
By Sam Williams
I’ve been using the Hemingway App to try to improve my posts. At the same time I’ve been trying to find ideas for small projects. I came up with the idea of integrating a Hemingway style editor into a markdown editor. So I needed to find out how Hemingway worked!
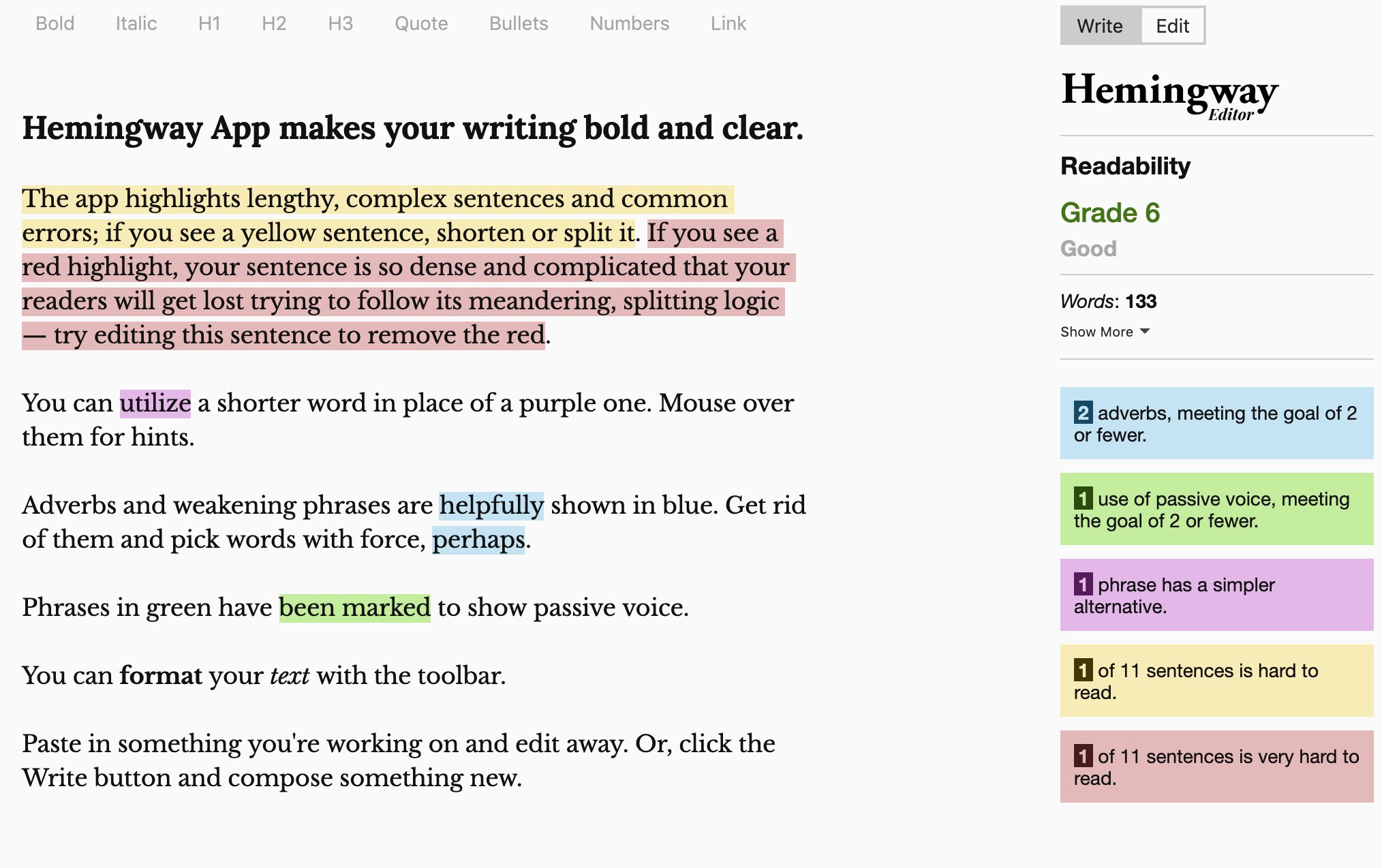 A screenshot of the Hemingway Editor
A screenshot of the Hemingway Editor
Getting the Logic
I had no idea how the app worked when I first started. It could have sent the text to a server to calculate the complexity of the writing, but I expected it to be calculated client side.
