
By François Paupier
Introduction
That’s a crazy flow of water. Just like your application deals with a crazy stream of data. Routing data from one storage to another, applying validation rules and addressing questions of data governance, reliability in a Big Data ecosystem is hard to get right if you do it all by yourself.
Good news, you don’t have to build your dataflow solution from scratch — Apache NiFi got your back!
At the end of this article, you’ll be a NiFi expert — ready to build your data pipeline.
What I will cover in this article:
- What Apache NiFi is, in which situation you should use it, and what are the key concepts to understand in NiFi.
What I won’t cover:
- Installation, deployment, monitoring, security, and administration of a NiFi cluster.
For your convenience here is the table of content, feel free to go straight where your curiosity takes you. If you’re a NiFi first-timer, going through this article in the indicated order is advised.
Table of Content
- I — What is Apache NiFi?
- Defining NiFi
- Why using NiFi?
- II — Apache Nifi under the microscope
- FlowFile
- Processor
- Process Group
- Connection
- Flow Controller
- Conclusion and call to action
What is Apache NiFi?
On the website of the Apache Nifi project, you can find the following definition:
An easy to use, powerful, and reliable system to process and distribute data.
Let’s analyze the keywords there.
Defining NiFi
Process and distribute data
That’s the gist of Nifi. It moves data around systems and gives you tools to process this data.
Nifi can deal with a great variety of data sources and format. You take data in from one source, transform it, and push it to a different data sink.
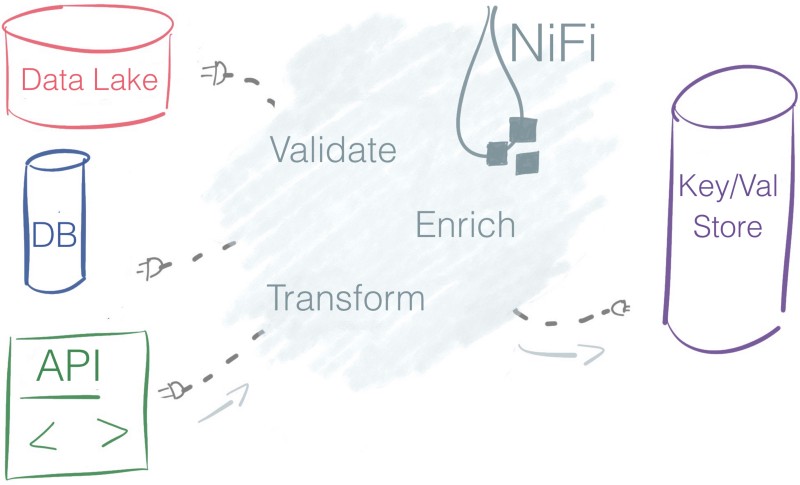
Easy to use
Processors — the boxes — linked by connectors — the arrows create a flow_. N_iFi offers a flow-based programming experience.
Nifi makes it possible to understand, at a glance, a set of dataflow operations that would take hundreds of lines of source code to implement.
Consider the pipeline below:
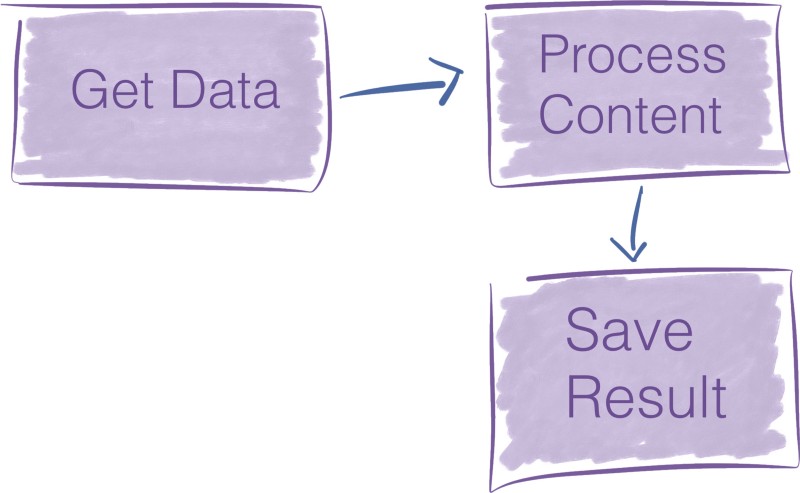
To translate the data flow above in NiFi, you go to NiFi graphical user interface, drag and drop three components into the canvas, and
That’s it. It takes two minutes to build.
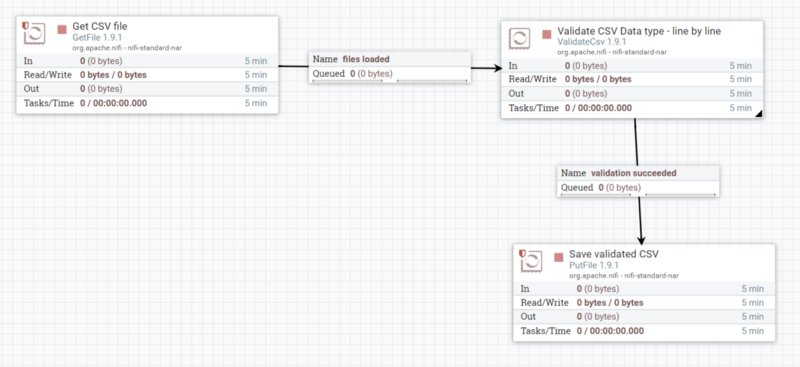
Now, if you write code to do the same thing, it’s likely to be a several hundred lines long to achieve a similar result.
