By Aviator Ifeanyichukwu
Data Orchestration involves using different tools and technologies together to extract, transform, and load (ETL) data from multiple sources into a central repository.
Data orchestration typically involves a combination of technologies such as data integration tools and data warehouses.
Apache Airflow is a tool for data orchestration.
With Airflow, data teams can schedule, monitor, and manage the entire data workflow. Airflow makes it easier for organizations to manage their data, automate their workflows, and gain valuable insights from their data
In this guide, you will be writing an ETL data pipeline. It will download data from Twitter, transform the data into a CSV file, and load the data into a Postgres database, which will serve as a data warehouse.
External users or applications will be able to connect to the database to build visualizations and make policy decisions.
What you will learn
- How to extract data from Twitter
- How to write a DAG script
- How to load data into a database
- How to use Airflow Operators
What you need
To follow along with this tutorial, you'll need the following:
- Apache Airflow installed on your machine
- Airflow development environment up and running
- An understanding of the building blocks of Apache Airflow (Tasks, Operators, etc)
- An IDE of your choice. Mine is VsCode.
Sounds interesting yeah? Let’s begin.
How to Get the Data from Twitter
Twitter is a social media platform where users gather to share information and discuss trending world events/topics. Tons of data is generated daily through this platform. This will be your data source.
To get data from Twitter, you need to connect to its API. Numerous libraries make it easy to connect to the Twitter API. For this guide, we'll use snscrape. You will also need Pandas, a Python library for data exploration and transformation.
Installation
Make sure your Airflow virtual environment is currently active.
pip install snscrape pandas
Inside the Airflow dags folder, create two files: extract.py and transform.py.
extract.py:
import snscrape.modules.twitter as sntwitter
import pandas as pd
from transform import transform_data
# Creating list to append tweet data to
def extract_data():
# scrape tweets and append to a list
for i,tweet in enumerate(sntwitter.TwitterSearchScraper('Chatham House since:2023-01-14').get_items()):
if i>1000:
break
tweets_list.append([tweet.date, tweet.user.username, tweet.rawContent,
tweet.sourceLabel,tweet.user.location
])
# convert tweets into a dataframe
tweets_df = pd.DataFrame(tweets_list, columns=['datetime', 'username', 'text', 'source', 'location'])
# save tweets as csv file
transform_data(tweets_df)
transform.py:
import pandas as pd
from airflow.hooks.postgres_hook import PostgresHook
# Load clean data into postgres database
def task_data_upload(data):
print(data.head() )
data = data.to_csv(index=None, header=None)
postgres_sql_upload = PostgresHook(postgres_conn_id="postgres_connection")
postgres_sql_upload.bulk_load('twitter_etl_table', data)
return True
## perform data cleaning and transformation
def transform_data(tweets_df):
print(tweets_df.info() )
### Transformation happens here
# load transformed data into database
task_data_upload(tweets_df)
###
The Database
Airflow comes with a SQLite3 database. To store your data, you'll use PostgreSQL as a database.
You should have PostgreSQL installed and running on your machine.
Install the libraries
pip install psycopg2
If this fails, try installing the binary version like this:
pip install psycopg2-binary
Install the provider package for the Postgres database like this:
pip install apache-airflow-providers-postgres
How to Set Up the DAG Script
Create a file named etl_pipeline.py inside the dags folder.
Start by importing the different airflow operators like this:
from airflow import DAG
from airflow.operators.empty import EmptyOperator
from datetime import datetime, timedelta
with DAG(
'etl_twitter_pipeline',
description="A simple twitter ETL pipeline using Python,PostgreSQL and Apache Airflow",
start_date=datetime(year=2023, month=2, day=5),
schedule_interval=timedelta(minutes=2)
) as dag:
start_pipeline = EmptyOperator(
task_id='start_pipeline',
)
start_pipeline
With a dag_id named 'etl_twitter_pipeline', this dag is scheduled to run every two minutes, as defined by the schedule interval.
How to View the Web UI
Start the scheduler with this command:
airflow scheduler
Then start the web server with this command:
airflow webserver
Open the browser on localhost:8080 to view the UI.
Search for a dag named ‘etl_twitter_pipeline’, and click on the toggle icon on the left to start the dag.
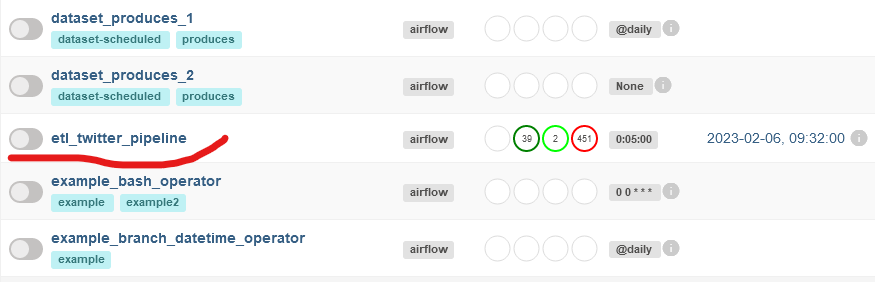 Airflow UI showing created dags
Airflow UI showing created dags
How to Set Up a Postgres Database Connection
You should already have apache-airflow-providers-postgres and psycopg2 or psycopg2-binary installed in your virtual environment.
From the UI, navigate to Admin -> Connections. Click on the plus sign at the top left corner of your screen to add a new connection and specify the connection parameters. Click on test to verify the connection to the database server. Once completed, scroll to the bottom of the screen and click on Save.
