
By Maxim Mamaev
Let’s take a computational problem as an example, write some code, and see how we can improve the running time. Here we go.
Setting the scene: the knapsack problem
This is the computational problem we’ll use as the example:
The knapsack problem is a well-known problem in combinatorial optimization. In this section, we will review its most common flavor, the 0–1 knapsack problem, and its solution by means of dynamic programming. If you are familiar with the subject, you can skip this part.
You are given a knapsack of capacity C and a collection of N items. Each item has weight w[i] and value v[i]. Your task is to pack the knapsack with the most valuable items. In other words, you are to maximize the total value of items that you put into the knapsack subject, with a constraint: the total weight of the taken items cannot exceed the capacity of the knapsack.
Once you’ve got a solution, the total weight of the items in the knapsack is called “solution weight,” and their total value is the “solution value”.
The problem has many practical applications. For example, you’ve decided to invest $1600 into the famed FAANG stock (the collective name for the shares of Facebook, Amazon, Apple, Netflix, and Google aka Alphabet). Each share has a current market price and the one-year price estimate. As of one day in 2018, they are as follows:
========= ======= ======= =========Company Ticker Price Estimate========= ======= ======= =========Alphabet GOOG 1030 1330Amazon AMZN 1573 1675Apple AAPL 162 193 Facebook FB 174 216 Netflix NFLX 312 327========= ======= ======= =========
For the simplicity of the example, we’ll assume that you’d never put all your eggs in one basket. You are willing to buy no more than one share of each stock. What shares do you buy to maximize your profit?
This is a knapsack problem. Your budget ($1600) is the sack’s capacity (C). The shares are the items to be packed. The current prices are the weights (w). The price estimates are the values. The problem looks trivial. However, the solution is not evident at the first glance — whether you should buy one share of Amazon, or one share of Google plus one each of some combination of Apple, Facebook, or Netflix.
Of course, in this case, you may do quick calculations by hand and arrive at the solution: you should buy Google, Netflix, and Facebook. This way you spend $1516 and expect to gain $1873.
Now you believe that you’ve discovered a Klondike. You shatter your piggy bank and collect $10,000. Despite your excitement, you stay adamant with the rule “one stock — one buy”. Therefore, with that larger budget, you have to broaden your options. You decide to consider all stocks from the NASDAQ 100 list as candidates for buying.
The future has never been brighter, but suddenly you realize that, in order to identify your ideal investment portfolio, you will have to check around 2¹⁰⁰ combinations. Even if you are super optimistic about the imminence and the ubiquity of the digital economy, any economy requires — at the least — a universe where it runs. Unfortunately, in a few trillion years when your computation ends, our universe won’t probably exist.
Dynamic programming algorithm
We have to drop the brute force approach and program some clever solution. Small knapsack problems (and ours is a small one, believe it or not) are solved by dynamic programming. The basic idea is to start from a trivial problem whose solution we know and then add complexity step-by-step.
If you find the following explanations too abstract, here is an annotated illustration of the solution to a very small knapsack problem. This will help you visualize what is happening.
Assume that, given the first i items of the collection, we know the solution values s(i, k) for all knapsack capacities k in the range from 0 to C.
In other words, we sewed C+1 “auxiliary” knapsacks of all sizes from 0 to C. Then we sorted our collection, took the first i item and temporarily put aside all the rest. And now we assume that, by some magic, we know how to optimally pack each of the sacks from this working set of i items. The items that we pick from the working set may be different for different sacks, but at the moment we are not interested what items we take or skip. It is only the solution value s(i, k) that we record for each of our newly sewn sacks.
Now we fetch the next, (i+1)th, item from the collection and add it to the working set. Let’s find solution values for all auxiliary knapsacks with this new working set. In other words, we find s(i+1, k) for all k=0..C given s(i, k).
