By Michel Sassano
Before we even start: We do not know the journalists who recorded the interview and we do not know Roger Ver. Anyone who had access to this video could have retrieved the private key.
We could have simply named this post “How great QR code are and how we recovered one from almost nothing.” But it’s much more interesting when the QR code is the key to a $1000 Bitcoin Cash wallet.
Bitcoin, Ethereum, Litecoin, Dash, Neo… Cryptocurrencies are all over and are moving fast. I have been following Bitcoin since 2013 (following doesn’t mean buying), had to read Mastering Bitcoin 3 times to understand how each part of it really works and be able to explain it to someone else. Still, I can’t keep up with the market, new cryptocurrencies, new forks, new ICOs everywhere, every day.
It’s easy to start using cryptocurrencies by following a tutorial online. Download a random wallet app, generate a random pair of keys and buy some crypto on a random exchange but the cryptocurrencies learning curve is difficult.
If you don’t fully understand how all parts of this work you should avoid cryptocurrencies. If you don’t, you risk losing your money by falling in one of the many pitfalls. One of them, keeping your private key secure, is the subject of this post.
The first rule of Crypto Club is: You do not share your private key.
The most precious thing you have when you own cryptocurrencies is your private key. If you lose your private key, you lose your money. If someone gets access to your private key, you lose your money. Simple.
With this real-world example will show you step by step how we recovered the private key of the $1000 Bitcoin wallet created by @rogerkver for the French TV show “Complément d’enquête” even though it was obfuscated.
The intro
Last week France 2 broadcasted a documentary about Bitcoin. They interviewed @rogerkver who decided to offer $1000 in Bitcoin to the quickest viewer. Unfortunately, the QR code and the private key were obfuscated by France 2.
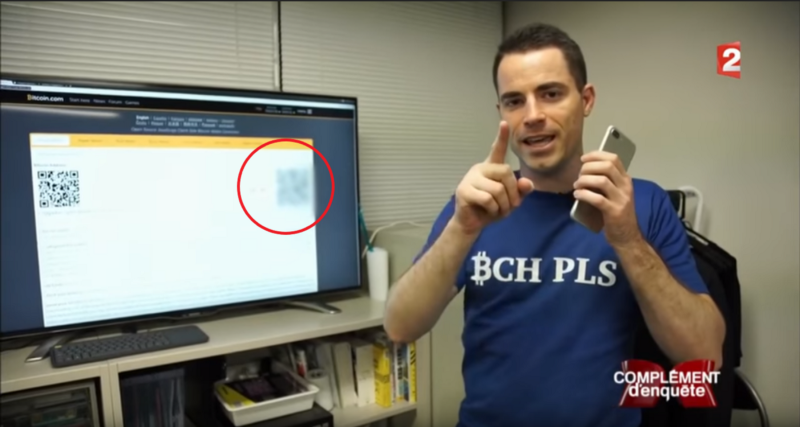
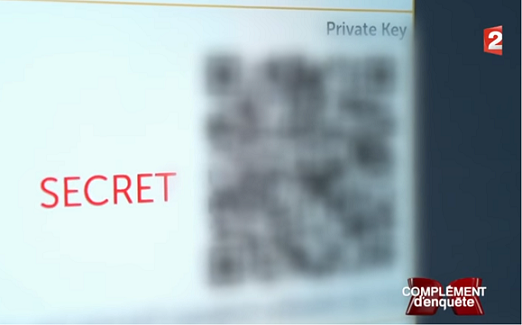 n°1 — Obfuscated QR code and private key.
n°1 — Obfuscated QR code and private key.
I’ve seen several people complaining about this on twitter, some even tweeting that France 2 decided to keep the Bitcoins for themselves. That is false, France 2 had to obfuscate the key, not because they wanted to keep the Bitcoins but because they were legally obligated to.
You can try to scan the QRCode with as many different apps as you can, you won’t be able to decode it because there is too much blur.
The story could have ended here, the $1000 lost forever as I don’t think Roger Ver kept a copy of the private key. Only the journalists who recorded the interview were able to redeem the Bitcoins.
But, near the very end of the interview, they showed a clear small part of the QR code. Did they do this on purpose, knowing the $1000 would be lost if no one was able to find the private key? Or this was just one of the mistake you can make when you start using cryptocurrencies?