You don’t capture the essence of the pipeline through code as you do with a flow-based approach. Nifi is more expressive to build a data pipeline; it’s designed to do that.
Powerful
NiFi provides many processors out of the box (293 in Nifi 1.9.2). You’re on the shoulders of a giant. Those standard processors handle the vast majority of use cases you may encounter.
NiFi is highly concurrent, yet its internals encapsulates the associated complexity. Processors offer you a high-level abstraction that hides the inherent complexity of parallel programming. Processors run simultaneously, and you can span multiple threads of a processor to cope with the load.
Concurrency is a computing Pandora’s box that you don’t want to open. NiFi conveniently shields the pipeline builder from the complexities of concurrency.
Reliable
The theory backing NiFi is not new; it has solid theoretical anchors. It’s similar to models like SEDA.
For a dataflow system, one of the main topics to address is reliability. You want to be sure that data sent somewhere is effectively received.
NiFi achieves a high level of reliability through multiple mechanisms that keep track of the state of the system at any point in time. Those mechanisms are configurable so you can make the appropriate tradeoffs between latency and throughput required by your applications.
NiFi tracks the history of each piece of data with its lineage and provenance features. It makes it possible to know what transformation happens on each piece of information.
The data lineage solution proposed by Apache Nifi proves to be an excellent tool for auditing a data pipeline. Data lineage features are essential to bolster confidence in big data and AI systems in a context where transnational actors such as the European Union propose guidelines to support accurate data processing.
Why using Nifi?
First, I want to make it clear I’m not here to evangelize NiFi. My goal is to give you enough elements so you can make an informed decision on the best way to build your data pipeline.
It’s useful to keep in mind the four Vs of big data when dimensioning your solution.

- Volume — At what scale do you operate? In order of magnitude, are you closer to a few GigaBytes or hundreds of PetaBytes?
- Variety — How many data sources do you have? Are your data structured? If yes, does the schema vary often?
- Velocity — What is the frequency of the events you process? Is it credit cards payments? Is it a daily performance report sent by an IoT device?
- Veracity — Can you trust the data? Alternatively, do you need to apply multiple cleaning operations before manipulating it?
NiFi seamlessly ingests data from multiple data sources and provides mechanisms to handle different schema in the data. Thus, it shines when there is a high variety in the data.
Nifi is particularly valuable if data is of low veracity. Since it provides multiple processors to clean and format the data.
With its configuration options, Nifi can address a broad range of volume/velocity situations.
An increasing list of applications for data routing solutions
New regulations, the rise of the Internet of Things and the flow of data it generates emphasize the relevance of tools such as Apache NiFi.
- Microservices are trendy. In those loosely coupled services, the data is the contract between the services. Nifi is a robust way to route data between those services.
- Internet of Things brings a multitude of data to the cloud. Ingesting and validating data from the edge to the cloud poses a lot of new challenges that NiFi can efficiently address (primarily through MiniFi, NiFi project for edge devices)
- New guidelines and regulations are put in place to readjust the Big Data economy. In this context of increasing monitoring, it is vital for businesses to have a clear overview of their data pipeline. NiFi data lineage, for example, can be helpful in a path towards compliance to regulations.
Bridge the gap between big data experts and the others
As you can see by the user interface, a dataflow expressed in NiFi is excellent to communicate about your data pipeline. It can help members of your organization become more knowledgeable about what’s going on in the data pipeline.
- An analyst is asking for insights about why this data arrives here that way? Sit together and walk through the flow. In five minutes you give someone a strong understanding of the Extract Transform and Load -ETL- pipeline.
- You want feedback from your peers on a new error handling flow you created? NiFi makes it a design decision to consider error paths as likely as valid outcomes. Expect the flow review to be shorter than a traditional code review.
Should you use it? Yes, No, Maybe?
NiFi brands itself as easy to use. Still, it is an enterprise dataflow platform. It offers a complete set of features from which you may only need a reduced subset. Adding a new tool to the stack is not benign.
If you are starting from scratch and manage a few data from trusted data sources, you may be better off setting up your Extract Transform and Load — ETL pipeline. Maybe a change data capture from a database and some data preparations scripts are all you need.
On the other hand, if you work in an environment with existing big data solutions in use (be it for storage, processing or messaging ), NiFi integrates well with them and is more likely to be a quick win. You can leverage the out of the box connectors to those other Big Data solutions.
It’s easy to be hyped by new solutions. List your requirements and choose the solution that answers your needs as simply as possible.
Now that we have seen the very high picture of Apache NiFi, we take a look at its key concepts and dissect its internals.
