
By Jeff M Lowery
In a previous post I confessed defeat in attempting to get an AWS Lambda GraphQL server to connect to a Firebase server. I didn’t give up right away, though, and a short time later found a different Node package to achieve what I couldn’t before.
Why use AWS Lambda to host a GraphQL server? Scalability would be the obvious reason, but I did it to learn.
And I learned a lot
Especially when it came to deployment. I used Netlify Functions to manage the deployment of both the AWS Lambda functions and the React client that calls them. There was more to this than I originally thought.
There are several ways to deploy a project using Netlify:
zip-it-and-ship-it
This is a utility that works a lot like webpack: for each function, it creates an archive file which bundles the function along with its dependencies. Like webpack, it only pulls in dependencies that are actually required by the function.
Netlify expects /functions folder by convention. When writing new functions, its source is at the same level as any NodeJS modules it needs as dependencies. If you add a new function that has new module dependencies, then they go into the node_modules folder (using yarn add or npminstall --save).
The following shows two lambda functions along with a single node_modules folder:
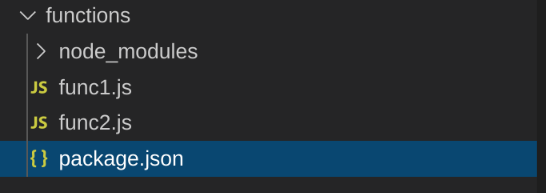
To use zip-it-and-ship-it, you write a simple JavaScript program that is called by the package.json build script.
zipIt.js
const { zipFunctions } = require('@netlify/zip-it-and-ship-it')zipFunctions('functions', 'functions-dist')
And this would be invoked something like so:
package.json
"build": "npm-run-all build:*","build:app": "react-scripts build","build:functions": "node ./zipFuncs.js",
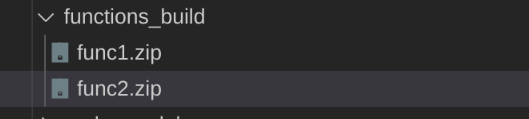
Once built, several .zip files are generated . Those archives contain the function code as well as a node_modules folder which is not the original, but contains only those dependencies needed by each function:
netlify-lambda
This deployment mechanism is similar to the above, but uses babel and webpack to perform its duties. If your comfortable and familiar with webpack, this might be the deployment option for you.
continuous deployment
The continuous deployment option is available if you’re using one of the supported repositories (GitHub, GitLab, or Bitbucket). Once you push changes to your repository, Netlify is notified and will run your build processes, which may involve zip-it-and-ship-it or netlify-lambda…but you also have the option of deploying unbundled functions to your repository, and Netlify will use zip-it-and-ship-it behind the scenes.
Netlify CLI
The Netlify CLI offers yet another way to deploy, without much fuss or mystery. There are two main deployment options:
netlify deploywill push the local project to a Netlify server. You first have to invoke the build step locally, though.netlify devcreates a local server, along with a proxy to your lambda functions, and kicks off the application. It does not require a build step.
There is also a script to help you create your lambda functions: netlify function:create. If you use this method, you will get a folder structure different than shown previously:
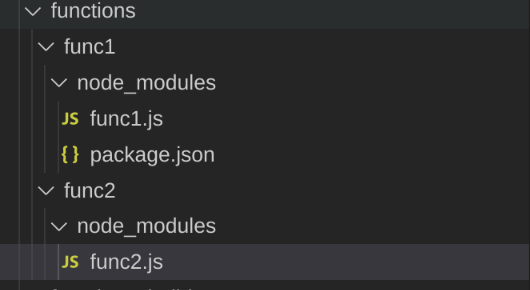
In this case, each function has its own folder, along with a node_modules and package.json file (plus others not shown, such as .lock files). Similar to what would be in the .zip archives that zip-it-and-ship-it creates.
