![How to Avoid the N+1 Query Problem in GraphQL and REST APIs [with Benchmarks]](https://www.freecodecamp.org/news/content/images/size/w2000/2023/07/N-1-Query-Problem.png)
By Mohamed Mayallo
The N+1 query problem is a performance issue you might face while building APIs, regardless of whether they're GraphQL or REST APIs.
In fact, this problem occurs when your application needs to return a set of data that includes related nested data – for example, a post that includes comments.
But how can you fix this problem? To avoid this issue, you should understand what is it and how it occurs.
So in this tutorial, you'll learn what the N+1 query problem is, why it is easy to fall into it, and how you can avoid it.
Before starting, it is good to know:
- The examples in this article are just for the sake of simplicity.
SELECT *is very bad, and you should avoid it.- You should care about pagination if you’re working with large data sets.
You can find the examples in this article in this repo. Let's dive in.
Understanding the N+1 Query Problem
The N+1 problem occurs when your application needs to return a set of data that includes related data that exists in:
- Another table.
- Another database (in the case of microservices, for example)
- Or even another third-party service.
In other words, you need to execute extra database queries or external requests to return the nested data.
If you are wondering about what the name means (N+1), follow the below example, which uses a single database:
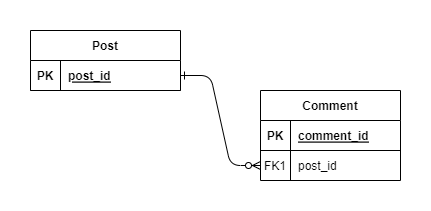 Illustration of N+1 problem
Illustration of N+1 problem
As you can see, the relationship between Post and Comment is one-to-many, respectively.
So, if your application needs to return a list of posts and their related comments, you might end up with this code:
const posts = await rawSql('SELECT * FROM "Post"'); // Get all posts (1 database query)
for (const post in posts) {
// For sure, you can replace the following query with an external request if you need to retrieve the post's comments from another service
const comments = await rawSql(`SELECT * FROM "Comment" WHERE "post_id" = ${post.id}`); // Get all comments for every post (n database query for n posts)
post.comments = comments;
}
So, you have executed N queries to retrieve every post’s comments and 1 query to retrieve all posts (N comments queries + 1 posts query).
But, why you should be aware of this problem?
Why Is the N+1 Query Problem a Serious Issue?
Here are some reasons why the N+1 query problem can cause serious performance issues in your application:
- Your application makes a lot of database queries or external requests to retrieve a list of data like posts.
- The more data your application retrieves, the slower your request is going to be and the more resources your application is going to consume.
- A large data set might end up with notable network latency.
- It is going to be challenging to scale the application to handle larger data sets.
On top of that, you are going to see the performance impact in numbers in the benchmarks section later in this article.
Now that you understand the N+1 query problem and its impact on your application, let’s introduce some effective ways you can avoid this problem.
Strategies to Avoid the N+1 Query Problem
Fortunately, there are a few simple strategies you can follow to avoid the N+1 query problem.
Let’s apply them to our previous example.
1) Eager Loading (Using SQL Joins, for example)
In this strategy, instead of returning the post’s comments separately for every post, you can use SQL Joins.
const postsAndComments = await rawSql(`
SELECT *
FROM "Post"
JOIN "Comment"
ON "Comment"."post_id" = "Post"."post_id"
`);
When you're using this strategy, it's good to know that:
- It is only one database query to return all posts and their nested comments.
- You can't apply this strategy if you are consuming your data sets from a different database or service.
2) Batch Loading
In this strategy, your code should follow the below steps:
- Execute one request to retrieve all posts.
- Execute another request to load a batch of posts’ comments instead of loading every post’s comments separately.
- Map every comment to its corresponding parent post.
Let’s jump into an example:
const posts = await rawSql('SELECT * FROM "Post"'), // 1- Retrieve all posts in one request
postsIds = posts.map(post => post.id),
postsComments = await rawSql(`SELECT * FROM "Comment" WHERE "post_id" IN (${postsIds})`); // 2- retrieve all posts’ comments in another request
for (const post in posts) { // 3- Map every comment to its parent post
const comments = postsComments.filter(comment => comment.post_id === post.id);
post.comments = comments;
}
As you see, in this strategy, there are just two requests: one to retrieve all posts and another one to retrieve their comments.
3) Caching
You may be familiar with caching and its impact on any application's performance.
You can implement caching on your client side or server side using Redis, Memcached, or any other similar tool. Wherever you can properly use caching, it significantly pushes your application's performance.