If k is less than the weight of the new item w[i+1], we cannot take this item. Indeed, even if we took only this item, it alone would not fit into the knapsack. Therefore, s(i+1, k) = s(i, k) for all k < w[i+1].
For the values k >= w[i+1] we have to make a choice: either we take the new item into the knapsack of capacity k or we skip it. We need to evaluate these two options to determine which one gives us more value packed into the sack.
If we take the (i+1)th item, we acquire the value v[i+1] and consume the part of the knapsack’s capacity to accommodate the weight w[i+1]. That leaves us with the capacity k–w[i+1] which we have to optimally fill using (some of) the first i items. This optimal filling has the solution value s(i, k–w[i+1]). This number is already known to us because, by assumption, we know all solution values for the working set of i items. Hence, the candidate solution value for the knapsack k with the item i+1 taken would be
s(i+1, k | i+1 taken) = v[i+1] + s(i, k–w[i+1]).
The other option is to skip the item i+1. In this case, nothing changes in our knapsack, and the candidate solution value would be the same as s(i, k).
To decide on the best choice we compare the two candidates for the solution values:
s(i+1, k | i+1 taken) = v[i+1] + s(i, k–w[i+1])
s(i+1, k | i+1 skipped) = s(i, k)
The maximum of these becomes the solution s(i+1, k).
In summary:
if k < w[i+1]: s(i+1, k) = s(i, k)else: s(i+1, k) = max( v[i+1] + s(i, k-w[i+1]), s(i, k) )
Now we can solve the knapsack problem step-by-step. We start with the empty working set (i=0). Obviously, s(0, k) = 0 for any k. Then we take steps by adding items to the working set and finding solution values s(i, k) until we arrive at s(i+1=N, k=C) which is the solution value of the original problem.
Note that, by the way of doing this, we have built the grid of NxC solution values.
Yet, despite having learned the solution value, we do not know exactly what items have been taken into the knapsack. To find this out, we backtrack the grid. Starting from s(i=N, k=C), we compare s(i, k) with s(i–1, k).
If s(i, k) = s(i–1, k), the ith item has not been taken. We reiterate with i=i–1 keeping the value of k unchanged. Otherwise, the ith item has been taken and for the next examination step we shrink the knapsack by w[i] — we’ve set i=i–1, k=k–w[i].
This way we examine all items from the Nth to the first, and determine which of them have been put into the knapsack. This gives us the solution to the knapsack problem.
Code and analysis
Now, as we have the algorithm, we will compare several implementations, starting from a straightforward one. The code is available on GitHub.
The data is the Nasdaq 100 list, containing current prices and price estimates for one hundred stock equities (as of one day in 2018). Our investment budget is $10,000.
Recall that share prices are not round dollar numbers, but come with cents. Therefore, to get the accurate solution, we have to count everything in cents — we definitely want to avoid float numbers. Hence the capacity of our knapsack is ($)10000 x 100 cents = ($)1000000, and the total size of our problem N x C = 1 000 000.
With an integer taking 4 bytes of memory, we expect that the algorithm will consume roughly 400 MB of RAM. So, the memory is not going to be a limitation. It is the execution time we should care about.
Of course, all our implementations will yield the same solution. For your reference, the investment (the solution weight) is 999930 ($9999.30) and the expected return (the solution value) is 1219475 ($12194.75). The list of stocks to buy is rather long (80 of 100 items). You can obtain it by running the code.
And, please, remember that this is a programming exercise, not investment advice. By the time you read this article, the prices and the estimates will have changed from what is used here as an example.
 _Credit: [Martin von Rotz](https://www.snapwi.re/user/mavoro" rel="noopener" target="blank" title=")
_Credit: [Martin von Rotz](https://www.snapwi.re/user/mavoro" rel="noopener" target="blank" title=")
Plain old “for” loops
The straightforward implementation of the algorithm is given below.
There are two parts.
In the first part (lines 3–7 above), two nested for loops are used to build the solution grid.
