
This article is intended to be an introductory guide to the fundamentals of software engineering.
I have written it with the assumption that you, dear reader, may not know much about the basics of the field, why they are important, and when you should bother to learn them.
We shall go into each of these questions and finish by discussing some ways in which I recommend you learn and approach them.
For those who do happen to be familiar with this subject, there may still be some interesting new perspectives, and particularly in the last section, useful ways to speed up your learning process.
In this article we will discuss:
What made software engineering spooky and intimidating for me, and how that changed
The reason for, and metrics by which we look at some code and conclude that it is less efficient than another approach (computational complexity)
A simple but hopefully useful introduction to Data Structures and Algorithms
The things I personally do to learn topics in software engineering for maximum efficiency and understanding
A way to motivate your efforts by adding in some basic tests to measure correctness and efficiency of your algorithms
Please be aware that I have tried to structure this article in a logical progression where each section (apart from the next which is more about getting over the fear of diving into this subject) builds upon or motivates the next.
I am condensing over a thousand hours of practice and study into one article, and have done my best to explain things clearly and simply as well.

Photo by [Unsplash](https://unsplash.com/@thisisengineering?utm_source=ghost&utm_medium=referral&utm_campaign=api-credit">ThisisEngineering RAEng / <a href="https://unsplash.com/?utm_source=ghost&utm_medium=referral&utm_campaign=api-credit)
Where The Problems Began
Throughout my limited formal education, I did not have the best relationship with the field of mathematics. And by extension, this impacted my relationship with a great deal of computer science (CS) and software engineering (SEng).
To be specific, it is not that I am bad at math, but I am poor at arithmetic and bad at remembering formulae.
I also found that the way in which mathematics, CS, and SEng are usually taught in schools does not tend to work for me either.
My own learning process to this day is largely driven by pragmatism (emphasis on practical over theoretical knowledge), curiosity about nature, and how this information can help me earn a living – three things I saw rarely emphasized in my western education.
Apart from my uneasy relationship with dry and boring presentations of things which are predominantly of a mathematical nature, I am a self-taught programmer.
To be clear, I took a single programming class at a community college (circa 2013), and the rest of my knowledge comes from self-directed studies. During my early years of that process, I also had to work various day jobs in order to pay the rent, which left me very little spare time and energy to learn my craft.
The end result was that I chose to spend most of my time building personal projects and learning topics specifically for those projects.
This led to me being really quite good at the skill of writing code, learning new technologies, and solving problems. However, if I did apply any concepts in CS and SEng to the code I was writing, it was largely by accident.
To summarize this introduction, I am trying to say that the biggest obstacle in my study of SEng was that I just was not very interested in learning it.
I did not know the sense of accomplishment you can get from making a small change to an algorithm which reduces its runtime to completion by a factor of tens or hundreds of times.
I did not know how important it was to pick a data structure based on the nature of the problem I was trying to solve, let alone how to make that decision.
And I had no idea how it was relevant to me slinging mobile apps for a living.
So just in case you are in the same boat, before we get to the technical details, I would like to attempt to answer some of those questions for you. To make things less boring, I will motivate this topic by sharing a true story about what changed my attitude towards this subject.
Swimming With the Big Fish
Towards the end of 2019, I had taken a break from studying Android Development in order to take a deep dive into UNIX Operating Systems and C/C++ programming.
I felt very comfortable with the Android SDK, but many years of JVM programming had left me with a strong sense of having no idea how computers actually worked under the hood. Which bothered me quite a bit.
I was not really looking for work, but at the time a recruiter from a big tech company had reached out to me about my interest in an Android Software Engineer position.
Despite being many months out of practice with Android, I did well in the first interview (it was all core Android concepts that I was familiar with) and was sent an email detailing the topics to be covered in future interviews.
The first section of this email, which detailed Android specific knowledge, was extensive, but I was at least somewhat familiar which most topics and not intimidated. However, when I scrolled down to the section on Data Structures and Algorithms, I suddenly felt like I did when I first started writing code: Like a fish out of water.
It is not that I had never applied any of these concepts in my code, but I certainly had not formally studied any of them.
Although I will do my best to give you a soft and clear introduction to these topics, SEng will immediately hit you with a wall of jargon terms, and my face was figuratively very sore and bruised after reading the entire list of DS and Algos I had to learn in that email.
