

A step by step guide to migrating an existing software product to run serverlessly in the cloud
You’ve got an app that you run and you've heard loads about serverless and the benefits. You may have even tried deploying some things with serverless but you want to move you whole app to serverless.
How do you do that? What bits do you do first? Do you have to do it all at the same time?
This article will guide you through the steps you can take to migrate your app or service to the cloud with Serverless.
1. Simple APIs
When you start the process of migrating your service to, it’s best to start with the low hanging fruit. This will get you some experience working with serverless and AWS but still provide value to the application.
Simple APIs are endpoints that don’t need to access your databases to perform their actions. This could be an API for sending emails, hitting external APIs and combining the data or for running some logic on the input.
A secondary advantage to creating these APIs is that it reduces the load on the existing servers. We, at MissionLabs, have found that this removal of functionality and complexity has allowed us to reduce the code on our servers by over 50%. This has resulted in much more readable code and quicker bug fixes.
How to migrate

Luckily, migrating simple APIs to the cloud using serverless is really easy with AWS Lambda and API Gateway.
AWS Lambda is a cloud function service where you can run code functions and only pay for when the function is running. You can write your code in Ruby, Python, Node, Java, Go or .Net and through the AWS SDK you can easily access other AWS services (such as email, sms, kinesis, databases).
To create an API using AWS Lambda and API Gateway you need to write a function that executes the logic. Then you need to export the function as exports.handler .
exports.handler = async (event, context) => {
// your function code goes here
}To deploy your code with an API using serverless, we need to add this new function to our serverless.yml file under function declaration. You need to define the location of the code as well as the methods and path for the API endpoint.
functions:
myFirstApi:
handler: src/myFirstApi/index.handler
events:
- http:
path: getFromMyAPI
method: GET
cors: trueThis will deploy your function code to ${random-api-subdomain}.execute-api.${region}.amazonaws.com/${stage}/getFromMyApi. Here is an example of an endpoint.
https://ic5hwq6j0a.execute-api.eu-west-1.amazonaws.com/live/item
If you want to create a more readable API address then you can use Route 53 to forward traffic so that your endpoint could be something like:
https://api.completecoding.io/v1/item (not active)
2. Databases and Connected APIs
Now that you’ve migrated some of your APIs, you’re familiar with writing Lambda functions and deploying them with Serverless.
The next step is to migrate your databases over to serverless and create the rest of your APIs.
2.1 Databases
Databases are obviously a massive part of any software product, but creating, managing and scaling them can be a pain. Provisioning shards and syncing instances can be difficult at the best of times.
With Serverless you can use DynamoDB, where scaling and performance are managed by AWS, leaving you to work on the valuable parts of the product.

How to migrate
Creating DynamoDB tables in serverless is relatively simple. All we need to do is create a new Resource and provide the table details.
Resources:
OrderTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: order-table
AttributeDefinitions:
- AttributeName: userID
AttributeType: S
- AttributeName: orderId
AttributeType: S
KeySchema:
- AttributeName: userId
KeyType: HASH
- AttributeName: orderId
KeyType: HASH Things can get a little more complex when it comes to auto-scaling and secondary indexes.
To get auto-scaling added to our table, we have two options. We can either set up PayPerReqest billing or provision auto-scaling on the table.
PayPerRequest is better if you have more irregular traffic that comes in spikes and troughs. To provision is you can remove these lines:
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5and replace them with this line:
BillingMode: PAY_PER_REQUESTThe other option is to add auto-scaling. This wasn’t a feature when Dynamo was first released so the configuration is more complex. To reduce the complexity we can use the serverless-dynamodb-autoscaling plugin. To install this plugin run npm install serverless-dynamodb-autoscaling and then add some custom fields to our serverless.yml file.
plugins:
- serverless-dynamodb-autoscaling
custom:
capacities:
- table: order-table # DynamoDB Resource
read:
minimum: 5 # Minimum read capacity
maximum: 1000 # Maximum read capacity
usage: 0.75 # Targeted usage percentage
write:
minimum: 40 # Minimum write capacity
maximum: 200 # Maximum write capacity
usage: 0.5 # Targeted usage percentageYou should use whichever of these methods is most applicable to how each of your tables is used. There is no reason you can’t have some tables on PayPerRequest and others using normal auto-scaling.
There is also the issue of migrating all your data from your existing tables to your new dynamo tables. Luckily this is a brilliant article about how to complete these kinds of migrations, whether from MongoDB, Cassandra, mySQL or RDBMS.
2.2 Connected APIs
Now that we have our databases created, we should be able to convert most of our remaining APIs over to serverless. These might be user lookups, logins, product lookups, order status updates or any other kind of request that read or write to one of your tables.
How to migrate
The process to create these functions will be exactly the same as the process that you did in step 1, but now we have databases to access.
To access your data in DynamoDB, you can use the AWS SDK and the DynamoDB document client. This interface has the functionality to perform all the rest methods as well as a few extra such as scan, query, batchGet and batchWrite.