Apache Nifi under the microscope
“NiFi is boxes and arrow programming” may be ok to communicate the big picture. However, if you have to operate with NiFi, you may want to understand a bit more about how it works.
In this second part, I explain the critical concepts of Apache NiFi with schemas. This black box model won’t be a black box to you afterward.
Unboxing Apache NiFi
When you start NiFi, you land on its web interface. The web UI is the blueprint on which you design and control your data pipeline.
In Nifi, you assemble processors linked together by connections. In the sample dataflow introduced previously, there are three processors.
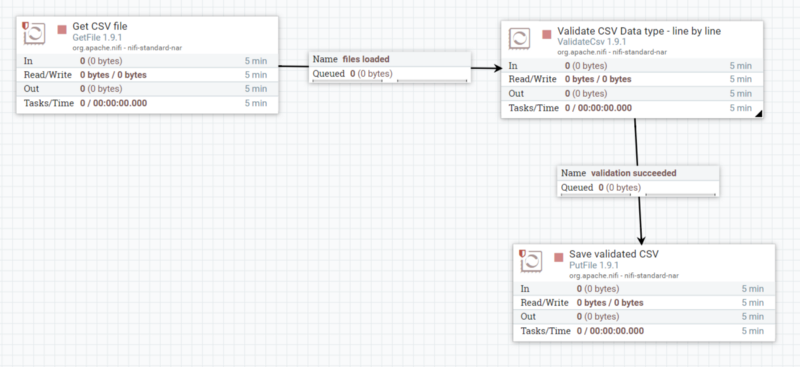
The NiFi canvas user interface is the framework in which the pipeline builder evolves.
Making sense of Nifi terminology
To express your dataflow in Nifi, you must first master its language. No worries, a few terms are enough to grasp the concept behind it.
The black boxes are called processors, and they exchange chunks of information named FlowFiles through queues that are named connections. Finally, the FlowFile Controller is responsible for managing the resources between those components.
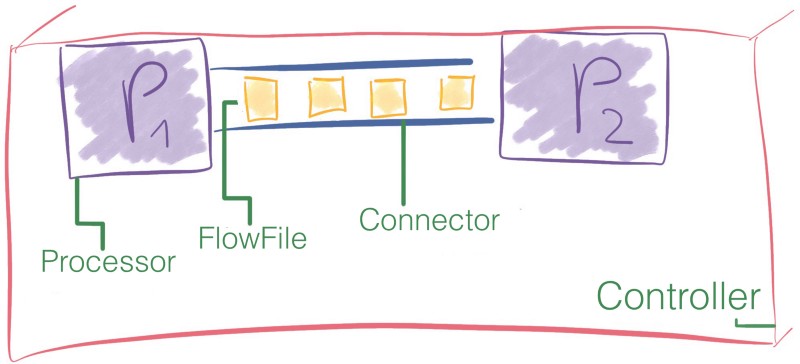
Let’s take a look at how this works under the hood.
FlowFile
In NiFi, the FlowFile is the information packet moving through the processors of the pipeline.

A FlowFile comes in two parts:
- Attributes, which are key/value pairs. For example, the file name, file path, and a unique identifier are standard attributes.
- Content, a reference to the stream of bytes compose the FlowFile content.
The FlowFile does not contain the data itself. That would severely limit the throughput of the pipeline.
Instead, a FlowFile holds a pointer that references data stored at some place in the local storage. This place is called the Content Repository.
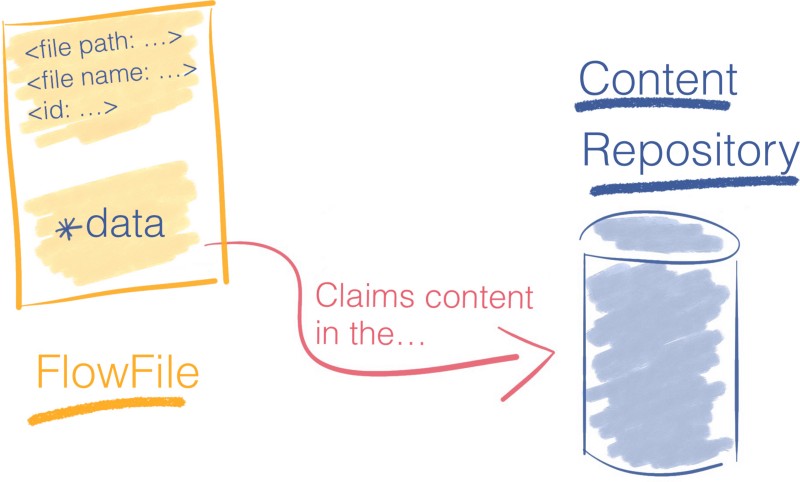
To access the content, the FlowFile claims the resource from the Content Repository. The later keep tracks of the exact disk offset from where the content is and streams it back to the FlowFile.
Not all processors need to access the content of the FlowFile to perform their operations — for example, aggregating the content of two FlowFiles doesn’t require to load their content in memory.