I was very up front about that with my recruiter, who kindly gave me four weeks to prepare before the next interview.
I knew I could not cover every topic in four weeks, but I did hope that learning a year or two of SEng in a few weeks would show some talent and initiative.
I would love to tell you a juicy story about how I epically failed, or completely dazzled in the next interview, but the reality is that things fell apart before I even got the chance.
I am a Canadian citizen, and the position required relocation to one of many campuses in the United States, in either California or Washington State.
Two weeks into my first deep dive into SEng, I received an email from my recruiter stating that their immigration department did not want to sponsor me. I suspect it had to do with some difficulties around sponsoring a worker who had no degree, but the brewing global pandemic may also have been a factor.
In the end, even though I wanted the chance to succeed or fail in real time, I was happy knowing that I had a very clear idea of the knowledge I was lacking to be a software engineer in a big tech company.
With a clear but difficult path in front of me, I resolved to no longer let the field of SEng intimidate me. I wanted to know what it truly means to be a software developer versus a software engineer.
With that in mind, we shall go into the core ideas in SEng, and how to make the learning of them easier. Not easy – just easier.
The "Big Three" Topics in Software Engineering –And Why They Matter
The main topics in software engineering can be summarized using a bunch of big scary words and phrases – as is the tradition in anything related to computer science and mathematics. To avoid confusion, I will instead explain them using the English language and examples which prioritize clarity above all else.
I suggest you follow this section in the order I have laid out, as I have deliberately structured it in a logical progression.
First - What Are Runtime And Memory Space?
I want to start off by explaining the reason why we study these topics to begin with.
Being a fan of physics, I was happy to learn that the interplay of time and space which we see in nature is also directly observed in any kind of computer.
However, in this field, we refer to these qualities as runtime and memory space.
To better understand what runtime is, I suggest you pull up your Task Manager, Activity Monitor, or whatever program you have that tells you about your system’s active “processes.”
A process is just a “running program,” and through the magic of having multiple “processors”, CPU virtualization, and time slicing, it can appear that we have tens or hundreds of processes running at the same time.
I threw those jargon terms in so that you can look them up if you are curious about how operating systems work, but doing so it is not necessary to proceed with this article.
In any case, a process’s runtime can generally be thought of as any point in time during which it can be viewed in your system’s process tracking tool.
I use this definition to point out that an active process does not need to have a user interface or even do anything useful even though it may still be taking up runtime in the CPU and memory space.
Speaking of memory space, in order for something to have run time, it has to be somewhere too. That somewhere is the physical memory space of the computer, which is virtualized (again, look up virtualization on your own time but it is not necessary for this article) in order to make it more secure and easier to use.
Every process is allocated its own distinct and protected virtual memory space, which can grow or shrink up to certain boundaries and depending on various factors.
Let us take a break from theory to talk about why we should care about it. Since runtime and memory space can be accurately measured but are also limited, humans like you and I can really screw things up if we do not pay attention to these limitations!
To be clear, here are two very important things we want to care about as programmers and engineers:
Will our program or even the whole system crash because we have mismanaged the finite resource of memory space?
Will our programs solve problems for our users in a timely and efficient manner, or will they hang so long that our users decide to force quit, demand a refund, and leave a nasty review?
These question largely dictate the success of our programs whether you formally study them or not. With any luck I have motivated you to learn what I call the big three topics in software engineering, which we shall go into now.
How We Measure Runtime And Memory Space
The first of the big three topics is described using a big scary term: Asymptotic Runtime & Space Complexity.
Having already described runtime and memory space, I think a serviceable replacement for the word complexity here is “efficiency." And asymptotic is related to the fact that we can represent this efficiency (or lack thereof) on a two dimensional Cartesian Graph. You know, x and y, rise over run, and all that stuff.
Do not worry if you are unfamiliar with this stuff. You only need a very basic understanding of these things to apply it in your code.
Also, note that there is such a thing as a Graph data structure, but that concept is far removed from a Cartesian Graph and not what I am referring to.
Since we can represent our code and how it behaves with respect to either runtime or memory space on a Cartesian Graph, it follows that there must be functions which describe how to draw such a graph.
The way in which we describe how efficient our code in this way is to use “Big O” notation.
Here is the simplest introduction I can give you in order to understand this topic. I will use the modern programming language Kotlin for my code samples which will hopefully provide a happy middle ground for you web and native developers.
