
By Romain Thalineau
A while ago I read this nice article from Laurent Luce where he explained how he implemented a system that collected the tweets related to the 2012 French presidential election. The article is very well written, and I highly recommend reading it.
This gave me the idea to implement something similar for the 2017 election. But I wanted to add some features:
- Instead of using a SQL database for storing the data, I wanted to use a Graph database. The main reason was to experiment with such a system, but it’s fairly easy to see how this is a good fit for social media data.
- I wanted to be able to monitor the data in real time. Practically speaking, this means that the data need to be processed as they arrive. This would also involve serving the analyzed data to a web site with data visualizations.
- Ideally I wanted to run a sentiment analysis on the tweets. I would train a learning algorithm and implement it along the data pipeline to serve its results in real time.
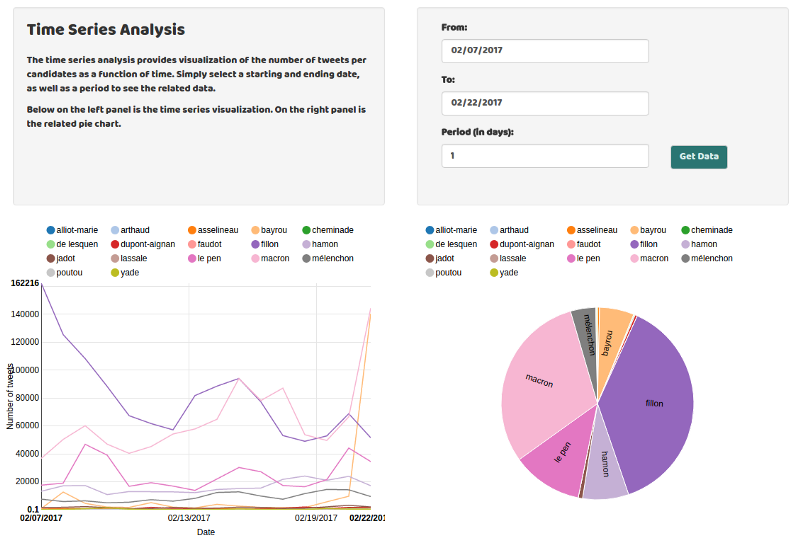 _[Time Series Analysis](https://www.auguratech.com/#/twitter/time_series" rel="noopener" target="blank" title=")
_[Time Series Analysis](https://www.auguratech.com/#/twitter/time_series" rel="noopener" target="blank" title=")
Well, I managed to build all of this. You can go to see how it looks like on my personal website. So far, there are two simple analyses:
- The first one is a time series analysis, which shows the numbers of tweets per candidates as a function of the date. Besides being able to select the starting/ending date and the period, you can also display just the candidates you would like to see by clicking on their names in the visualization.
- The second analysis displays the geolocation of the tweets. The options are relatively similar to the first analysis.
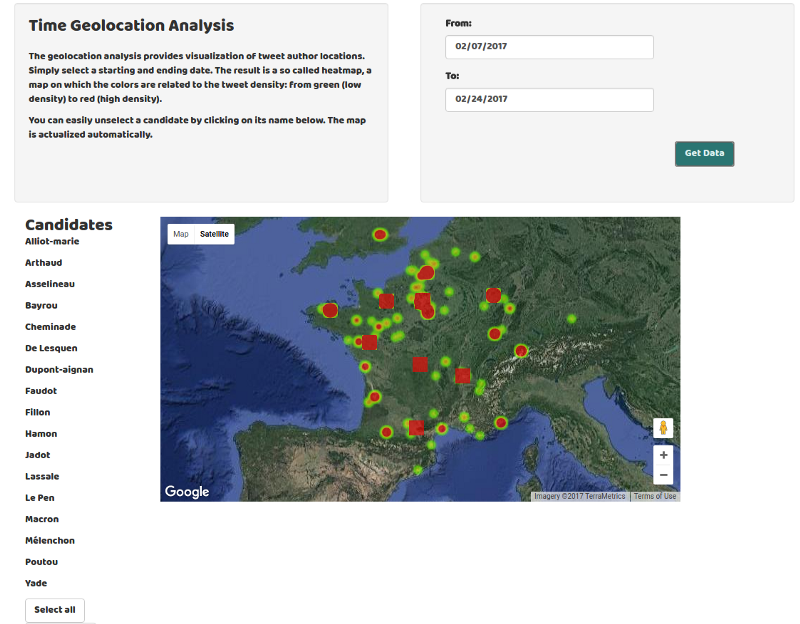 _[Tweet geolocation analysis](https://www.auguratech.com/#/twitter/geospatial" rel="noopener" target="blank" title=")
_[Tweet geolocation analysis](https://www.auguratech.com/#/twitter/geospatial" rel="noopener" target="blank" title=")
For collecting the data from Twitter, I used an approach similar to Laurent Luce. Instead of focusing on the similarities, I’ll show you the approaches I took that were different.