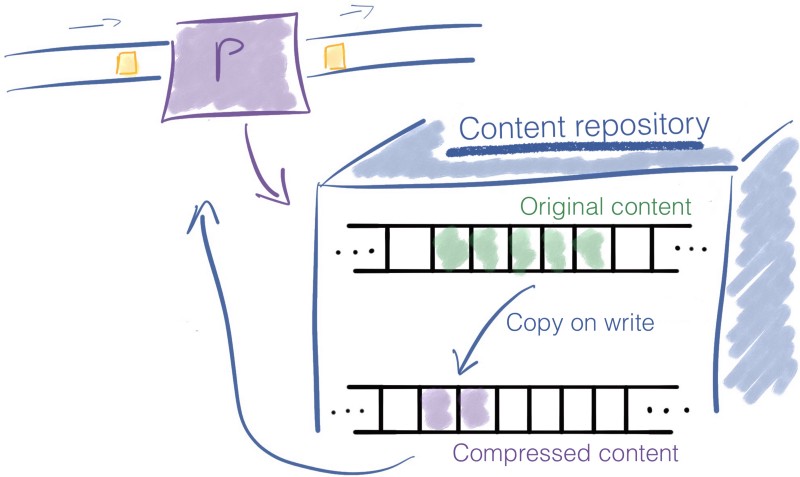
When a processor modifies the content of a FlowFile, the previous data is kept. NiFi copies-on-write, it modifies the content while copying it to a new location. The original information is left intact in the Content Repository.
Example
Consider a processor that compresses the content of a FlowFile. The original content remains in the Content Repository, and a new entry is created for the compressed content.
The Content Repository finally returns the reference to the compressed content. The FlowFile is updated to point to the compressed data.
The drawing below sums up the example with a processor that compresses the content of FlowFiles.
Reliability
NiFi claims to be reliable, how is it in practice? The attributes of all the FlowFiles currently in use, as well as the reference to their content, are stored in the FlowFile Repository.
At every step of the pipeline, a modification to a Flowfile is first recorded in the FlowFile Repository, in a write-ahead log, before it is performed.
For each FlowFile that currently exist in the system, the FlowFile repository stores:
- The FlowFile attributes
- A pointer to the content of the FlowFile located in the FlowFile repository
- The state of the FlowFile. For example: to which queue does the Flowfile belong at this instant.
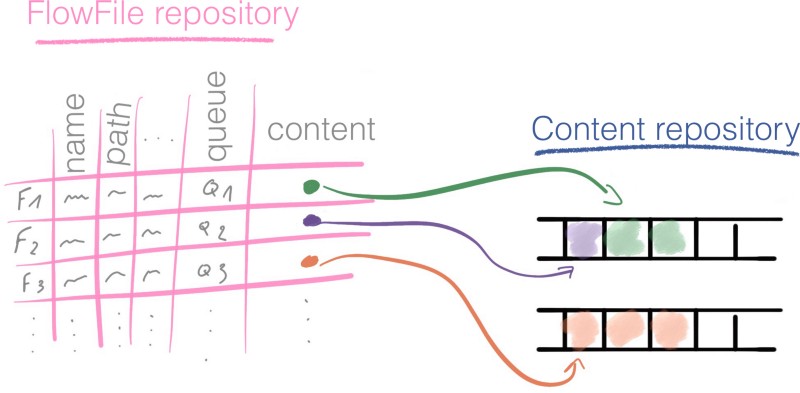
The FlowFile repository gives us the most current state of the flow; thus it’s a powerful tool to recover from an outage.
NiFi provides another tool to track the complete history of all the FlowFiles in the flow: the Provenance Repository.
Provenance Repository
Every time a FlowFile is modified, NiFi takes a snapshot of the FlowFile and its context at this point. The name for this snapshot in NiFi is a Provenance Event. The Provenance Repository records Provenance Events.
Provenance enables us to retrace the lineage of the data and build the full chain of custody for every piece of information processed in NiFi.
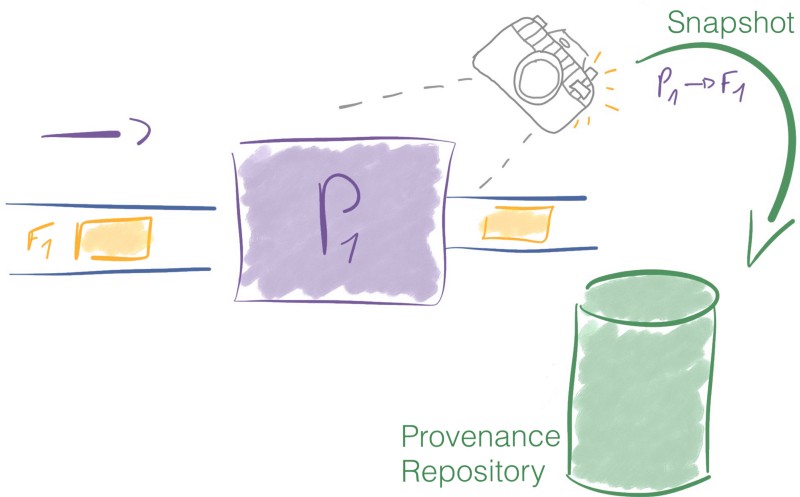
On top of offering the complete lineage of the data, the Provenance Repository also offers to replay the data from any point in time.