Suppose three functions (also sometimes known as methods, algorithms, commands, or procedures):
Function printStatement:
fun printStatement(){
//print to the system or program’s textual output stream/console
println(“Hello World!”)
}
Function printArray:
fun printArray(arr: Array<String>){
//if 'arr' was {“Hello”, “World!”} then the output of this function would be:
//Hello
//World!
arr.forEach { string ->
// "string" is a temporary reference given to each element of 'arr'
println(string)
}
}
Function printArraySums:
fun printArraySums(arrOne: Array<Int>, arrTwo: Array<Int>){
//Prints the sum of every value in both Arrays
arrOne.forEach { aInt ->
arrTwo.forEach { bInt ->
println(aInt + bInt)
}
}
}
For ease of understanding, suppose that every time println(...) is called, it takes 100ms, or 1/10th of a second on average to complete (in reality 100ms for a single print command is terribly slow but it's easier to imagine than a microsecond or picosecond).
With that in mind, let us think critically about how these functions can be expected to behave differently, based on what inputs they are given.
printStatement, barring anything other than a catastrophic failure of the system itself, will always take an average time of 100ms to complete.
In fact, while Big O notation is very concerned about the size of the arguments given to a function (that will make more sense shortly), this function does not even have any arguments to change its behaviour.
Therefore, we can say that the runtime complexity (time taken until completion), is constant, which can be represented by the following mathematical function and graph:
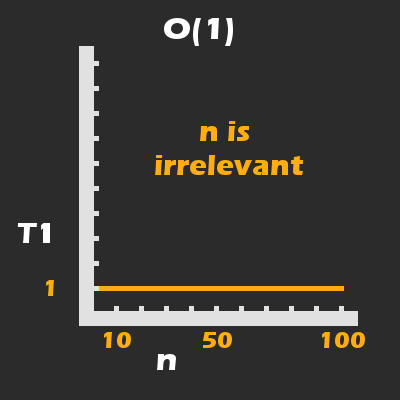
The runtime (T) for printStatement is always an average of 100 milliseconds and is therefore constant.
In the above graphic, T represents the runtime for println(...) which we established to be an average of 100 milliseconds. I will explain what n refers to momentarily.
printArray presents a new problem. It stands to reason that the time it takes for printArray to complete will be directly proportionate to the size of the Array, arr, which is passed into it.
If the Array has four elements, that would result in println(...) being called four times, for a total average runtime of 400ms for printArray itself. To be more mathematically precise, we would say that the runtime complexity of printArray is linear:
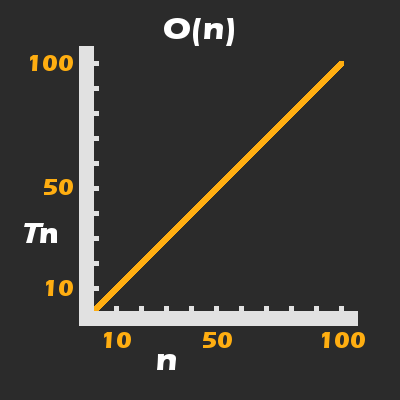
The number of times println(...) is called, is directly proportionate (i.e. grows linearly) with respect to n.
printArraySums takes things a step further into something which you should be concerned about even as a junior or intermediate level developer. The number of arguments/inputs to any given function is referred to with a small n, when using Big O notation.
In our second function, this refers exclusively to the size of the Array (that is, arr.size), but in the third function it refers to the collective size of multiple arguments (that is, arrOne and arrTwo).
In Big O notation, there are actually three different qualities of a given piece of code that we can pay attention to:
How efficient is the code if n is small (best-case performance)?
How efficient is the code if n is of an average expected size (average performance)?
How efficient is the code if n is near or at the its maximum allowable value for the system (worst-case performance)?
Generally speaking, in the same sense that a civil engineer is most concerned about the maximum number of vehicles a bridge can support, a software engineer is usually most concerned about worst-case performance.
By looking at printArraySums, you should be able to reason that we can represent its worst-case runtime complexity (the number of times println(...) will be called) as n \ n; where n* is at or near to the maximum allowable size of an Array in the system.
In case it is not clear, we are not just pairing and summing the elements of arrOne and arrTwo at the same indexes, we are literally summing every value of them together in a nested loop.
