

Cache Me If You Can
About 2 years ago, I remember witnessing a reunion that had a profound impact on my software developer life.
The client, a former developer with decades of experience, a tech savvy product owner and another senior developer were talking about a caching problem. The API was answering stales video fragments that caused clients to view the wrong content.
It was bad. Really bad.
Although nobody knew what to do to fix the problem, they all seemed to agree on one thing. The problem was most likely a caching problem.
I didn’t know a thing about HTTP caching back then, so all I could do was listen to them arguing about what could have possibly gone wrong. And all of them had a different explanation.
“Browsers deviate from the specs !” the client said. “The CDN override our caching directives!” the tech product owner thought. “We need to invalidate the whole cache” the tech lead replied.
Since I wanted to be helpful too, even though I wasn’t exactly sure how, given my level of understanding, I started asking questions to my fellow coworkers.
I remember very well the level of confidence everyone seemed to have when answering my questions. Everyone acted like they knew what HTTP caching was all about. But at the same time, all their answers felt really vague and shallow. It was really like everybody had this high level of understanding of how things worked, but nobody wanted to get into the details.
Eventually, the problem magically fixed itself and the team was pretty satisfied with how things worked out.
But I was not.
I thought to myself, what just happened these past few days? Why is it that nobody was willing to admit that they don’t have a clue on how this whole caching thing works? Is it the curse of the software developer to always be tempted to pretend that we know more about a subject than we actually do?
So I decided to check it out for myself. And I somewhat understood why everybody was pretending. The subject was by no means easy. But I was determined to go to the bottom of this.
And that’s how what was supposed to be a few hours of Googling turned out to be months of reading articles, meditating on the specs, and experimenting with caching softwares.
Fast forward today, I now realize that web performance (of which HTTP caching is one of the most important aspects) is a topic on which we are not trained enough. Too few articles talk about it, and most of them don’t go deep enough.
The following articles are my attempt to rectify that by sharing everything I have learned during the past two years about HTTP caching.
I’m not a caching expert, and I won’t turn you into one. But it will hopefully give you a strong understanding of how things actually work.
Let’s Get Started
This series of articles deals with caching in the context of HTTP. When properly done, caching can increase the performance of your application by an order of magnitude.
On the contrary, when overlooked or completely ignored, it can lead to some really unwanted side effects caused by misbehaving proxy servers that, in the absence of clear caching instructions, decide to cache anyway and serve stale resources.
Before we get to the tactical details of how caching works, it helps to understand the context and the landscape of the problem we are up against. For this reason, the first part of this series covers where caching should happen and why we need it.
Without further ado, let us start with an overview of key considerations to keep in mind when dealing with HTTP caching, and to a lesser extent, with web performance in general.
Caching everywhere
Browsers
Caching is a very popular technique. The idea is indeed pretty appealing: no matter how long the I/O request, how CPU-intensive the computation, or any other programming task, it is always the same: storing the result somewhere and retrieving it as it is, for its further application.
Taking the example of browser’s HTTP cache that all browsers implement, web resources are stored on the user’s filesystem. Hence further requests that will access these same resources will have them delivered instantly.
No network request, no client/server round-trips, no database access, and so on. Can you think of any performance enhancement that would yield better results than no latency at all and complete server offloading? That’s simply not possible.
One might think that this situation is too ideal and impractical. If it were true, how come most pages don’t load that fast? One reason for this is because, even though all web resources are cacheable, they should not be cached the same way.
HTML files for example, which are the first to be downloaded and that contain references to other assets, are notoriously dangerous to cache. Therefore, they’re unlikely to find their way to browser caches except for a few minutes at most, as we shall see in a moment.
But another possible explanation, one that we find more likely based on our experience, is that caching policies are often completely left out for web servers to decide.
Setting a flag on a web server’s configuration file to automatically activate ETag generation and Last-Modified headers is not time-consuming and can give decent results.
For some time at least. Until one realizes that the feature doesn’t work as expected or even worse, that users are starting to be served stale content due to unknown reasons.
Besides, these web servers won’t do much good in terms of caching your API. Most of them generate cache headers based on files metadata, which can have subtle consequences. But with API requests, there is no file to read metadata from. Hence when they see a resource that is dynamically generated, all they can do is watch and forward the request.
Granted, as efficient as it can be, caching in the browser is not as easy it as looks. Major browsers implement different layers of cache, of which the HTTP one we’re talking about is only a piece. And in case you’re wondering, they can interact in some ways that are not always as predictable as we would like them to be.