Let’s get back to our example and cache the posts’ comments in a Redis store.
const posts = await rawSql('SELECT * FROM "Post"'),
postsIds = posts.map(post => post.id),
cachedPostsComments = getPostsCommentsFromRedis(postsIds);
for (const post in posts) {
const comments = cachedPostsComments.filter(comment => comment.post_id === post.id);
post.comments = comments;
}
As you might guess, you can cache the posts’ comments or even the posts themselves which significantly minimizes the load on databases.
4) Lazy Loading
In this strategy, you are distributing the responsibility between the server side and the client side.
You shouldn’t return all data at once from the server side. Instead, you prepare two endpoints for the client side like this:
GET /api/posts: Retrieves all posts.GET /api/comments/:postId: Retrieves a post’s comments on demand.
And now, the data retrieval is up to the client side.
This strategy is very useful because:
- It enables the client side to load the parent post first and display its content, and then load its related comments lazily. So users don't have to wait for the entire data set to be returned from the server side.
- You have full control over sorting, filtering, pagination and so on over every endpoint.
The key point of this strategy is that it gets rid of nested data like comments and flattens all data sets in their own endpoint.
5) GraphQL Dataloader
As you might guess, this strategy works with GraphQL APIs.
Dataloader is a GraphQL utility that works by batching multiple database queries into one request. So, it uses the Batch Loading strategy under the hood.
Let’s jump into our example:
const DataLoader = require('dataloader');
// 1- GraphQL Schema Definition
const typeDefs = gql`
type Post {
post_id: ID!
comments: [Comment]
}
type Comment {
comment_id: ID!
post_id: ID!
}
type Query {
posts: [Post]
}
`;
// 2- Resolve the GraphQL Schema
const resolvers = {
Query: {
posts: async () => {
const posts = await rawSql('SELECT * FROM "Post"');
return posts;
}
},
Post: {
comments: (post, args, { dataLoaders }) => {
return dataLoaders.commentsLoader.load(post.id);
}
}
};
// 3- Define Dataloaders
const commentsBatchFunction = async postsIds => {
const comments = await rawSql(`SELECT * FROM "Comment" WHERE "post_id" IN (${postsIds})`);
const groupedComments = comments.reduce((tot, cur) => {
if (!tot[cur.post_id]) {
tot[cur.post_id] = [cur];
} else {
tot[cur.post_id].push(cur);
}
return tot;
}, {});
return postsIds.map((postId) => groupedComments[postId]);
},
createCommentsLoader = new DataLoader(commentsBatchFunction),
createDataloaders = () => ({
commentsLoader: createCommentsLoader()
});
// 4- Inject Dataloaders in the GraphQL Context
const server = new ApolloServer({
typeDefs,
resolvers,
context: () => {
return {
dataLoaders: createDataloaders(),
}
}
});
So how does it work? To get more detailed information, you can check out the documentation. But we'll go through the basics here.
The key point of the Dataloader is the Batch Function. Here, the batch function commentsBatchFunction takes an array of keys postsIds and returns a Promise which resolves to an array of values comments, [ [post1comment1, post1comment2], [post2comment1], ... ].
On top of that, the batch function has two constraints:
- The size of the keys array
postsIdsmust equal the values arraycomments. In other words, this expression must be true:postsIds.length === comments.length. - Each index in the keys array
postsIdsmust correspond to the values arraycomments. So you might note that I looped over thepostsIdsto map each corresponding comment.
As a result, you can see that GraphQL Dataloader uses the second strategy (Batch Loading) under the hood.
Let’s get back to our example to walk through its implementation:
- First, we defined the GraphQL schema.
- Then we resolved the GraphQL schema. Keep in mind, if you resolved the comments in the
Posttype using this queryawait rawSql('SELECT * FROM "Comment" WHERE "post_id" = ' + post.id);, you’re going to fall into the N+1 query problem. - Next, we defined the comments batch function and then created the comments dataloader.
- Finally, we injected dataloaders in the GraphQL Context to be able to use them in resolvers.
So, by using GraphQL Dataloader, if you have 10 posts and every post has 5 comments, you would end up with two queries – one to retrieve the 10 posts and another one to retrieve their comments.