Whilst these sound perfect for baking into your Lambda code, I would suggest creating your own class that uses these methods. This is because the format of the request made to the document client is often overly complicated. Here’s my example of a simplified method for getting from Dynamo.
get(ID, table) {
if (!table)
throw 'table needed';
if (typeof ID !== 'string')
throw `ID was not string and was ${ID} on table ${table}`;
return new Promise((resolve, reject) => {
let params = {
TableName: table,
Key: {
ID: ID,
},
};
documentClient.get(params, function (err, data) {
if (err) {
console.log(`There was an error fetching the data for ID ${ID} on table ${table}`, err);
return reject(err);
}
return resolve(data.Item);
});
});
}If you now need to do a lookup in any of your APIs you can just use
let user = await DB.get('123-f342-3ca', 'user-table')You can do the same for write, update, delete, scan and query.
With these methods you should be able to port almost all your APIs over to serverless. This can be a large piece of work but there are a lot of benefits, including autoscaling, only pay for what you use, redundancy, separation of concerns and many more.
3. Storage
Cloud storage was the first service that was ever provided by AWS - Amazon S3. This service allows you to host file in the cloud, define the access policies, and easily use those files in other AWS services.
Items stored in S3 are put into buckets, which are isolated containers used to group items (similar to folders on your machine). You can store whatever files you like in S3, from product images, to invoices, from data in JSON format to whole websites.

How to migrate
There are two stages to migrating to serverless cloud storage: creating the buckets and deploying the resources.
To create a bucket in serverless, you are defining a new resource. One thing to remember is that the bucket name must be globally unique. This means you can't have the same bucket name on two accounts, or in two regions.
resources:
Resources:
UploadBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: my-bucket-name-is-uniqueWhen you run sls deploy now, you'll find that you've created a bucket on your account. Now you can manually upload files into this bucket using the UI, or use it as a location to put uploaded files, but we're also going to learn how to sync up local files to the bucket.
To automatically upload files to our new bucket, we're going to be using the serverless-s3-sync plugin. This plugin allows us to upload all the content of a folder on our computer to an S3 bucket as part of the deployment process.
To start using the plugin, we need to install it using npm install --save serverless-s3-sync and then adding the plugin to our serverless file. With out autoscaling DynamoDB plugin we'll now have this:
plugins:
- serverless-dynamodb-autoscaling
- serverless-s3-syncTo configure the upload we need to add another field to our custom section as well.
custom:
s3Sync:
- bucketName: my-bucket-name-is-unique # required
bucketPrefix: assets/ # optional
localDir: dist/assets # required The bucketName needs to match the name of the bucket you created. The localDir is the folder that you want to upload to the bucket. You can also use bucketPrefix if you want to add a prefix onto the start of the files (put them in a folder within the bucket).
With this all set up, running sls deploy will now create a new bucket and upload the files you have in dist/assets.
4. Website Hosting
So far you will have had to make quite a few URL changes to your website for all the API changes that you've already implemented. Now wouldn't it be cool if you could also host that website entirely serverlessly and deploy it with all of your APIs, databases and everything else.
How to migrate
We're going to host and deploy our website in a very similar way to the way that we are hosting our asset storage in the last section: serverless-s3-sync.
There are a few extra bits that we need to take care of when we're hosting a website. To start out though, we're still uploading a folder (containing our static site) to an S3 bucket. We can add a new bucket (MyWebsiteBucket) and new S3Sync setup. We set a custom variable called siteName and then use that to define the bucket name.
resources:
Resources:
UploadBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: my-bucket-name-is-unique
MyWebsiteBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: ${self:custom.siteName} custom:
s3Sync:
- bucketName: my-bucket-name-is-unique
bucketPrefix: assets/
localDir: dist/assets
- bucketName: ${self:custom.siteName}
localDir: myWebsiteFolder
siteName: serverlessfullstack.comBut this time we need to add a few more things onto our S3 bucket configuration. We need to set the access control and tell S3 that this is a website we're hosting in the bucket.
MyWebsiteBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: ${self:custom.siteName}
WebsiteConfiguration:
IndexDocument: index.html
AccessControl: PublicReadWe also need to create a policy document for the bucket in our resources
WebsiteS3BucketPolicy:
Type: AWS::S3::BucketPolicy
Properties:
Bucket:
Ref: MyWebsiteBucket
PolicyDocument:
Statement:
- Sid: PublicReadGetObject
Effect: Allow
Principal: "*"
Action:
- s3:GetObject
Resource:
Fn::Join: ["", [
"arn:aws:s3:::",
{"Ref": "StaticSite"},
"/*"
]]
When we now run sls deploy we'll get our content of our website uploaded to S3 and all the correct permissions set on the bucket.
You'll now be able to view your site at http://serverlessfullstack.com.s3-website-us-east-1.amazonaws.com/
This is nice but it would be better if we were hosting on our own url, so that's what we'll do now. We need to create a DNS record that points the requested domain to our s3 bucket.