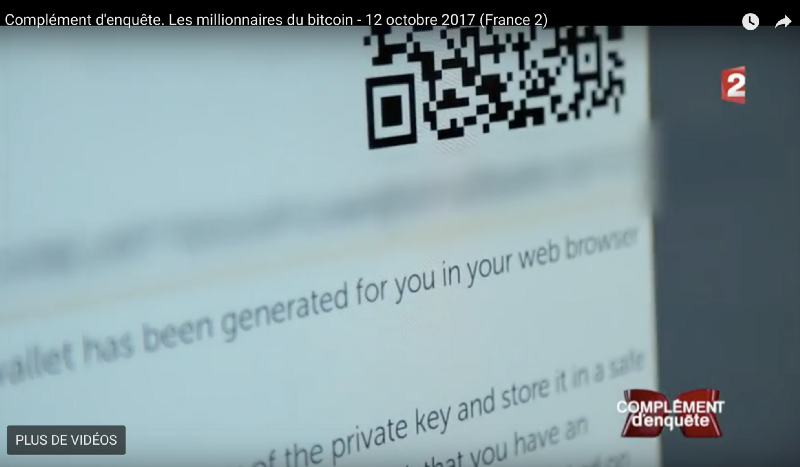 n°2 — Clear part of the QR code. Obfuscated private key string below.
n°2 — Clear part of the QR code. Obfuscated private key string below.
I was about to mail my friend @clementstorck when I received a screenshot of the QR code he took. We decided to work on it to see if we could find the private key from such a small amount of information.
Let’s be clear, the chances of finding the private key by only brute forcing were close to zero. We knew the property of QR codes and their resilience to damages. Our goal was to gather as many information as possible to make unknown parameters as small as possible. We knew we would have to brute force at some point. After all the steps below, we only had to brute force 2 097 152 combinations.
So, where do we begin? Below, all the steps we did to retrieve the private key
- Information gathering
- Let’s enhance! Image Analysis
- QR code standard part 1
- QR code reconstruction
- QR code standard part 2
- QR code decoding
- Error Correction Code
- Python & Brute force
1 — Information gathering
The first step was to gather as much information as possible from the interview. We watched the replay frame by frame and took several screenshots such as:
- The public key, which leads us to an (almost) empty BTC wallet. Did Roger Ver lie? Many people on Twitter said so. He didn’t lie, he tweeted about the giveaway here. We had to search for a BCH wallet.
 n°3 — The public key string and QR code: 17Qgadvc7pm51mV9r9zUAs4xU1XXwDRr8o
n°3 — The public key string and QR code: 17Qgadvc7pm51mV9r9zUAs4xU1XXwDRr8o
- A blurred part of the private key string. We will exploit this during the Image analysis step to get the first 6 letters. The Error Correction Code step will give us the next 7 letters.
 n°4 — Blurred part of the private key string. You can read some letters but it’s not very clear.
n°4 — Blurred part of the private key string. You can read some letters but it’s not very clear.
- The last letter of the private key, this will also be very helpful to unlock the last 8 letters of the private key.
 n°5 — The last letter of the private key. A nice “V”
n°5 — The last letter of the private key. A nice “V”
- Bad quality screenshots of the top and the left of the QR code. They will also be useful to get (a bit) more data and complete the QR code during the reconstruction phase.
 n°6 — The top of the QR code, first row can be exploited.
n°6 — The top of the QR code, first row can be exploited.
 n°7 — Seriously ?? The left side of the QR code, first two columns can (partially) be exploited.
n°7 — Seriously ?? The left side of the QR code, first two columns can (partially) be exploited.
- The tool he used to create the public and the private key is the Single Wallet tool on Bitcoin.com. This gave us information about the data inside the QR code: a 52 characters long Wallet Import Format Bitcoin private key similar to this:
KwjiU4CVAmdyxyDbvkbx2XbSoU1nxZgyXz7usqAemvsd4RdGHoPF
The next step is to recreate the QRCode.
2 — Let’s Enhance! Image analysis
Ok, we have less than 1/3 of a QR code, we are still far away from the private key. What can we learn from the screenshots we took?
We decided to focus on 2 screenshots, the first one is the blurred QR code of the private key, we wanted to know if QR code apps would be able to read it after being processed.
The second screenshot we wanted to work on was the one with the private key string. We knew we had to have at least a small amount of data if we wanted the ECC (Error Correction Code) step to work.
We decided to send the screenshots to our experts. With much results :)
This is what we got after some unblurring.
- A unblurred version of the QR code, none of the QR code apps were able to decode it. We wanted to give it a try because this guy did some crash test on QR codes and from the comments all of them were scannable.