From here you can start to truly understand the importance of asymptotic runtime and space complexity. In a worst-case scenario, the runtime grows exponentially in a quadratic curve:
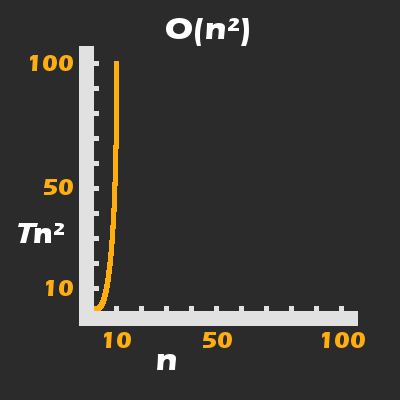
printArraySums(...) has its runtime grow in a quadratic curve. For T = 100ms, n does not even need to be that large to result in a bad user experience.
Two final notes on this topic: Firstly, if I suddenly made you a bit fearful of nested loops (and yes, each nested loop potentially adds another factor of n), then I have done a good job.
Even so, understand that if you are certain that n will not exceed a reasonable size even in a function which has exponential growth, then there is not actually a problem.
If you would like to know how to determine if n will have a negative impact on performance, stick around for the last section of this article.
Secondly, you may have noticed that all of my examples were about runtime complexity, not memory space complexity.
The reason for this is simple: We represent space complexity in exactly the same manner and notation. Since we do not actually allocate any new memory apart from a temporary reference or two within each frame of the forEach{...} loops, asymptotically speaking, the second and third functions are still linear, O(n), with respect to memory allocation.
Data Structures
The term Data Structure, despite what any single teacher may tell you, does not have a singular definition.
Some teachers will emphasize their abstract nature and how we can represent them in mathematics, some teachers will emphasize how they are physically arranged in memory space, and some will emphasize how they are implemented in a particular language specification.
I hate to tell you this, but this is actually a very common problem in computer science and engineering: One word meaning many things and many words meaning one thing, all at the same time.
Therefore, rather than trying to make every kind of expert from every kind of academic or professional background happy by using a plethora of technical definitions, let me upset everyone equally by explaining things as clearly as I can in plain English.
For the purposes of this article, Data Structures (DS) refer to the ways in which we represent and group together our application’s data in our programs. Things like user profiles, friends lists, social networks, game states, high scores and so on.
When considering DS from the physical perspective of the hardware and operating system, there are two main ways to build a DS. Both ways take advantage of the fact that physical memory is discrete (a fancy word for countable), and therefore addressable.
An easy way to imagine this is to think about street addresses and how, depending on which direction you are physically moving (and depending on how your country organizes street addresses), the address increases or decreases in value.
Physical Array
The first way takes advantage of the fact that we can group pieces of data (for example a list of friends in a social media application) into a chunk of contiguous (physically next to each other) memory space.
This turns out to be a very fast and efficient way for a computer to traverse memory space. Instead of giving the computer an n sized list of addresses for each piece of data, we give the computer a single address denoting the start of this DS in physical memory, and the size of (that is, n) the DS as a single value.
The instruction set for doing this could be as simple as telling the machine to move from left to right (or whatever direction), decrement the value of n by 1 each move, and to stop/return when that value hits 0.
Lists Of Links (Addresses)
The second way requires each piece of data in the structure itself to contain the address(es) of the next or previous (maybe both?) item within itself.
One of the big problems with contiguous memory spaces is that they present problems when it comes to growing (adding more elements) or shrinking (this can fragment the memory space, which I will not explain but suggest a quick google search).
By having each piece of data Link to the other pieces (usually just the previous or next one), it becomes largely irrelevant where each piece sits in physical memory space.
Therefore, we can grow or shrink the data structure with relative ease. You should be able to reason that since each part of the structure stores not just its own data, but the address of the next (or more than that) element, then each piece would necessarily require more memory space than with the contiguous Array approach.
However, whether it is ultimately more efficient depends on what kind of problem you are trying to solve.
The two approaches I have discussed are generally known as an Array and a Linked List. With very little exception, most of what we care about in the study of DS is how to group collections of data which have some kind of reason to be grouped together, and how best to do that.
As I tried to point out, what makes one structure better in a certain situation can make it worse in another.
You should be able to reason from the previous few paragraphs that a Linked List is typically more suitable for a dynamic (changing) collection, whereas an Array is typically more suitable for a fixed collection – at least with respect to runtime and space efficiency.