Opening developer tools in Chrome ( Control + Shift + I or F12 on Windows/Linux, Command + Option + I on Mac) and navigating to Sources provided the answers. There, I found the file I was looking for: hemingway3-web.js.
This code is in a minified form, which is a pain to read and understand. To solve this, I copied the file into VS Code and formatted the document (Control+ Shift + I for VS Code). This changes a 3-line file into a 4859-line file with everything formatted nicely.
Exploring the Code
I started to look through the file for anything that I could make sense of. The start of the file contained immediately invoked function expressions. I had little idea of what was happening.
!function(e) {
function t(r) {
if (n[r])
return n[r].exports;
var o = n[r] = {
exports: {},
id: r,
loaded: !1
};
...
This continued for about 200 lines before I decided that I was probably reading the code to make the page run (React?). I started skimming through the rest of the code until I found something I could understand. (I missed quite a lot that I would later find through finding function calls and looking at the function definition).
The first bit of code I understood was all the way at line 3496!
getTokens: function(e) {
var t = this.getAdverbs(e),
n = this.getQualifiers(e),
r = this.getPassiveVoices(e),
o = this.getComplexWords(e);
return [].concat(t, n, r, o).sort(function(e, t) {
return e.startIndex - t.startIndex
})
}
And amazingly, all these functions were defined right below. Now I knew how the app defined adverbs, qualifiers, passive voice, and complex words. Some of them are very simple. The app checks each word against lists of qualifiers, complex words, and passive voice phrases. this.getAdverbs filters words based on whether they end in ‘ly’ and then checks whether it’s in the list of non-adverb words ending in ‘ly’.
The next bit of useful code was the implementation of highlighting words or sentences. In this code there is a line:
e.highlight.hardSentences += h
‘hardSentences’ was something I could understand, something with meaning. I then searched the file for hardSentences and got 13 matches. This lead to a line that calculated the readability stats:
n.stats.readability === i.default.readability.hard && (e.hardSentences += 1),
n.stats.readability === i.default.readability.veryHard && (e.veryHardSentences += 1)
Now I knew that there was a readability parameter in both stats and i.default. Searching the file, I got 40 matches. One of those matches was a getReadabilityStyle function, where they grade your writing.
There are three levels: normal, hard and very hard.
t = e.words;
n = e.readingLevel;
return t < 14
? i.default.readability.normal
: n >= 10 && n < 14
? i.default.readability.hard
: n >= 14 ? i.default.readability.veryHard
: i.default.readability.normal;
“Normal” is less than 14 words, “hard” is 10–14 words, and “very hard” is more than 14 words.
Now to find how to calculate the reading level.
I spent a while here trying to find any notion of how to calculate the reading level. I found it 4 lines above the getReadabilityStyle function.
e = letters in paragraph;
t = words in paragraph;
n = sentences in paragraph;
getReadingLevel: function(e, t, n) {
if (0 === t
0 === n) return 0;
var r = Math.round(4.71 * (e / t) + 0.5 * (t / n) - 21.43);
return r <= 0 ? 0 : r;
}
That means your score is 4.71 average word length + 0.5 average sentence length -21.43. That’s it. That is how Hemingway grades each of your sentences.
Other Interesting Things I Found
- The highlight commentary (information about your writing on the right hand side) is a big switch statement. Ternary statements are used to change the response based on how well you’ve written.
- The grading goes up to 16 before it’s classed as “Post-Graduate” level.
What I’m going to do with this
I am planning to make a basic website and apply what I’ve learned from deconstructing the Hemingway app. Nothing fancy, more as an exercise for implementing some logic. I’ve built a Markdown previewer before, so I might also try to create a writing application with the highlighting and scoring system.
Creating My Own Hemingway App
Having figured out how the Hemingway app works, I then decided to implement what I had learnt to make a much simplified version.
I wanted to make sure that I was keeping it basic, focusing on the logic more that the styling. I chose to go with a simple text box entry box.
Challenges
How to assure performance. Rescanning the whole document on every key press could be very computationally expensive. This could result in UX blocking which is obviously not what we want.
How to split up the text into paragraphs, sentences and words for highlighting.
Possible Solutions
- Only rescan the paragraphs that change. Do this by counting the number of paragraphs and comparing that to the document before the change. Use this to find the paragraph that has changed or the new paragraph and only scan that one.
Have a button to scan the document. This massively reduces the calls of the scanning function.
Use what I learnt from Hemingway — every paragraph is a
and any sentences or words that need highlighting are wrapped in an internal with the necessary class.