Besides, caching in the browser is notoriously dangerous, because developers lack the ability to invalidate resources at will. Doing so would involve allowing a web server to push information to every client that interacted with it, without clients initiating a connection, which is not possible in a client/server architecture.
Furthermore, from the cacher’s point of view, as powerful as it is, the browser has other flaws. It uses some doubtful heuristics when no caching instructions are explicitly present, all the more reason for us to help it know exactly what to do.
But even if we were to do it, users have the ability to flush their cache anyway or disable it. Not the almighty caching tool that one could ask for Christmas, after all.
So let us take the browser out of the equation for now and ask ourselves: without it, is HTTP caching still relevant? Is it implemented at other places? As it turns out, the browser is just one piece of the caching chain. And if browsers were all of a sudden to stop caching everything, rest assured: CDNs got us covered.
CDN
Content Delivery Networks (CDN) are the unified champions of the HTTP caching world. Most of them have installed tons of servers — Akamai has ~240 000 — all geographically around the globe in order to serve our content closely to our end users.
These companies have accumulated decades of experience on web performance. Most of the people who write the specs or the software that power the specs usually work in these companies, which is a bit of an indication that they know what they’re doing. Let us take a quick tour of why they are so important and how they work.
First and foremost, is it crucial to understand that all of these servers are HTTP servers. In HTTP terminology, they are proxy servers which means that they speak HTTP. They do not encapsulate our requests into another shady proprietary application protocol. They just use these proxies, most of which are even free or open source!
As a direct consequence, any knowledge of HTTP caching is immediately actionable to leverage the infrastructure they put at our disposal. In addition to billions of browsers, we now have thousands of servers strategically placed by specialized companies waiting for us to instruct them how to cache our content for maximum efficiency. Furthermore, depending on what your priorities are, that’s not even the best feature.
Most modern CDNs advertise the ability to programmatically purge resources out of the CDN’s network instantly. Let us say this again: programmatically and instantly.
As far as HTTP caching is concerned, the two hard problems in computer sciences might just have been reduced down to one! Caching anything and invalidating instantly whenever we want. From a developer keen on web performance point of view, it can hardly get any better.
A word of caution: CDNs are not to be blindly trusted based on that. We’ve already experienced some slight differences between what was marketed on the brochure, and what we had in production, where other cache busting techniques had to be used to ensure the cache was actually cleared.
Before starting to cache all of your resources forever carelessly, experimenting on a small sample first might be a good idea. However, if it’s not here today, it will eventually land consistently everywhere, making our lives much easier.
Another aspect to keep in mind is that it is in every CDN’s best interest that developers see them as effective and powerful tools. As a consequence, they’ll often do their best to comply to the specification.
Also, they all provide some web interface that makes it a breeze to give caching rules that will either override or play nice with upstreaming caching directives coming from origin servers. The ability to configure your caching policy outside of your codebase happens to have two interesting consequences.
First, it means that people other than developers can have control on this which can be seen as a strength or a weakness based on your perspective. The ability to have someone other than a software developer fine-grain caching settings at the CDN’s level on critical occasions might come in handy in some situations.
But perhaps even more importantly, it means that the performance part of your application, or at least a large part of it, can be completely factored out at the infrastructure level.
All developers that have experienced performance problems at some point know this: it is rarely something you can mutualize in a single file called performance and is often best planned ahead, just like detailed application-level logging. But that’s not necessarily the case with caching.
Provided your caching headers are smartly set and your CDN well configured, you could write poorly optimized server code (although, please don’t) and still have the vast majority of your users be served content in less than 300 milliseconds, by reusing cached versions that are still perfectly fresh.
On the flip side, as one might expect, setting up and maintaining such a network of servers is both expensive and complex. As a result, although some of them have free plans that already allow for some serious performance boost in rather wide geographic areas, they remain paid solutions. If your intention is to cache millions of resources, be prepared to pay several thousand of dollars. This is where private proxy caches come into play.
Private proxy
The third and last player of the HTTP caching game is simply the same softwares many of the CDNs we just talked about are made of. Do the names Varnish, Squid, Traffic Server, or even Nginx ring a bell? Well, they certainly should!
Given what we just said about the unmatched performance of web browser caches, and the case we just argued in favor of CDNs, one might legitimately asks: why bother setting up these in front of my origin servers when CDNs can do much more, and browsers are closer to my end users?
Well, this third and last solution in the HTTP caching landscape also comes with its fair share of advantages. As a matter of fact, we’ll argue that this should often be the first solution to look for. Let us examine a few bonus points of the most popular solutions.
