
By Soundarya Balasubramani
Welcome to a story of five simple students with one big goal: reducing food waste. In the US alone, pitched food weighs in at over 100 Empire State Buildings per year. Just how do five students dream of tackling this monumental task you ask? Well, this is our story of using data for good.

In Columbia Business School’s, Analytics in Action, we partnered with an innovative food delivery startup to minimize their waste and cut expenses. The course pairs teams of 4–6 students with real companies to solve problems through analytics.
Our diverse team was comprised of three MBAs and two Data Scientists from the School of Engineering and Applied Sciences. Our backgrounds include finance, venture capital, engineering, and submarining. We paired with Good Uncle, an innovative, tech-enabled startup which brings the best food in the country onto college campuses nationwide.

The Problem
All of Good Uncle’s food prep starts in a large central kitchen in Delaware, nearly a week before a customer places their order. This business model leaves no time for the company to adjust to demand; put simply, food waste is extra sensitive to the accuracy of their demand forecast.
Other food businesses monitor their inventory and can order replenishment that arrive before the restaurant runs out. Good Uncle needs to accurately order tomatoes and mozzarella several days before the thought of ordering pizza-rolls crosses the patron’s mind.



Our Journey
We first met with Matt, the CEO and Founder of Good Uncle, at his HQ office in Midtown Manhattan. After discussing the ins and outs of the business, we parted ways with the Spring 2018 data for Syracuse University and put on our cleaning gloves.
We added every external feature we could imagine, including weather from DarkSky, events from StubHub, and, of course, the academic calendar from the school’s website. Armed with an arsenal of descriptive features, we began fitting models right away. Lots of models.
Our process started with the ambitious goal of modeling demand at the most granular level. When model after model failed miserably, we bottled our frustration and sought help from our invaluable professors and brilliant TA. We realized we had waged battle with a formidable foe: sparse-demand time-series forecasting.
We dove into the data and searched for sensible ways to group sales points together. We needed to eliminate this sparsity by aggregating sales on a spatiotemporal basis. Because the food trucks rove through the drop points throughout the day, we needed to look at several methods of clustering.
With high double-digit combinations of modeling techniques and data clusters, we turned to bench-marking in order to hone in on our choice model and eventual product for Good Uncle.
Although our goal all along was demand prediction, we realized our real-life target was the bottom line. We quantified the monetary value of ordering too much or too little of a given item on the menu, and used that to set a target equation. To compare models, we optimized for profit and found XGBoosted Trees and Poisson Regression to be the obvious leaders of the pack. With some restored dignity and much more confidence, we made the shift to real-time data.
About halfway through the Fall 2018 semester, we pulled a data-dump from the company and started optimizing models in real time. The results speak for themselves in the section below.
The Solution: CAUTION: Technical jargon ahead