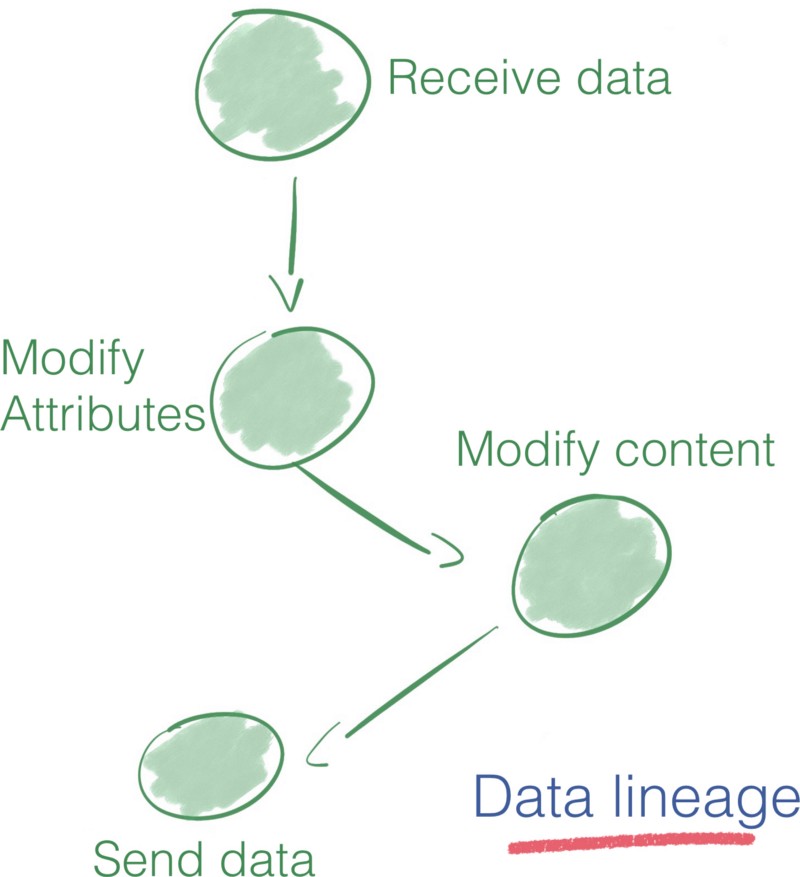
Wait, what’s the difference between the FlowFile Repository and the Provenance Repository?
The idea behind the FlowFile Repository and the Provenance Repository is quite similar, but they don’t address the same issue.
- The FlowFile repository is a log that contains only the latest state of the in-use FlowFiles in the system. It is the most recent picture of the flow and makes it possible to recover from an outage quickly.
- The Provenance Repository, on the other hand, is more exhaustive since it tracks the complete life cycle of every FlowFile that has been in the flow.
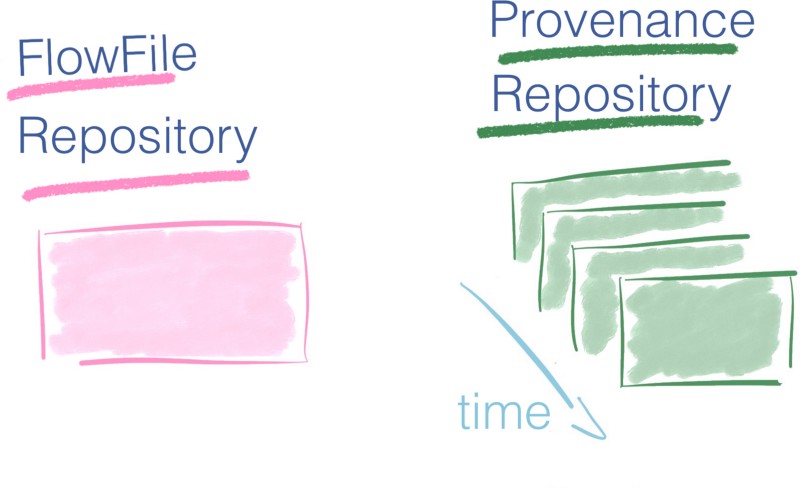
If you have only the most recent picture of the system with the FlowFile repository, the Provenance Repository gives you a collection of photos — a video. You can rewind to any moment in the past, investigate the data, replay operations from a given time. It provides a complete lineage of the data.
FlowFile Processor
A processor is a black box that performs an operation. Processors have access to the attributes and the content of the FlowFile to perform all kind of actions. They enable you to perform many operations in data ingress, standard data transformation/validation tasks, and saving this data to various data sinks.
