
Did you know that there's an unofficial draft specification for a feature that would allow arbitrary text to be passed to the fragment (#) of a URL?
This would allow users to share links that point to any particular text on a webpage!
What's a URI fragment?
The URI fragment is the optional part at the end of a URL which starts with a hash (#) character. It lets you refer to a specific part of the document you've accessed.
For example, if you visit the following link, you'll automatically scroll to the top of the section you're reading right now!
Assuming you're consuming this article in the browser, you'll notice the URL changes too. It's now appended with #what-s-a-uri-fragment, which is the ID that the Ghost CMS assigned to the heading.
What's Changing?
Before, the primary way to anchor links to part of a page was by specifying the ID of an HTML element in the fragment (source).
This put readers at the whim of the web developer or content writer. If writers didn't provide appropriate IDs, there'd be no way to anchor links to that section.
Some websites or tools provide a non-standard way of handling this, namely highlighting. For example, in Read the Docs you can pass the highlight query parameter to highlight any particular text on the page.
You can try it out in the Weblate documentation.
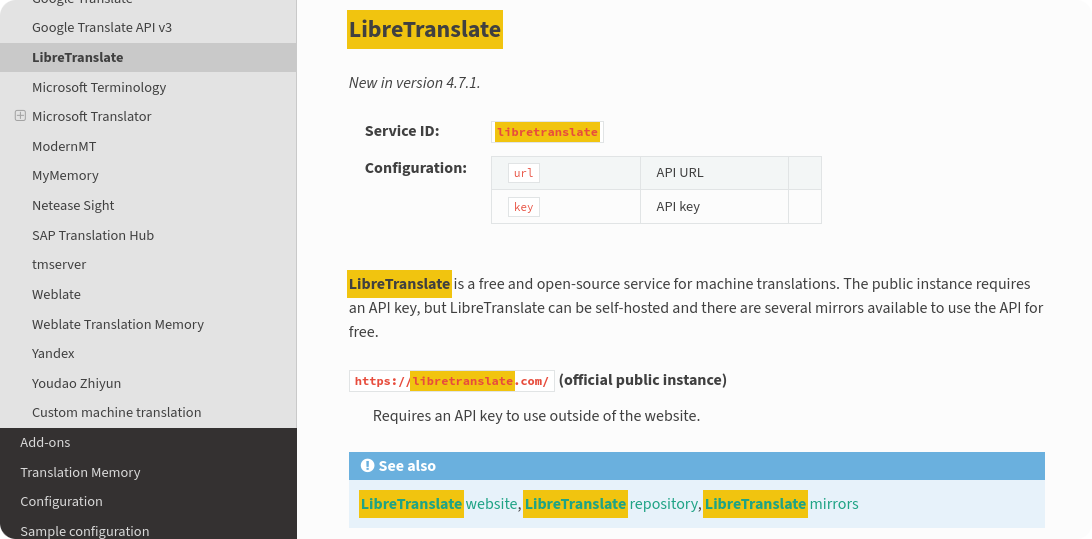
This is what you see when you specify the highlight query parameter on the Weblate documentation.
Text Fragments are a relatively new proposal which extend the usability of URI fragments to query and highlight any arbitrary text as well.
Why Would This Be Useful?
Can you relate to one or more of these scenarios?
When sourcing information, you can link directly to the quote or content you cited.
As a member of support staff, you can link to and highlight a particular excerpt of the documentation or FAQ for the user.
Text fragments can be used with any arbitrary text document that can't store anchor metadata, such as plaintext or configuration files.
You're a web developer who implemented a custom solution for this, but can now just let the browser handle it for you.
If so, then this might help better attribute content on the web, highlight information your users need, or relieve some maintenance effort for developers.
