

What are Regular Expressions?
Regular expressions, also known as regex, work by defining patterns that you can use to search for certain characters or words inside strings.
Once you define the pattern you want to use, you can make edits, delete certain characters or words, substitute one thing for another, extract relevant information from a file or any string that contains that particular pattern, and so on.
Why Should You Learn Regex?
Regex let you to do text processing in a way that can save you a lot of time. It can also introduce some fun in the process.
Using regex can make locating information much easier. Once you find your target, you can batch edit/replate/delete or whatever processing you need to do.
Some practical examples of using regex are batch file renaming, parsing logs, validating forms, making mass edits in a codebase, and recursive search.
In this tutorial, we're going to cover regex basics with the help of this site. Later on, I will introduce some regex challenges that you'll solve using Python. I'll also show you how to use tools like sed and grep with regex.
Like many things in life, regular expressions are one of those things that you can only truly understand by doing. I encourage you to play around with regex as you are going through this article.
Table of Contents
- Regex Basics
- How to use regex with command line tools
- Advanced Regex: Lookarounds
- Practical Examples of Regex
- Final words
Regex Basics
A regular expression is nothing but a sequence of characters that match a pattern. Besides using literal characters (like 'abc'), there are some meta characters (*,+,? and so on) which have special purposes. There are also features like character classes which can help you simplify your regular expressions.
Before writing any regex, you'll need to learn about all the basic cases and edge cases for the pattern you are looking for.
For instance, if you want to match 'Hello World', do you want the line to start with 'Hello' or can it start with anything? Do you want exactly one space between 'Hello' and 'World' or there can be more? Can other characters come after 'World' or should the line end there? Do you care about case sensitivity? And so on.
These are the kind of questions you must have the answer to before you sit down to write your regex.
Exact match
The most basic form of regex involves matching a sequence of characters in a similar way as you can do with Ctrl-F in a text editor.

On the top you can see the number of matches, and on the bottom an explanation is provided for what the regex matches character by character.
Character set
Regex character sets allow you to match any one character from a group of characters. The group is surrounded by square brackets [].
For example, t[ah]i matches "tai" and "thi". Here 't' and 'i' are fixed but between them can occur 'a' or 'h'.
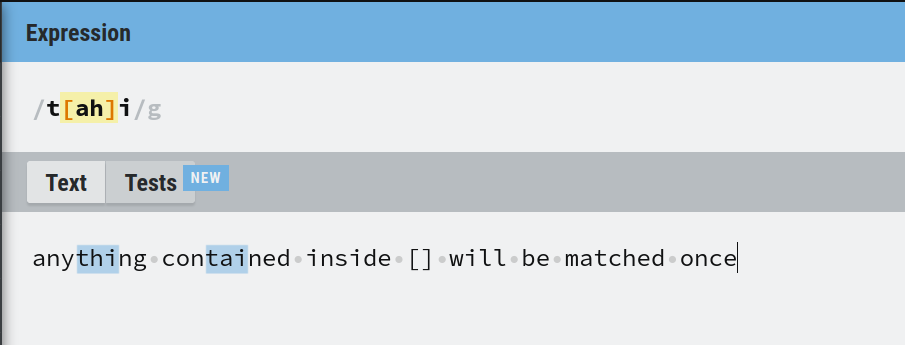
Match ranges in regex
Sometimes you may want to match a group of characters which are sequential in nature, such as any uppercase English letter. But writing all 26 letters would be quite tedious.
Regex solves this issue with ranges. The "-" acts as a range operator. Some valid ranges are shown below:
| Range | Matches |
| [A-Z] | uppercase letters |
| [a-z] | lowercase letters |
| [0-9] | Any digit |
You can also specify partial ranges, such as [b-e] to match any of the letters 'bcde' or [3-6] to match any of the numbers '3456'.
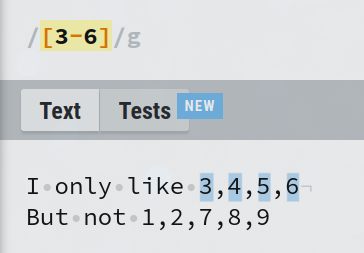
You are not limited to specifying only one range inside a character set. You can use multiple ranges and also combine them with any other additional character(s). Here, [3-6u-w;] will match any of '3456uvw' or semicolon ';'.

Match any character not in the set
If you prefix the set with a '^', the inverse operation will be performed. For example, [^A-Z0-9] will match anything except uppercase letters and digits.