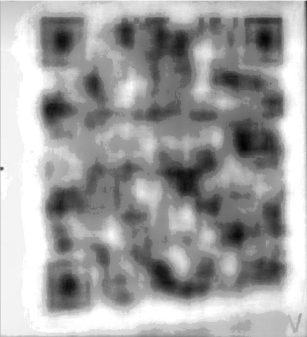 n°8 — We got nothing out of this picture. Only a confirmation of the last letter.
n°8 — We got nothing out of this picture. Only a confirmation of the last letter.
- Two version of the private key string unblurred. The first one gives us the first four letters (we don’t clearly see the “K”) and the second one the first six letters (we don’t clearly see the “z”).
 n°9 — It’s fuzzy but you can read “?yUz”
n°9 — It’s fuzzy but you can read “?yUz”
 n°10 — A bit more clear. You can read up to the 6th letter “KyU?sR”.
n°10 — A bit more clear. You can read up to the 6th letter “KyU?sR”.
Let’s keep this information for later. They’ll help us fill some bits down the road.
3 — QR code standard part 1
It was important to understand how QR codes work and the limits of their ECC capabilities in restoring a damaged QR code.
Wikipedia is a good start but everything we needed was in the ISO/IEC 18004 standard (There is a free version of the first edition on Swisseduc). We also found this gem online.
 n°11 — The Error Correction level and the Mask of the QR code can be extracted from this screenshot.
n°11 — The Error Correction level and the Mask of the QR code can be extracted from this screenshot.
Before we start to reconstruct the QR code, let’s see what we can learn from this picture using the ISO standard and the structure of a QR code.
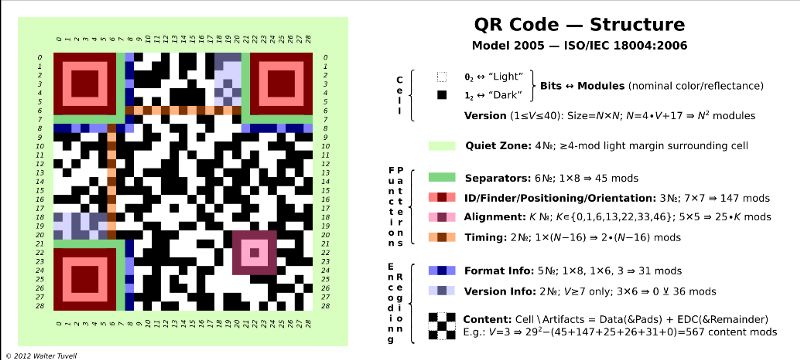 n°12 — By Wtuvell at English Wikipedia (Own work) [Public domain], via Wikimedia Commons
n°12 — By Wtuvell at English Wikipedia (Own work) [Public domain], via Wikimedia Commons
The interesting part for us was the blue column (x:8, y:22–28).
This is a part of the format information string (15-bit sequence. 5 data bits and 10 BCH error correction bits). The bits located at (x:8, y:22–28) are the bits 8 to 14 of the string. We only had 7 bits out of 15 but this was enough to find the information we needed.
The format information string encodes the Error Correction (EC) level and the mask pattern applied to the QR code. There are 4 possible EC level (L, M, Q, H) and 8 possible mask patterns => 32 possible format information strings.
Details about how to create the information string can be found page 76 of the standard (Annex C — Format Information). List of the 32 possibilities can be found here.
Let’s use the standard again to find which bit is which.
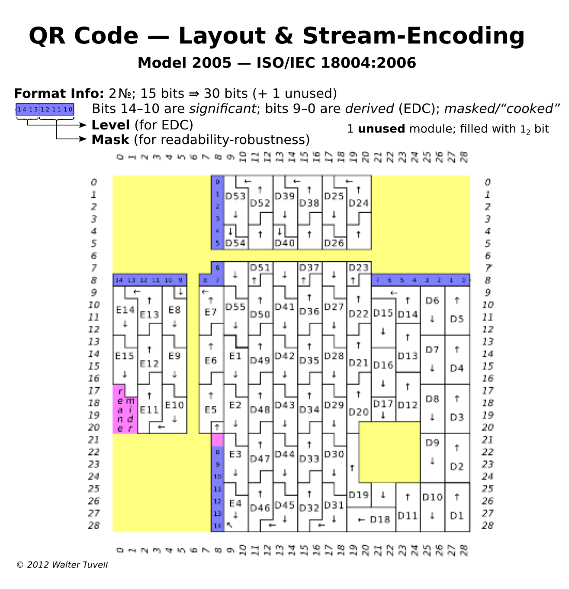 n°13 — By Wtuvell at English Wikipedia (Own work) [Public domain], via Wikimedia Commons
n°13 — By Wtuvell at English Wikipedia (Own work) [Public domain], via Wikimedia Commons
From top to bottom, we have bit 8 to 14 of the information string. The bit 14 is the most significant bit. From the screenshot n°11, we took we can then read.