Building the App
Recently I’ve read a lot of articles about building a Minimum Viable Product (MVP) so I decided that I would run this little project the same. This meant keeping everything simple. I decided to go with an input box, a button to scan and an output area.
This was all very easy to set up in my index.html file.
<link rel=”stylesheet” href=”index.css”>
<title>Fake Hemingway</title>
<div>
<h1>Fake Hemingway</h1>
<textarea name=”” id=”text-area” rows=”10"></textarea>
<button onclick=”format()”>Test Me</button>
<div id=”output”>
</div>
</div>
<script src=”index.js”></script>
Now to start on the interesting part. Now to get the Javascript working.
The first thing to do was to render the text from the text box into the output area. This involves finding the input text and setting the output’s inner html to that text.
function format() {
let inputArea = document.getElementById(“text-area”);
let text = inputArea.value;
let outputArea = document.getElementById(“output”);
outputArea.innerHTML = text;
}
Next is getting the text split into paragraphs. This is accomplished by splitting the text by ‘\n’ and putting each of these into a
tag. To do this we can map over the array of paragraphs, putting them in between
tags. Using template strings makes doing this very easy.
let paragraphs = text.split(“\n”);
let inParagraphs = paragraphs.map(paragraph => `<p>${paragraph}</p>`);
outputArea.innerHTML = inParagraphs.join(“ “);
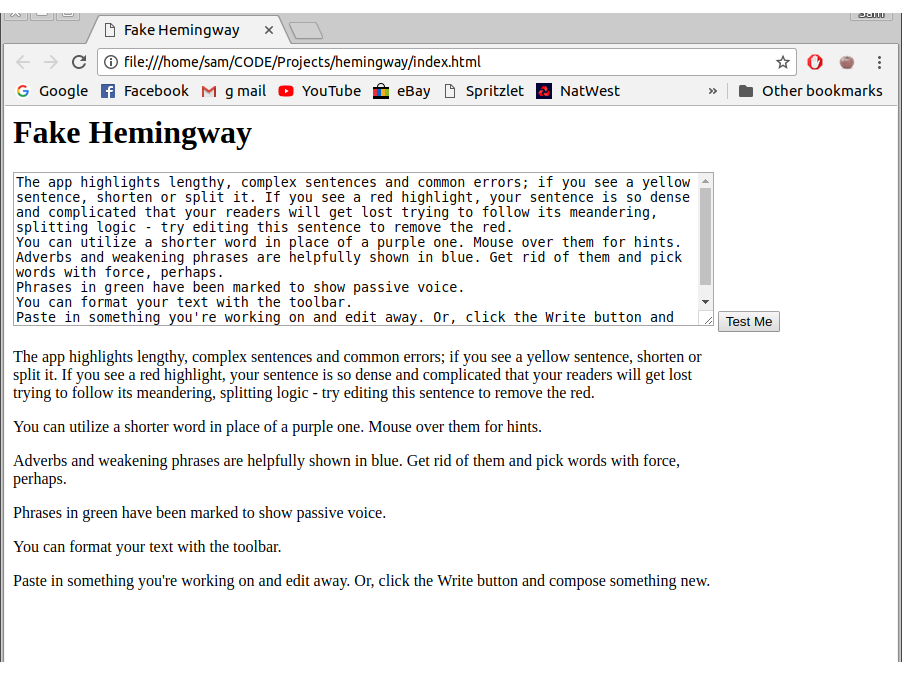
Whilst I was working though that, I was becoming annoyed having to copy and paste the test text into the text box. To solve this, I implemented an Immediately Invoked Function Expression (IIFE) to populate the text box when the web page renders.
(function start() {
let inputArea = document.getElementById(“text-area”);
let text = `The app highlights lengthy, …. compose something new.`;
inputArea.value = text;
})();
Now the text box was pre-populated with the test text whenever you load or refresh the web page. Much simpler.
Highlighting
Now that I was rendering the text well and I was testing on a consistent text, I had to work on the highlighting. The first type of highlighting I decided to tackle was the hard and very hard sentence highlighting.