Character classes
While writing regex, you'll need to match certain groups such as digits quite often and multiple times in the same expression as well.
So for example, how would you match a pattern like 'letter-digit-letter-digit'?
With what you've learned up until now, you can come up with [a-zA-Z]-[0-9]-[a-zA-z]-[0-9]. This works, but you can see how the expression can get quite messy as the pattern length gets bigger.
To make the expression simpler, classes have been assigned to well-defined character groups such as digits. The following table shows these classes and their equivalent expression with character sets:
| Class | Matches | Equivalent expression |
| . | anything except newline | [^\n\r] |
| \w | word character | [a-zA-Z0-9_] |
| \W | non-word character | [^\w] |
| \d | digits | [0-9] |
| \D | non-digits | [^\d] |
| \s | space, tab, newlines | [ \t\r\n\f] |
| \S | non whitespace characters | [^\s] |
Character classes are quite handy and make your expressions much cleaner. We will use them extensively throughout this tutorial, so you can use this table as a reference point and come back here if you forget any of the classes.
Most of the time, we won't care about all the positions in a pattern. The "." class saves us from writing all possible characters in a set.
For example, t.. matches anything that starts with t and any two characters afterwards. This may remind you of the SQL LIKE operator which would use t%% to accomplish the same thing.

Quantifiers
The word "pattern" and "repetition" go hand in hand. If you want to match a 3 digit number you can use \d\d\d. But what if you need to match 11 digits? You could write '\d' 11 times, but a general rule of thumb while writing regex or just doing any kind of programming is that if you find yourself repeating something more than twice, you are probably unaware of some feature.
In regex, you can use quantifiers for this purpose. To match 11 digits, you can simply write the expression \d{11}.
The table below lists the quantifiers you can use in regex:
| Quantifier | Matches |
| * | 0 or more |
| ? | 0 or 1 |
| + | 1 or more |
| {n} | exactly n times |
| {n, } | n or more times |
| {n, m} | n to m times inclusive |
In this example, the expression can\s+write matches can followed by 1 or more whitespaces followed by write. But you can see 'canwrite' is not matched as \s+ means at least one whitespace needs to be matched. This is useful when you are searching through text which is not trimmed.
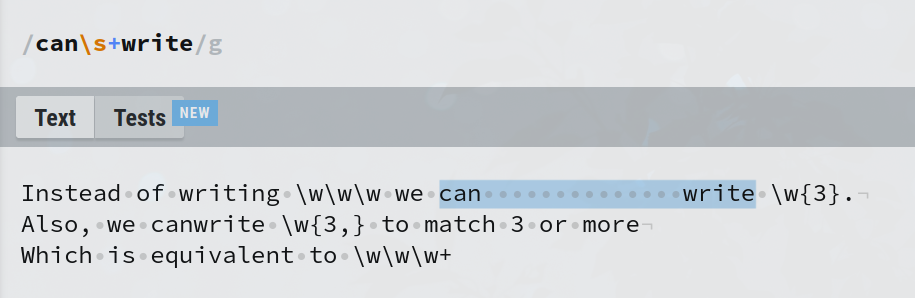
Can you guess what can\s?write will match?
Capture groups
Capture groups are sub-expressions enclosed in parentheses (). You can have any number of capture groups, and even nested capture groups.
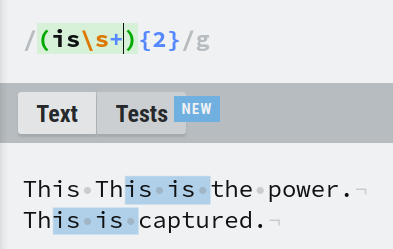
The expression (The ){2} matches 'The ' twice. But without a capture group, the expression The {2} would match 'The' followed by 2 spaces, as the quantifier will be applied on the space character and not on 'The ' as a group.
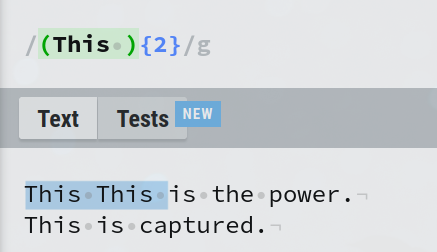
You can match any pattern inside capture groups as you would with any valid regex. Here (is\s+){2} matches if it finds 'is' followed by 1 or more spaces twice.
How to use logical OR in regex
You can use "|" to match multiple patterns. This is (good|bad|sweet) matches 'This is ' followed by any of 'good' or 'bad' or 'sweet'.

Again, you must understand the importance of capture groups here. Think about what the expression This is good|bad|sweet would match?