Now, if you do generate your lambdas this way, continuous deployment will break, as zip-it-and-ship-it doesn’t handle this folder structure by itself. You can put something like this in your build script to fix continuous deployment:
"build": "npm-run-all build:*",
"build:app": "react-scripts build",
"build:functions": "yarn --cwd functions/func1 install",
"build:functions": "yarn --cwd functions/func2 install",
These build steps will install the dependencies needed by each lambda.
The Example
Your homework assignment is to set up a Netlify account and a Firebase account. The app will use Netlify Identity to login to the Netlify service. You will also need to grab a Firebase credentials JSON file and put it somewhere in your project (the example uses fake-creds.json, which is FAKE, so won’t work).
About the application
Being a geek, I’m building a database of chess openings. I have an openings book in a JSON file, from which I’ll load the database. In this somewhat contrived example, the book is actually stored with the lambda function in the /functions/pgnfen folder (netlify function:create pgnfen), however the loading is triggered by the React client through a GraphQL mutation call.
Creating the lambda function
I used apollo-server-lambda add a GraphQL API frontend to the Firestore database. To talk to Firestore, I use firebase-admin. When using netlify function:create to create your function, it will ask what template to use; in this case, the correct choice is in blue:

In addition, I have added some utility functions and supporting GraphQL schema and resolvers.
The lambda function
The core of the whole operation is in /functions/pgnfen.js. It creates the server, logs into firebase, makes the necessary GraphQL declarations, and finally invokes the handler function that receives requests from the client and passes them on to the database via GraphQL resolvers:
/* eslint-disable no-unused-vars */
const apolloLambda = require('apollo-server-lambda');
const admin = require('firebase-admin');
const typeDefs = require('./schema.gql');
const { fetchGames, addOpenings } = require('./resolvers');
const {
ApolloServer,
} = apolloLambda;
const credential = require('./fake-creds.json');
admin.initializeApp({
credential: admin.credential.cert(credential),
});
const resolvers = {
Query: {
allGames: (root, args, context) => [], //TBD
},
Mutation: {
addOpenings: async (root, args, context) => addOpenings(root, args, { ...context, admin }),
},
};
const server = new ApolloServer({
typeDefs,
resolvers,
});
exports.handler = server.createHandler(
{
cors: {
origin: '*',
credentials: true,
},
},
);
The Schema
The schema defines the GraphQL API. ‘Nuf said.
const typeDefs = `
type Mutation {
addOpenings(start: Int!, end: Int!) : Int!
}
`
module.exports = typeDefs;
The resolver
This resolves the GraphQL addOpenings mutation into Firestore queries (batched, in this case), then sends back a count of documents submitted (if successful):
const openings = require('./scid.js');
const addOpenings = async (_, { start, end }, { admin }) => {
const db = admin.firestore();
const batch = db.batch();
const fens = db.collection('chess/openings/fen');
const data = openings.slice(start, end);
data.forEach((opening) => {
const id = opening.fen.replace(/\//g, '$');
const doc = fens.doc(id);
batch.set(doc, opening);
});
await batch.commit();
return data.length;
};
module.exports = { addOpenings };
The opening book
The JSON version of the opening book consists of an SCID (an opening identifier based on ECO), as well as the opening name and its FEN. Each one becomes a document in the database.
/* eslint-disable comma-dangle */
module.exports = [
{
SCID: 'A00b',
desc: '"Barnes Opening"',
fen: 'rnbqkbnr/pppppppp/8/8/8/5P2/PPPPP1PP/RNBQKBNR b KQkq - 0 1'
},
{
SCID: 'A00b',
desc: '"Fried fox"',
fen: 'rnbqkbnr/pppp1ppp/8/4p3/8/5P2/PPPPPKPP/RNBQ1BNR b kq - 1 2'
},
{
SCID: 'A00c',
desc: '"Kadas Opening"',
fen: 'rnbqkbnr/pppppppp/8/8/7P/8/PPPPPPP1/RNBQKBNR b KQkq h3 0 1'
},
...
];
Creating the client
I’m using apollo-client in the React application. The easiest way to do so is create-react-app, then toss in [apollo-boost] to get a skeletal client up and running quickly. Then create a React component to trigger a call to the lambda, using the GraphQL API it provides.