The first stage of this is to loop over every paragraph and split them into an array of sentences. I did this using a split() function, splitting on every full stop with a space after it.
let sentences = paragraph.split(‘. ’);
From Heminway I knew that I needed to calculate the number of words and level of each of the sentences. The level of the sentence is dependant on the average length of words and the average words per sentence. Here is how I calculated the number of words and the total words per sentence.
let words = sentence.split(“ “).length;
let letters = sentence.split(“ “).join(“”).length;
Using these numbers, I could use the equation that I found in the Hemingway app.
let level = Math.round(4.71 * (letters / words) + 0.5 * words / sentences — 21.43);
With the level and number of words for each of the sentences, set their difficulty level.
if (words < 14) {
return sentence;
} else if (level >= 10 && level < 14) {
return `<span class=”hardSentence”>${sentence}</span>`;
} else if (level >= 14) {
return `<span class=”veryHardSentence”>${sentence}</span>`;
} else {
return sentence;
}
This code says that if a sentence is longer than 14 words and has a level of 10 to 14 then its hard, if its longer than 14 words and has a level of 14 or up then its very hard. I used template strings again but include a class in the span tags. This is how I’m going to define the highlighting.
The CSS file is really simple; it just has each of the classes (adverb, passive, hardSentence) and sets their background colour. I took the exact colours from the Hemingway app.
Once the sentences have been returned, I join them all together to make each of the paragraphs.
At this point, I realised that there were a few problems in my code.
- There were no full stops. When I split the paragraphs into sentences, I had removed all of the full stops.
- The numbers of letters in the sentence included the commas, dashes, colons and semi-colons.
My first solution was very primitive but it worked. I used split(‘symbol’) and join(‘’) to remove the punctuation and then appended ‘.’ onto the end. Whist it worked, I searched for a better solution. Although I don’t have much experience using regex, I knew that it would be the best solution. After some Googling I found a much more elegant solution.
let cleanSentence = sent.replace(/[^a-z0–9. ]/gi, “”) + “.”;
With this done, I had a partially working product.
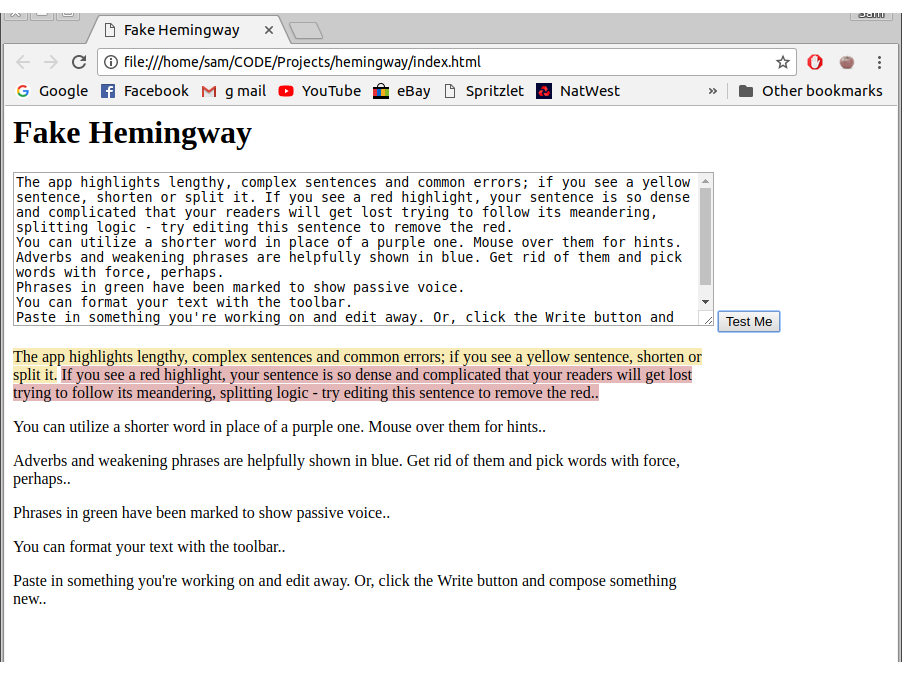 Hard sentence highlighting
Hard sentence highlighting
The next thing I decided to tackle was the adverbs. To find an adverb, Hemingway just finds words that end in ‘ly’ and then checks that it isn’t on a list of non-adverb ‘ly’ words. It would be bad if ‘apply’ or ‘Italy’ were tagged as adverbs.
To find these words, I took the sentences and split them into an arary of words. I mapped over this array and used an IF statement.
if(word.match(/ly$/) &&, !lyWords[word] ){
return `<span class=”adverb”>${word}</span>`;
} else {
return word
};
Whist this worked most of the time, I found a few exceptions. If a word was followed by a punctuation mark then it didn’t match ending with ‘ly’. For example, “The crocodile glided elegantly; it’s prey unaware” would have the word ‘elegantly;’ in the array. To solve this I reused the .replace(/^a-z0-9. ]/gi,””) functionality to clean each of the words.