First, these solution are free and open source, which can be seen as a double edge sword. How many of such software that were once praised by the community suddenly stopped being maintained by their core committers due to a lack of interest, sponsoring, or both? The fear of seeing a project’s main dependency (web framework, ui library…) going to the software graveyard is a real concern.
Although when assessing this risk, one must always consider the maturity of the technology, how long it’s been around, which big company is using or supporting it — they usually do both — and how effective it is at solving a particular problem. Lucky for us, the proxies we’re talking about score pretty high on all levels.
Another aspect simply comes from the performance gain. As mentioned previously, these softwares are what CDNs are made of. This has two consequences.
First, it massively decreases the chance of termination of their usage, because CDNs whole infrastructure relies on it. This kind of stability is greater than when a company is just using a library as part of a larger system. In this case, the software is the system.
Second, any hard gained knowledge about their installation, configuration and maintenance will directly be transferable the day you decide to switch or complement your caching infrastructure with a CDN, since they are the same servers! In the software development world, where everything changes so fast, this is always good news.
It’s the same reason why learning HTTP caching is a good bet, because it’s relevant in many different places. And will likely stay that way for decades, we shall see why in the end of this article.
Browsers, edge servers, proxy servers… that’s a lot of caching intermediaries. Thinking about all these caches at the same time can be a little overwhelming and hard to picture. Luckily for us as we mentioned previously, all these caches speak HTTP and comply to the same specification.
As proxy servers, they all act transparently both for clients and for servers. Origin servers communicate with the proxy as if it were the client, and end users browsers communicate with the proxy as if it were the server. This holds true even between proxy servers.
As such, we can model the reality by considering that all caching infrastructures are equivalent to one with a single caching proxy in place.
This is best described by the following picture:
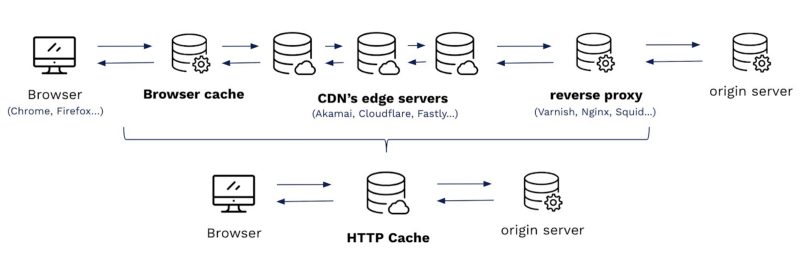
We’ll use this simplification in the rest of this series of articles. This abstraction is helpful to visualize the mechanisms at play, but it comes with certain limitations. Putting two proxies one after the other can have subtle consequences.
So far, we have covered a lot of ground without giving away anything about the detailed interactions between a client and a caching server. HTTP caching is a complex subject. Before moving on to the real technicalities in part 2, there is one last important aspect that needs to be explored.
Caching for the future
Have you ever had to wait a few seconds to interact with a web page, or to see anything meaningful on the screen? Probably. That’s actually not unlikely at all. Everyone has experienced the slow internet at some point in their life, even at home with fiber connectivity.
Past UX research actually has got some scary metrics about this. Metrics that have been the same for more than 40 years, by the way, making them unlikely to change anytime soon. Their guidelines are expressed in terms of hundreds of milliseconds, whereas we are used to browse the Internet and wait several seconds.
So why do we believe that HTTP caching is relevant today and will almost certainly remain so for the years to come?
It all comes down to this basic question: why is the web so slow?
This question is undoubtedly a difficult one, and a rigorous examination would take us far too deep and lose our primary focus, which is HTTP caching. However, if we don’t have any idea on what makes a web page slow, how can we be sure that caching, despite all of its virtues, is the right tool for the job?
From its conception, the web has certainly changed a lot. The days where web pages consisted of simple HTML files containing mostly text and hyperlinks are long gone.
These days, many websites are labeled as web applications, as their look and feel resembles that of desktop apps. But despite all the improvements and innovations that have been made over the years, one thing has always remained the same: it’s always begun with the downloading of an HTML file.
As it gradually downloads the HTML, the browser discovers all the other resources that combined will result in all the client’s side code that gets parsed and ultimately, executed.
In case of a typical SPA for instance, the flow of requests goes on. Upon execution, the application starts downloading data from the server, typically serialized as JSON these days, in order to render the UI. Each URL inside the JSON payload will, once referenced into the code (it doesn’t even have to be added to the DOM), triggers another download so that it can be displayed on the screen.
This model of execution, where all the bytes needed for the application to do its job are scattered among different places and must be downloaded every time is quite remarkable. Arguably, it’s what makes the web so unique in the software development world.
But there is a catch.