The outer loop adds items to the working set until we reach N (the value of N is passed in the parameter items). The row of solution values for each new working set is initialized with the values computed for the previous working set.
The inner loop for each working set iterates the values of k from the weight of the newly added item to C (the value of C is passed in the parameter capacity).
Note that we do not need to start the loop from k=0. When k is less than the weight of item, the solution values are always the same as those computed for the previous working set, and these numbers have been already copied to the current row by initialisation.
When the loops are completed, we have the solution grid and the solution value.
The second part (lines 9–17) is a single for loop of N iterations. It backtracks the grid to find what items have been taken into the knapsack.
Further on, we will focus exclusively on the first part of the algorithm as it has O(N*C) time and space complexity. The backtracking part requires just O(N) time and does not spend any additional memory — its resource consumption is relatively negligible.
It takes 180 seconds for the straightforward implementation to solve the Nasdaq 100 knapsack problem on my computer.
How bad is it? On the one hand, with the speeds of the modern age, we are not used to spending three minutes waiting for a computer to do stuff. On the other hand, the size of the problem — a hundred million — looks indeed intimidating, so, maybe, three minutes are ok?
To obtain some benchmark, let’s program the same algorithm in another language. We need a statically-typed compiled language to ensure the speed of computation. No, not C. It is not fancy. We’ll stick to fashion and write in Go:
As you can see, the Go code is quite similar to that in Python. I even copy-pasted one line, the longest, as is.
What is the running time? 400 milliseconds! In other words, Python came out 500 times slower than Go. The gap will probably be even bigger if we tried it in C. This is definitely a disaster for Python.
 _Quote from J. K. Rowling’s “Harry Potter and the Chamber of Secrets” [Source of original image here](https://pixabay.com/en/snail-rainy-day-spring-animal-slow-3385348/" rel="noopener" target="blank" title=").
_Quote from J. K. Rowling’s “Harry Potter and the Chamber of Secrets” [Source of original image here](https://pixabay.com/en/snail-rainy-day-spring-animal-slow-3385348/" rel="noopener" target="blank" title=").
To find out what slows down the Python code, let’s run it with line profiler. You can find profiler’s output for this and subsequent implementations of the algorithm at GitHub.
In the straightforward solver, 99.7% of the running time is spent in two lines. These two lines comprise the inner loop, that is executed 98 million times:
I apologize for the excessively long lines, but the line profiler cannot properly handle line breaks within the same statement.
I’ve heard that Python’s for operator is slow but, interestingly, the most time is spent not in the for line but in the loop’s body.
We can break down the loop’s body into individual operations to see if any particular operation is too slow:
It appears that no particular operation stands out. The running times of individual operations within the inner loop are pretty much the same as the running times of analogous operations elsewhere in the code.
Note how breaking the code down increased the total running time. The inner loop now takes 99.9% of the running time. The dumber your Python code, the slower it gets. Interesting, isn’t it?
Built-in map function
Let’s make the code more optimised and replace the inner for loop with a built-in map() function:
The execution time of this code is 102 seconds, being 78 seconds off the straightforward implementation’s score. Indeed, map() runs noticeably, but not overwhelmingly, faster.
List comprehension
You may have noticed that each run of the inner loop produces a list (which is added to the solution grid as a new row). The Pythonic way of creating lists is, of course, list comprehension. Let’s try it instead of map().
This finished in 81 seconds. We’ve achieved another improvement and cut the running time by half in comparison to the straightforward implementation (180 sec). Out of the context, this would be praised as significant progress. Alas, we are still light years away from our benchmark 0.4 sec.
NumPy arrays
At last, we have exhausted built-in Python tools. Yes, I can hear the roar of the audience chanting “NumPy! NumPy!” But to appreciate NumPy’s efficiency, we should have put it into context by trying for, map() and list comprehension beforehand.
