
By Siddhesh Rane
Apache Spark is an open-source fault-tolerant cluster-computing framework that also supports SQL analytics, machine learning, and graph processing.
It works by splitting your data into partitions, and then processing those partitions in parallel on all the nodes in the cluster. If any node goes down, it reassigns the task of that node to a different node and hence provides fault tolerance.
Being 100x faster than Hadoop has made it hugely popular for Big Data processing. Spark is written in Scala and runs on the JVM, but the good news is it also provides APIs for Python and R as well as C#. It is well documented with examples that you should check out.
When you are ready to give it a try, this article will guide you from download and setup through to performance tuning. My tiny Spark cluster performed 100 million string matches over all the articles in Wikipedia — in less than two hours.
It’s when you get past the tutorials and do some serious work that you realize all the hassles of the tech stack you are using. Learning through mistakes is the best way to learn. But sometimes you are just short on time and wish you knew every possible thing that could go wrong.
Here, I describe some of the problems that I faced when starting with Spark, and how you can avoid them.
How to get started
Download the Spark binary that comes with packaged Hadoop dependencies
If you set out to download Spark, you’ll notice that there are various binaries available for the same version. Spark advertizes that it does not need Hadoop, so you might download the user-provided-hadoop version which is smaller in size. Don’t do that.
Although Spark does not use Hadoop’s MapReduce framework, it does have dependencies on other Hadoop libraries like HDFS and YARN. The without-hadoop version is for when you already have Hadoop libraries provided elsewhere.
Use the standalone cluster mode, not Mesos or YARN
Once you test the built-in examples on local cluster, and ensure that everything is installed and working properly, proceed to set up your cluster.
Spark gives you three options: Mesos, YARN, and standalone.
The first two are resource allocators which control your replica nodes. Spark has to request them to allocate its own instances. As a beginner, don’t increase your complexity by going that way.
The standalone cluster is the easiest to setup. It comes with sensible defaults, like using all your cores for executors. It is part of the Spark distribution itself and has a sbin/start-all.sh script that can bring up the primary as well as all your replicas listed in conf/slaves using ssh.
Mesos/YARN are separate programs that are used when your cluster isn’t just a spark cluster. Also, they don’t come with sensible defaults: executors don’t use all cores on the replicas unless explicitly specified.
You also have the option of a high availability mode using Zookeeper, which keeps a list of backup primaries incase any primary fails. If you are a beginner, you are likely not handling a thousand-node cluster where the risk of node failure is significant. You are more likely to set up a cluster on a managed cloud platform like Amazon’s or Google’s, which already takes care of node failures.
You don’t need high availability with cloud infrastructure or a small cluster
I had my cluster set up in a hostile environment where human factors were responsible for power failures, and nodes going off the grid. (Basically my college computer lab where diligent students turn off the machine and careless students pull out LAN cables). I could still pull off without high availability by careful choice of the primary node. You wouldn’t have to worry about that.
Check the Java version you use to run Spark
One very important aspect is the Java version you use to run Spark. Normally, a later version of Java works with something compiled for older releases.
But with Project Jigsaw, modularity introduced stricter isolation and boundaries in Java 9 which breaks certain things that use reflection. On Spark 2.3.0 running on Java 9, I got illegal reflection access. Java 8 had no issues.
This will definitely change in the near future, but keep that in mind until then.
Specify the primary URL exactly as is. Do not resolve domain names to IP adresses, or vice-versa
The standalone cluster is very sensitive about URLs used to resolve primary and replica nodes. Suppose you start the primary node like below:
> sbin/start-master.sh
and your primary is up at localhost:8080

By default, your PC’s hostname is chosen as the primary URL address. x360 resolves to localhost but starting a replica like below will not work.
# does not work > sbin/start-slave.sh spark://localhost:7077
# works > sbin/start-slave.sh spark://x360:7077
This works, and our replica has been added to the cluster:
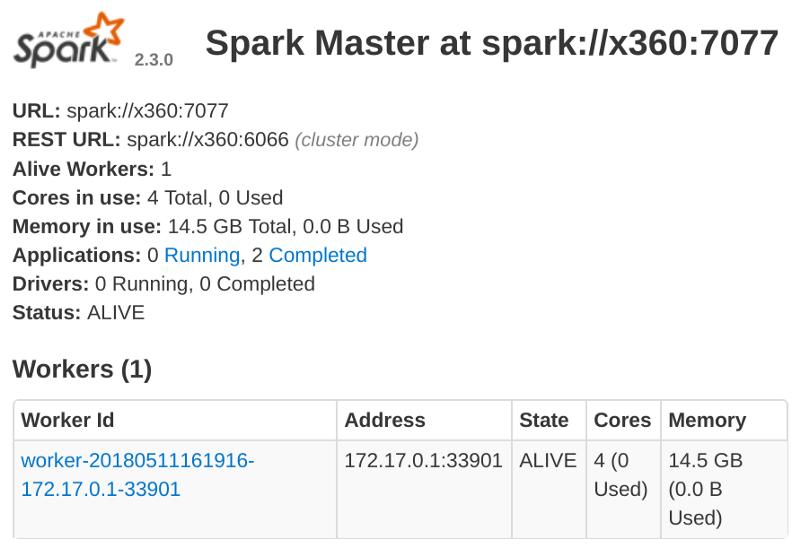
Our replica has an IP address in the 172.17.x.x subdomain, which is actually the subdomain set up by Docker on my machine.