With a capture group, good|bad|sweet is isolated from This is. But if it's not inside a capture group, the entire regex is only one group. So the expression This is good|bad|sweet will match if the string contains 'This is good' or 'bad' or 'sweet'.
How to reference capture groups
Capture groups can be referenced in the same expression or while performing replacements as you can see on the Replacement tab.
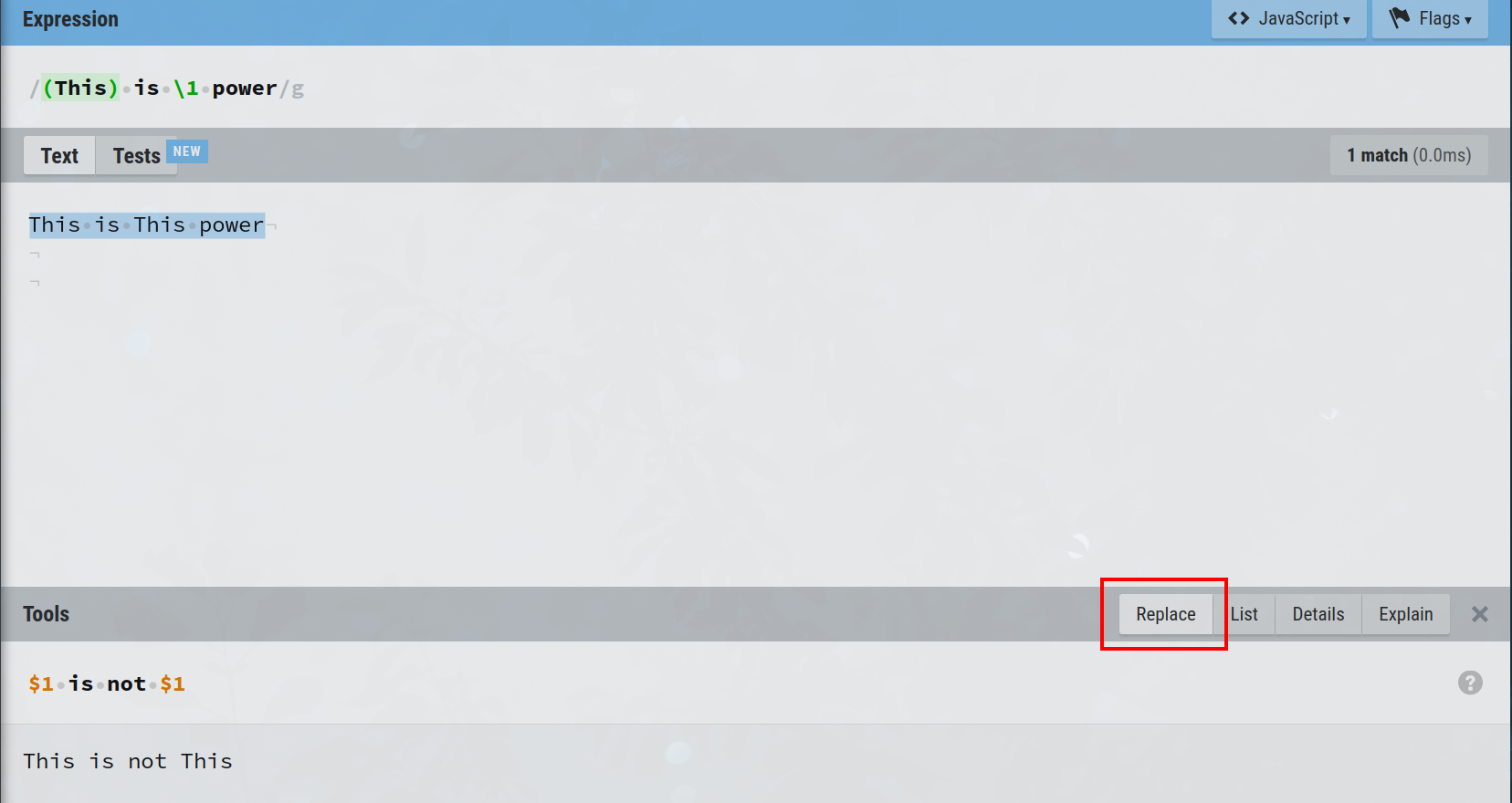
Most tools and languages allow you to reference the nth captured group with '\n'. In this site '$n' is used while referencing on replacement. The syntax for replacement will vary depending on the tools or language you're using. For JavaScript, for example, its '$n', while for Python its '\n'.
In the expression (This) is \1 power, 'This' is captured and then referenced with '\1', effectively matching This is This power.
How to name capture groups
You can name your capture groups with the syntax (?<name>pattern) and backreference them in the same expression with \k<name>.
On replacement, referencing is done by $<name>. This is the syntax for JavaScript and can vary among languages. You can learn about the differences here. Also note that this feature might not be available in some languages.
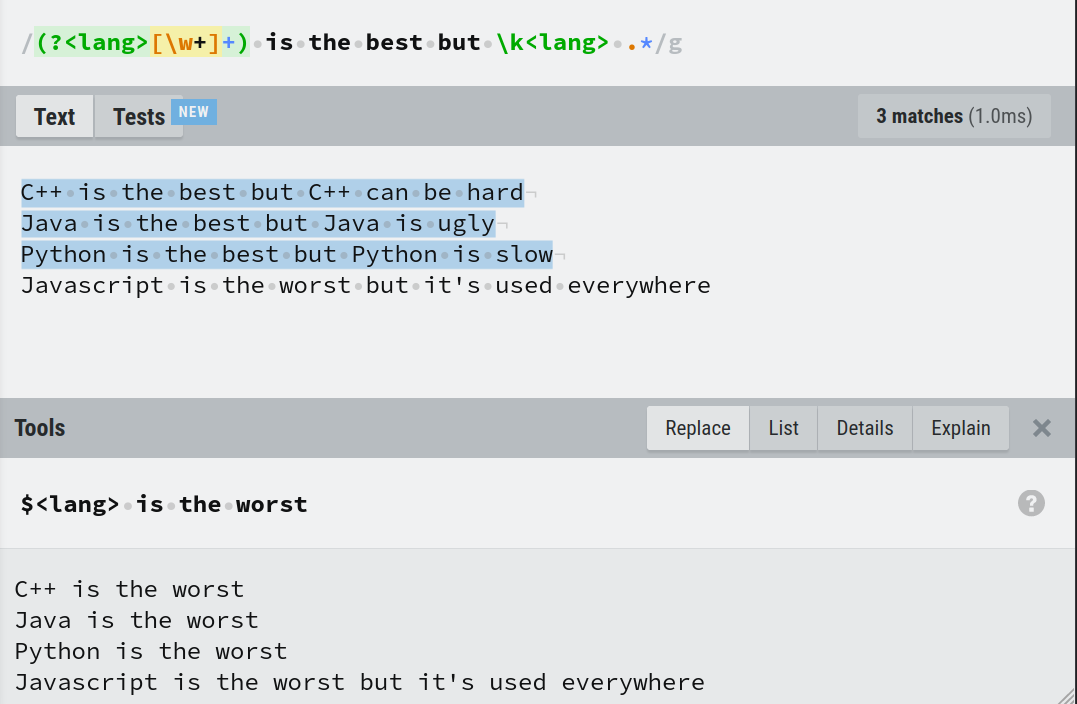
In the expression (?<lang>[\w+]+) is the best but \k<lang> .*, the pattern [\w+]+ is captured with the name 'lang' and backreferenced with \k<lang>. This pattern will match any word character or '+' character 1 or more times. The .* at the end of the regex matches any character 0 or more times. And finally on replacement, the referencing is done by $<lang>.
How to Use Regex with Command Line Tools
There are good CLI tools available that let you perform regex from your terminal. These tools save you even more time as you can easily test different regex without writing code in some langauge and then compiling or interpreting it.
Some of the well-known tools are grep, sed, and awk. Let's look at a few examples to give you some ideas on how you can leverage these tools.
Recursive regex search with grep
You can execute the power of regex through grep. Grep can search patterns in a file or perform recursive search.
If you are on Windows, you can install grep using winget. Run this command in powershell:
winget install -e --id GnuWin32.Grep
I will show you the solution to a challenge I created for a CTF competition at my university.
The file attached to the challenge is a zip file that contains multiple levels of directories and a lot of files in it. The name of the competition was Coderush with flag format coderush{flag is here}. So you have to search for the pattern coderush{.*} which will match the flag format coderush{any character here}.
Unzip the file with unzip ripG.zip and cd into it with cd ripG.
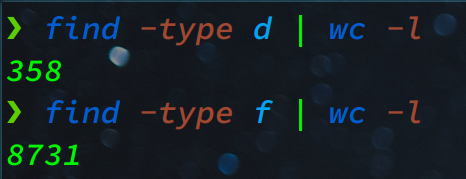
There are 358 directories and 8731 files. Instead of searching the pattern in the files one by one, you can employ grep like this:
grep --color -R "coderush{.*}"
The "-R" flag enables recursive search.

