
By Ilya Lyamkin
Today we’ll look under the hood of JavaScript's V8 engine and figure out how exactly JavaScript is executed.
In a previous article we learned how the browser is structured and got a high-level overview of Chromium. Let's recap a bit so we're ready to dive in here.
Background
Web Standards are a set of rules that the browser implements. They define and describe aspects of the World Wide Web.
W3C is an international community that develops open standards for the Web. They make sure that everyone follows the same guidelines and doesn't have to support dozens of completely different environments.
A modern browser is quite a complicated piece of software with a codebase of tens of millions of lines of code. So it's split into a lot of modules responsible for different logic.
And two of the most important parts of a browser are the JavaScript engine and a rendering engine.
Blink is a rendering engine that is responsible for the whole rendering pipeline including DOM trees, styles, events, and V8 integration. It parses the DOM tree, resolves styles, and determines the visual geometry of all the elements.
While continually monitoring dynamic changes via animation frames, Blink paints the content on your screen. The JS engine is a big part of the browser – but we haven't gotten into those details yet.
JavaScript Engine 101
The JavaScript engine executes and compiles JavaScript into native machine code. Every major browser has developed its own JS engine: Google's Chrome uses V8, Safari uses JavaScriptCore, and Firefox uses SpiderMonkey.
We’ll work particularly with V8 because of its use in Node.js and Electron, but other engines are built in the same way.
Each step will include a link to the code responsible for it, so you can get familiar with the codebase and continue the research beyond this article.
We will work with a mirror of V8 on GitHub as it provides a convenient and well-known UI to navigate the codebase.
Preparing the source code
The first thing V8 needs to do is to download the source code. This can be done via a network, cache, or service workers.
Once the code is received, we need to change it in a way that the compiler can understand. This process is called parsing and consists of two parts: the scanner and the parser itself.
The scanner takes the JS file and converts it to the list of known tokens. There's a list of all JS tokens in the keywords.txt file.
The parser picks it up and creates an Abstract Syntax Tree (AST): a tree representation of the source code. Each node of the tree denotes a construct occurring in the code.
Let’s have a look at a simple example:
function foo() {
let bar = 1;
return bar;
}
This code will produce the following tree structure:
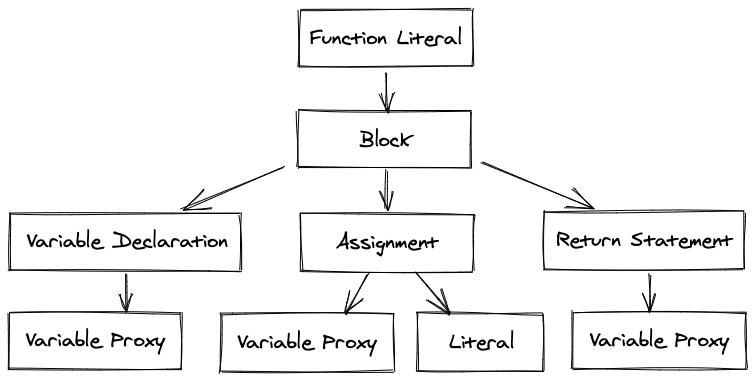 Example of AST tree
Example of AST tree
You can execute this code by executing a preorder traversal (root, left, right):
- Define the
foofunction. - Declare the
barvariable. - Assign
1tobar. - Return
barout of the function.
You will also see VariableProxy — an element that connects the abstract variable to a place in memory. The process of resolving VariableProxy is called Scope Analysis.
In our example, the result of the process would be all VariableProxys pointing to the same bar variable.
The Just-in-Time (JIT) paradigm
Generally, for your code to execute, the programming language needs to be transformed into machine code. There are several approaches to how and when this transformation can happen.
The most common way of transforming the code is by performing ahead-of-time compilation. It works exactly as it sounds: the code is transformed into machine code before the execution of your program during the compilation stage.
This approach is used by many programming languages such as C++, Java, and others.
On the other side of the table, we have interpretation: each line of the code will be executed at runtime. This approach is usually taken by dynamically typed languages like JavaScript and Python because it’s impossible to know the exact type before execution.