Indeed as of today, the typical web application requires 75 requests and weighs 1.5 Mb, meaning that browsers must initiate a lot of requests of ~20kB each. To put it another way, it means that a typical web application is made of lots of short-lived connections.
And here is the catch: this is the exact opposite of what TCP is optimized for.
The anatomy of a web request
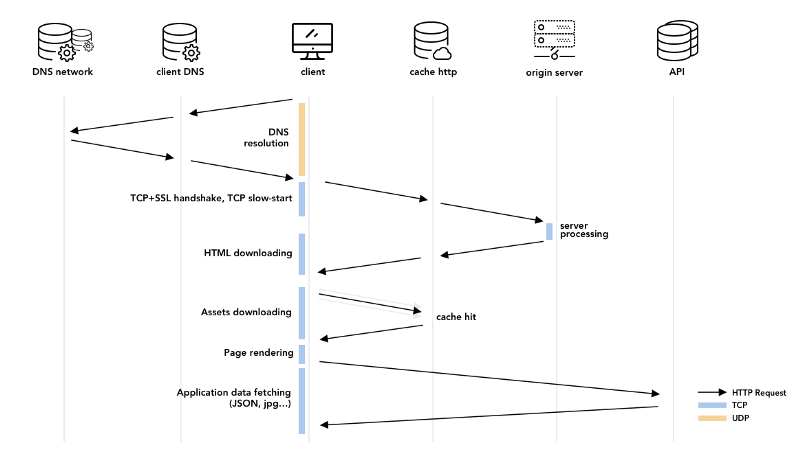
In theory, all of these 75 requests should go through these steps:
DNS resolution
TCP handshake
SSL handshake
Data downloading constrained by TCP flow and congestion control
Let us walk through each of them and draw a counter-intuitive consequence from it.
DNS resolution is the process of converting a human readable hostname such as example.com into an IP address. Although the DNS protocol is based on UDP instead of TCP, the journey to getting a hostname IP address can be really long, involving multiple DNS servers. And it’s not uncommon that these DNS resolutions take between 50 to 250 milliseconds.
Then, each request must initiate a TCP connection. HTTP has always needed a reliable transport protocol to work. If the ASCII bytes representing every HTTP request were to be delivered out of order, a status line such as
GET /home.html HTTP/1.1
would become:
GTE /mohe.hmtl HTTP/1.1
and the request wouldn’t make much sense.
In order to guarantee delivery order, TCP marks each byte of applications data with a unique identifier called a sequence number (SYN). The problem is that this number must be chosen randomly for security reasons.
Therefore, if a client is asking for a resource, it cannot do so without signaling to the server its initial sequence number (ISN). Then it must wait before the server acknowledges good reception of this segment, before being able to send application data.
Well, unless the request is secure, which it probably is since 80% of HTTP requests these days are actually secure HTTPS requests. These are normal HTTP requests, except that they are encrypted in order to guarantee (at least, up to this day) confidentiality, integrity, and authenticity.
To accomplish that, the client and servers must now agree on a TLS protocol version, select cryptographic functions, authenticate each other by exchanging and validating x509 certificates… for no less than ~10 protocol messages that can be packed into a minimum of 2 TCP exchanges, and as many round trips.
Once the connection is setup and secure, then TCP can finally start sending segments carrying our application data, such as our HTTP request. Unfortunately for us, TCP prevents us from sending all our data at once in one batch of multiple segments.
This restriction is a necessary evil, so that we don’t accidentally cause a buffer overflow on the receiver. When an application that initiated a connection asks the underlying TCP socket for data, TCP will refuse to give any chunk that would be incomplete or made of unordered smaller chunks. Hence, the need for a buffer.
The way it works is that TCP sends N segments in the first batch, and, if all segments were received by the server, will send twice as many segments (2N) in the next batch, and so on, leading to an exponential growth. This mechanism is commonly known as the slow-start algorithm and is one of the two only possible modes in which TCP operates, along with congestion avoidance.
We won’t discuss congestion avoidance in this series. But if there was only one thing to be aware of, it would be that once TCP senses that the underlying network may be congested, the protocol starts acting much more conservatively. Thereby extending even more the time required to transmit data.
The consequence
With all these steps in mind, let us make a simple calculation to realize something important. At the beginnings of the web, the N parameter (known as the congestion window in TCP’s terms) was equal to 1. With such a window and an average resource of 20kB, we can determine how many round trips are necessary for an average request to be fully transmitted.
Indeed, under normal circumstances, the maximum segment size (MSS) is 1460 bytes. That’s equivalent to 20 000 / 1460 = 14 TCP segments. When dispatched according to the exponential scheme we just described, this is equivalent to 4 round-trips to the server.