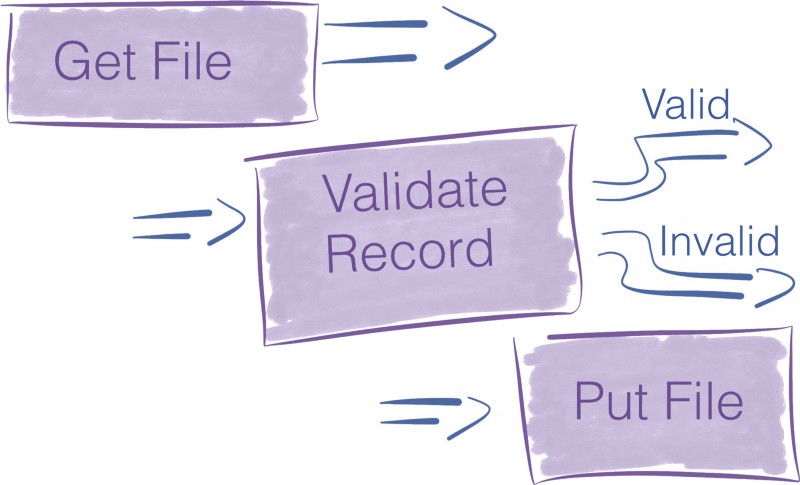
NiFi comes with many processors when you install it. If you don’t find the perfect one for your use case, it’s still possible to build your own processor. Writing custom processors is outside the scope of this blog post.
Processors are high-level abstractions that fulfill one task. This abstraction is very convenient because it shields the pipeline builder from the inherent difficulties of concurrent programming and the implementation of error handling mechanisms.
Processors expose an interface with multiple configuration settings to fine-tune their behavior.
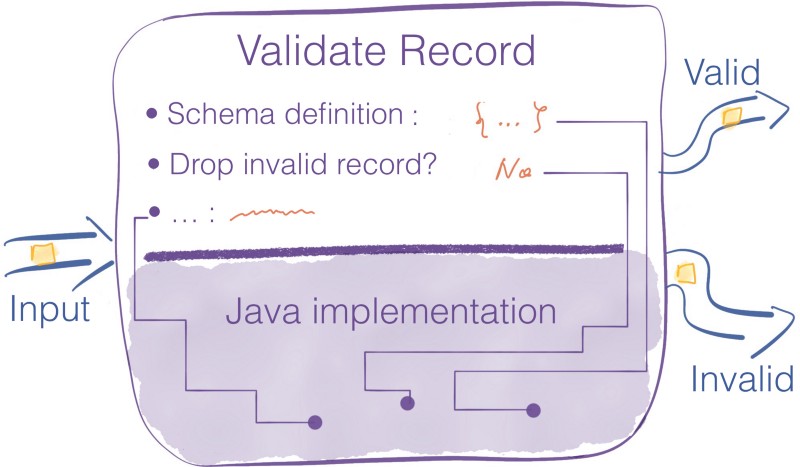
The properties of those processors are the last link between NiFi and the business reality of your application requirements.
The devil is in the details, and pipeline builders spend most of their time fine-tuning those properties to match the expected behavior.
Scaling
For each processor, you can specify the number of concurrent tasks you want to run simultaneously. Like this, the Flow Controller allocates more resources to this processor, increasing its throughput. Processors share threads. If one processor requests more threads, other processors have fewer threads available to execute. Details on how the Flow Controller allocates threads are available here.
Horizontal scaling. Another way to scale is to increase the number of nodes in your NiFi cluster. Clustering servers make it possible to increase your processing capability using commodity hardware.
Process Group
This one is straightforward now that we’ve seen what processors are.
A bunch of processors put together with their connections can form a process group. You add an input port and an output port so it can receive and send data.
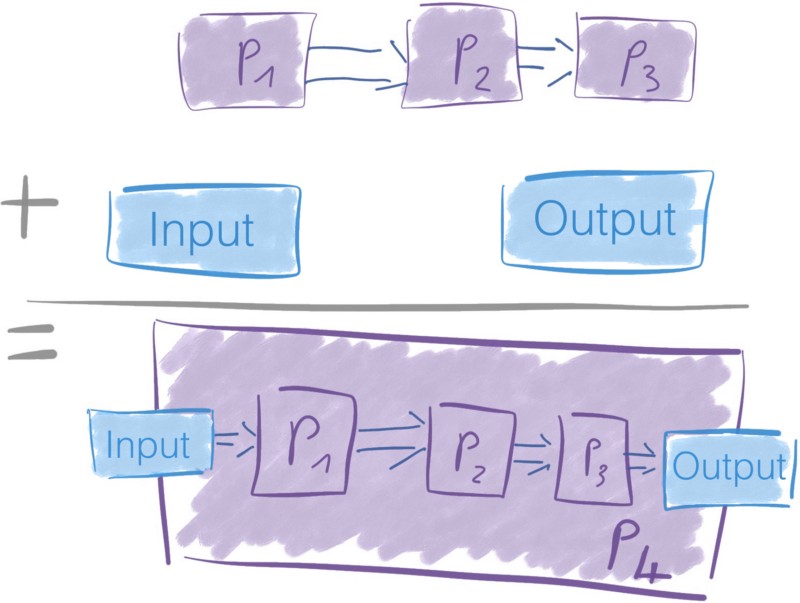
Processor groups are an easy way to create new processors based from existing ones.
Connections
Connections are the queues between processors. These queues allow processors to interact at differing rates. Connections can have different capacities like there exist different size of water pipes.