Do not be misled, however! It is not always the case that our primary concern is to pick the most efficient DS (or algorithm) with respect to runtime and memory space. Remember, if n is very small then worrying about a nanosecond or a few bits of memory here and there are not necessarily as important as ease of use and legibility.
The last thing I would like to say about DS is that I have observed a profound lack of consensus about the difference between a DS and a Data Type (DT).
Again, I think this is largely due to different experts approaching this from different backgrounds (mathematics, digital circuits, low level programming, high level programming) and the fact that it is really quite hard to make a verbal definition of one that does not at least partially (or entirely) describe the other.
At the risk of making the situation even more confusing, on a purely practical level_,_ I think of data structures as things which are independent of a high level programming language’s Type System (assuming it has one). On the other hand, a data type is defined by and within such a Type system.
But I know that Type Theory itself is independent of any particular Type system, so you can hopefully see how tricky it is to say anything concrete about these two terms.
Algorithms
I took quite a long time to explain the previous two topics because they allow me to introduce and motivate this topic rather easily.
Before we continue, I must very briefly try to untangle another mess of jargon. To explain the term “algorithm” in my own way, it is actually very simple: An algorithm is a set of instructions (commands) which can be understood and executed (acted upon) by an Information Processing System (IPS).
For example, if you were to follow a recipe to cook something, then you would be the IPS, the algorithm would be the recipe, and the ingredients and cookware would be the data inputs (arguments).
Now, by that definition the words function, method, procedure, operation, program, script, subroutine and algorithm all point to the same underlying concept.
This is not by accident – these words all fundamentally mean the same thing. The confusion is that different computer scientists and language designers will implement (build) the same idea in a slightly different way. Or even more depressingly, they will build them the same way but give a different name. I wish this was not the case, but the best I can do is to warn you.
That is all you need to know about algorithms in general, so let us be more specific about how they can help us to write better code.
Recall that our primary concern as software engineers is to write code which is guaranteed to be efficient (at least such that it keeps our users happy) and safe with respect to limited system resources.
Also recall that I previously stated that some DS perform better than others with respect to runtime and memory space, particularly as n gets large.
The same is true of algorithms. Depending on what you are trying to do, different algorithms will perform better than others.
It is also worth noting that the DS will tend to shape which algorithms can be applied to the problem, so selecting the right DS and the right algorithm is the true art of software engineering.
To finish off this third main topic, we will look at two common but very different ways to solve the one problem: Searching an ordered Array. By ordered, I mean to say that it is ordered something like least to greatest, greatest to least, or even alphabetically.
Also, assume that the algorithm is given some kind of target value as an argument, which is what we use to locate a particular element. This should become clear in the example in case there is any confusion.
The example problem is as follows: We have a collection of Users (perhaps loaded from a database or server), which is sorted from least to greatest by a field called userId, which is an Integer value.
Suppose that this userId comes from taking the system time (look up Unix Time for more info) just prior to creating the new User. Rounded to the smallest value that still guarantees no repeated values.
If that previous sentence did not make sense, all you need to know is that this is a sorted collection with no repeats.
A simple way to write this algorithm would be to write what we will call a Naive Search (NS). Naive, in this context, means simple, but in a bad way, which refers to the fact that we just tell the computer to start from one end of the collection and move to the other until it finds a match to the target index.
This is generally achieved by using some kind of loop:
Function naiveSearch:
//this function accepts an Integer targetId to match against,
// and an Array of User objects as arguments.
// Assume for simplicity's sake that it is guaranteed to find a User.
fun naiveSearch(targetId: Int, a: Array<User>): User {
a.forEach { user ->
if (targetId == user.userId) return user
}
}
If we happen to only have a few hundred, or even a few thousand users in this collection, then we can expect this function to return quite quickly all the same.
But let us assume we are working in a successful social media tech start up, and we have just hit one million users.
You should be able to reason that naiveSearch has O(n) asymptotic complexity as its worst case runtime complexity. The reason in short is that if the target User happens to be located at n, then we must invariably traverse the entire collection to get there.
If you are not already familiar with the Binary Search (BS) algorithm, then you should prepare to have your mind blown.
What if I told you that by using a BS algorithm to search our collection with one million elements, you will only ever make, at most, 20 comparisons? That is right; 20 comparisons (as opposed to 1 million with NS) is the worst case scenario.
