the data necessary to update the queries previously fetched.
That’s also why is a best practice to use fragments to share fields among all queries and mutations that are related.
However, updating the author name would not have the same result as the previous one because we have no id field within the author. To make it work both query and mutation should include the author’s id as well:
idtitlepublishedauthor { id name}
Extended use cases
However this above is the only type of scenario where the in-place update is more than enough. Indeed there are many other common situations that the automatic update is not covering such as:
- article creation
- article deletion
- filtered lists of articles
and so on.
Generally, any case where you need to update your cache in a way that is dependent on the data currently in your cache.
Those are cases that can be solved only in 2 ways:
- refresh the browser** after the mutation :D
- directly access the local cache using the
updatefunction that allows you to manually update the cache after a mutation occurs without refetching data
** considering you’re using the cache-first default fetchPolicy
While refetchQueries would be the third option, update is the Apollo’s recommended way of updating the cache after a query. It is explained in full here.
Use of the update function
However, because using the update function gives you full control over the cache, allowing you to make changes to your data model in response to a mutation in any way you like, it quickly became complex to manage your own cache.
The temptation would be to turn off the Apollo cache by default, but that should never be the case.
Let’s address the most common challenges you may face when you start managing your own cache directly.
Use always a try/catch block
Most of the examples you see, also in the official Apollo’s documentation, look like the following:
const query = gql`{ todos { ... } }`export default graphql(gql` mutation ($text: String!) { createTodo(text: $text) { ... } }`, { options: { update: (proxy, { data: { createTodo } }) => { const data = proxy.readQuery({ query }); data.todos.push(createTodo); proxy.writeQuery({ query, data }); }, },})(MyComponent);
That’s cool, but what happens if the query has not yet been fetched, so is not in your cache as you supposed? proxy.readQuery would throw an error and the application would crash.
Being sure that the query is there would be safe only in simple scenarios. You need to use a try/catch block:
update: (proxy, { data: { createTodo } }) => { try { const data = proxy.readQuery({ query }); data.todos.push(createTodo); proxy.writeQuery({ query, data }); } catch(error) { console.error(error); }},
Otherwise, you should be damn sure that the query would be in the cache already.
The message here is that you’re better off not making assumptions at all. As Dan Abramov wrote explained perfectly in his blog post:
We can’t predict the exact user interactions and their order. At any point in time, our app may be in one of a mind-boggling number of possible states. We do our best to make the result predictable and limited by our design. We don’t want to look at a bug screenshot and wonder “how did that happen.
Keep in mind that both proxy.readQuery and proxy.writeQuery may throw errors independently. As an example, you can successfully read a query from the cache while the write operation will throw an error because of a missing field in data, more than often that missing field would be __typename
Always define the variables used in the query
Imagine now that we have a mutation that creates a new article that is already marked as published.
Generally, simple examples show a single query retrieving all articles than later are filtered on the Client (ex. articles.filter(article => article.published))
To illustrate our point, let’s assume instead that we have a query that retrieves from the server only the published articles.
At that point, after the new article mutation completed, we need to read/write the cached query using the published: true variable to match the exact query we need to update in the cache.
update: (proxy, { data: { createPublishdedArticles } }) => { try { const data = proxy.readQuery({ query, variables: { published: true } }); data.articles.push(createPublishdedArticles); proxy.writeQuery({ query, variables: { published: true }, data }); } catch(error) { console.error(error); }},
That’s it. While this use case is manageable, since we only have one Boolean variable, it becomes quite tricky once you have more complicated use cases, that include multiple queries and variables.
Increasing complexity
So far we covered just basic cases. When developing any app, things get easily more demanding down the road in terms of cache management.
Indeed while using the Apollo Client updating the local cache becomes exponentially complicated when it needs to include multiple variables, include multiple queries or cover scenarios where Apollo’s in-place update may not be sufficient:
- Add/remove to list
- Move from one list to another
- Update filtered list
and so on.
Updating more than one query after a mutation
It generally happens that after a mutation we want to update more than just one query. For example, let’s think we are retrieving all articles in the dashboard component, but also published articles and unpublished articles in two other different components.
Apollo client will not only write each query in the cache but will do it so that the same query with different variables is stored as 2 different entries. For example, these are our two queries:
// query 1query articles { articles { id title published author { name } }}// will be stored as: articles
// query 2query articles($where: JSON) { articles(where: $where) { id title published author { name } }}/* will be stored as:articles({"where":{"published":true,"sort":"asc"})
when the query is invoked with:{ variables: { where: { published: true, sort: "asc" } } }*/
Those are 2 different queries in the Apollo’s cache as one would expect. However, we want to retrieve also all unpublished articles. To do so we need to additionally invoke “query 2” with the variables where: { published: false, sort: 'asc' }
Doing so you end up with 3 entries in the cache:
articlesarticles({"where":{"published":true,"sort":"asc"}})articles({"where":{"published":false,"sort":"asc"}})
Why is this important? If you’re going to add a new article and want to update the local cache after the mutation, you will need to read more than one query and also the same query multiple times (one time per each set of variables). Like this:
// STEP #1// update 'articles'try { const dataQuery = proxy.readQuery({ query: getArticles });
dataQuery.articles.push(newArticle);
proxy.writeQuery({ query: getArticles, data: dataQuery });}catch(error) { console.error(error);}
// STEP #2// articles({"where":{"published":true,"sort":"asc"}})try { const dataQuery = proxy.readQuery({ query: getArticles, variables: { { where:{ published: true, sort: "asc", }, }, }, });
dataQuery.articles.push(newArticle);
proxy.writeQuery({ query: getArticles, variables: { { where:{ published: true, sort: "asc", }, }, }, data: dataQuery });}catch(error) { console.error(error);}
// STEP #3// articles({"where":{"published":false,"sort":"asc"}})try { const dataQuery = proxy.readQuery({ query: getArticles, variables: { { where:{ published: false, sort: "asc", }, }, }, });
dataQuery.articles.push(newArticle);
proxy.writeQuery({ query: getArticles, variables: { { where:{ published: false, sort: "asc", }, }, }, data: dataQuery });}catch(error) { console.error(error);}
You should already see where this goes and how easily you will need to add more boilerplate for each query/variables combination.