Ok, now it is NumPy time. So, we abandon lists and put our data into numpy arrays:
Suddenly, the result is discouraging. This code runs 1.5 times slower than the vanilla list comprehension solver (123 sec versus 81 sec). How can that be?
Let’s examine the line profiles for both solvers.
Initialization of grid[0] as a numpy array (line 274) is three times faster than when it is a Python list (line 245). Inside the outer loop, initialization of grid[item+1] is 4.5 times faster for a NumPy array (line 276) than for a list (line 248). So far, so good.
However, the execution of line 279 is 1.5 times slower than its numpy-less analog in line 252. The problem is that list comprehension creates a list of values, but we store these values in a NumPy array which is found on the left side of the expression. Hence, this line implicitly adds an overhead of converting a list into a NumPy array. With line 279 accounting for 99.9% of the running time, all the previously noted advantages of numpy become negligible.
But we still need a means to iterate through arrays in order to do the calculations. We have already learned that list comprehension is the fastest iteration tool. (By the way, if you try to build NumPy arrays within a plain old for loop avoiding list-to-NumPy-array conversion, you’ll get the whopping 295 sec running time.) So, are we stuck and is NumPy of no use? Of course, not.
 _Credit: [Taras Makarenko](https://www.pexels.com/@taras-makarenko-188506" rel="noopener" target="blank" title=")
_Credit: [Taras Makarenko](https://www.pexels.com/@taras-makarenko-188506" rel="noopener" target="blank" title=")
Proper use of NumPy
Just storing data in NumPy arrays does not do the trick. The real power of NumPy comes with the functions that run calculations over NumPy arrays. They take arrays as parameters and return arrays as results.
For example, there is function where() which takes three arrays as parameters: condition, x, and y, and returns an array built by picking elements either from x or from y. The first parameter, condition, is an array of booleans. It tells where to pick from: if an element of condition is evaluated to True, the corresponding element of x is sent to the output, otherwise the element from y is taken.
Note that the NumPy function does all this in a single call. Looping through the arrays is put away under the hood.
This is how we use where() as a substitute of the internal for loop in the first solver or, respectively, the list comprehension of the latest:
There are three pieces of code that are interesting: line 8, line 9 and lines 10–13 as numbered above. Together, they substitute for the inner loop which would iterate through all possible sizes of knapsacks to find the solution values.
Until the knapsack’s capacity reaches the weight of the item newly added to the working set (this_weight), we have to ignore this item and set solution values to those of the previous working set. This is pretty straightforward (line 8):
grid[item+1, :this_weight] = grid[item, :this_weight]
Then we build an auxiliary array temp (line 9):
temp = grid[item, :-this_weight] + this_value
This code is analogous to, but much faster than:
[grid[item, k — this_weight] + this_value for k in range(this_weight, capacity+1)]
It calculates would-be solution values if the new item were taken into each of the knapsacks that can accommodate this item.
Note how thetemp array is built by adding a scalar to an array. This is another powerful feature of NumPy called “broadcasting”. When NumPy sees operands with different dimensions, it tries to expand (that is, to “broadcast”) the low-dimensional operand to match the dimensions of the other. In our case, the scalar is expanded to an array of the same size as grid[item, :-this_weight] and these two arrays are added together. As a result, the value of this_value is added to each element of grid[item, :-this_weight]— no loop is needed.
In the next piece (lines 10–13) we use the function where() which does exactly what is required by the algorithm: it compares two would-be solution values for each size of knapsack and selects the one which is larger.
grid[item + 1, this_weight:] = np.where(temp > grid[item, this_weight:], temp, grid[item, this_weight:])
The comparison is done by the condition parameter, which is calculated as temp > grid[item, this_weight:]. This is an element-wise operation that produces an array of boolean values, one for each size of an auxiliary knapsack. A T_r_ue value means that the corresponding item is to be packed into the knapsack. Therefore, the solution value taken from the array is the second argument of the function, temp. Otherwise, the item is to be skipped, and the solution value is copied from the previous row of the grid — the third argument of the where()function .