Now, I will explain how BS works in principle, but my one piece of homework for you to do is to implement it in your preferred programming language. It may be that the language you choose already has a BS implementation from its standard library, but this is an important learning exercise!
In principle, rather than searching an ordered collection one by one, unidirectionally, we start by looking at the value at index n/2. So in a collection with 10 elements, we would check the fifth element. The ordering is important, because we can then compare the element at n/2 with our target:
If the value of that element is greater than the target, we know that the element we want must be located earlier in the collection
If the value of that element is less than the target, then we know that the element we want must be located further ahead in the collection
You should be able to guess what happens if we have a match
Now, the idea is that we are cutting the dataset in half every iteration. Suppose the value at element n/2 was less than our target value. We would next select the middle index between n/2 and n.
From there, our algorithm keeps slicing back or forth using the same logic over a smaller and smaller range of indexes in our collection.
This brings us to the beauty of the BS algorithm applied to a sorted collection: Rather than the time it takes to complete growing linearly, or exponentially with respect to n, it grows logarithmically:
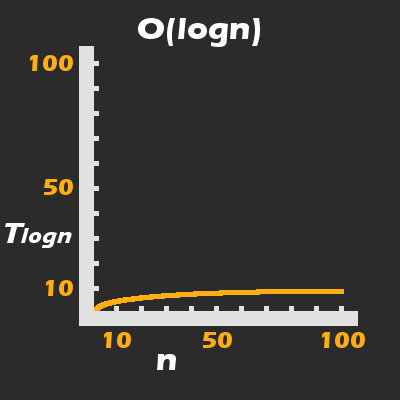
A Binary Search has logarithmic runtime complexity, which means that it handles large values of n like a boss (very well)
If this article really is your first introduction to the main ideas in software engineering, then please do not expect everything to make sense immediately.
While I hope that some of my explanations helped, my primary goal was to give you a basic list of ideas to study yourself, and what I believe to be a good order in which to study those ideas.
The next step for you is to make a plan for learning this field, and to take action on it. The following section is all about how to do that.
How to Learn Software Engineering – Some Practical Advice
I will now discuss some ideas and approaches which I have personally used to make the process of learning various DS and algorithms easier (but not easy!), both practically, and from motivational perspective.
I am confident that there will at least be one or two points here which will be useful (assuming you have not already arrived at them yourself), but I also want to emphasize that our brains might work slightly differently. Take what is useful and throw away the rest.
As a learning aid, you might also want to watch my live lesson on youtube where I cover this topic. Do not skip the rest of this article though; I go into much more detail here!
Follow A Project-Based Learning Approach
This is actually the first thing I tell any new programmer who asks me the “best way” to learn how to code. I have given a longer version of this explanation many times, but I will summarize the general idea.
In any field of programming, you will notice that there is an incredibly large number of topics to study, and the field itself is constantly evolving both for academics and industry professionals.
As I mentioned in the introduction, not only did I have no curriculum to guide my studies, but I also had limited time to study because I had rent due at the end of each month. This led me out of sheer necessity to develop and follow my project based learning approach.
In essence, what I suggest you do is to avoid learning DS & Algorithms by simply studying things topic by topic and just taking notes about each one.
Instead, you will start by picking a basic topic (like the ones I covered before) and immediately writing a code snippet or small application which uses it.
I created a repository which had a package for every family of DS & algorithm that I wanted to learn. For general algorithms it was mostly the sorts and searches (Bubble Sort, Merge Sort, Quick Sort, Binary Search, and so on). For more specific DS like Linked Lists, Trees, Heap, Stack, and others, I wrote both the DS itself and a few algorithms specific to that particular DS.
Now, I found that some kinds of DS were difficult to understand and implement at first.
One family of DS which gave me trouble for quite some time were called “Graphs.” The field in general is full of some particularly awful and overloaded jargon, but this particular topic even has a misleading name (hint: a better name would be “Networks”).
After spinning my wheels for several weeks (although in fairness I was learning this on the side), I finally admitted to myself that I needed a clear reason to use this DS in some application code. Something to justify and motivate the many hours I was going to spend learning this topic.
Having previously built a Sudoku game using algorithms that worked with two and one dimensional Arrays, I recalled reading somewhere that it was possible to represent and solve a Sudoku game using an Undirected Colored Graph.
