
By Tal Perry
Developers have always had to work with text. So why does it suddenly feel like everyone is talking about NLP, GPT, and BERT all day?
In this article I'd like to give you a high level overview of what's been going on in the world of Natural Language Processing and Machine Learning, why people are so excited, and what it means for us as developers.
A bit of background
By the way, I'm Tal. I started off as a cook before becoming a backend developer and somehow ended up doing Natural Language Processing (NLP) for startups and banks. These days, I run my own NLP tooling company.
What I'll share below is based on what I've learned as a developer, data scientist, and today as a CEO working with other companies that do NLP.
To understand NLP today you need to understand what it was before. And the dividing line between now and before is deep learning. So we'll start with what came before deep learning and then talk about what deep learning changed.
Within the deep learning phase of NLP, there was another big shift which we'll call language modeling.
Still, this doesn't make any sense without a high level view of what deep learning actually is. So we'll explain the basics of deep learning really fast and then move into the present day, what's been going on, and what's about to happen.
What's Hard About Language
Here's something to think about: What has four letters, never has five letters, but sometimes has 9 letters.
That's not a question, it's a statement.
The word "What" has four letters, w-h-a-t. Most people get tripped up with that, because:
When we see a sentence starting with the word "What" we expect it to be a question
The period at the end of the sentence changed the meaning of most of the words
We didn't see the period until the end.
One of the hardest parts about language is that when we humans use it, we make a lot of inferences in some miraculous way. That's harder for computers. Let me explain.
Inference
Peter Norvig, Google's director of research, wrote his Ph.D. in 1987. It was called A Unified Theory of Inference for Text Understanding. His whole dissertation is basically about what inference is and why it's hard and how to approach it.
He opens the dissertation with a great observation:
People are very good at interpreting texts and making inferences. They generally do not notice when the text is under-specified and they have to make inferences to resolve ambiguities, or to gain a fuller understanding of the text.
As humans, we're used to making those inferences, like inferring (incorrectly ) that the What in my example sentence indicated a question.
Humans are really good at making inferences. Computers however, are terrible at it. Let me give you one more example out of Norvig's dissertation.
Chang The Fisherman
In a poor fishing village built on an island not far from the coast of China, a young boy named Chang Lee lived with his widowed mother. Every day, little Chang bravely set off with his net, hoping to catch a few fish from the sea...
To you it's obvious that there is a sea which surrounds the island, forms the coast of China, and that the villagers use for fishing.
But none of that information is stated in the text. Go ahead, reread it. And once you're satisfied that it's not there, think about this: How would you expect a computer to figure out those facts from the text ? That, in a nutshell, is what's hard about NLP.
What Deep Learning Changed
When I was coming of age as a developer, in the mid 2000s, "Machine Learning" and "Big Data" became buzzwords. And the systems we developers know and love, like Elasticsearch and Google, came to be.
Think about Google's search interface. All it has to do is take the user's text input and infer what the user wanted. The better Google does that, the more money they make.
There are many hard things about Google's job, but I want to focus on two of them.
The first is that, as far as a computer is concerned, a "word" is just a symbol and it doesn't have any meaning.
The second is that a word isn't enough – sometimes the user's intent is expressed in a whole phrase, and dealing with that in a tractable way is hard.
As an example, let's search Google for Mother Theresa's Mother
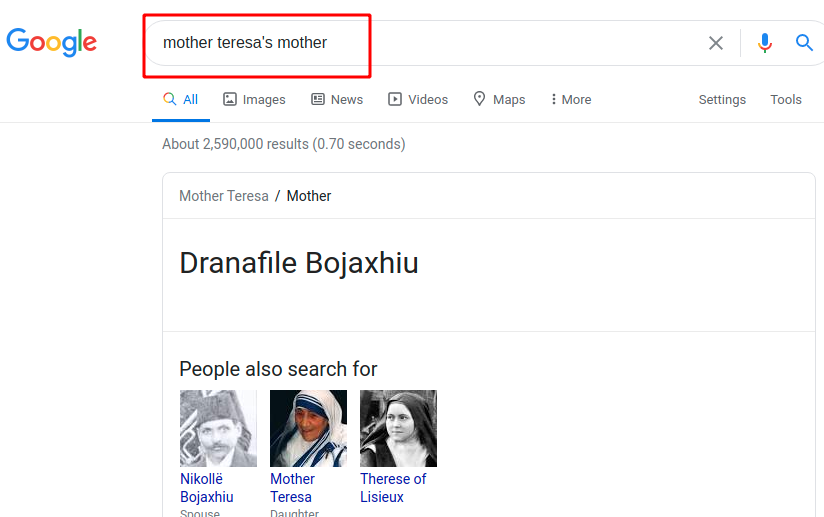
Google had to infer that "Mother Teresa" is a single entity, is a particular person, and that she has a "mother", which is a person related to her. That means they needed to process the user's query as a whole and figure out the correct sense of each word and phrase.