At last, the warp drive engaged! This solver executes in 0.55 sec. This is 145 times faster than the list comprehension-based solver and 329 times faster than the code using thefor loop. Although we did not outrun the solver written in Go (0.4 sec), we came quite close to it.
Some loops are to stay
Wait, but what about the outer for loop?
In our example, the outer loop code, which is not part of the inner loop, is run only 100 times, so we can get away without tinkering with it. However, other times the outer loop can turn out to be as long as the inner.
Can we rewrite the outer loop using a NumPy function in a similar manner to what we did to the inner loop? The answer is no.
Despite both being for loops, the outer and inner loops are quite different in what they do.
The inner loop produces a 1D-array based on another 1D-array whose elements are all known when the loop starts. It is this prior availability of the input data that allowed us to substitute the inner loop with either map(), list comprehension, or a NumPy function.
The outer loop produces a 2D-array from 1D-arrays whose elements are not known when the loop starts. Moreover, these component arrays are computed by a recursive algorithm: we can find the elements of the (i+1)th array only after we have found the ith.
Suppose the outer loop could be presented as a function:grid = g(row0, row1, … rowN)
All function parameters must be evaluated before the function is called, yet only row0 is known beforehand. Since the computation of the (i+1)th row depends on the availability of the ith, we need a loop going from 1 to N to compute all the row parameters. Therefore, to substitute the outer loop with a function, we need another loop which evaluates the parameters of this function. This other loop is exactly the loop we are trying to replace.
The other way to avoid the outer for loop is to use the recursion. One can easily write the recursive function calculate(i) that produces the ith row of the grid. In order to do the job, the function needs to know the (i-1)th row, thus it calls itself as calculate(i-1) and then computes the ith row using the NumPy functions as we did before. The entire outer loop can then be replaced with calculate(N). To make the picture complete, a recursive knapsack solver can be found in the source code accompanying this article on GitHub.
However, the recursive approach is clearly not scalable. Python is not tail-optimized. The depth of the recursion stack is, by default, limited by the order of one thousand. This limit is surely conservative but, when we require a depth of millions, stack overflow is highly likely. Moreover, the experiment shows that recursion does not even provide a performance advantage over a NumPy-based solver with the outer for loop.
This is where we run out of the tools provided by Python and its libraries (to the best of my knowledge). If you absolutely need to speed up the loop that implements a recursive algorithm, you will have to resort to Cython, or to a JIT-compiled version of Python, or to another language.
Takeaways
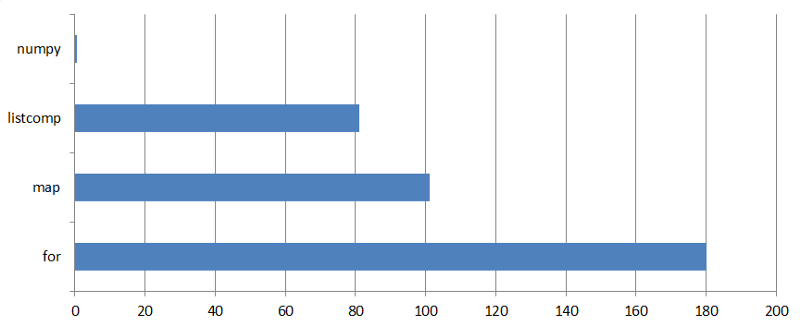 Running times of knapsack problem solvers
Running times of knapsack problem solvers
- Do numerical calculations with NumPy functions. They are two orders of magnitude faster than Python’s built-in tools.
- Of Python’s built-in tools, list comprehension is faster than
map(), which is significantly faster thanfor. - For deeply recursive algorithms, loops are more efficient than recursive function calls.
- You cannot replace recursive loops with
map(), list comprehension, or a NumPy function. - “Dumb” code (broken down into elementary operations) is the slowest. Use built-in functions and tools.