You can learn more about grep and its command line options here
Substitution with sed
You can use sed to perform insertion, deletion, substitution on text files by specifying a regex. If you are on windows, you can get sed from here. Or if you use WSL, tools like grep and sed will already be available.
This is the most common usage of sed:
sed 's/pattern/replacement/g' filename
echo "${text}" | sed 's/pattern/replacement/g'
Here, the option "g" is specified to replace all occurrences.
Some other useful options are -n to suppress the default behaviour of printing all lines and using p instead of g to print only the lines which are affected by the regex.
Let's take a look at the content of texts.txt.
Hello rand chars World 56 rand chars
Henlo 52 rand chars W0rld rand chars
GREP rand chars Henlo 62 rand chars
Henlo 10 rand chars Henlo rand chars
GREP rand chars Henlo 45 rand chars
Our task is replacing Henlo number with Hello number only in the lines where "GREP" is present. So, we are searching for the pattern Henlo ([0-9]+) which will match 'Henlo ' followed by 1 or more digits and all the digits are captured. Then our replacement string will be Hello \1 – the '\1' is referencing the capture group containing the digits.
One way to accomplish that would be using grep to grep the lines which have "GREP" present then perform the replacement with sed.
grep "GREP" texts.txt | sed -En 's/Henlo ([0-9]+)/Hello \1/p'
The "-E" option enables extended regex without which you would need to escape the parentheses.