This was incredibly useful, as I was already familiar with the problem domain of Sudoku, so I could focus intensively on DS and algorithms.
While there is plenty more that I have to learn, I cannot describe how satisfying it was when I wrote an algorithm that generated and solved 102 Sudoku puzzles in 450 milliseconds.
Speaking of, let me talk about another way to write better algorithms which can also be a great source of motivation and goal setting.
Test Your Code
Look, I know many people make the subject of testing a complete nightmare for beginners. This happens because they confuse the very simple idea of how to test code with some very elaborate and confusing tools one can optionally use to test their code. But this one is important so please stay with me.
To go back to basics, without even talking about Big O notation, how do we know if one algorithm is more efficient than another? Of course, we have to test them both.
Now, it is important to mention that benchmark tests can give you a good (or even great) general idea, but they are also strongly influenced by the system in which they are tested.
The more precise your tests need to be, the more concerned you will need to be about your test environment, set up, and accuracy. However, for the kind of code I typically write, a good general idea is all I need.
There are two kinds of tests which I find most useful for when I am writing my algorithms, both for practice and production code. The first kind of test answers a very simple question: Does it work?
To take an example from my Graph Sudoku application, one of the first hurdles for me was to build what is called an Adjacency List for Sudokus of varying sizes (I tested 4, 9, 16, and 25, which are, not by accident, perfect squares (mathematically speaking).
I cannot explain what an Adjacency List is in detail, but think of it conceptually as a Network of nodes and lines (called edges for some reason). In practice, it forms the virtual structure of the “Graph.”
In the rules for Sudoku, every column, row, or subgrid of numbers may not contain any repeats. From these rules, we can deduce that in a 9x9 Sudoku, there must be 81 nodes (one for each number), and each node ought to possess 21 edges (one for every other node in a given column, row, or subgrid).
The first step was to simply check to make sure that I was building the correct number of nodes:
@Test
fun verifyGraphSize() {
//note: In Kotlin, brackets following a class name denotes
//an assignment statement; it does not use a "new" keyword
val fourGraph = SudokuPuzzle(4, Difficulty.MEDIUM)
val nineGraph = SudokuPuzzle(9, Difficulty.MEDIUM)
val sixteenGraph = SudokuPuzzle(16, Difficulty.MEDIUM)
assert(fourGraph.graph.size == 16)
assert(nineGraph.graph.size == 81)
assert(sixteenGraph.graph.size == 256)
}
The algorithm for that was really quite easy to write, but things were slightly more difficult for the next one.
Now I needed to, as they say in Graph jargon, build the edges. This was a bit trickier as I had to write some algorithms to select for rows, columns, and subgrids of dynamic size. Again, to confirm that I was on the right track, I wrote another test:
@Test
fun verifyEdgesBuilt() {
val fourGraph = SudokuPuzzle(4, Difficulty.MEDIUM)
val nineGraph = SudokuPuzzle(9, Difficulty.MEDIUM)
val sixteenGraph = SudokuPuzzle(16, Difficulty.MEDIUM)
fourGraph.graph.forEach {
assert(it.value.size == 8)
}
nineGraph.graph.forEach {
assert(it.value.size == 21)
}
sixteenGraph.graph.forEach {
assert(it.value.size == 40)
}
}
Sometimes I followed the Test Driven Development (TDD) approach and wrote the tests before the algorithms, and sometimes I wrote the tests after the algorithms.
In any case, once I was able to verify the correctness of each algorithm to the point that I was generating a solved, variably sized Sudoku puzzle, it was time to write a different set of tests: Benchmarks!
This particular kind of benchmark testing is quite blunt, but that is all I needed. To test the efficiency of my algorithms, which at this stage could build and solve a randomly generated Sudoku, I wrote a test which generated 101 Sudoku puzzles:
@Test
fun solverBenchmarks() {
//Run the code once to hopefully warm up the JIT
SudokuPuzzle(9, Difficulty.EASY).graph.values.forEach {
assert(it.first.color != 0)
}
//loop 100 times
(1..100).forEach {
SudokuPuzzle(9, Difficulty.EASY)
}
}
Initially I had two calls to System.nanoTime() immediately before and after generating 100 puzzles, and subtracted the difference to get an unintelligible number.