Another exception was if the word was capitalised, which was easily solved by calling toLowerCase()on the string.
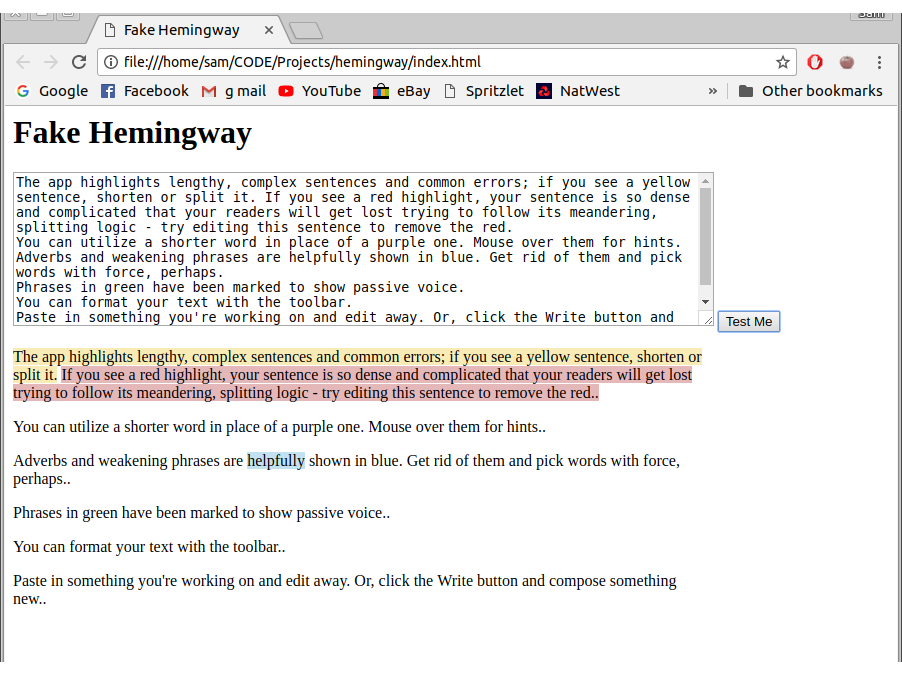 Adverbs working
Adverbs working
Now I had a result that worked with adverbs and highlighting individual words. I then implemented a very similar method for complex and qualifying words. That was when I realised that I was no longer just looking for individual words, I was looking for phrases. I had to change my approach from checking if each word was in the list to seeing if the sentence contained each of the phrases.
To do this I used the .indexOf() function on the sentences. If there was an index of the word or phrase, I inserted an opening span tag at that index and then the closing span tag after the key length.
let qualifiers = getQualifyingWords();
let wordList = Object.keys(qualifiers);
wordList.forEach(key => {
let index = sentence.toLowerCase().indexOf(key);
if (index >= 0) {
sentence =
sentence.slice(0, index) +
‘<span class=”qualifier”>’ +
sentence.slice(index, index + key.length) +
“</span>” +
sentence.slice(index + key.length);
}
});
With that working, it’s starting to look more and more like the Hemingway editor.