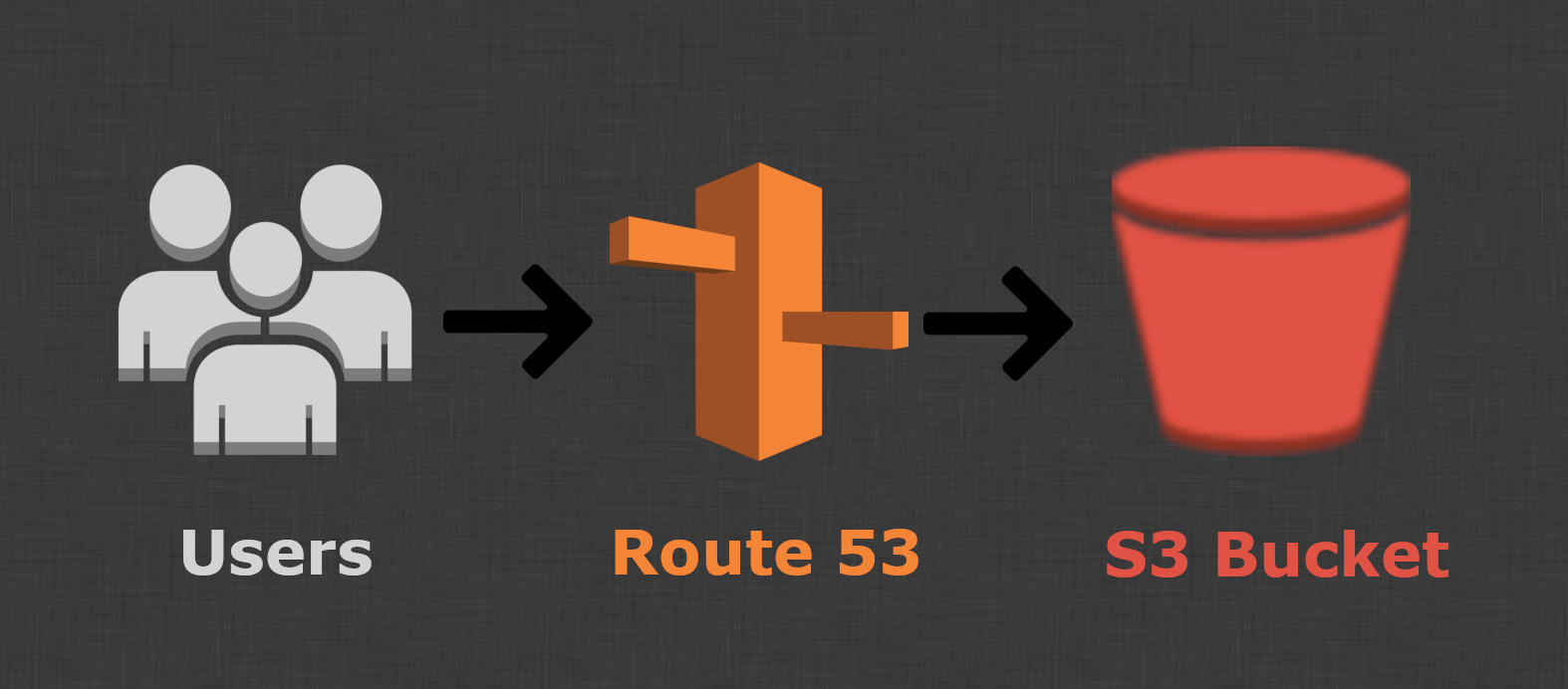
In Route 53, make sure you've set up your hosted zone name and then we can add the DNS record to the resources.
DnsRecord:
Type: 'AWS::Route53::RecordSet'
Properties:
AliasTarget:
DNSName: ${self:custom.aliasDNSName}
HostedZoneId: ${self:custom.aliasHostedZoneId}
HostedZoneName: ${self:custom.siteName}.
Name:
Ref: MyWebsiteBucket
Type: 'A'With this we also need to set a few extra custom fields of hostedZoneName, aliasHostedZoneId and aliasDNSName.
custom:
s3Sync:
- bucketName: ${self:custom.siteName}
localDir: myWebsiteFolder
siteName: serverlessfullstack.com
hostedZoneName: ${self:custom.siteName}
aliasHostedZoneId: Z3AQBSTGFYJSTF # us-east-1
aliasDNSName: s3-website-us-east-1.amazonaws.comIf you've set this up in a region that isn't us-east-1 then you can find your aliasHostedZoneId here.
With this all set up you should now be able to run sls deploy again. This will add the DNS record to your account and now you can visit serverlessfullstack.com and see the live page hosted from S3.
If you've followed along, the only differences between our code should be: custom.siteName and your assets bucket name and you should have your own serverlessly hosted app!
If you've found this article useful and want to start working with Serverless then check out my FREE course on creating and deploying a Serverless API. You'll learn to:
- Create a user and get credentials on AWS and set up Serverless
- Create a Lambda and API Endpoint to handle the API requests
- Deploy, Test and Update your API