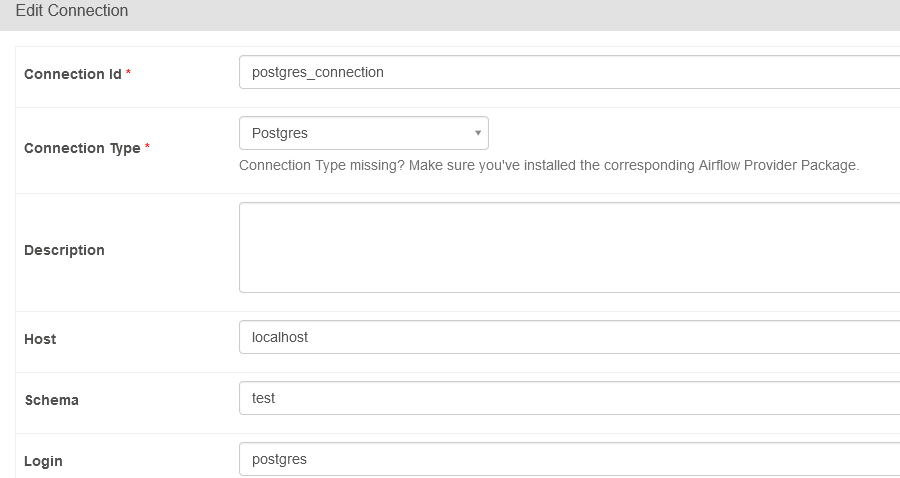 PostgreSQL database connection
PostgreSQL database connection
Inside the Airflow directory created in the virtual environment, open the airflow.cfg file in your text editor, locate the variable named sql_alchemy_conn, and set the PostgreSQL connection string:
sql_alchemy_conn = postgresql+psycopg2://postgres:1234@localhost:5432/test
The Airflow executor is currently set to SequentialExecutor. Change this to LocalExecutor:
executor = LocalExecutor
 Airflow DAG Executor
Airflow DAG Executor
The Airflow UI is currently cluttered with samples of example dags. In the airflow.cfg config file, find the load_examples variable, and set it to False.
load_examples = False
 Disable example dags
Disable example dags
Restart the webserver, reload the web UI, and you should now have a clean UI:
 Airflow UI
Airflow UI
How to Use the Postgres Operator
Start by importing the different Airflow operators. You'll also need to import the extract and transform Python files.
etl_pipeline.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.empty import EmptyOperator
from airflow.operators.postgres_operator import PostgresOperator
from datetime import datetime, timedelta
from extract import extract_data
with DAG(
'etl_twitter_pipeline',
description="A simple twitter ETL pipeline using Python,PostgreSQL and Apache Airflow",
start_date=datetime(year=2023, month=2, day=5),
schedule_interval=timedelta(minutes=5)
) as dag:
start_pipeline = EmptyOperator(
task_id='start_pipeline',
)
create_table = PostgresOperator(
task_id='create_table',
postgres_conn_id='postgres_connection',
sql='sql/create_table.sql'
)
etl = PythonOperator(
task_id = 'extract_data',
python_callable = extract_data
)
clean_table = PostgresOperator(
task_id='clean_sql_table',
postgres_conn_id='postgres_connection',
sql=["""TRUNCATE TABLE twitter_etl_table"""]
)
end_pipeline = EmptyOperator(
task_id='end_pipeline',
)
sql/create_table.sql
sql="""CREATE TABLE IF NOT EXISTS twitter_etl_table(
id SERIAL PRIMARY KEY,
datetime DATE NOT NULL,
username VARCHAR(200) NOT NULL,
text TEXT,
source VARCHAR(200),
location VARCHAR(200)
);"""
The create_table task makes a connection to postgres to create a table.
The ETL task makes a call to the extract_data() function which is where our ETL data processing takes place.
The clean_table task invokes the postgresOperator which truncates the table of previous contents before new contents in inserted into the postgres table.
The end_pipeline marks the end of the task definition.
How to Create Dependencies Between Tasks
The last step is to create a dependencies between tasks, to enable Airflow to know the order of priority to schedule tasks.
start_pipeline >> create_table >> clean_table >> etl >> end_pipeline
How to Test the Workflow
To start, click on the 'etl_twitter_pipeline' dag. Click on the graph view option, and you can now see the flow of your ETL pipeline and the dependencies between tasks.
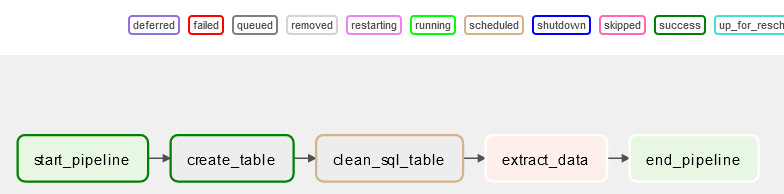 Airflow running data pipeline
Airflow running data pipeline
And there you have it – your ETL data pipeline in Airflow. I hope you found it useful and yours is working properly.
Conclusion
Apache Airflow is an easy-to-use orchestration tool making it easy to schedule and monitor data pipelines. With your knowledge of Python, you can write DAG scripts to schedule and monitor your data pipeline.
In this guide, you learned how to set up an ETL pipeline using Airflow and also how to schedule and monitor the pipeline.
You also have seen the usage of some Airflow operators such as PythonOperator, PostgresOperator, and EmptyOperator.
I hope you learned something from this guide.