The primary can communicate with this replica because both are on the same machine. But the replica cannot communicate with other replicas on the network, or a primary on a different machine, because its IP address is not routable.
Like in the primary case above, a replica on a machine without primary will take up the hostname of the machine. When you have identical machines, all of them end up using the same hostname as their address. This creates a total mess and no one can communicate with the other.
So the above commands would change to:
# start master> sbin/start-master.sh -h $myIP # start slave > sbin/start-slave.sh -h $myIP spark://<masterIP>:7077 # submit a job > SPARK_LOCAL_IP=$myIP bin/spark-submit ...
where myIP is the IP address of the machine which is routable between the cluster nodes. It is more likely that all nodes are on the same network, so you can write a script which will set myIP on each machine.
# assume all nodes in the 10.1.26.x subdomain siddhesh@master:~$ myIP=`hostname -I | tr " " "\n" | grep 10.1.26. | head`
Flow of the code
So far we have set up our cluster and seen that it is functional. Now its time to code. Spark is quite well-documented and comes with lots of examples, so its very easy to get started with coding. What is less obvious is how the whole thing works which results in some very hard to debug errors during runtime. Suppose you coded something like this:
class SomeClass { static SparkSession spark; static LongAccumulator numSentences;
public static void main(String[] args) { spark = SparkSession.builder() .appName("Sparkl") .getOrCreate(); (1) numSentences = spark.sparkContext() .longAccumulator("sentences"); (2) spark.read() .textFile(args[0]) .foreach(SomeClass::countSentences); (3) } static void countSentences(String s) { numSentences.add(1); } (4) }
1 create a spark session
2 create a long counter to keep track of job progress
3 traverse a file line by line calling countSentences for each line
4 add 1 to the accumulator for each sentence
The above code works on a local cluster but will fail with a null pointer exception when run on a multinode cluster. Both spark as well as numSentences will be null on the replica machine.
To solve this problem, encapsulate all initialized states in non-static fields of an object. Use main to create the object and defer further processing to it.
What you need to understand is that the code you write is run by the driver node exactly as is, but what the replica nodes execute is a serialized job that spark gives them. Your classes will be loaded by the JVM on the replica.
Static initializers will run as expected, but functions like main won’t, so static values initialized in the driver won’t be seen in the replica. I am not sure how the whole thing works, and am only inferring from experience, so take my explanation with a grain of salt. So your code now looks like:
class SomeClass { SparkSession spark; (1) LongAccumulator numSentences; String[] args; SomeClass(String[] args) { this.args = args; } public static void main(String[] args){ new SomeClass(args).process(); (2) } void process() { spark = SparkSession.builder().appName("Sparkl").getOrCreate(); numSentences = spark.sparkContext().longAccumulator("sentences"); spark.read().textFile(args[0]).foreach(this::countSentences); (3) } void countSentences(String s) { numSentences.add(1); }}
1 Make fields non static
2 create instance of the class and then execute spark jobs
3 reference to this in the foreach lambda brings the object in the closure of accessible objects and thus gets serialized and sent to all replicas.
Those of you who are programming in Scala might use Scala objects which are singleton classes and hence may never come across this problem. Nevertheless, it is something you should know.
Submit app and dependencies
There is more to coding above, but before that you need to submit your application to the cluster. Unless your app is extremely trivial, chances are you are using external libraries.
When you submit your app jar, you also need to tell Spark the dependent libraries that you are using, so it will make them available on all nodes. It is pretty straightforward. The syntax is:
bin/spark-submit --packages groupId:artifactId:version,...
I have had no issues with this scheme. It works flawlessly. I generally develop on my laptop and then submit jobs from a node on the cluster. So I need to transfer the app and its dependencies to whatever node I ssh into.
Spark looks for dependencies in the local maven repo, then the central repo and any repos you specify using --repositories option. It is a little cumbersome to sync all that on the driver and then type out all those dependencies on the command line. So I prefer all dependencies packaged in a single jar, called an uber jar.
Use Maven shade plugin to generate an uber jar with all dependencies so job submitting becomes easier
Just include the following lines in your pom.xml
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId <version>3.0.0</version> <configuration> <artifactSet> <excludes> <exclude>org.apache.spark:*</exclude> </excludes> </artifactSet> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
When you build and package your project, the default distribution jar will have all dependencies included.
As you submit jobs, the application jars get accumulated in the work directory and fill up over time.
Set spark.worker.cleanup.enabled to true in conf/spark-defaults.conf
This option is false by default and is applicable to the stand-alone mode.
Input and Output files
This was the most confusing part that was difficult to diagnose.