Storing the tweets in a graph database
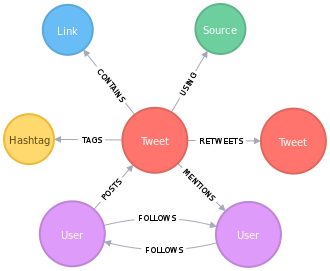
As I said, I wanted to store the data in a graph database. I chose to use Neo4J. In a graph database, data are modeled using a combination of nodes, edges, and properties structures.
 _[Image credit](http://network.graphdemos.com/" rel="noopener" target="blank" title=")
_[Image credit](http://network.graphdemos.com/" rel="noopener" target="blank" title=")
In our case, nodes can represent a tweet, a user or even a hashtag. They can be distinguished by using a label. The relationship between nodes is handled by connecting them through edges. For example, a user node can be connected to a tweet node via a POSTS relationship.
The relationships are directional. A tweet can’t POST a user, but it can MENTION a user.
Finally both nodes and edges (relationships) can hold properties. For example, a user has a name and a tweet has text.
When interacting with a graph database, Object Graph Mapper (OGM) are particularly useful. In this project, I’ve been using Neomodel. It exposes an API relatively similar to the Django models API. You define your models like:
As you can see, both the property and the relationships are defined. I invite you checking the models file in my github repo to see the full data model definition.
Neo4J being a NoSQL database, it uses a non-SQL query language called Cypher. It’s a pretty straightforward language. For instance, the following query will return all the tweets posted by a user that contain the word “fillon” (one of the candidates):
MATCH (u:User)-[:POSTS]->(t:Tweet) WHERE t.text contains "fillon" return t
Neomodel being an OGM, it provides an API so you don’t have to write very many queries manually. You can obtained the same results as above by running:
Tweet.nodes.filter(text__contains="fillon")
Streaming from Twitter
Twitter provides two ways to get their data. The first one is through a standard REST API. Each endpoint access is limited, so it isn’t the preferred solution in our case.
Luckily, Twitter also provides a streaming API. By setting a filter, we can receive all the tweets that pass this filter (with a limit of 1% of the global amount of tweets published at instant t). The library Tweepy facilitates this process.
As you can see in my repo, you need to define a Listener class, which will trigger some actions while streaming. For instance, the method “on_status” is called any time a tweet is streamed.
In addition, I defined a Streaming class whose responsibilities are to authenticate to Twitter, to instantiate a Tweepy stream with the above Listener, and to expose a method to start streaming. The “start_streaming” method accepts a “to_track” argument, which is a list of words on which you want to filter.
You have to instantiate the Streaming class with a bunch of arguments. Aside from the Twitter API credentials, you need “pipeline” and “batch_size” arguments. The latter is a number specifying the amount of tweets that are processed at once.
Since processing a tweet involves saving it to Neo4J, doing it one by one is a very costly operation. Saving them by batches of 100 (or even more in some cases) improves performance considerably.
The “pipeline” argument must be a reference to a function, which will receive the batch of tweets. Inside of this, you are free to do whatever you want. I provided an example of it in the utils.py module.
As you can see, this function makes a call to an asynchronous Celery task defined in the tasks.py module. Celery is a Python distributed task queue library. I used it with RabbitMQ as a message broker. So how does it work? Let us get back to the “streaming_pipeline” function in the utils.py module, and focus on this line:
bulk_parsing.delay(users_attributes, tweets_attributes)
When this line is processed, instead of processing the “bulk_parsing” function synchronously, a message will be published to a broker (here RabbitMQ). It allows for consumers (workers) to retrieve these messages, and therefore to process the “bulk_parsing” task asynchronously and in parallel. Why’s that? Because it enables horizontal scaling of tweet processing. If the messages accumulate faster than you can process them, you can add more workers to help consume them.
One final remark. I wanted the process to be as versatile as possible, in the sense that if the processing needed to be change — or if something needed to be added — it must be easy to do so. In this case, I can just change the “streaming_pipeline” function and add some asynchronous tasks. It’s quick and easy to modify.
Thanks for reading!
- Be sure to check out the code in my Github repo.
- You can see all this in action on my site, where I used this to feed some analysis.