Or you could just use sed. Use /pattern/ to restrict substitution on only the lines where pattern is present.
sed -En '/GREP/ s/Henlo ([0-9]+)/Hello \1/p' texts.txt
Advanced Regex: Lookarounds
Lookaheads and Lookbehinds (together known as lookarounds) are features of regex that allow you to check the existence of a pattern without including it in the match.
You can think of them as zero width assertions – they assert the existence of a pattern but do not consume any characters in the match. These are very powerful features, but they're also computationally expensive. So make sure you keep an eye on performance if you are using them often.
Lookbehinds
Let's say you want to match the word 'linux', but you have 2 conditions.
- The word 'GNU' must occur before 'linux' occurs. If a line contains 'linux' but doesn't have 'GNU' before it, we want to discard that line.
- We want to match only
linuxand nothing else.
We already know how to satisfy the 1st condition. GNU.* will match 'GNU' followed by any number of characters. Then finally we match the word linux. This will match all of GNU-any-characters-linux.
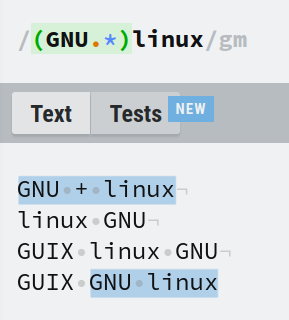
But how do we prevent matching GNU.* while still maintaining the 1st condition?
That's where a positive lookbehind comes in. You can mark a capture group as a positive lookbehind by prefixing it with ?<=. In this example, the expression becomes (?<=GNU.*)linux.