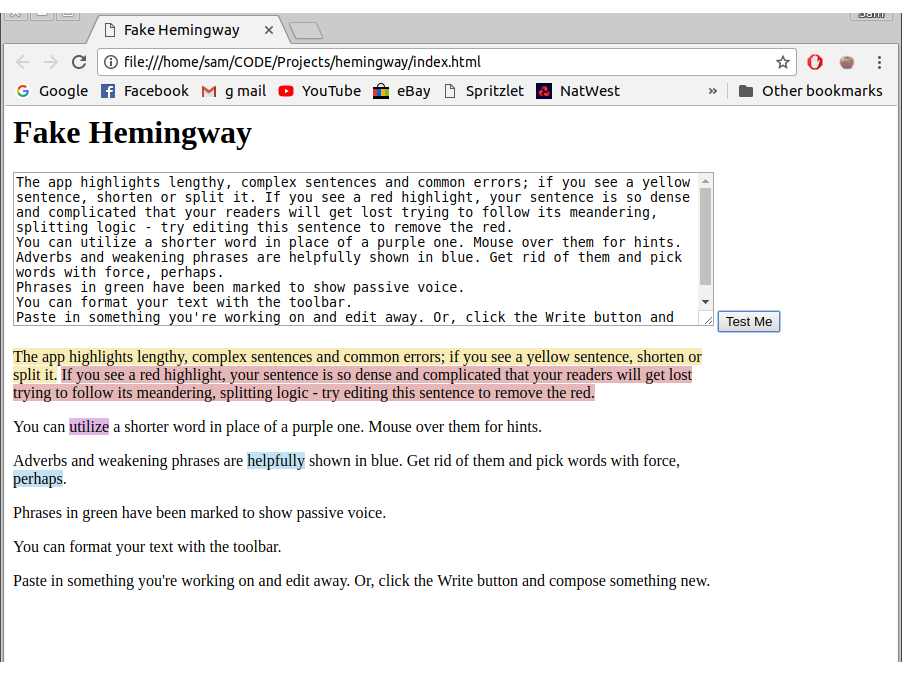 Getting complex phrases and qualifiers working
Getting complex phrases and qualifiers working
The last piece of the highlighting puzzle to implement was the passive voice. Hemingway used a 30 line function to find all of the passive phrases. I chose to use most of the logic that Hemingway implemented, but order the process differently. They looked to find any words that were in a list (is, are, was, were, be, been, being) and then checked whether the next word ended in ‘ed’.
I looped though each of the words in a sentence and checked if they ended in ‘ed’. For every ‘ed’ word I found, I checked whether the previous word was in the list of pre-words. This seemed much simpler, but may be less performant.
With that working I had an app that highlighted everything I wanted. This is my MVP.
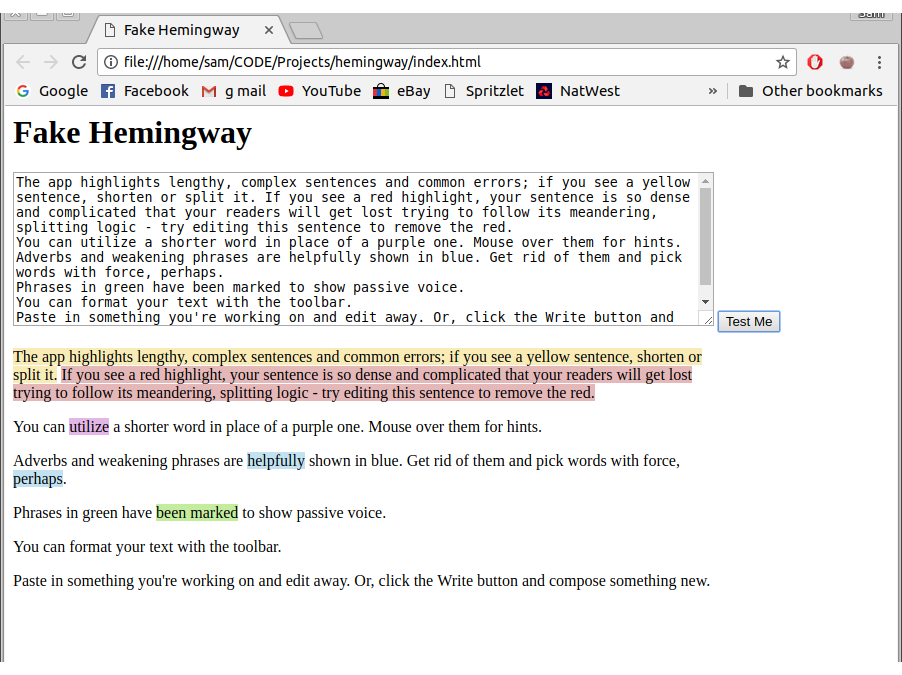 All the highlighting working
All the highlighting working
Then I hit a problem
As I was writing this post I realised that there were two huge bugs in my code.