Because ahead-of-time compilation can assess all the code together, it can provide better optimization and eventually produce more performant code. Interpretation, on the other side, is simpler to implement, but it’s usually slower than the compiled option.
To transform the code faster and more effectively for dynamic languages, a new approach was created called Just-in-Time (JIT) compilation. It combines the best from interpretation and compilation.
While using interpretation as a base method, V8 can detect functions that are used more frequently than others and compile them using type information from previous executions.
However, there is a chance that the type might change. We need to de-optimize compiled code and fallback to interpretation instead (after that, we can recompile the function after getting new type feedback).
Let's explore each part of JIT compilation in more detail.
Interpreter
V8 uses an interpreter called Ignition. Initially, it takes an abstract syntax tree and generates byte code.
Byte code instructions also have metadata, such as source line positions for future debugging. Generally, byte code instructions match the JS abstractions.
Now let's take our example and generate byte code for it manually:
LdaSmi #1 // write 1 to accumulator
Star r0 // read to r0 (bar) from accumulator
Ldar r0 // write from r0 (bar) to accumulator
Return // returns accumulator
Ignition has something called an accumulator — a place where you can store/read values.
The accumulator avoids the need for pushing and popping the top of the stack. It’s also an implicit argument for many byte codes and typically holds the result of the operation. Return implicitly returns the accumulator.
You can check out all the available byte code in the corresponding source code. If you’re interested in how other JS concepts (like loops and async/await) are presented in byte code, I find it useful to read through these test expectations.
Execution
After the generation, Ignition will interpret the instructions using a table of handlers keyed by the byte code. For each byte code, Ignition can look up corresponding handler functions and execute them with the provided arguments.
As we mentioned before, the execution stage also provides the type feedback about the code. Let’s figure out how it’s collected and managed.
First, we should discuss how JavaScript objects can be represented in memory. In a naive approach, we can create a dictionary for each object and link it to the memory.
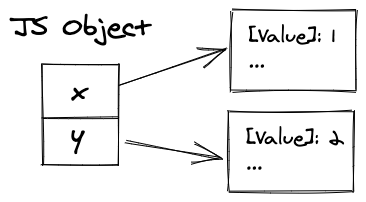 The first approach for keeping the object
The first approach for keeping the object
However, we usually have a lot of objects with the same structure, so it would not be efficient to store lots of duplicated dictionaries.
To solve this issue, V8 separates the object's structure from the values itself with Object Shapes (or Maps internally) and a vector of values in memory.
For example, we create an object literal:
let c = { x: 3 }
let d = { x: 5 }
c.y = 4
In the first line, it will produce a shape Map[c] that has the property x with an offset 0.
In the second line, V8 will reuse the same shape for a new variable.
After the third line, it will create a new shape Map[c1] for property y with an offset 1 and create a link to the previous shape Map[c] .
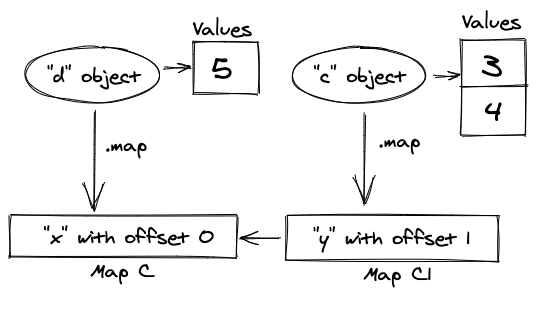 Example of object shapes
Example of object shapes
In the example above, you can see that each object can have a link to the object shape where for each property name, V8 can find an offset for the value in memory.
Object shapes are essentially linked lists. So if you write c.x, V8 will go to the head of the list, find y there, move to the connected shape, and finally it gets x and reads the offset from it. Then it’ll go to the memory vector and return the first element from it.
As you can imagine, in a big web app you’ll see a huge number of connected shapes. At the same time, it takes linear time to search through the linked list, making property lookups a really expensive operation.
To solve this problem in V8, you can use the Inline Cache (IC). It memorizes information on where to find properties on objects to reduce the number of lookups.