Now only linux is matched and nothing else.
Note that the expressions (?<=GNU.*)linux and linux(?<=GNU.*) will behave exactly the same. In the 2nd expression, although linux is before the lookbehind, there is .* after 'GNU' which matches linux. This means it satisfies the lookbehind.
To make it simpler, think about the pattern without the lookbehind. The pattern GNU.* will match 'GNU' and anything after it, in our case matching linux.
Now we can derive a generalized statement that the expression (?<=C)X will match the pattern X – only if pattern C came before X (and C must not be included in the match).
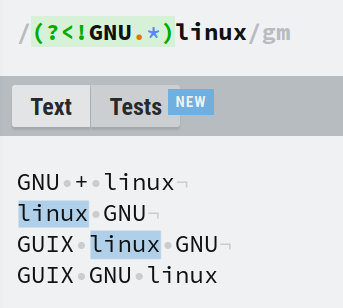
You can also reverse the 1st condition. Match lines that contains the word linux only if GNU never came before it. This is called a negative lookbehind. The prefix in this case is ?<!. The inverse of the previous expression would be (?<!GNU.*)linux.
Lookaheads
Lookaheads are also assertions like lookbehinds, as you saw in the previous example. The only difference is that lookbehinds make an assertion before and lookaheads makes assertion after.
Let's say you have these two conditions:
- Match
Helloonly ifWorldcomes somewhere after it. - Match only Hello and nothing else.
The prefix for a positive lookahead is ?=. The expression Hello(?=.*World) will meet both conditions. This is similar to Hello.*World except that only Hello will be matched whereas Hello.*World will match 'Hello', 'World' and anything in between.
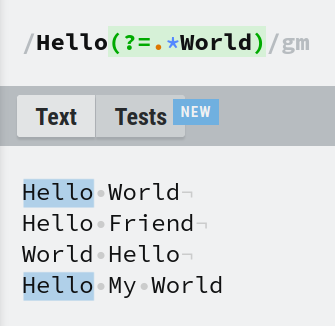
Similar to the example in a positive lookbehind, the expressions Hello(?=.*World) and (?=.*World)Hello are equivalent. Because the .* before 'World' matches Hello, satisfying the 1st condition.
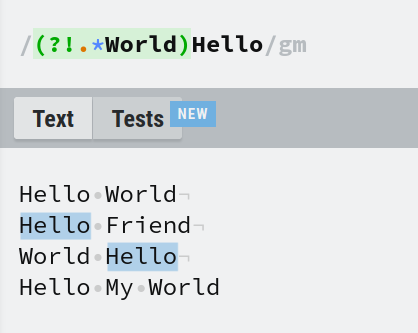
A negative lookahead is just the complement of a negative lookbehind. You can use it by prefixing it with ?!. (?!World)Hello will match Hello only if there is no World anywhere after it.
Here is a summary of the syntax for lookarounds when you want to match the pattern X with assertion C.
| Operation | RegEx |
| positive lookahead | (?=C)X |
| negative lookahead | (?!C)X |
| positive lookbehind | (?<=C)X |
| negative lookbehind | (?<!C)X |
Practical Examples of Regex
Logs parsing
In this log file, these are the lines which we care about:
[1/10000] Train loss: 11.30368, Valid loss: 8.95446, Elapsed_time: 7.58941
[500/10000] Train loss: 0.96180, Valid loss: 0.20098, Elapsed_time: 82.48651
[1000/10000] Train loss: 0.04051, Valid loss: 0.11927, Elapsed_time: 156.86243
Our task is to extract the training loss and validation loss for purposes such as plotting loss over the epochs. We need to extract the training loss values like 11.30368, 0.96180, 0.04051 and put them in an array.
All the relevant values are prefixed with 'Train loss:', so we can use this in our regex as it is. To match the float numbers we have to match some digits followed by a "." and then followed by more digits. You can do this with \d+\.\d+. Because we want to keep track of these numbers, they should be inside a capture group.
As "." has special purpose in regex, when you want to match a "." character you have to escape it with a backslash. This is applicable for all characters with a special purpose. But you dont have to escape it inside a character set.
Putting it altogether, the expression for extracting training loss is Train loss: (\d+\.\d+). We can use the same logic to extract validation loss with Valid loss: (\d+\.\d+).
Here is one way to extract this information using Python:
import re
f = open("log_train.txt", "r").read()
train_loss = re.findall(r'Train loss: (\d+\.\d+)', f)
valid_loss = re.findall(r'Valid loss: (\d+\.\d+)', f)
train_loss = [float(i) for i in train_loss]
valid_loss = [float(i) for i in valid_loss]
print("train_loss =", train_loss)
print("")
print("valid_loss =", valid_loss)
When there is one capture group, re.findall searches all the lines and returns the values inside the capture group in a list.
Any regex function only return strings, so the values are converted to floats and printed out. Then you can directly use them in another Python script as a list of floats.
This is the result:

