

Regular expressions provide a powerful and flexible way to define patterns and match specific strings, be it usernames, passwords, phone numbers, or even URLs.
In this article, I'll show you the fundamentals of crafting a regular expression for URLs. Whether you need to validate user input, extract components from URLs, or perform any other URL-related tasks, understanding how to construct a regex for URLs can greatly enhance URL validation in your applications.
First, let me show you what a URL is.
What We'll Cover
- What is a URL?
- How to Write a Regular Expression for a URL
- Testing the RegEx with JavaScript
- Conclusion
What is a URL?
A URL, short for Uniform Resource Locator, is a string that identifies the location of a resource on the web. It typically consists of various components, including:
- the protocol – for instance, HTTP or HTTPS
- domain name – for example, freecodecamp.org
- subdomain – for example, Chinese.freecodecamp.org
- port number – 3000, 5000, 4000, and more
- path – for example,
freecodecamp.org/news - query parameters – for example,
https://example.com/search?q=apple&category=fruits
How to Write a Regular Expression for a URL
A URL can be a base URL (without a subdomain, path, or query param). It can also contain a subdomain, path, or other components. Due to this, you have to tailor your regular expression to the way you're expecting the URL.
If the users are typing in a base URL, you have to tailor your regex fir that, and if you're expecting a URL that has a subdomain or path, you have to tailor your regex that way. If you like, you can also write a complex regex that can accept a URL in any form it can come. It is not impossible.
Here's a regex pattern that matches a base URL of any domain extension:
(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z0-9]{2,}(\.[a-zA-Z0-9]{2,})(\.[a-zA-Z0-9]{2,})?
This would match domains like https://www.freecodecamp.org, http://www.freecodecamp.org/, freeCodeCamp.org, google.co.uk, facebook.net, google.com.ng, google.com.in, and many other base URLs.
The pattern below matches any URL with a path:
(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z0-9]{2,}(\.[a-zA-Z0-9]{2,})(\.[a-zA-Z0-9]{2,})?\/[a-zA-Z0-9]{2,}
This include URLs like https://www.freecodecamp.org/news,
http://www.freecodecamp.org/ukrainian, and others
If you want to match a URL with a subdomain, the pattern below can do it for you:
(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z0-9]{2,}\.[a-zA-Z0-9]{2,}\.[a-zA-Z0-9]{2,}(\.[a-zA-Z0-9]{2,})?
This would match subdomains like https://www.chinese.freecodecamp.org,
chinese.freecodecamp.org, https://chinese.freecodecamp.org, and others.
If you want a regex that matches any URL that is base, has a subdomain, or a path, you can combine all the patterns I've shown you like this:
(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z]{2,}(\.[a-zA-Z]{2,})(\.[a-zA-Z]{2,})?\/[a-zA-Z0-9]{2,}|((https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z]{2,}(\.[a-zA-Z]{2,})(\.[a-zA-Z]{2,})?)|(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z0-9]{2,}\.[a-zA-Z0-9]{2,}\.[a-zA-Z0-9]{2,}(\.[a-zA-Z0-9]{2,})?