You can think about it as a listening site in your code: it tracks all CALL, STORE, and LOAD events within a function and records all shapes passing by.
The data structure for keeping IC is called Feedback Vector. It’s just an array to keep all ICs for the function.
function load(a) {
return a.key;
}
For the function above, the feedback vector will look like this:
[{ slot: 0, icType: LOAD, value: UNINIT }]
It’s a simple function with only one IC that has a type of LOAD and value of UNINIT. This means it’s uninitialized, and we don’t know what will happen next.
Let’s call this function with different arguments and see how Inline Cache will change.
let first = { key: 'first' } // shape A
let fast = { key: 'fast' } // the same shape A
let slow = { foo: 'slow' } // new shape B
load(first)
load(fast)
load(slow)
After the first call of the load function, our inline cache will get an updated value:
[{ slot: 0, icType: LOAD, value: MONO(A) }]
That value now becomes monomorphic, which means this cache can only resolve to shape A.
After the second call, V8 will check the IC's value and it'll see that it’s monomorphic and has the same shape as the fast variable. So it will quickly return offset and resolve it.
The third time, the shape is different from the stored one. So V8 will manually resolve it and update the value to a polymorphic state with an array of two possible shapes.
[{ slot: 0, icType: LOAD, value: POLY[A,B] }]
Now every time we call this function, V8 needs to check not only one shape but iterate over several possibilities.
For the faster code, you can initialize objects with the same type and not change their structure too much.
Note: You can keep this in mind, but don’t do it if it leads to code duplication or less expressive code.
Inline caches also keep track of how often they're called to decide if it’s a good candidate for optimizing the compiler — Turbofan.
Compiler
Ignition only gets us so far. If a function gets hot enough, it will be optimized in the compiler, Turbofan, to make it faster.
Turbofan takes byte code from Ignition and type feedback (the Feedback Vector) for the function, applies a set of reductions based on it, and produces machine code.
As we saw before, type feedback doesn’t guarantee that it won’t change in the future.
For example, Turbofan optimized code based on the assumption that some addition always adds integers.
But what would happen if it received a string? This process is called deoptimization. We throw away optimized code, go back to interpreted code, resume execution, and update type feedback.
Summary
In this article, we discussed JS engine implementation and the exact steps of how JavaScript is executed.
To summarize, let’s have a look at the compilation pipeline from the top.
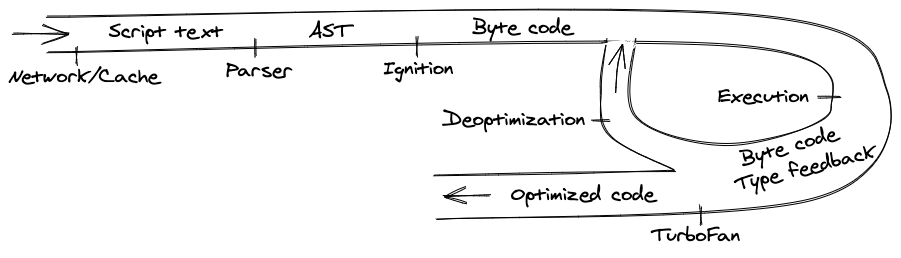 V8 overview
V8 overview
We’ll go over it step by step:
- It all starts with getting JavaScript code from the network.
- V8 parses the source code and turns it into an Abstract Syntax Tree (AST).
- Based on that AST, the Ignition interpreter can start to do its thing and produce bytecode.
- At that point, the engine starts running the code and collecting type feedback.
- To make it run faster, the byte code can be sent to the optimizing compiler along with feedback data. The optimizing compiler makes certain assumptions based on it and then produces highly-optimized machine code.
- If, at some point, one of the assumptions turns out to be incorrect, the optimizing compiler de-optimizes and goes back to the interpreter.
That’s it! If you have any questions about a specific stage or want to know more details about it, you can dive into source code or hit me up on Twitter.
Further reading
- “Life of a script” video from Google
- A crash course in JIT compilers from Mozilla
- Nice explanation of Inline Caches in V8
- Great dive in Object Shapes