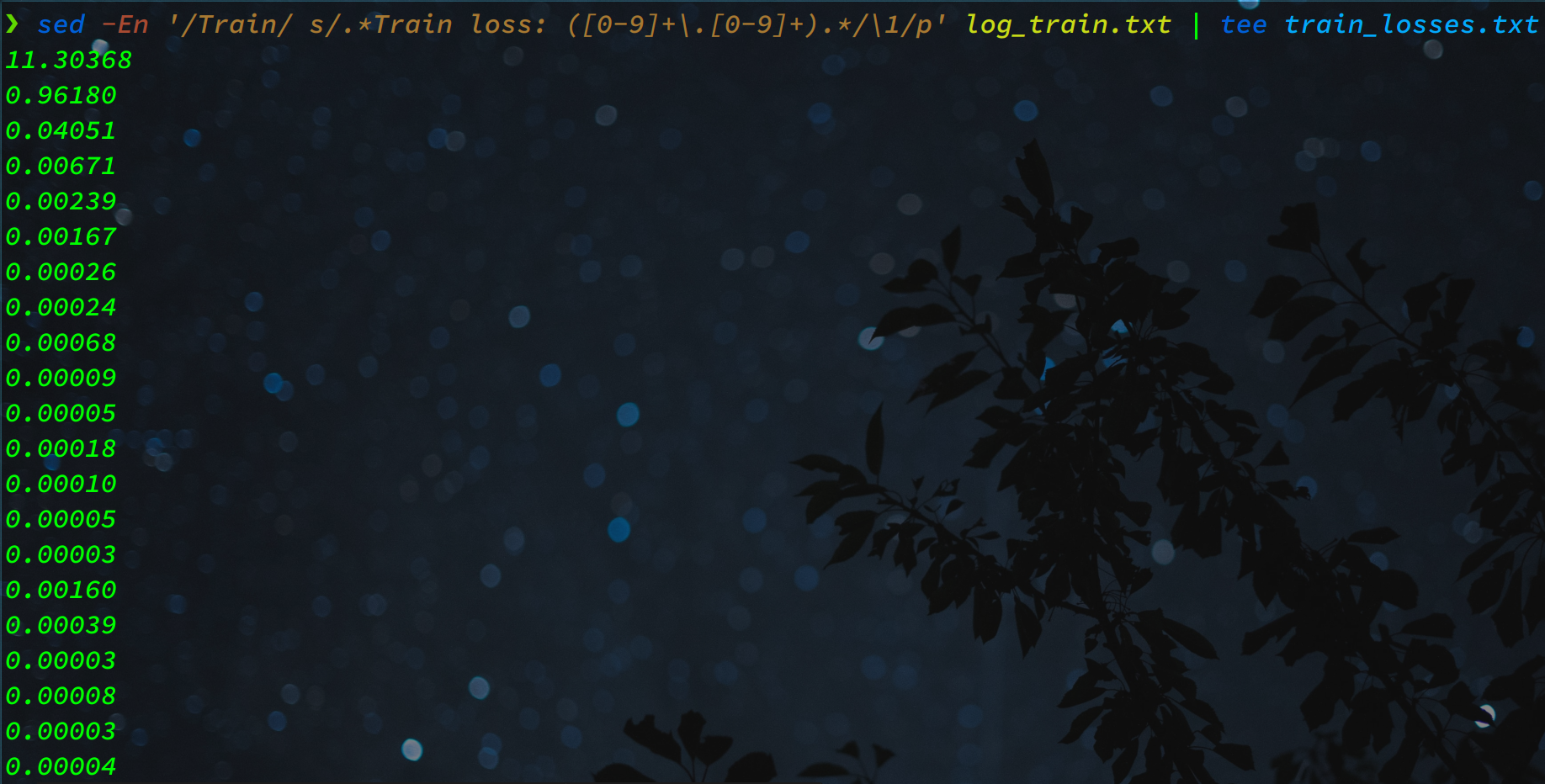
You could also use sed, save the output in train_losses.txt, and read from the file. First we use '/Train/' to target only the lines with 'Train' present then we are applying the same regex as before.
sed -En '/Train/ s/.*Train loss: ([0-9]+\.[0-9]+).*/\1/p' log_train.txt | tee train_losses.txt
".*" is added at the start and end so that sed matches the contents of all the relevant lines. Then the entire line is replaced by the value of the capture group. The tee command is used to redirect the output of sed into train_losses.txt while also printing the contents in the terminal.
Take a moment to think about what would you need to extract the epochs. You have to extract 500 from [500/10000] for all such lines. The array should look like [1, 500, 1000, 1500, ...]. You can follow the same approach as we used for the previous example.
Note that if you want to match "[" or "]", you have to escape it. The answer is given here.
Bulk File Renaming
You have these files with some random values as prefixes. You have to rename all files as 1.mp4, 2.mp4 and so on. This is how the files were generated.

This is a common scenario where you have a list of files which have their sequence number in the name but there are also some other characters that you don't want.
The pattern has to match anything up to Episode then an underscore and then the number and .mp4 at the end.
The relevant value is the number before '.mp4' which we will put inside a capture group. .*Episode_ will match everything up to the number. Then we can capture the number with ([0-9]+) and also match .mp4 with \.mp4.
So the final regex is .*Episode_([0-9]+)\.mp4. As we want to keep the .mp4 the replacement string will be \1.mp4.
This is one way to solve it using sed.
for i in *.mp4; do
newname=$(echo $i | sed -En 's/.*Episode_([0-9]+)\.mp4/\1.mp4/p')
mv $i $newname
done;ls
First the new name is saved in a variable and then the mv command is used to rename the file.