We battled between more than half a dozen modeling techniques, constantly pivoting as new data and insights came into play. We worked with linear regression, auto-regressive modeling, Poisson regression, random forest, extreme gradient boosted decision trees, and so on. In the end, the perfect model was not one, but a combination of two different models.
We realized that this was not just a problem involving forecasting demand, but also forecasting inventory, so we combined the above machine learning models with the famous Newsvendor model used for inventory management.
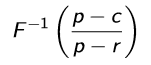
First, we fed the input data into Poisson Generalized Linear Model (GLM) and Gradient Boosted Tree models. The output of both the models was fed as inputs to the Newsvendor model, transforming the above equation into:
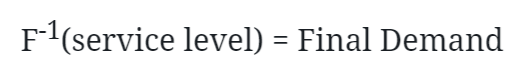
The final output gave the demand forecast, and, by training the model and validating it with various service levels (ranging from 0.1 to 0.99), we were able to find the optimal one.
Result:
The graph below gives a glimpse into how our model outperforms the current method (let’s call it GU’s model). The best way to compare our new method to the old was to find the underage (supply less than demand) and overage (supply greater than demand), which has been plotted below.
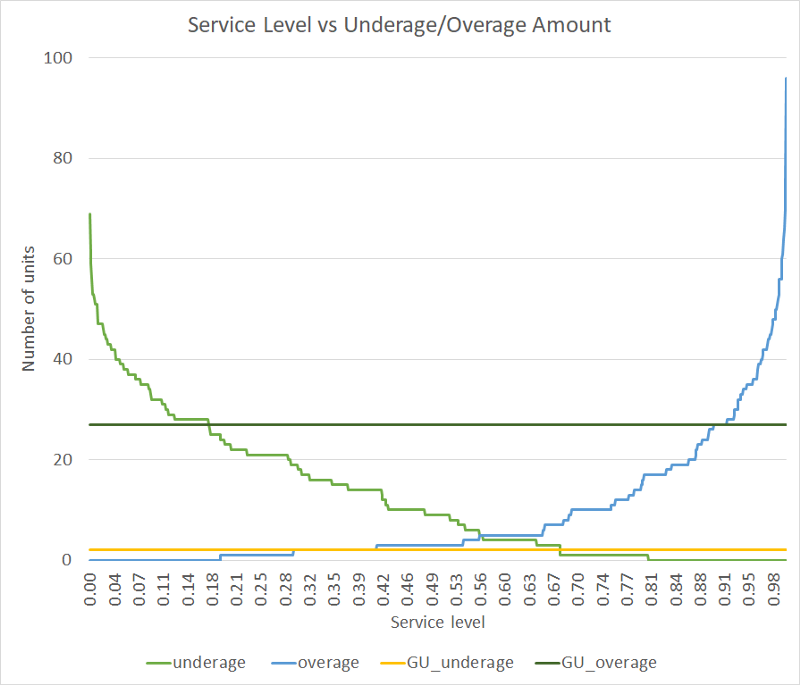
From this graph, we can see two major takeaways.
- We can be flexible in setting our underage and overage levels, whereas this flexibility is not possible for GU’s model (which takes a constant value).
- We can achieve lesser overage as well as underage compared to Good Uncle’s model for service levels between 0.67 to 0.91.
We realized that by setting the optimal service level at 0.68, our model was able to save ~$70 compared to GU’s model for a single food item per route per 10 days. But we wanted to go further. So we ran the model for the top 10 most bought food items across both routes and clusters, and got this handy table shown below:
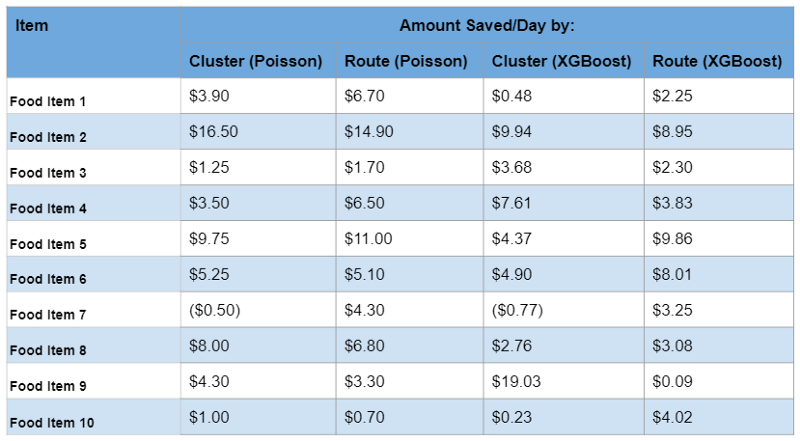
Our model was able to save money on all items except for one (it just doesn’t like the BBQ Pulled Pork Plate!). Finally, to clearly show the power of the model, we extrapolated the dollar value to an entire semester by running it on all routes and clusters for the top 10 items.
We observed a potential savings of $29,256 for the top 10 most bought food items over all drop-points (route wise) in just 1 semester, at just 1 campus.
In Closing
This has been the greatest academic opportunity of our tenure, reaching far beyond the walls of the classroom. We had such a great time working with new friends and we learned so much from the professors, and, of course, the wonderful people of Good Uncle. Not only did we drink from the fire-hose of data analytics, but we shared the journey of an innovative, fast-moving startup and learned from the best entrepreneurs in NYC.
The Team
The team consisted of 5 members: Bowen Bao, Don Holder, Jack Spitsin, Nicolai Mouhin and yours truly. This article was written as a team effort.
If you found this to be useful, do Follow me for more articles. Did you know you can ? m_ore than once? Try it out! ?_I love writing about social issues, products, the technology sector and my graduate school experience in the US. Here is my personal blog. If you’re a curious soul looking to learn everyday, here’s a Slack Group that I created for you to join.
The best way to get in touch with me is via Instagram and Facebook. I share some interesting content there. To know more about my professional life, check out my LinkedIn. Happy reading!