By Ritvik Khanna
What is logging?
Let’s say you are developing a software product. It works remotely, interacts with different devices, collects data from sensors and provides a service to the user. One day, something goes wrong and the system is not working as expected. It might not be identifying the devices or not receiving any data from the sensors, or might have just gotten a runtime error due to a bug in the code. How can you know for sure?
Now, imagine if there are checkpoints in the system code where, if the system returns an unexpected result, it simply flags it and notifies the developer. This is the concept of logging.
Logging enables the developers to understand what the code is actually doing and how the work-flow is. A large part of software developers’ lives is monitoring, troubleshooting and debugging. Logging makes this a much easier and smoother process.
Visualisation of logs
 _[source](https://www.datalabsagency.com/wp-content/uploads/2014/11/Interactive-Data-Visualisation-Service.png" rel="noopener" target="blank" title=")
_[source](https://www.datalabsagency.com/wp-content/uploads/2014/11/Interactive-Data-Visualisation-Service.png" rel="noopener" target="blank" title=")
Now, if you are an expert developer who has been developing and creating software for quite a while, then you would think that logging is not a big deal and most of our code is included with a **Debug.Log('____')** statement. Well, that is great but there are some other aspects of logging we can make use of.
Visualisation of specific logged data has the following benefits:
- Monitor the operations of the system remotely.
- Communicate information clearly and efficiently via statistical graphics, plots and information graphics.
- Extract knowledge from the data visualised in the form of different graphs.
- Take necessary actions to better the system.
There are a number of ways we can visualise raw data. There are a number of libraries in the Python and R programming languages that can help in plotting graphs. You can learn more about it here. But in this post, I am not going to discuss about above mentioned methods. Have you ever heard about the ELK stack?
ELK stack
E — Elasticsearch, L — Logstash, K — Kibana
Let me give a brief introduction to it. The ELK stack is a collection of three open source softwares that helps in providing realtime insights about data that can be either structured or unstructured. One can search and analyse data using its tools with extreme ease and efficiently.
Elasticsearch is a distributed, RESTful search and analytics engine capable of solving a growing number of use cases. As the heart of the Elastic Stack, it centrally stores your data so you can discover the expected and uncover the unexpected. Elasticsearch lets you perform and combine many types of searches — structured, unstructured, geo, metric etc. It is built on Java programming language, which enables Elasticsearch to run on different platforms. It enables users to explore very large amount of data at very high speed.
Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your favourite “stash” (like Elasticsearch). Data is often scattered or siloed across many systems in many formats. Logstash supports a variety of inputs that pull in events from a multitude of common sources, all at the same time. Easily ingest from your logs, metrics, web applications, data stores, and various AWS services, all in continuous, streaming fashion. Logstash has a pluggable framework featuring over 200 plugins. Mix, match, and orchestrate different inputs, filters, and outputs to work in pipeline harmony.
Kibana is an open source analytics and visualisation platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualise your data in a variety of charts, tables, and maps. Kibana makes it easy to understand large volumes of data. Its simple, browser-based interface enables you to quickly create and share dynamic dashboards that display changes to Elasticsearch queries in real time.
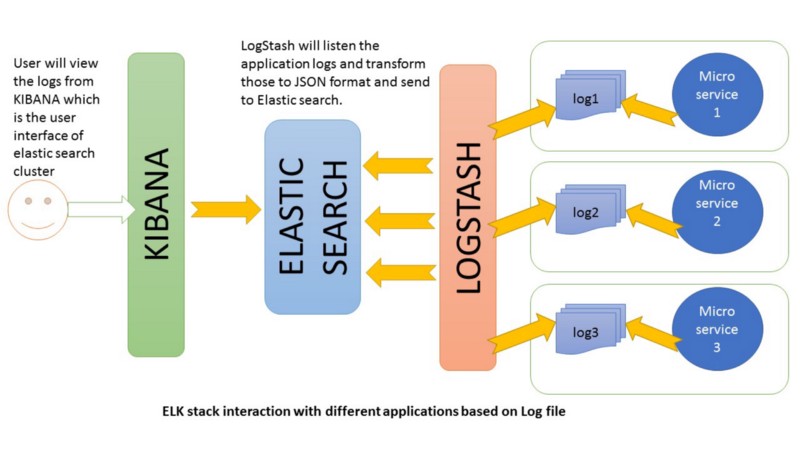
To get a better picture of the workflow of how the three softwares interact with each other, refer to the following diagram:
 _[source](http://Howtodoinjava.com" rel="noopener" target="blank" title=")
_[source](http://Howtodoinjava.com" rel="noopener" target="blank" title=")
Implementation
Logging in Python
Here, I chose to explain the implementation of logging in Python because it is the most used language for projects involving communication between multiple machines and internet of things. It’ll help give you an overall idea of how it works.