Variables’ order and values
It is also worth noting that the variables’ order is very important.
These two following queries are not considered the same and will be stored separately in the cache:
// Calling a query
export default graphql(gql` query ($width: Int!, $height: Int!) { dimensions(width: $width height: $height) { ... } ... }`, { options: (props) => ({ variables: { width: props.size, height: props.size, }, }),})(MyComponent);
// Calling the same query above, but with a different order of variables fieldsexport default graphql(gql` query ($width: Int!, $height: Int!) { dimensions(width: $width height: $height) { ... } ... }`, { options: (props) => ({ variables: { height: props.size, width: props.size, }, }),})(MyComponent);
This ends up with the same query stored twice in the cache with a different order of variables:
dimensions({"width":600,"height":600})dimensions({"height":600,"width":600})
Invoke again the same query with different props.size and you get an additional entry in the cache:
dimensions({"width":600,"height":600})dimensions({"height":600,"width":600})dimensions({"height":100,"width":100})
Crazy, huh? You see how this gets easily out of control if approached naively.
Edge cases
If that was not enough there is even more.
When you define a query with variables you generally use them, too.
Let’s consider the following example:
query articles($sort: String, $limit: Int) { articles(sort: $sort, limit: $limit) { _id title published flagged } }
You’re probably going to invoke it like this:
export default graphql(gql`${ABOVE_QUERY}`, { options: (props) => ({ variables: { sort: props.sort, limit: props.limit, }, }),})(MyComponent);
But what about if it gets called with either no variables object at all (variables object is not present) or a variables empty object has been passed, such as variables: {}. This may happen when variables are built programmatically.
For example:
export default graphql(gql`${ABOVE_QUERY}`, { options: (props) => ({ variables: props.varObj, // props.varObj might be an empty object }),})(MyComponent);
stores articles({"sort":null,"limit":null}) in the cache;
while:
export default graphql(gql`${ABOVE_QUERY}`)(MyComponent);
stores articles({}) in the cache.
The above edge cases are more the result of unwanted/unexpected behavior than done on purpose. However, it is good to keep in mind how that query will end in the cache and in what form.
Moving items between cached queries
There could also be the case that we want to unpublish an article. That would mean to move it from the published query to the unpublished one.
Basically, we first need to save the item from the published list, then remove it and finally add the save item to the unpublished list. Let’s see how it can be done:
const elementToMoveId = '1';let elementToMove;
try { const dataQueryFrom = proxy.readQuery({ query: getArticles, variables: { { where:{ published: true, sort: "asc", }, }, }, }); elementToMove = dataQueryFrom.articles.filter(item => item.id === elementToMoveId)[0]; dataQueryFrom.articles = dataQueryFrom.articles.filter(item => item.id !== elementToMoveId)
proxy.writeQuery({ query: getArticles, variables: { { where:{ published: true, sort: "asc", }, }, }, data: dataQueryFrom });}catch(error) { console.error(error);}
if (elementToMove) { try { const dataQueryTo = proxy.readQuery({ query: getArticles, variables: { { where:{ published: false, sort: "asc", }, }, }, });
dataQueryTo.articles.push(elementToMove);
proxy.writeQuery({ query: getArticles, variables: { { where:{ published: true, sort: "asc", }, }, }, data: dataQueryTo, }); } catch(error) { console.error(error); }}
Apollo Cache Updater
As you see, there are a lot of things to wrap up just to handle very common use cases.
There is a lot of code to be written and it is prone to error.
For those reasons, I published the Apollo Cache Updater, an npm package that is a zero-dependencies helper for updating Apollo’s cache after a mutation. It helped me stay sane while handling the cache :)
It tries to decouple the view from the caching layer by configuring the mutation’s result caching behavior through the Apollo’s update variable.
The goal is to cover all the above scenarios by just passing a configuration object.
What it does, after you probably run multiple queries with different variables, pagination, etc., is to iterate over every object in ROOT_QUERY performing actions on your behalf you defined in the configuration object you passed.
Conclusions
Managing the cache is hard, in any language. Apollo Client gives us many advantages though in more complex scenarios it leaves us, developers, to deal with everything by ourselves. Apollo Cache Updater tries to mitigate that pain a little while waiting for an official, easy to use, solution to automatically add/remove entries to cached queries.
Get the npm package here.