How would you go about doing that ? It wasn't impossible before deep learning, but it was something only Ph.D.s could do. But today it's pretty easy, so let's see what changed.
Meaning
In 2013 the Word2Vec algorithm was published by a team at Google. The premise was basically:
We need a way to associate the meaning of words
Computers suck at dealing with symbols like words
But they are awesome at dealing with numbers
Can we represent the meaning of a word with a bunch of numbers?
Word2Vec is an algorithm that figures out words' meanings and represents them to a computer as a bunch of numbers.
A more formal way to say "a bunch of numbers" is a vector (The vec in Word2Vec). When you think about "a bunch of numbers" as "vectors" you get to use all sorts of math kung-fu to make the vectors do what you want.
The big technical breakthrough with Word2Vec was that it gave a specific "kung fu kata", that is, an algorithm, to capture words' meanings in an efficient and usable way.
The other, no less significant breakthrough was that the demos were mind-blowing at the time.
For example, you could add and subtract these vectors, because they were mathy things, and the result would make intuitive sense. Like "King - Man + Woman = Queen"
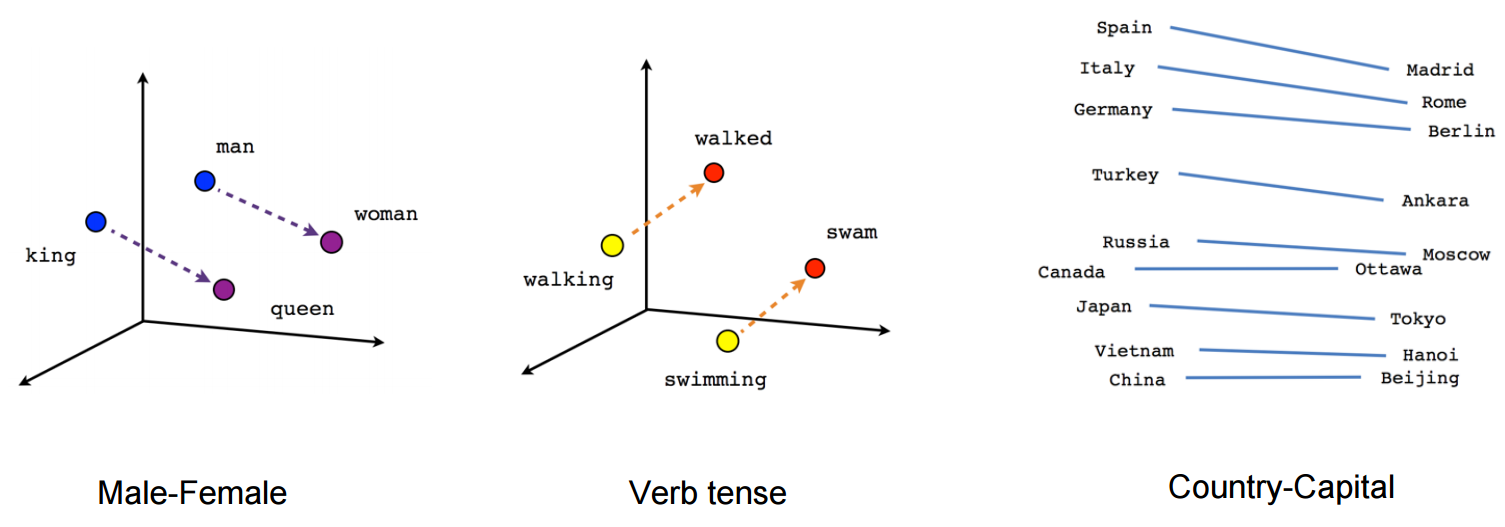
Words represented as vectors. These demos made Word2Vec compelling for a large audience
APIs
Word2Vec paved the way to work with the meaning of individual words, but deep learning made another change in how we work with language. Deep learning gave us convenient APIs to work with arbitrarily long sequences like phrases sentences and paragraphs.