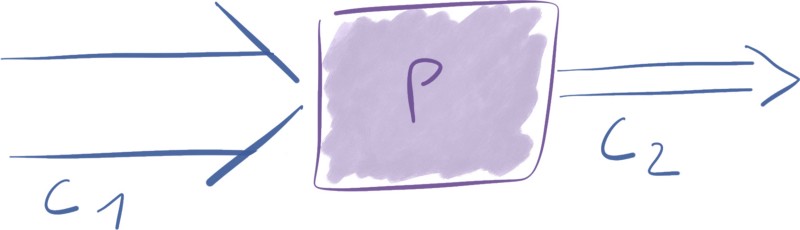
Because processors consume and produce data at different rates depending on the operations they perform, connections act as buffers of FlowFiles.
There is a limit on how many data can be in the connection. Similarly, when your water pipe is full, you can’t add water anymore, or it overflows.
In NiFi you can set limits on the number of FlowFiles and the size of their aggregated content going through the connections.
What happens when you send more data than the connection can handle?
If the number of FlowFiles or the quantity of data goes above the defined threshold, backpressure is applied. The Flow Controller won’t schedule the previous processor to run again until there is room in the queue.
Let’s say you have a limit of 10 000 FlowFiles between two processors. At some point, the connection has 7 000 elements in it. It is ok since the limit is 10 000. P1 can still send data through the connection to P2.

Now let’s say that processor one sends 4 000 new FlowFiles to the connection.
7 0000 + 4 000 = 11 000 → We go above the connection threshold of 10 000 FlowFiles.
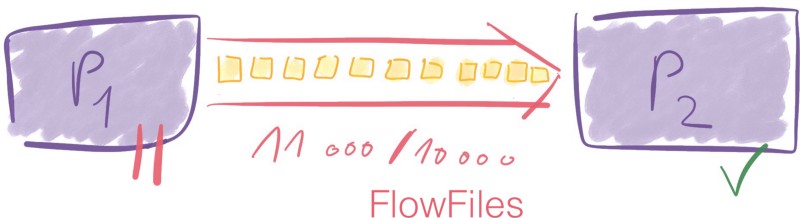
The limits are soft limits, meaning they can be exceeded. However, once they are, the previous processor, P1 won’t be scheduled until the connector goes back below its threshold value — 10 000 FlowFiles.
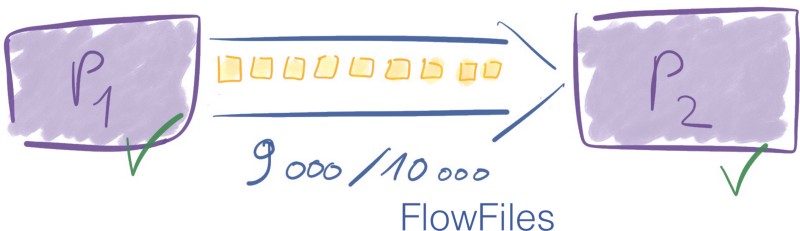
This simplified example gives the big picture of how backpressure works.
You want to setup connection thresholds appropriate to the Volume and Velocity of data to handle. Keep in mind the Four Vs.
The idea of exceeding a limit may sound odd. When the number of FlowFiles or the associated data go beyond the threshold, a swap mechanism is triggered.
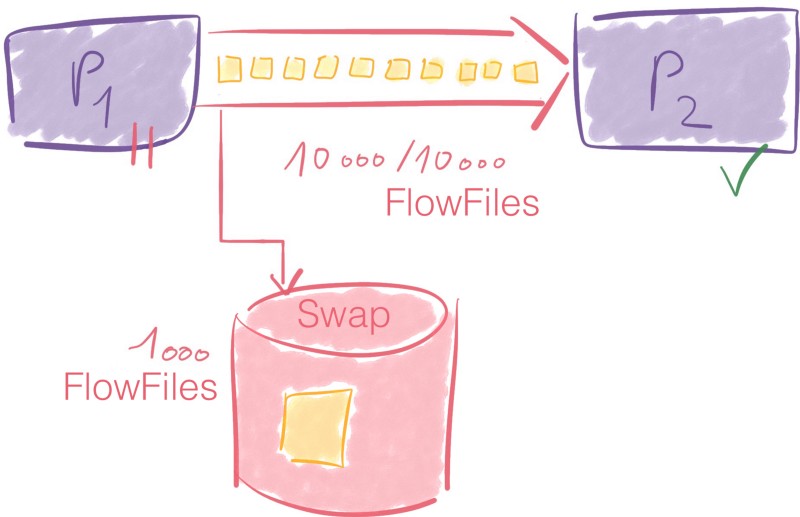
For another example on backpressure, this mail thread can help.
Prioritizing FlowFiles
The connectors in NiFi are highly configurable. You can choose how you prioritize FlowFiles in the queue to decide which one to process next.
Among the available possibility, there is, for example, the First In First Out order — FIFO. However, you can even use an attribute of your choice from the FlowFile to prioritize incoming packets.
Flow Controller
The Flow Controller is the glue that brings everything together. It allocates and manages threads for processors. It’s what executes the dataflow.