Could we have just used .* in place of .*Episode_ ? In this example, yes. But there might be filenames such as Steins_Gate0.mp4 where the 0 is part of the movie name and you didn't really want to rename this file so its always better to be as specific as possible.
What if some files were named as "Random_Episode6.mp4"? The difference being, there is no underscore after Episode. What change will you need to make?
The answer is that you'll need to add a "?" after the "_" to make it optional. The regex will be .*Episode_?([0-9]+)\.mp4.
Email validation
There are all sorts of complicated regex for validating email.
Here is a simple one: ^[^@ ]+@[^@.]+\.\w+$. It matches the format A@B.C
The table below breaks down this pattern into smaller pieces:
| Pattern | Matches |
^ | start of line |
[^@ ]+ | anything except "@" and space character |
@[^@.]+ | @ followed by anything except "@" and "." characters |
\.\w+ | "." followed by word characters |
$ | end of line |
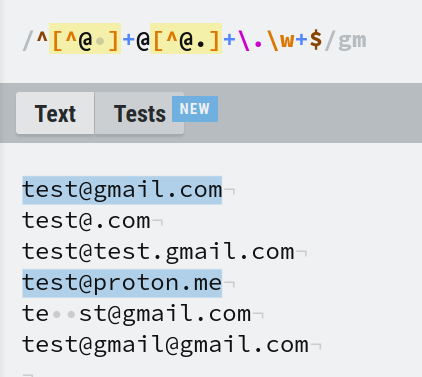
In the regexr site, you can enable the multline flag from the Flags tab in the upper right corner. The 'gm' at the end indicates that the multiline flag is enabled.
We can see that line 2,3,5,6 didn't match. Can you find out the reason and which part of the regex is responsible for disqualifying it?
The answer is given here
Password constraints
You can also use regex to impose constraints. Here we will uncover the power of positive lookaheads.
Lets say we want to accept a string only if there is a digit in it. You already know how to find a digit with the '\d' class. To accomplish that, we can use [^\d]*\d. This will match any non-digit character 0 or more times and then match a digit.
We can also use the expression .*\d to match one digit. So if there is no digit in the string then the lookahead will fail and the none of the characters of that string will be matched, returning an empty string "".
When we are using a programming language, we can check if the regex returned an empty string and determine that the constraints are not satisfied.
We will create a regex which imposes the following criteria:
- Minimum 8 characters and maximum 16 characters.
- At least one lower case letter.
- At least one upper case letter.
- At least one number.
To achieve this, you can use positive lookaheads. This is the regex:
^(?=.*[a-z])(?=.*[A-Z])(?=.*\d).{8,16}$
The table below explains which part of the regex imposes which constraint:
| Pattern | Imposed Constraint |
.{8,16} | min 8 and max 16 characters |
(?=.*[a-z]) | minimum one lower case letter |
(?=.*[A-Z]) | minimum one upper case letter |
(?=.*\d) | minimum one digit |

What modification you would need for imposing at least 5 upper case letters?
You may think (?=.*[A-Z]{5,}) will do the job. But this expression requires all the 5 letters to be together. A string like rand-ABCDE-rand will be matched but 0AxBCDxE0 will not be matched even though it has 5 upper case letters (as they are not adjacent).
Yet again, we have capture groups coming to the rescue. We want to match 5 uppercase letters anywhere in the string. We already know that we can match 1 uppercase letter with .*[A-Z]. Now we will put them inside a capture group and attach a quantifier of minimum 5. The expression will be (.*[A-Z]){5,}.
Here is the final answer:
In place of (?=.*[A-Z]) you will need (?=(.*[A-Z]){5,}). The expression becomes ^(?=.*[a-z])(?=(.*[A-Z]){5,})(?=.*\d).{8,16}$.

You could also require that the password not contain certain words to enforce stronger passwords.
For example, we want to reject the password if contains pass or 1234. Negative lookaheads is the tool for this job. The regex would be ^(?!.*(pass|1234)).*$.
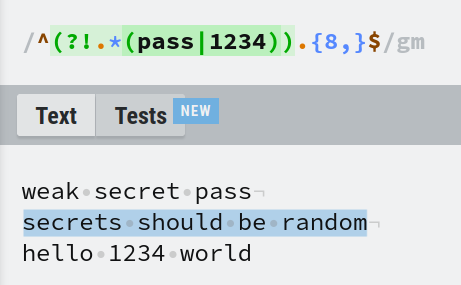
In this regex, we put pass and 1234 inside a capture group and used the logical OR operator. This capture group is nested inside another capture group which is prefixed with ?!.*. This makes it a negative lookahead that matches if there are at least 8 characters by .{8,} with the condition that, pass or 1234 can't be present anywhere in the string.
Final Words
I hope you got a good amount of practice while going through this article. It's ok if you forget some syntax. What's important is understanding the core concepts and having a good idea of what's possible with regex. Then, if you forget a pattern, you can just google it or reference a cheatsheet.
The more you practice, the more you will get by without outside help. Eventually you will be able write super complex and effective regex completely offline.
There are already some good regex cheatsheets out there, so I wanted to create something more in-depth here that you can reference for the core concepts and common use cases.
If you're looking for a cheatsheet, the one from QuickRef is helpful. It's a good place to recall the syntax and they also provide some basic overview of regex related functions in various programming languages.
Most regex techniques are the same in all programming languages and tools – but certain tools might offer additional features. So do some research on the tool you are using to pick the best one for you.
My final suggestion would be not to force using regex just because you can. A lot of the times a regular string.find() is enough to get the job done. But if you live in the terminal, you really can do a lot just with regex for sure.
If you like this type of article, you may keep an eye on my blog or twitter.