Python provides a logging system as a part of its standard library, so you can quickly add logging to your application.
import logging
In Python, logging can be done at 5 different levels that each respectively indicate the type of event. There are as follows:
- Info — Designates informational messages that highlight the progress of the application at coarse-grained level.
- Debug — Designates fine-grained informational events that are most useful to debug an application.
- Warning — Designates potentially harmful situations.
- Error — Designates error events that might still allow the application to continue running.
- Critical — Designates very severe error events that will presumably lead the application to abort.
Therefore depending on the problem that needs to be logged, we use the defined level accordingly.
Note: Info and Debug do not get logged by default as logs of only level Warning and above are logged.
Now to give an example and create a set of log statements to visualise, I have created a Python script that logs statements of specific format and a message.
import logging
import random
logging.basicConfig(filename="logFile.txt",
filemode='a',
format='%(asctime)s %(levelname)s-%(message)s',
datefmt='%Y-%m-%d %H:%M:%S')
for i in xrange(0,15):
x=random.randint(0,2)
if(x==0):
logging.warning('Log Message')
elif(x==1):
logging.critical('Log Message')
else:
logging.error('Log Message')
Here, the log statements will append to a file named logFile.txt in the specified format. I ran the script for three days at different time intervals creating a file containing logs at random like below:
2019-01-09 09:01:05,333 ERROR-Log Message
2019-01-09 09:01:05,333 WARNING-Log Message
2019-01-09 09:01:05,333 ERROR-Log Message
2019-01-09 09:01:05,333 CRITICAL-Log Message
2019-01-09 09:01:05,333 WARNING-Log Message
2019-01-09 09:01:05,333 ERROR-Log Message
2019-01-09 09:01:05,333 ERROR-Log Message
2019-01-09 09:01:05,333 WARNING-Log Message
2019-01-09 09:01:05,333 WARNING-Log Message
2019-01-09 09:01:05,333 ERROR-Log Message
2019-01-09 09:01:05,333 CRITICAL-Log Message
2019-01-09 09:01:05,333 CRITICAL-Log Message
2019-01-09 09:01:05,333 CRITICAL-Log Message
2019-01-09 11:07:05,333 ERROR-Log Message
2019-01-09 11:07:05,333 WARNING-Log Message
2019-01-09 11:07:05,333 ERROR-Log Message
2019-01-09 11:07:05,333 ERROR-Log Message
2019-01-09 11:07:05,333 WARNING-Log Message
2019-01-09 11:07:05,333 CRITICAL-Log Message
2019-01-09 11:07:05,333 WARNING-Log Message
2019-01-09 11:07:05,333 ERROR-Log Message
Setting up Elasticsearch, Logstash and Kibana
At first let’s download the three open source softwares from their respective links [elasticsearch],[logstash]and[kibana]. Unzip the files and put all three in the project folder.
Let’s get started.
Step 1 — Set up Kibana and Elasticsearch on the local system. We run Kibana by the following command in the bin folder of Kibana.
bin\kibana
Similarly, Elasticsearch is setup like this:
bin\elasticsearch
Now, in the two separate terminals we can see both of the modules running. In order to check that the services are running open localhost:5621 and localhost:9600.
After both the services are successfully running we use Logstash and Python programs to parse the raw log data and pipeline it to Elasticsearch from which Kibana queries data.
Step 2— Now let’s get on with Logstash. Before starting Logstash, a Logstash configuration file is created in which the details of input file, output location, and filter methods are specified.
input{
file{
path => "full/path/to/log_file/location/logFile.txt"
start_position => "beginning"
}
}
filter
{
grok{
match => {"message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:log-level}-%{GREEDYDATA:message}"}
}
date {
match => ["timestamp", "ISO8601"]
}
}
output{
elasticsearch{
hosts => ["localhost:9200"]
index => "index_name"}
stdout{codec => rubydebug}
}
This configuration file plays a major role in the ELK stack. Take a look at filter{grok{…}} line. This is a Grok filter plugin. Grok is a great way to parse unstructured log data into something structured and queryable. This tool is perfect for syslog logs, apache and other webserver logs, mysql logs, and in general, any log format that is generally written for humans and not computer consumption. This grok pattern mentioned in the code tells Logstash how to parse each line entry in our log file.