// from getQualifier and getComplex
let index = sentence.toLowerCase().indexOf(key);
// from getPassive
let index = words.indexOf(match);
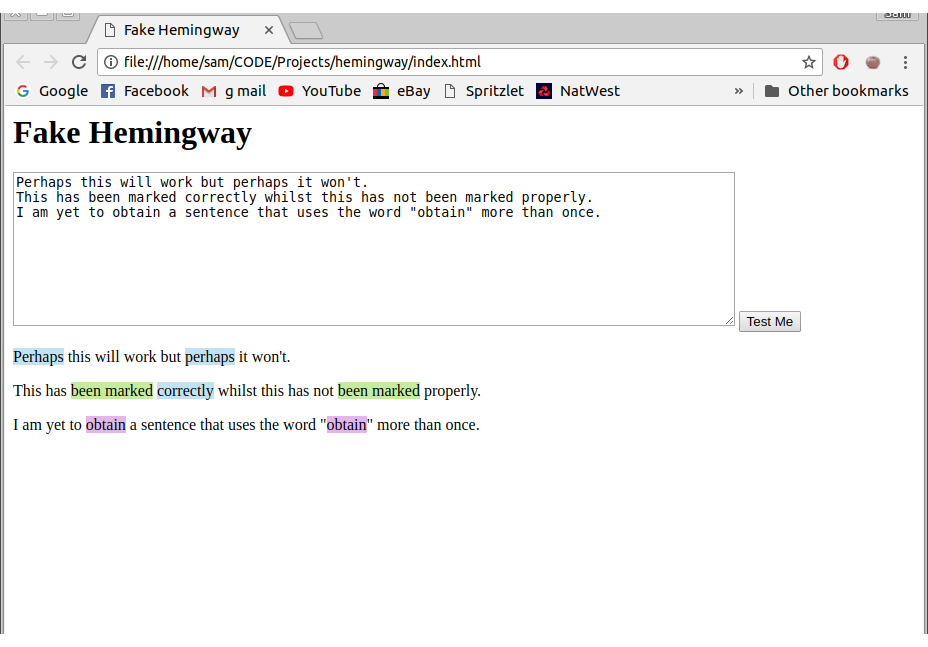
These will only ever find the first instance of the key or match. Here is an example of the results this code will produce.
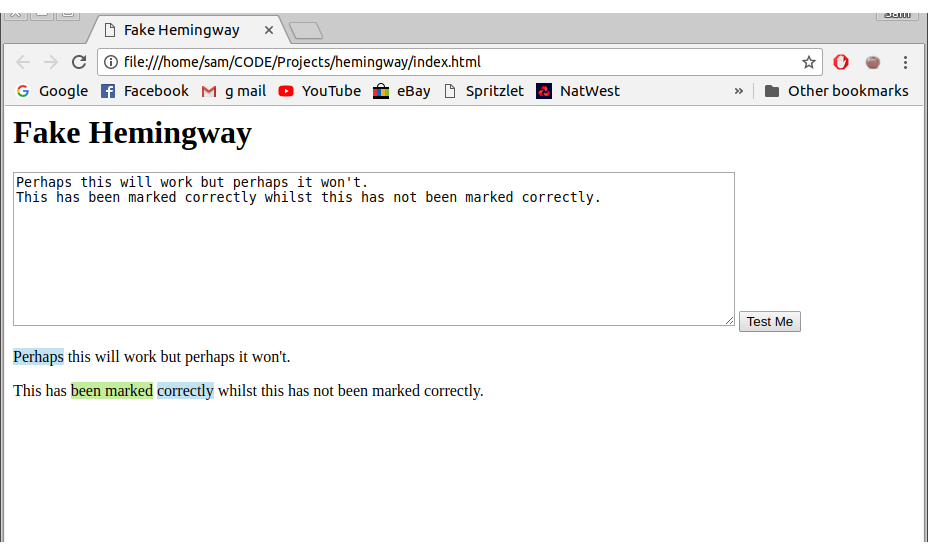 Code with bugs in
Code with bugs in
‘Perhaps’ and ‘been marked’ should have been highlighted twice each but they aren’t.
To fix the bug in getQualifier and getComplex, I decided to use recursion. I created a findAndSpan function which uses .indexOf() to find the first instance of the word or phrase. It splits the sentence into 3 parts: before the phrase, the phrase, after the phrase. The recursion works by passing the ‘after the phrase’ string back into the function. This will continue until there are no more instances of the phrase, where the string will just be passed back.
function findAndSpan(sentence, string, type) {
let index = sentence.toLowerCase().indexOf(key);
if (index >= 0) {
sentence =
sentence.slice(0, index) +
`<span class="${type}">` +
sentence.slice(index, index + key.length) +
"</span>" +
findAndSpan(
sentence.slice(index + key.length),
key,
type);
}
return sentence;
}
Something very similar had to be done for the passive voice. The recursion was in an almost identical pattern, passing the leftover array items instead of the leftover string. The result of the recursion call was spread into an array that was then returned. Now the app can deal with repeated adverbs, qualifiers, complex phrases and passive voice uses.