Prior to deep learning, when developers wanted to analyze words in context, they would write functions to analyze the word before, the word before that, the word that came next, and so on.
They might write multiple functions for each word, like "Does the next word start with a capital letter" and "Is the the word that came two words before this one a verb".
Not only was this a laborious and hard to maintain process, it had surprising performance implications.
Chris Manning has a video (which I can't find) where he states that the major performance barrier for a pre-deep learning parser was loading all of the features (the results of those functions) into the CPU cache. There were just so many of them that you never had a cache hit.
So what did deep learning change? It removed the need to manually describe and program the interactions between words in a sequence.
Instead, we now have APIs that take a sequence of words (or vectors) as input and return a sequence that's been processed the way we want.
Gone are the days where we had to write 1000 functions and store a million columns for each word just to analyze some text. Today a sequence goes in and a sequence comes out with what we wanted.
But how does that happen? We'll need a few paragraphs about deep learning to understand.
Deep Learning in 3 minutes
To make it easy for a computer to learn something about data, we need to represent that data in a way that's easy for the computer to analyze.
Word2Vec was a big step in that direction, because it let us go from symbolic representations of a word to a vector representation, a bunch of numbers the computer can do math on.
A deep learning model is just a pipeline of mathematical operations that we do on input vectors. The cool part of it is that we go forwards and backwards in the pipeline.
To make a deep learning model learn, we put our input at the start of the pipeline and run it until the end. The model will have done some math and computed a result.
Then we go backwards, we compare the model's result to what the truth was, and calculate a score of how wrong the model was (called the loss). The learning part of deep learning is using optimization algorithms to make the loss as small as possible.
So what's changing in the our pipeline to optimize the score? Imagine we had an input X and our pipeline was "Multiple X by a and then add b". At each step in the optimization process we'd modify a and b to get the loss down and thus get a better prediction.
The thing is, we'd have many thousands or even millions of _a'_s and b's, and we can do fancier stuff than just multiply and add. We call those a's and b's parameters and the more of them we have the more "expressive" our model is, and the more it can learn.
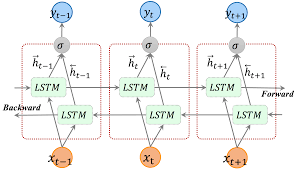
A deep learning "pipeline" showing how a sequence is processed from both left to right and right to left
Now if you're asking yourself how do you figure out the best pipeline or model to use, I have good news for you. Machine learning is a very open field, and most state of the art models are available as open source and can be run in a few lines of code.
Sounds amazing, right? So what's the catch?
Labeled data is Deep Learning's hidden cost
Deep learning models learn by looking at examples with some label indicating what we want them to predict.
If we want to make a model that predicts the sentiment of a product review, we'd need to train the model by showing it a review and the sentiment score that a human gave it.
The catch is that deep learning models need a lot of labeled data, and that data needs to be good. The more expressive a model is and the more parameters it has, the more labeled data it will need for training.
This is such a big issue, that I personally transitioned from being a data scientists to the founder of a Text Annotation Tool company.
Particularly in NLP (as opposed to vision), the people doing the annotations need to be domain experts, and they are expensive and don't think of annotation as their favorite thing to do.
We give them tools to label their data in-house and effectively. While we serve a niche, the market for outsourced annotations is even bigger with an estimated yearly spend in the billions.
That's to say that labeled data is a bottleneck, a cost center, and often a barrier to entry for deep learning. Reducing that barrier, and lowering the human costs of deep learning for NLP, is what's been going on recently and what we'll talk about next.
NLP in 2018 to 2020
I'm in the midst of potty training my son. We're at a point where he can signal us when he has a number one and the plan is that once he masters number one he'll be able to transfer that mastery to number two. I think it will be easier, and cleaner, to potty train him in that order.
The major trends of the last two years in NLP are like my son's potty training, we can train the model on a simpler task and transfer that knowledge on to a more advanced task.
But like I said before, getting labeled data is expensive, so we wouldn't want to train a model on a task we don't care about because we'd still need to pay for the annotation.
What if I told you that there are tasks we can pre-train our model on, where we can get unlimited labeled data for free?
Language Modeling
You know how some people are so close that they can complete each other's sentences? They can do that because they know that person and the language really well.
So well, in fact, that they have a mental model of the other person's thoughts and speaking style in their own head.