Now save the file in Logstash folder and start the Logstash service.
bin\logstash –f logstash-simple.conf
In order to learn more about configuring logstash, click [here].
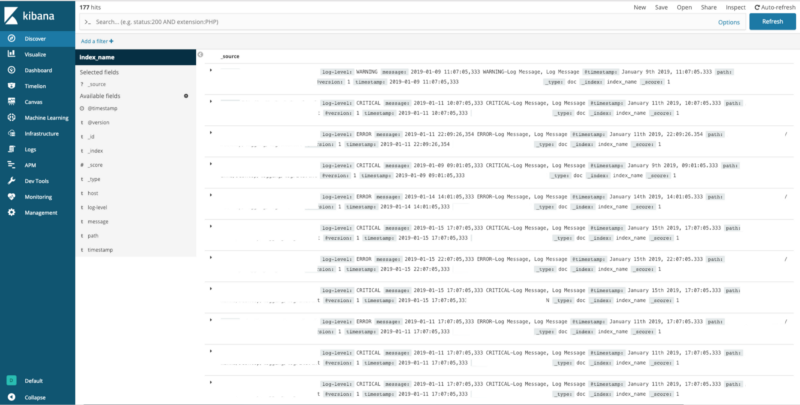
Step 3 — After this the parsed data from the log files will be available in Kibana management at localhost:5621 for creating different visuals and dashboards. To check if Kibana is receiving any data, in the management tab of Kibana run the following command:
localhost:9200/_cat/indices?v
This will display all the indexes. For every visualisation, a new Index pattern has to be selected from dev tools, after which various visualisation techniques are used to create a dashboard.
Dashboard Using Kibana
After setting up everything, now it’s time to create graphs in order to visualise the log data.
After opening the Kibana management homepage, we will be asked to create a new index pattern. Enter index_name* in the Index pattern field and select @timestamp in the Time Filter field name dropdown menu.
Now to create graphs, we go to the Visualize tab.
Select a new visualisation, choose a type of graph and index name, and depending on your axis requirements, create a graph. We can create a histogram with y-axis as the count and x-axis with the log-level keyword or the timestamp.
 Creating a graph
Creating a graph
After creating a few graphs, we can add all the required visualisations and create a Dashboard, like below:
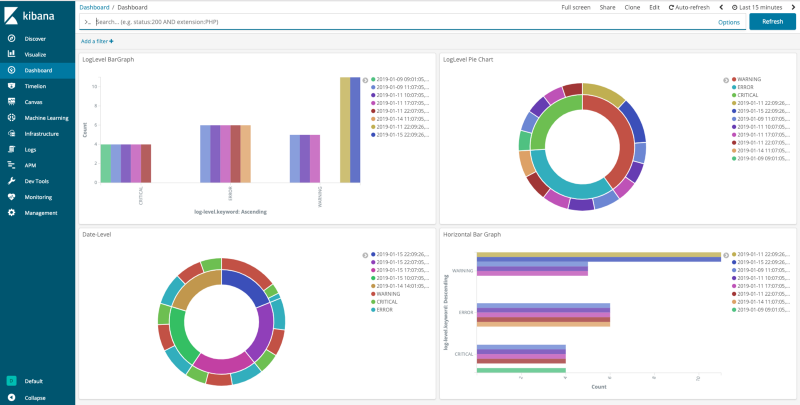
Note — Whenever the logs in the log file get updated or appended to the previous logs, as long as the three services are running the data in elasticsearch and graphs in kibana will automatically update according to the new data.
Wrapping up
Logging can be an aid in fighting errors and debugging programs instead of using a print statement. The logging module divides the messages according to different levels. This results in better understanding of the code and how the call flow goes without interrupting the program.
The visualisation of data is a necessary step in situations where a huge amount of data is generated every single moment. Data-Visualization tools and techniques offer executives and other knowledge workers new approaches to dramatically improve their ability to grasp information hiding in their data. Rapid identification of error logs, easy comprehension of data and highly customisable data visuals are some of the advantages. It is one of the most constructive way of organising raw data.
For further reference you can refer to the official ELK documentation from here — https://www.elastic.co/learn and on logging in python — https://docs.python.org/2/library/logging.html