0011001XXXXXXXX
A quick lookup in the format information strings table. The only combination which match is the one for ECC level: H and Mask pattern: 3
 n°14 — By Bobmath (Own work) [CC0], via Wikimedia Commons
n°14 — By Bobmath (Own work) [CC0], via Wikimedia Commons
We also needed to find the encoding format of the QR code. There are fives encoding formats (each of them use a different method to convert text into bits):
- Numeric (0–9)
- Alphanumeric (0–9; A-Z; nine other characters: space $ % * +- . / : )
- 8-bit Byte (JIS 8-bit character set. JIS X 0201 Japanese version os ISO 646)
- Kanji (Shift JIS character, can encode each Kanji characters on 2 bytes)
- ECI (Extended Channel Interpretation, when you need special/custom encoding)
The encoding format for the QR code is 8-bit Byte, Numeric and Alphanumeric do not support the private key alphabet (no lower case letters), Kanji encode on 2 bytes (we need only one) and ECI is overkill.
We were almost ready to start the reconstruction of the QR code, the last thing we needed was knowing the size of the QR code.
There are 40 sizes of QR code (called versions). They can go from 21x21 pixels (version 1) to 177x177 pixels (version 40). They grow 4x4 pixels everytime they increase their version number. Each version has a maximum capacity, based on the encoding format and the error correction level.
The capacity of each QR code depends on its version and error correction level. Details can be found page 28 of the ISO standard.
We knew the QR code had to store 52 characters (416 bits) with an error correction level H.
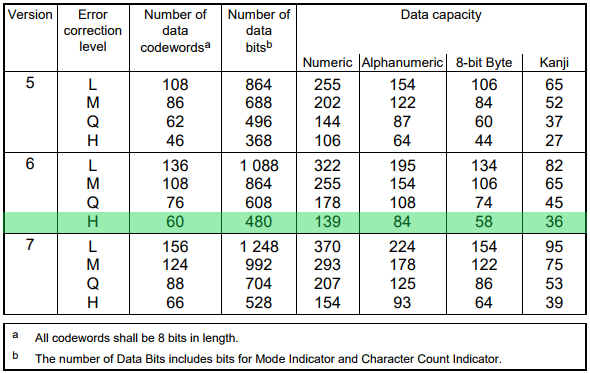 n°15 — V6 is the smallest size which can hold the 416 bits key with an EC level of H. V5 is too small, V7 too big.
n°15 — V6 is the smallest size which can hold the 416 bits key with an EC level of H. V5 is too small, V7 too big.
The size of a version 6 QR code is 41x41 pixels.
We now had all the information we needed to start the QR code reconstruction.
4 — QR code reconstruction
We know we had to reconstruct a 41x41 pixels QR code. We decided to work on a Google spreadsheet (easy to draw, color and apply functions such as masking onto the QR code).
We went through the following steps:
- Draw every pattern which is part of the standard (the positioning pattern, the alignment pattern (only one in a version 6 QR code), the timing pattern and the separators as seen in picture n°12)
- Add the bits from the format information string we found in the previous step.
- Fill the rest of the QR code based on the screenshot (n°11) we took.
Let’s also leverage the top and left QR code’s side screenshots. This doesn’t seem much but at this stage, every bit matters.
 n°16 — How we collected some more bits on the top rows
n°16 — How we collected some more bits on the top rows
 n°17 — Same process for the left side of the QR code (90° rotated)
n°17 — Same process for the left side of the QR code (90° rotated)
Below, the QR code we were able to reconstruct. The next step is to define the bit sequence to extract Codewords and Error Correction Codewords.
 n°18 — Step by step reconstruction of the QR code.
n°18 — Step by step reconstruction of the QR code.
5 — QR code standard part 2
We needed to figure how to read the QR code if we wanted to extract more bits from it.
A QR code is composed of Data codewords and EC codewords blocks. Each block is 8 bits long and each bit is represented by a module (black or white square). You can’t tell by just looking at a QR code if a specific white square is a “0” or a “1” because as we’ll see later a mask is applied to the QR code before it’s rendered.
Data Codewords carry the message/data encapsulated into a simple protocol shown below (details can be found on page 17 of the ISO standard):
- Mode indicator: 4 bits identifier indicating which encoding mode the message/data sequence is encoded.
- Character count indicator: bit sequence which indicates the length of the message. Varies according to the encoding mode and QR code version.