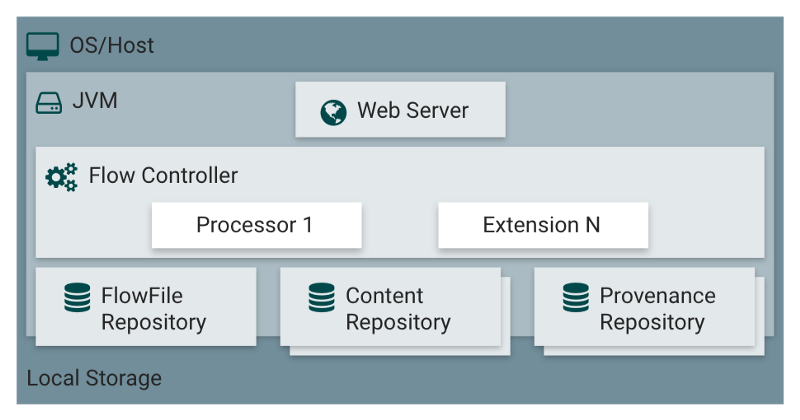
Also, the Flow Controller makes it possible to add Controller Services.
Those services facilitate the management of shared resources like database connections or cloud services provider credentials. Controller services are daemons. They run in the background and provide configuration, resources, and parameters for the processors to execute.
For example, you may use an AWS credentials provider service to make it possible for your services to interact with S3 buckets without having to worry about the credentials at the processor level.
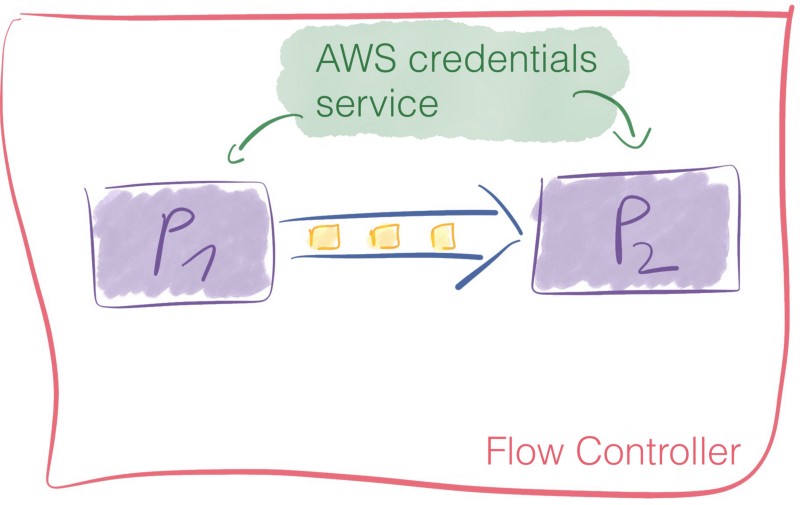
Just like with processors, a multitude of controller services is available out of the box.
You can check out this article for more content on the controller services.
Conclusion and call to action
In the course of this article, we discussed NiFi, an enterprise dataflow solution. You now have a strong understanding of what NiFi does and how you can leverage its data routing features for your applications.
If you’re reading this, congrats! You now know more about NiFi than 99.99% of the world’s population.
Practice makes perfect. You master all the concepts required to start building your own pipeline. Make it simple; make it work first.
Here is a list of exciting resources I compiled on top of my work experience to write this article.
Resources ?
The bigger picture
Because designing data pipeline in a complex ecosystem requires proficiency in multiple areas, I highly recommend the book Designing Data-Intensive Applications from Martin Kleppmann. It covers the fundamentals.
- A cheat sheet with all the references quoted in Martin’s book is available on his Github repo.
This cheat sheet is a great place to start if you already know what kind of topic you’d like to study in-depth and you want to find quality materials.
Alternatives to Apache Nifi
Other dataflow solutions exist.
Open source:
- Streamsets is similar to NiFi; a good comparison is available on this blog
Most of the existing cloud providers offer dataflow solutions. Those solutions integrate easily with other products you use from this cloud provider. At the same time, it solidly ties you to a particular vendor.
- Azure Data Factory, A Microsoft solution
- IBM has its InfoSphere DataStage
- Amazon proposes a tool named Data Pipeline
- Google offers its Dataflow
- Alibaba cloud introduces a service DataWorks with similar features
NiFi related resources
- The official Nifi documentation and especially the Nifi In-depth section are gold mines.
- Registering to Nifi users mailing list is also a great way to be informed — for example, this conversation explains back-pressure.
- Hortonworks, a big data solutions provider, has a community website full of engaging resources and how-to for Apache Nifi.
— This article goes in depth about connectors, heap usage, and back pressure.
— This one shares dimensioning best practices when deploying a NiFi cluster. - The NiFi blog distills a lot of insights NiFi usage patterns as well as tips on how to build pipelines.
- Claim Check pattern explained
- The theory behind Apache Nifi is not new, Seda referenced in Nifi Doc is extremely relevant
— Matt Welsh. Berkeley. SEDA: An Architecture for Well-Conditioned, Scalable Internet Services [online]. Retrieved: 21 Apr 2019, from http://www.mdw.la/papers/seda-sosp01.pdf