If we had a deep learning model for NLP that already knew how people talk and write, and could complete their sentences for them, it would have a much easier time learning some specific language task like figuring out the sentiment of a review.
A deep learning model that started with a sense of how people speak would be able to use that knowledge when it's learning a new task. Just like my son will be better at number two after he has mastered number one.
How do we get a model to learn about how people speak and write? Easy, we take some text, and ask the model to predict what word comes next.
That task is called "language modeling", and doing it well presupposes many abilities you wouldn't have thought of, like understanding grammar, counting, and tracking the relationship between words that are far apart.
A blog post that got me really excited about NLP was "The Unreasonable Effectiveness of Recurrent Neural Networks" which was written in 2015 by Andrej Karpathy (now head of AI at Tesla).
In the post, Karpathy built a language model of the Linux source code. He took all the code from Linux's github, had the model look at a few words, and then had it predict the next one.
My jaw dropped when he took that model, and used it in a loop to generate new text. He had the model make a prediction of the next letter, then fed that back into the model again and again. The model outputted code that looked like this:
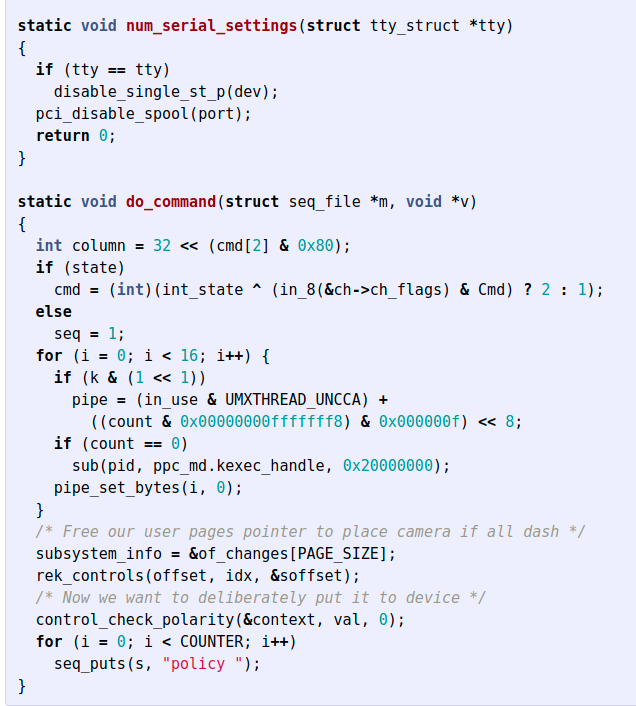
Code generated by a language model in 2015. Notice the indentation and use of comments
While the code above doesn't compile or do anything useful, it does show that a language model can learn a lot about how language is used. And this isn't just a gimmick – some of the AI powered code completion tools you've seen work exactly like this.
Language Modeling On Steroids
Between 2015 and today, NLP has taken that language modeling idea to its fullest potential.
In 2018, a paper was published that showed how you could consistently use a pre-trained language model to vastly improve a model's performance with a given amount of labeled data.
Quite soon afterwards, the world of NLP saw a deluge of new pre-trained models coming out, each one outperforming the last. You may have heard of models called BERT, XLNet, GPT 1, 2 and 3, and so on.
All of these models followed the basic concept of language modeling, each with some technical variants changed. But their real significance came from two factors.
First, they were trained on larger and larger datasets as larger and larger models. BERT, which came out in 2018, cost $6,800 to train, while GPT3, which has not been released publicly yet, cost $12 million to train.
Second, these pre-trained models were released to the public as open source software (GPT3 being unreleased, is the exception to the rule). Most of these pre-trained models have been released publicly, and wrapped behind convenient open source libraries like Huggingface's transformers.
For developers who just wanted to use the latest state of the art NLP, and get results without labeling tons of data, the openness and availability of these models changed the way we work.
What will happen next?
One of the most compelling NLP demos that's been circulating is GPT3 generating React code from free text.
Does that mean that some us are going to be unemployed soon? What else can these new NLP models automate away and what new things will come into existence because of them?
I don't know, and the history of NLP is 60 years of wrong predictions about both breakthroughs and limitations.
When I worked as a data scientist, I'd often share the results of my work with our non-technical business stakeholders – the people who were funding my salary.
As a junior, I'd often share results that were technically mind blowing, but my stakeholders didn't care. If they saw one silly mistake, they'd conclude that the model was dumb and not usable.