- Message/data (private key) bit stream. (8 bits per char)
- Terminator: 4 bits used to end the bit string representing the message.
- Padding bits: used to fill empty positions of the bit stream.
 n°19 — The bit stream contained in the Data codewords.
n°19 — The bit stream contained in the Data codewords.
ECC Codewords are added to the Data codewords sequence in order to detect and correct the data in case of error(s) or erasure(s). They are Reed-Solomon codes generated from the Data codewords. We’ll talk a bit more about them in step N°7.
The number of Data and ECC Codewords varies according to the version and the error correction level. They are split into groups (1 or 2) and into blocks (1 to 67) depending on the version and the EC level.
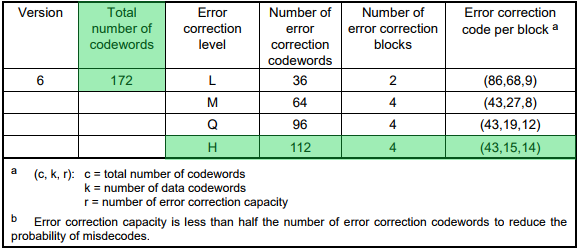 n°20 — Error correction characteristics for version 6 (page 35 of the ISO standard)
n°20 — Error correction characteristics for version 6 (page 35 of the ISO standard)
In our case (Version 6, EC level H), we’ll have 15 Data codewords and 28 ECC codewords per block. The QR code will contain 1 group of 4 blocks for a total of 172 codewords.
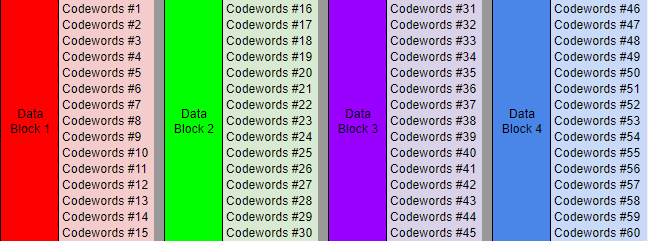 n°21 — Data Codewords blocks. Each Codeword is 8 bits long. They carry a part of the bit stream from N°19
n°21 — Data Codewords blocks. Each Codeword is 8 bits long. They carry a part of the bit stream from N°19
 n° 22 — ECC Codewords blocks. They are 8 bits long Reed-Solomon codes derived from the Data blocks.
n° 22 — ECC Codewords blocks. They are 8 bits long Reed-Solomon codes derived from the Data blocks.
6 — QR code decoding
The next step was to read the QR code and fill as much as possible the Data and ECC codewords table from step 5.
The first step was to unmask the QR code. We used Google spreadsheet to create the mask and used the BITXOR function to apply it.
 n°23 — When applied to the QR code, each green module of the mask inverts the color of the module.
n°23 — When applied to the QR code, each green module of the mask inverts the color of the module.
The result of the masking process is the readable QR code. How to read the QR code and where to start? The ISO standard explains how the codewords are mapped onto the QR code and how to read them (page 46: Codeword placement in the matrix).
Let’s map the codewords onto the QR code.
 n°24 — Position of the Data and Error Correction codewords. Regular and irregular symbols can be seen.
n°24 — Position of the Data and Error Correction codewords. Regular and irregular symbols can be seen.
Now let’s read each one of them. Each symbol has to be read in a different manner depending on its shape and reading direction as seen below and as explained page 47 of the ISO standard.
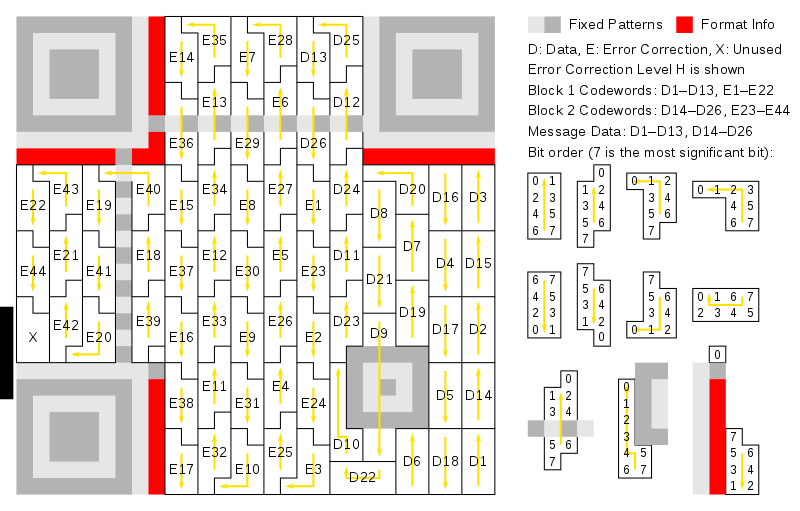 n°25 — By Bobmath (Own work) [CC0], via Wikimedia Commons
n°25 — By Bobmath (Own work) [CC0], via Wikimedia Commons
Below, the bit by bit readable QR code. Every “X” is an unknown bit.