The Proposal
You can specify either literal text, or the start and end of a range of text. The spec includes a pseudo-diagram that demonstrates what the syntax looks like:
:~:text=[prefix-,]textStart[,textEnd][,-suffix]
context |-------match-----| context
Or alternatively, a more digestible version:
| Section | Required | Description | Notes |
prefix | false | Value must appear before the text, but won't be highlighted. | Must end with -. |
textStart | true | If textEnd is not specified, matches literally, otherwise used in combination with textEnd to match a range. | |
textEnd | false | Used in combination with textStart to match a range of text. | |
suffix | false | Value must appear after the text, but won't be highlighted. | Must start with -. |
The sections prefix and suffix are used for context, so if the text you want to match appears multiple times on a page, you can use them to indicate to the browser which instance you want to match.
To provide some examples, let's suppose we open the Web Monetization website which includes the following text.
A JavaScript browser API that allows the creation of a payment stream from the user agent to the website
| Example | Highlights |
:~:text=javascript | JavaScript |
:~:text=api,stream | API that allows the creation of a payment stream |
:~:text=javascript-,browser | browser |
:~:text=a-,javascript,api | JavaScript browser API |
:~:text=that-,allows,stream,-from | allows the creation of a payment stream |
For longer excerpts of text, a range is preferred to avoid bloating the URL. Usually, developers will aim to keep the total length of URLs below 2,000~ characters anyway. This avoids potential issues with older user-agents, especially after accounting for the length of the domain and query parameters.
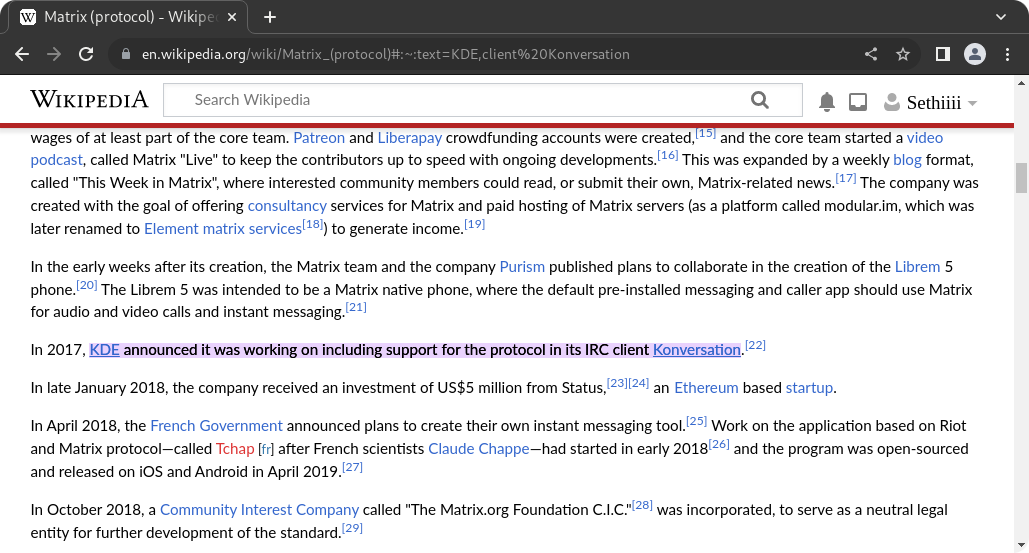
Here is how highlighting looks on Chromium when you visit a webpage with a text fragment.
Implementation Details
From reading the spec, and testing manually in a Chromium browser, here are some of the finer details with querying content in a text fragment.
The sections are not case-sensitive, and accents are ignored (source)
All sections match whole words only, so you can't partially match
Only the first match will be highlighted if there are multiple (source)
Compatibility
Text fragments are available in most Chromium browsers, as this was implemented in Chromium itself in 2020.
Text fragments are not available in Firefox at all yet. Mozilla will hopefully have this implemented in the future – in February 2022 they opened a ticket to track progress.
Privacy and Security
Some concerns have been raised with the specifications, namely that automatically scrolling to parts of the page may reveal certain details about the user.