Take a look at the following screenshot:
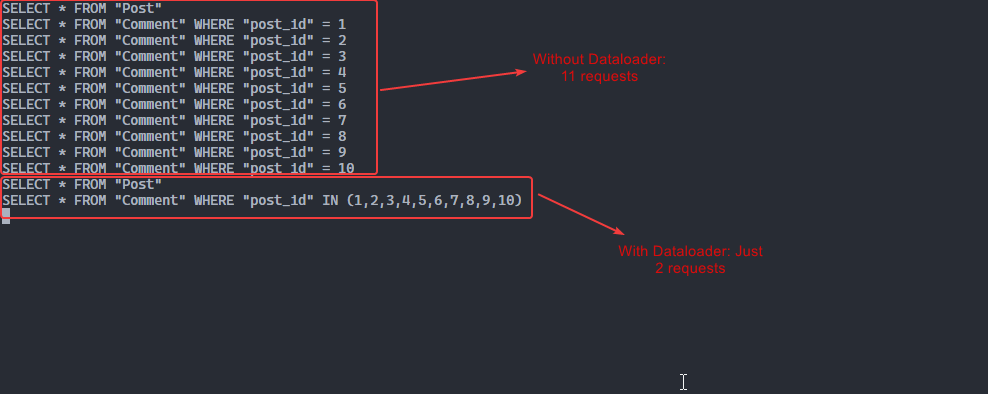 Illustration of process with and without Dataloader
Illustration of process with and without Dataloader
Benchmarks About N+1 Query Problem
In this section, let’s compare each strategy in terms of performance.
| N+1 in REST API | Eager Loading Strategy | Batch Loading Strategy | Caching Strategy | N+1 in GraphQL API | GraphQL Dataloader |
|---|---|---|---|---|---|
| 2.139 | 0.065 | 0.048 | 0.019 | 2.44 | 0.397 |
| 2.147 | 0.081 | 0.068 | 0.024 | 2.38 | 0.483 |
| 2.152 | 0.062 | 0.065 | 0.035 | 2.67 | 0.372 |
| 2.17 | 0.053 | 0.047 | 0.031 | 2.71 | 0.377 |
| 2.181 | 0.052 | 0.069 | 0.031 | 2.38 | 0.364 |
| 2.14 | 0.076 | 0.043 | 0.017 | 2.53 | 0.346 |
| 2.321 | 0.073 | 0.045 | 0.018 | 2.60 | 0.451 |
| 2.13 | 0.061 | 0.06 | 0.015 | 2.35 | 0.369 |
| 2.149 | 0.064 | 0.04 | 0.015 | 2.65 | 0.368 |
| 2.361 | 0.065 | 0.045 | 0.016 | 2.54 | 0.424 |
| 2.190 | 0.065 | 0.053 | 0.022 | 2.525 | 0.395 |
Note that the results of the Cache strategy are coming just after caching the data set. The first query is ignored as caching is missed.
These results were generated from the following environment:
- Seeded data: 1000 posts and 50 comments for every post.
- CPU: AMD Ryzen 5 3600 6-Core Processor 3.60 GHz.
- RAM: 32.0 GB.
- OS: Windows 10 Pro.
To be able to retest these strategies in your environment, follow these steps:
- Clone this repo.
- Then run
docker-compose up. - For GraphQL, open
http://localhost:3000/graphql. - A query suffers from the N+1 problem: query only
commentsWithNPlusOnein thePosttype. - Dataloader strategy: query only
commentsWithDataloaderin thePosttype. - For REST, follow these endpoints:
- A query suffers from the N+1 problem:
http://localhost:3000/api/postsWithNPlusOne. - Eager Loading strategy:
http://localhost:3000/api/postsWithEagerLoading. - Batch Loading strategy:
http://localhost:3000/api/postsWithBatchLoading. - Caching strategy:
http://localhost:3000/api/postsWithCache.
My notes about these benchmarks:
- These strategies are way too efficient.
- You may notice that the slower strategy in REST, the Eager Loading strategy, is about 34 times faster than the N+1 query in the REST API.
- The Dataloader strategy is about 6.4 times faster than the N+1 query in the GraphQL API.
- If you compared the results of REST and GraphQL APIs, you may notice that REST is faster than GraphQL. I think this is because of the internal implementations of GraphQL, which makes sense.
Conclusion
In this article, you learned that the N+1 query problem is a performance issue you might encounter when working with APIs.
You then learned about some strategies you can follow to avoid this problem like:
- Eager Loading using SQL Joins
- Batch Loading by executing fewer requests and then mapping each corresponding item to its parent.
- Caching using Redis
- Dataloader in the GraphQL world.
Finally, we created some benchmarks about the N+1 query problem so we could see how efficiently these strategies improve our API performance.
Before you leave
If you found this article useful, you can check out some of my other articles on my personal blog as well.
Thanks a lot for staying with me up till this point. I hope you enjoy reading this article.