Statistics Counter
The last thing that I wanted to get working was the nice line of boxes informing you on how many adverbs or complex words you’d used.
To store the data I created an object with keys for each of the parameters I wanted to count. I started by having this variable as a global variable but knew I would have to change that later.
Now I had to populate the values. This was done by incrementing the value every time it was found.
data.sentences += sentence.length
or
data.adverbs += 1
The values needed to be reset every time the scan was run to make sure that values didn’t continuously increase.
With the values I needed, I had to get them rendering on the screen. I altered the structure of the html file so that the input box and output area were in a div on the left, leaving a right div for the counters. These counters are empty divs with an appropriate id and class as well as a ‘counter’ class.
<div id=”adverb” class=”adverb counter”></div>
<div id=”passive” class=”passive counter”></div>
<div id=”complex” class=”complex counter”></div>
<div id=”hardSentence” class=”hardSentence counter”></div>
<div id=”veryHardSentence” class=”veryHardSentence counter”></div>
With these divs, I used document.querySelector to set the inner html for each of the counters using the data that had been collected. With a little bit of styling of the ‘counter’ class, the web app was complete. Try it out here or look at my code here.
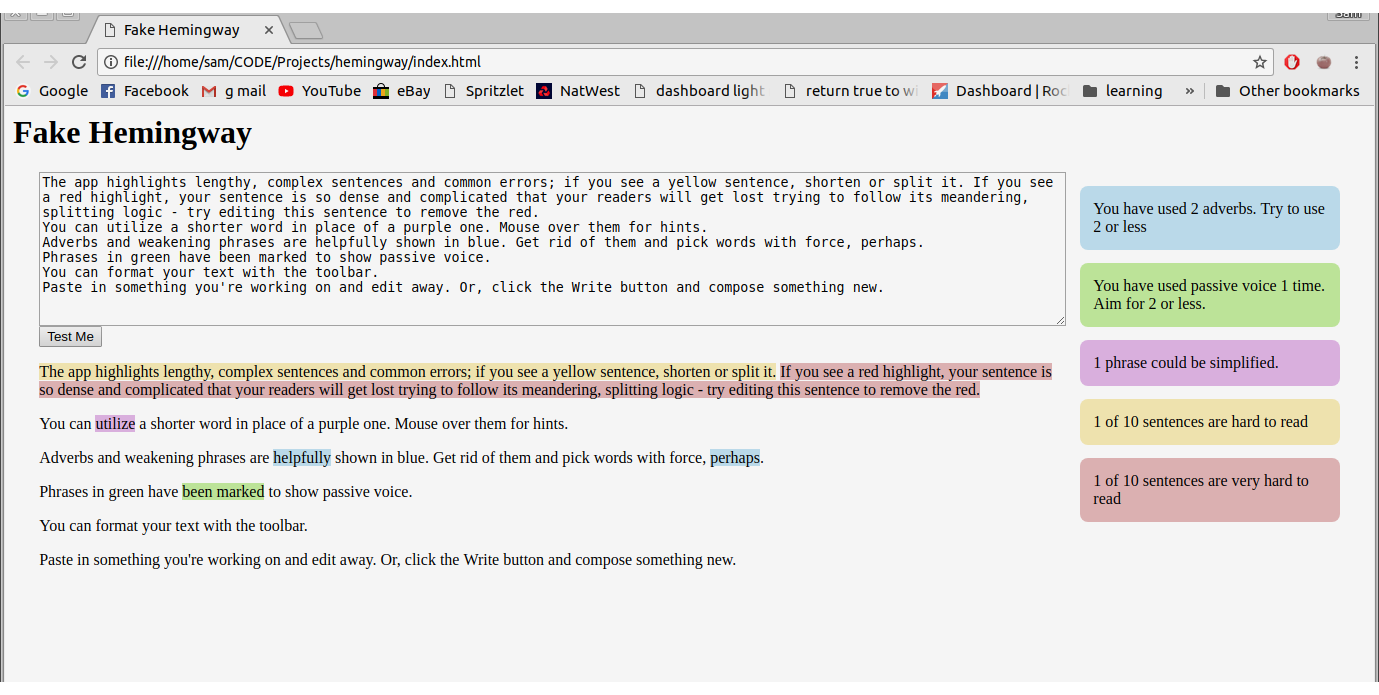 The completed app
The completed app