An interesting thing about URI fragments is that they shouldn't be sent to web servers for processing. URI fragments are intended to be a client-side/user-agent only mechanism to be handled locally by the browser or web application.
To verify this, we can run a small Express server that just logs the URL. We'll see if it includes the fragment:
const express = require('express');
const app = express();
const port = 3000;
app.get('*', (req, res) => {
console.log('URL:', req.url);
res.status(204).send();
});
app.listen(port, () => {
console.log(`Listening on port ${port}.`);
});

The results of each request via curl. The same strings would've printed had I executed the requests in a browser.
Some websites take advantage of this to improve privacy and reduce the bandwidth sent to web servers.
For example, if you look at TypeScript Playground, you'll notice instead of using query parameters or building a short URL, they just encode the TypeScript and store it in the URI fragment.
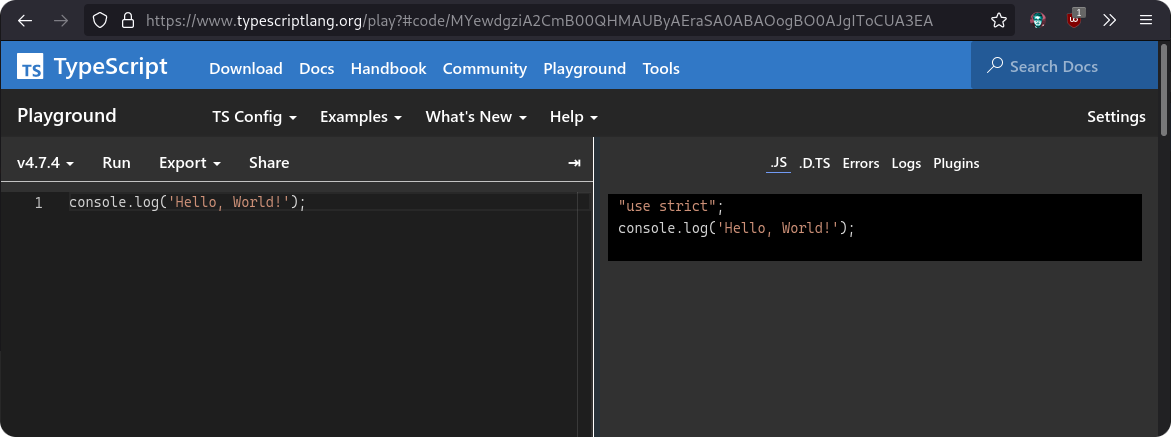
Observe how the URL includes a URI fragment. It's actually just console.log('Hello, World!'); but encoded.
With an implementation like this, you can bookmark or share the link with anyone, and their web server won't know or care about the code. However, any services you use to share the link could, of course, decode and read it.
However, the concern raised with text fragments is that, if a user-agent will automatically scroll down to a given section of a page, while the text fragment wouldn't have been shared with the web server, network requests may've been induced such as loading images on that part of the site. This would allow the web server to derive that you were linked to that section of the page (source).
Despite these concerns, it appears to me that URI fragments as a whole have been susceptible to this for a long-time, not just text fragments.
Regardless, it's a good thing to keep in mind until browser developers and security researchers give this more thought.
Link to Text Fragment Extension
Google has also developed an extension which provides a UI to link any arbitrary text as a URL.
The extension adds "Copy Link to Selected Text" to the context-menu when you select text and secondary-click on it. You can see it in action on the following video.
The extension also ships for Firefox, and polyfills an implementation of text fragments into each webpage, so it'll even scroll to and highlight the matched text too.
Conclusion
I hope this gives more incite on URI fragments as a whole, and especially text fragments.
If you have any ideas for how the specification can be improved, feel free to review the open issues on the browser's and WICG's repositories and provide your thoughts.
I'm eager to see more browsers support this, as it makes the experience of citing, attributing, and linking to content on the web a lot more convenient.