Not the prettiest way to do things, but it works:
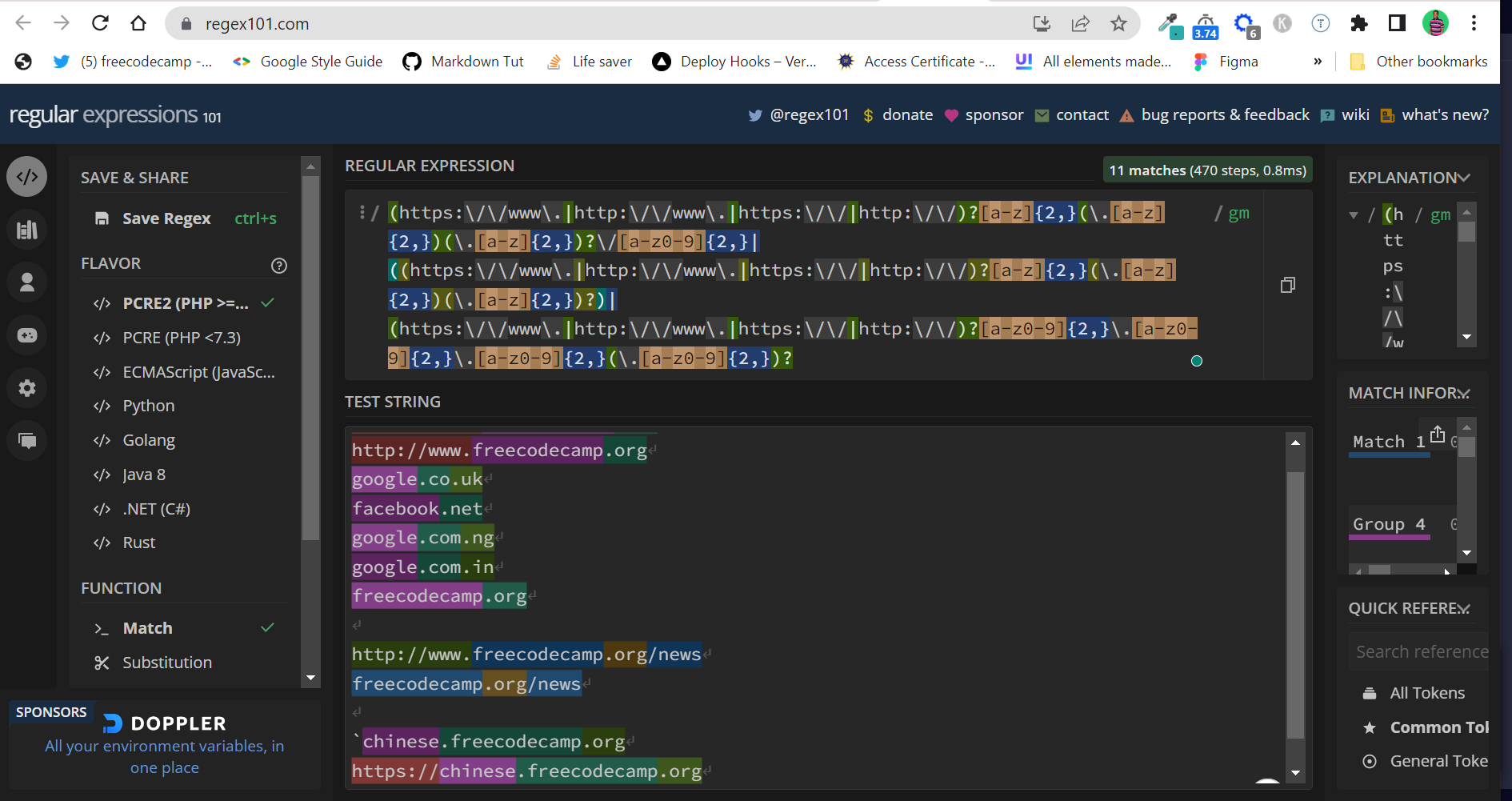
Testing the RegEx with JavaScript
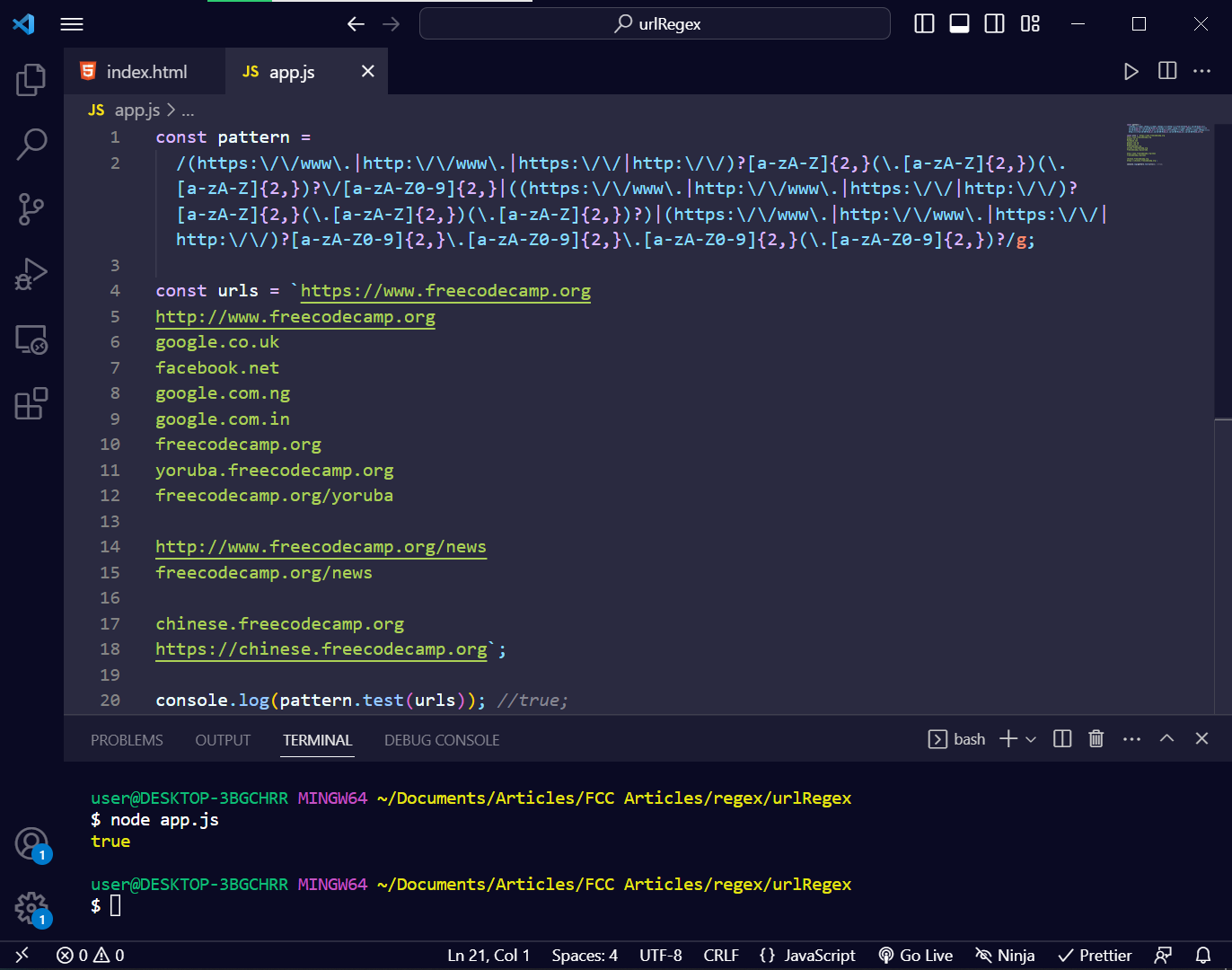
On testing the regex using the test() method of JavaScript RegEx, I got true:
const pattern =
/(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z]{2,}(\.[a-zA-Z]{2,})(\.[a-zA-Z]{2,})?\/[a-zA-Z0-9]{2,}|((https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z]{2,}(\.[a-zA-Z]{2,})(\.[a-zA-Z]{2,})?)|(https:\/\/www\.|http:\/\/www\.|https:\/\/|http:\/\/)?[a-zA-Z0-9]{2,}\.[a-zA-Z0-9]{2,}\.[a-zA-Z0-9]{2,}(\.[a-zA-Z0-9]{2,})?/g;
const urls = `https://www.freecodecamp.org
http://www.freecodecamp.org
google.co.uk
facebook.net
google.com.ng
google.com.in
freecodecamp.org
yoruba.freecodecamp.org
freecodecamp.org/yoruba
http://www.freecodecamp.org/news
freecodecamp.org/news
chinese.freecodecamp.org
https://chinese.freecodecamp.org`;
console.log(pattern.test(urls)); //true;
Conclusion
The regular expression patterns for matching a URL depend on your specific need – since URLs can be in various forms. So, while writing the patterns for the URL, you have to write them to suit the way you expect the URL.
Writing a regex that matches all kinds of URLs works, but it's not the best way to because it's very hard to read and debug.