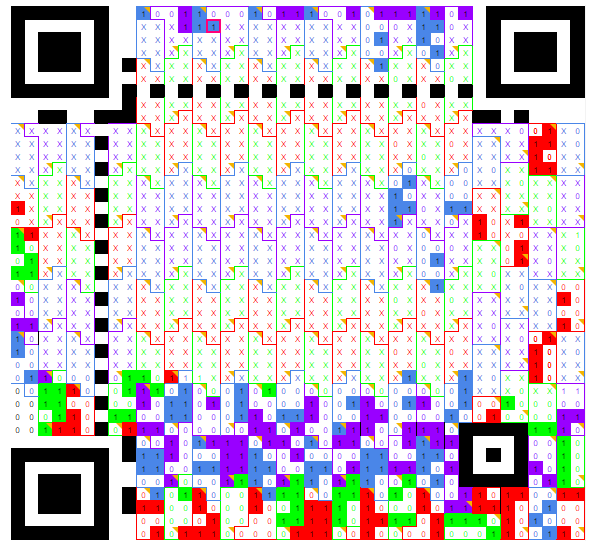 n°26 — Decoding a QR code by hand, one bit at a time. Seems fun right ?
n°26 — Decoding a QR code by hand, one bit at a time. Seems fun right ?
We then read and filled the Data and ECC tables from Step 4.
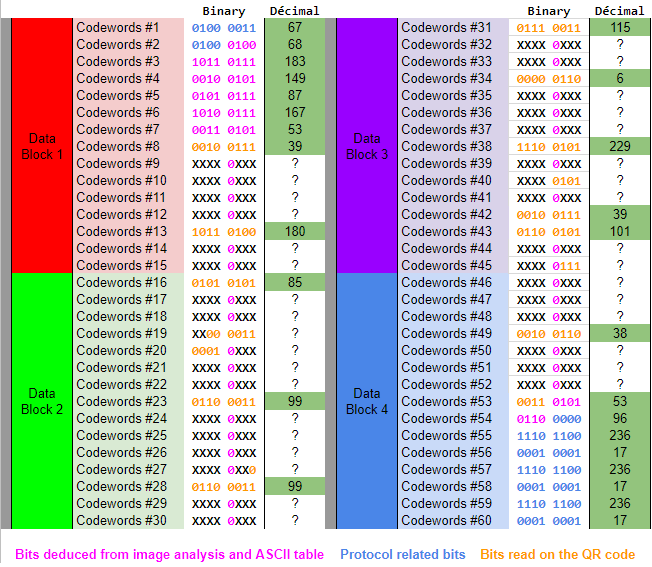 n°27 — Data codewords after we read the QR code, filled the protocol’s bits and those we got via image analysis.
n°27 — Data codewords after we read the QR code, filled the protocol’s bits and those we got via image analysis.
Codewords #1 and #2 are known because they are part of the protocol (Mode indicator + Character count indicator).
Codewords #3, #4, #6 and #7 are known because of the image analysis we did on step 2 (“KyUzsR”)
Codewords #54 to #60 are also known because they are part of the protocol (Terminator + Padding bits).
Every solved “X” increase our chance of succeeding in the ECC phase and split by 2 the number of possibilities we’ll have to brute force down the road.
You might be wondering why all the 5th bit of all the Codewords carrying the message/data are set to “0”. This is because we know the alphabet of the private key (Base58Check) and all the characters in this alphabet starts with a “0” when encoded onto 8 bits. (The 5th bit in each codeword is the first bit of each letter of the message because of the shift introduced by the first 12 protocol’s bits).