The component will provide the start/end indices of the opening book to load, and a submit button.

Here’s a condensed version of the component code:
/* eslint-disable no-alert */
import React, { useState } from 'react';
import fetch from 'node-fetch';
import ApolloClient, { gql } from 'apollo-boost';
const styles = {
//...
};
const client = new ApolloClient({
uri: '/.netlify/functions/pgnfen', //the lambda URL
fetch,
});
export default () => {
const [start, setStart] = useState(0);
const [end, setEnd] = useState(5);
const clickHandler = async () => {
const mutation = gql`mutation {
addOpenings(start: ${start}, end: ${end})
}`;
// eslint-disable-next-line no-console
const count = await client.mutate({ mutation })
.catch((e) => { window.alert(e); });
// console.dir(count);
window.alert(`${count.data.addOpenings} documents written`);
};
const startEndHandler = (evt) => {
if (evt.target.name === 'start') {
setStart(evt.target.value);
} else {
setEnd(evt.target.value);
}
};
return (
//...
<input type="button" onClick={clickHandler} value="Load Scids" /> Row start:
<input name="start" type="number" step="5" style={styles.numInput} onChange={startEndHandler} value={start} />
Row end:
<input name="end" type="number" step="5" style={styles.numInput} onChange={startEndHandler} value={end} />
//...
);
};
And the mutation response will show in a window alert box:
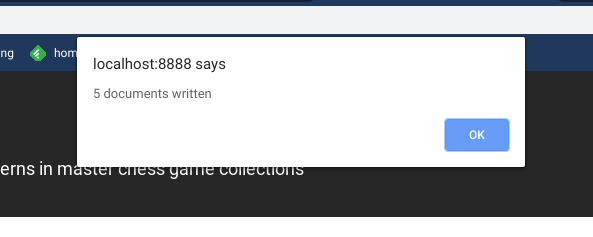
Added bonus!
Since I used apollo-server-lambda as a basis for the Netlify Function, I can go directly to the service endpoint via URL and it will bring up GraphQL Playground:
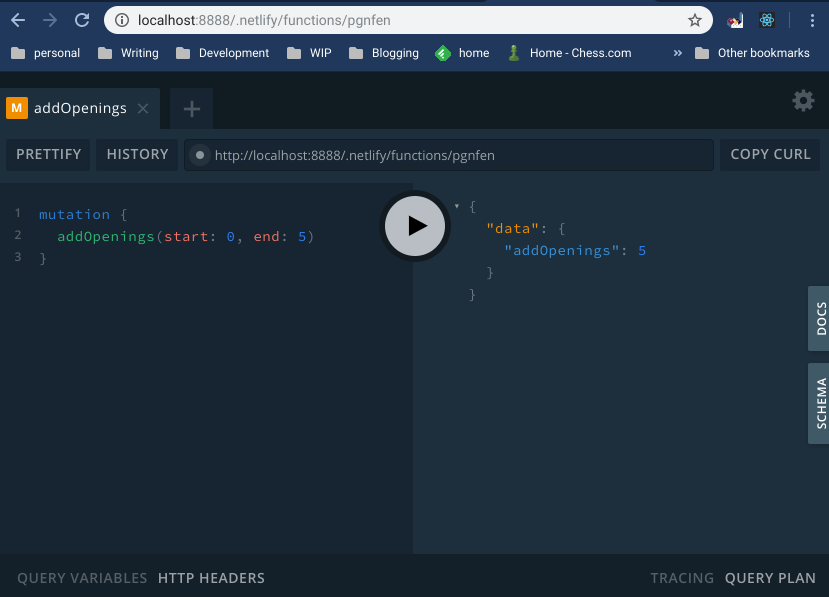
Here I can test queries and mutations prior to embedding them in my React client code.
Also, invoking netlify dev gives me a hot server courtesy of create-react-app, so I can see result of code changes in “real” time.
That’s it! Here’s a link to source.