However, my IDE also kept track of how long a test would take to complete in minutes, seconds, and milliseconds, so I eventually just went with that. The first set of benchmarks (for 9x9 puzzles) went as follows:
/**
* First benchmarks (101 puzzles):
* 2.423313576E9 (4 m 3 s 979 ms to completion)
* 2.222165776E9 (3 m 42 s 682 ms to completion)
* 2.002508687E9 (3 m 20 s 624 ms ...)
* ...
*/
Although I did not have much of a reference point, I knew that it was taking longer than a second to generate a 9x9 Sudoku, which was a very bad sign.
I was not happy about how I was preloading the Graph with some valid numbers ahead of time, so I decided to refactor my approach there.
Naturally, the result after thinking up a new way to do that was worse:
/**
* ...
* Second benchmarks after refactoring seed algorithm: (101 puzzles)
* 3.526342681E9 (6 m 1 s 89 ms)
* 3.024547185E9 (5 m 4 s 971 ms)
* ...
*/
After quite a few more benchmarks which seemed to get slightly worse over time, I was pretty demoralized and wondering what to do.
I had what I thought was a very ingenious way to make my algorithm more or less picky based on how certain it was about placing a number into the puzzle. It was not working out so well in practice, though.
As is often the case, on roughly the 400th pass of my code via a code stepper (part of a debugging tool), I noticed that I had a slight mistake which had to do with how I was adjusting the value which dictated how picky my algorithm was.
What happened next blew my mind.
I ran another benchmark test, and got a weird result:
/**
* ...
* Fifth benchmarks niceValue only adjusted after a
* fairly comprehensive search (boundary * boundary)
* for a suitable allocation 101 puzzles:
* 3774511.0 (480 ms)
* ...
*/
I was in complete disbelief, so the first thing I did was to undo the change I just made and rerun the test. After 5 minutes I stopped the test as this was clearly the game changing difference, and proceeded to run five more benchmarks:
/**
* 3482333.0 (456 ms)
* 3840088.0 (468 ms)
* 3813932.0 (469 ms)
* 3169410.0 (453 ms)
* 3908975.0 (484 ms)
* ...
*/
Just for the hell of it, I decided to try building 101 16x16 puzzles. Previously I couldn't even build one of these (at least I stopped trying after the test ran for 10 minutes):
/**
* 16x16 (all previous benchmarks were for 9 * 9):
* 9.02626914E8 (1 m 31 s 45 ms)
* 7.75323967E8 (1 m 20 s 155 ms)
* 7.06454975E8 (1 m 11 s 838 ms)
* ...
*/
The point I am trying to communicate is this: It is not just that writing tests allowed me to verify that my algorithms were working. They allowed me to have an objective way to establish their efficiency.
By extension, this gave me a very clear way to know which of the 50 different tweaks to the algorithm I made actually had a positive or negative effect on the outcome.
This is important for the success of the application, but it was also incredibly positive for my own motivation and psychological health.
What I did not yet mention is that the time it took me to get from the first benchmark to the fifth (the fast one), was approximately 40 hours (four days at 10 hours per day).
I really was quite demoralized by the fourth day, but when I finally tweaked things the right way, it was the first time I ever felt like a real software engineer instead of just someone studying it for fun.
To leave you with a great image, after I ran the 16x16 tests and saw they were promising, I took a full 15 minutes to run around my rural property hollering like an excited chimpanzee that just got dosed with adrenaline.
My Final Suggestion
I will keep this one short and sweet. The worst thing you can do as a student, upon not being able to understand something difficult and complicated, is to blame yourself.
Good teachers and explanations are rare, and this is particularly true of topics which most of us find relatively dry and boring.
I had to watch approximately four videos, read approximately five articles/textbook chapters, and blindly dive into writing some code which did not initially make sense to me, just to even get started with Graphs.
This may be good or bad news for you, but I work very hard at what I do, and I very rarely find things in my field which are natural or easy for me.
My goal with this article has never been to imply that learning software engineering was easy for me, nor that it will be easy for you.
The difference is that I am told from time to time that I explain things well, and that unlike people who just regurgitate what other teachers say, I put the time in to find out what works or does not work for me, and try to share that with you.
I truly hope that something in this article was useful for you. Good luck with your learning goals, and happy coding!
Before you go...
If you like my writing, you will probably like my video content. I create everything from dedicated tutorials on specific topics, to weekly live Q&A sessions, to 10+ hour coding marathons where I build an entire application in one sitting.