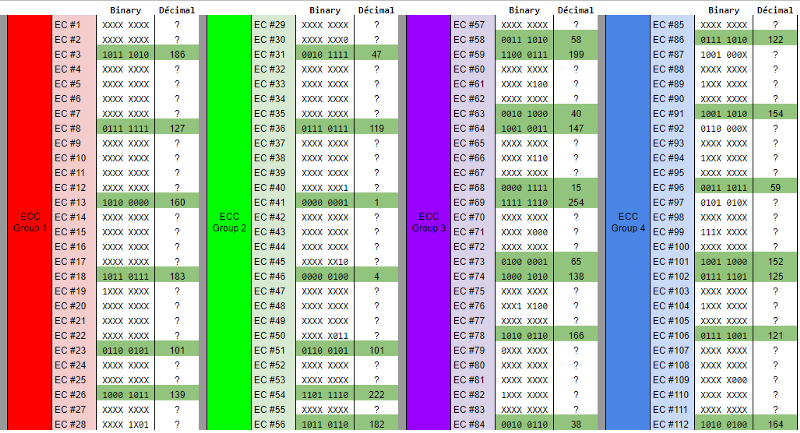 n°28 — ECC Codewords table after we read the QR code. Nothing we can do here as all of them are defined by the Reed-Solomon encoder.
n°28 — ECC Codewords table after we read the QR code. Nothing we can do here as all of them are defined by the Reed-Solomon encoder.
Let’s now use the magic of Error correction code to restore as much data as possible.
7 — Error Correction Code
At this stage, we were still far from the complete private key but we were soon able to know if we collected enough data to recover the key by leveraging ECC.
ECC are techniques that enable reliable communication over unreliable channels. They have the power to reconstruct the original data by detecting and correcting errors and erasures.
QR codes implement Reed-Solomon codes (a subtype of BCH codes we saw when decoding the Format information string at step 3).
We are not going to explain in details how to encode or decode Reed-Solomon codes. There are many good resources on the web but quickly:
- The Reed-Solomon encoder produces the ECC codewords. They are the remainder of a division between the polynomial representing the message and an irreducible generator polynomial.
 n°29 — The irreducible generator polynomial for 28 EC codewords.
n°29 — The irreducible generator polynomial for 28 EC codewords.
- The Reed-Solomon decoder is a bit more complex because there are lots of different ways to decode the message. Different decoding algorithms exist for this task, this page is very helpful to understand the decoding process.
A Reed-Solomon decoder is able to decode erasures and errors at the same time. Unfortunately, there is a limit, called the Singleton Bound.
The risk we had was to be over this limit. Reed-Solomon is an optimal FEC and is “vulnerable” to the cliff effect. That does mean that if you are over the limit, you can get nothing out of the EC codes and that’s where we needed to brute force.
The limit (number of erasures and errors correctable) is defined by the formula below as defined on page 33 of the ISO standard:
e + 2*t ≤ d - p
Where:
- e : number of erasures
- t : number of errors
- d : number of error correction codewords
- p : number of misdecode protection codewords (0 in our case: 6-H)
What this formula means is that you can correct up to 14 errors or 28 erasures per block (or a mix of the two if the sum is not greater than 28). We leveraged the fact that we knew where the erasures were on the QR code to have the highest error correction level possible (28 codewords per block).
Let’s check for each block if we are below or above the limit:
- Block 1: Data contains 6 erasures, ECC contains 22 erasures
- Block 2: Data contains 12 erasures, ECC contains 21 erasures
- Block 3: Data contains 10 erasures, ECC contains 18 erasures
- Block 4: Data contains 6 erasures, ECC contains 21 erasures
With 28 erasures, block 3 and block 1 are just at the limit and we will be able to recover 100% of it. Same for block 4 with a total of 27 erasures each.
With 33 erasures, block 2 is above the limit and we will have to brute force it. Fortunately, the brute force will be made on a small number of combinations.
8 — Python & Brute force
We decided to use this Reed-Solomon Python codec to decode the message.
We’ll use a mix of Python code and pseudocode to describe the steps we did to find the final result.
Let’s start with the best case scenario, when we are below the limit and decode Block 3, 4 and 1.
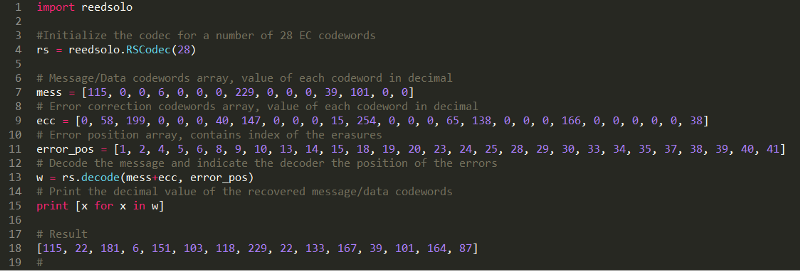 n°30 — Decoding block 3 using the Reed-Solomon decoder.
n°30 — Decoding block 3 using the Reed-Solomon decoder.