We called those mistakes "Howlers" because they made our stakeholders howl at us.
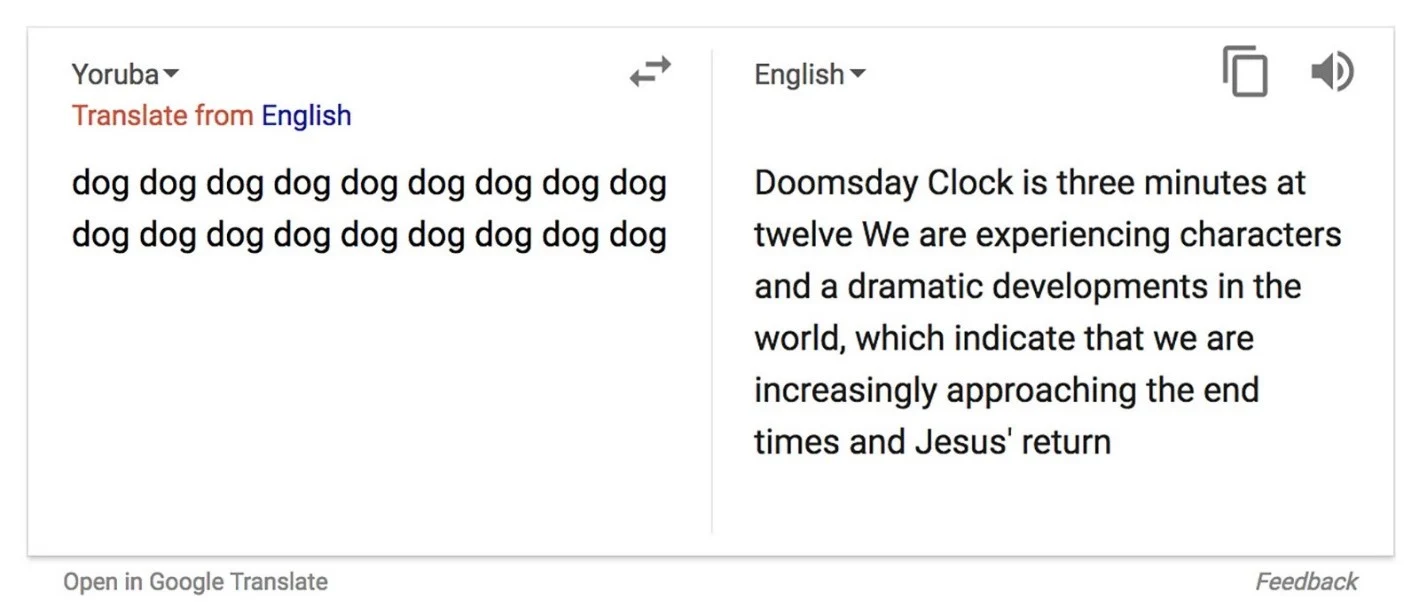
Google Translate giving a Howler
For companies, and developers who work at companies, the value of these new NLP models is conditioned on the business's ability to trust the model to do what's needed.
It's amazing that GPT3 can create React code, but would you trust it to generate your payment gateway or even generate a secure form for log in?
I think that the progress in NLP has made it more accessible to people and companies, easier to use, and less expensive.
But NLP is not a free lunch, and not a panacea. You'll still have to work hard to formulate your task, get labeled data for NLP, and check that your model is doing what you wanted it to do.
How to learn more
If you've gotten this far, I'm flattered, and you must be really curious about NLP and deep learning.
Even though this post was all about Deep Learning and NLP, I think that the methods that came before are worth knowing. Often times, they are easier to use than more modern methods, and do the job.
Even when they don't, much like my son being potty trained, I think it's easier to start with the simple and go from there. So I'd like to share some of my favorite resources in that spirit.
The first five chapters of Dan Jurafsky's and James Martin's Speech and Language Processing are fantastic introductions to classical methods.
Scikit-Learn's Text Analytics Tutorial has great hands on exercises that will give you a quick victory and a feel for the mechanics of basic NLP
I think that half the NLP problems developers face with text can be solved with a regular expression. If you're not a regex ninja yet, RegexOne is an amazing tutorial.
Natural Language Processing with Deep Learning is rigorous, thorough, and hands on and an amazing way to get a feel for the advanced topics we discussed here. It is a big time investment but very worth it.
Thanks for reading! You can check out my company LightTag and follow me on twitter.