Now, if we approximate a UDP-based DNS request to a TCP-based request to the origin servers, we can estimate a total number of round-trips (RT) that require the booting of a modern web application:
DNS request: ~1 RT
TCP connexion setup: 1 RT
SSL handshake: 2 RT
Resource downloading: 4 RTT
Total: 8 RT
75 requests that all require 8 round-trips each result in a total of 600 rounds trips to the server. A typical RTT between Europe and the US is 50ms, which gives us the amount of time that information spend flowing on the Internet when we request a typical web application: 30 seconds. And it could get worse.
The Amazon homepage for instance, a typical MPA, currently weighs 6.3Mb and requires 339 requests. That would translate into a salient page loading time of 2 minutes and 15 seconds. As an exercise, try do the same for the Facebook Messenger homepage, a typical SPA.
How to interpret this number? This would be the actual page load if every single resource had to be downloaded sequentially, TCP initial congestion was down to its minimum value of 1, and if DNS requests, TCP and SSL handshakes had to be done all over again every time. The web would be a much different place for sure.
Fortunately, many improvements have been made over the years. DNS resolutions are cached at different places, TLS handshakes results are reused.
TCP connections were allowed to be persisted between multiple requests, avoiding the cost of both connection setup and slow-start on each request.
TCP’s initial congestion window was lifted up twice, from 1 to 4 and more recently, to 10. Browsers started to open up parallel connections (6) as well as some really advanced strategies to accelerate page load times.
Some proposals tried to break free from the connection setup, although none of them are widely implemented.
Some CDNs even acquired patented algorithms to tune some of TCP aspects such as congestion avoidance, always for the same reason: speed up delivery.
What consequence can we draw from all these round-trips between browser and origin servers?
That bandwidth stopped being the bottleneck many years ago.
This is somewhat counter-intuitive to most of us, because bandwidth has embodied the browsing speed for years. After all, it has exactly the dimension of a speed, bits by unit of time, and it is the only thing ISPs advertise when trying to lure us into becoming their customers.
Besides, browsing on 3G is clearly slower than on 4G. But that is because the threshold at which bandwidth stops being the bottleneck is 5 Mb/s, and 3G maxes out at 2 Mb/s in ideal conditions!
And if wireless technologies such as Wi-Fi or 5G are indeed slower than their wired counterpart of some sort, it is also because in wireless systems, packet drops caused by interferences are commonplace thereby making latency much higher and volatile.
The latest version of the HTTP protocol, HTTP/2, codenamed H2, was a continuation of the SPDY protocol which itself was initially designed following this very observation: bandwidth doesn’t matter much anymore. Latency does. But latency is fundamentally a function of two things: the speed of light in optic fiber, and the distance between clients and servers.
Active research to increase the speed of light in optic fiber has already been conducted, but it only got us so far. In most deployments, light already travels at 60% of its maximum theoretical limit.
But even if we were to reach 99%, that would only have a significant impact on your website if it’s already loading in a few seconds at most. If it’s loading in more than 5 seconds, even though the performance increase would be noticeable, it would still feel slow.
Therefore we are left with one obvious choice: reducing the distance.
And the only way to accomplish that is by leveraging browsers and content delivery networks with HTTP caching.
Conclusion
Along this article, we have argued that HTTP caching is one if not the most effective way to improve the performance of your web application. And as many studies keep pointing out, page load time is an important subject that can be directly translated into user satisfaction and, ultimately, profitability.
We have seen that caching can happen pretty much everywhere, from the browser, to CDN, to private proxy servers sitting just in front of your origin servers. But also that, unlike many performance decisions, it can be completely externalized outside the main codebase, which is both valuable and convenient.
Finally, we took a closer look at the anatomy of a modern web application, to understand why latency is the new bottleneck, making caching relevant today and for years to come, even with the steady deployment of H2.
In the next article of this series, we will deep dive into the How.
In a way, this first part was merely a warm-up! We’ll learn how all of this actually works: resource freshness, revalidation, representations, cache-control headers… and much more!
Stay tuned!
To go further:
Ilya Grigorik High Performance Browser Applications (a must read):
https://hpbn.co/
Mike Belshe paper that served as a basis for the SPDY protocol: https://docs.google.com/a/chromium.org/viewer?a=v&pid=sites&srcid=Y2hyb21pdW0ub3JnfGRldnxneDoxMzcyOWI1N2I4YzI3NzE2
Active CDN blogs with tons of great articles:
https://www.fastly.com/blog
https://blogs.akamai.com/web-performance/