The result of the decoder for block 3 is:
[115, 22, 181, 6, 151, 103, 118, 229, 22, 133, 167, 39, 101, 164, 87]
Same process for block 4, just modify the value of the mess, ecc and error_pos variables. The result is:
[118, 132, 183, 38, 36, 99, 116, 53, 96, 236, 17, 236, 17, 236, 17]
The result of the decoder for block 1 is:
[67, 68, 183, 149, 87, 167, 53, 39, 86, 71, 4, 230, 180, 196, 182]
So far so good. Unfortunately, if we try the same thing with block 2 the decoder will fail because we are over the limit.
The only solution we had was to brute force. We had a negative margin of 5 (33 erasures instead of 28) so the goal was to restore (brute force on) 5 codewords and see which result the decoder gave us.
To reduce the number of possibilities we looked in the tables n°27 and n°28 for the bytes with the fewer unknowns bits. Data codewords #17, #19, #20, #27 and EC codeword #50 were interesting.
21 unknow bits in total, 2²¹ combinations (2 097 152) not that big. Below the pseudocode of the brute force.
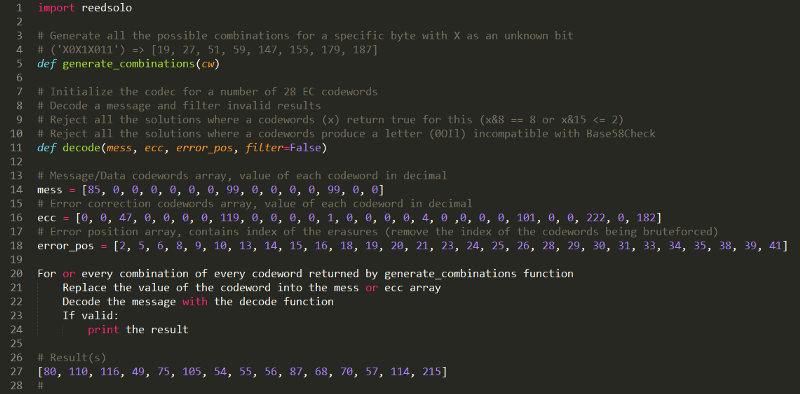 n°31 — Brute forcing the block 2, giving us the last bits we needed.
n°31 — Brute forcing the block 2, giving us the last bits we needed.
My i5–6600K CPU was able to compute around 30 000 keys per minute on one core. It took 30 minutes and 838 849 trials to find the first solution which was the good one to reconstruct the private key (there were only 2 solutions out of these 2 097 152 combinations which matched the filters).
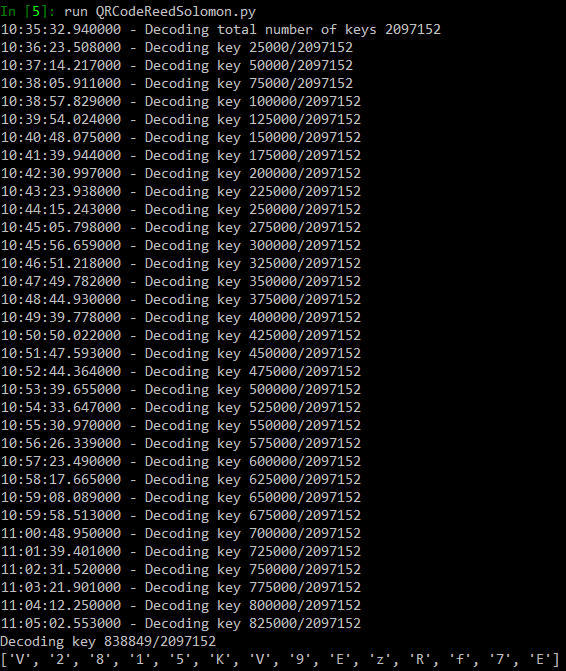 n°32 — Brute forcing the block 2
n°32 — Brute forcing the block 2
The result for block 2:
[85, 99, 35, 131, 19, 84, 181, 99, 148, 87, 165, 38, 99, 116, 84]
We now have all the codewords, the final step is to convert all these codewords into binary, fill the table n°27, trim the first 12 bits, the last 52 bits, decode and voilà!
The final result is the private key:
KyUzsRudpNkLKeV2815KV9EzRf7EG1kPivwnQhZrvZEwhKrbF7CV
It goes without saying that you should not use this private key as it’s not really private anymore!
 Private key QR code restored!
Private key QR code restored!
Roger, thank you for the giveaway. The process to redeem the BCH wasn’t as easy as scanning the QR code on TV but it was challenging and fun.