Spark supports reading/writing of various sources such as hdfs, ftp, jdbc or local files on the system when the protocol is file:// or missing. My first attempt was to read from a file on my driver. I assumed that the driver would read the file, turn it into partitions, and then distribute those across the cluster. Turns out it doesn’t work that way.
When you read a file from the local filesystem, ensure that the file is present on all the worker nodes at exactly the same location. Spark does not implicitly distribute files from the driver to the workers.
So I had to copy the file to every worker at the same location. The location of the file was passed as an argument to my app. Since the file was located in the parent folder, I specified its path as ../wikiArticles.txt. This did not work on the worker nodes.
Always pass absolute file paths for reading
It could be a mistake from my side, but I know that the filepath made it as is into the textFile function and it caused “file not found” errors.
Spark supports common compression schemes, so most gzipped or bzipped text files will be uncompressed before use. It might seem that compressed files will be more efficient, but do not fall for that trap.
Don’t read from compressed text files, especially gzip. Uncompressed files are faster to process.
Gzip cannot be uncompressed in parallel like bzip2, so nodes spend the bulk of their time uncompressing large files.
It is a hassle to make the input files available on all workers. You can instead use Spark’s file broadcast mechanism. When submitting a job, specify a comma separated list of input files with the --files option. Accessing these files requires SparkFiles.get(filename). I could not find enough documentation on this feature.
To read a file broadcasted with the --files option, use SparkFiles.get(<onlyFileNameNotFullPath>) as the pathname in read functions.
So a file submitted as --files /opt/data/wikiAbstracts.txt would be accesed as SparkFiles.get("WikiAbstracts.txt"). This returns a string which you can use in any read function that expects a path. Again, remember to specify absolute paths.
Since my input file was 5GB gzipped, and my network was quite slow at 12MB/s, I tried to use Spark’s file broadcast feature. But the decompression itself was taking so long that I manually copied the file to every worker. If your network is fast enough, you can use uncompressed files. Or alternatively, use HDFS or FTP server.
Writing files also follows the semantics of reading. I was saving my DataFrame to a csv file on the local system. Again I had the assumption that the results would be sent back to the driver node. Didn’t work for me.
When a DataFrame is saved to local file path, each worker saves its computed partitions to its own disk. No data is sent back to the driver
I was only getting a fraction of the results I was expecting. Initially I had misdiagnosed this problem as an error in my code. Later I found out that each worker was storing its computed results on its own disk.
Partitions
The number of partitions you make affects the performance. By default, Spark will make as many partitions as there are cores in the cluster. This is not always optimal.
Keep an eye on how many workers are actively processing tasks. If too few, increase the number of partitions.
If you read from a gzipped file, Spark creates just one partition which will be processed by only one worker. That is also one reason why gzipped files are slow to process. I have observed slower performance with small number of large partitions as compared to a large number of small partitions.
It’s better to explicitly set the number of partitions while reading data.
You may not have to do this when reading from HDFS, as Hadoop files are already partitioned.
Wikipedia and DBpedia
There are no gotchas here, but I thought it would be good to make you aware of alternatives. The entire Wikipedia xml dump is 14GB compressed and 65 GB uncompressed. Most of the time you only want the plain text of the article, but the dump is in MediaWiki markup so it needs some preprocessing. There are many tools available for this in various languages. Although I haven’t used them personally, I am pretty sure it must be a time consuming task. But there are alternatives.
If all you want is the Wikipedia article plaintext, mostly for NLP, then download the dataset made available by DBpedia.
I used the full article dump (NIF Context) available at DBpedia (direct download from here). This dataset gets rid of unwanted stuff like tables, infoboxes, and references. The compressed download is 4.3GB in the turtle format. You can covert it to tsv like so
Similar datasets are available for other properties like page links, anchor texts, and so on. Do check out DBpedia.
A word about databases
I never quite understood why there is a plethora of databases, all so similar, and on top of that people buy database licenses. Until this project I hadn’t seriously used any. I ever only used MySQL and Apache Derby.
For my project I used a SPARQL triple store database, Apache Jena TDB, accessed over a REST API served by Jena Fuseki. This database would give me RDF urls, labels, and predicates for all the resources mentioned in the supplied article. Every node would make a database call and only then would proceed with further processing.
My workload had become IO bound, as I could see near 0% CPU utilization on worker nodes. Each partition of the data would result in two SPARQL queries. In the worst case scenario, one of the two queries was taking 500–1000 seconds to process. Thankfully, the TDB database relies on Linux’s memory mapping. I could map the whole DB into RAM and significantly improve performance.
If you are IO bound and your database can fit into RAM, run it in memory.
I found a tool called vmtouch which would show what percentage of the database directory had been mapped into memory. This tool also allows you to explicitly map any files/directories into the RAM and optionally lock it so it wont get paged out.
My 16GB database could easily fit into my 32 GB RAM server. This boosted query performance by orders of magnitude to 1–2 seconds per query. Using a rudimentary form of database load balancing based on partition number, I could cut down my execution time to half by using 2 SPARQL servers instead of one.
Conclusion
I truly enjoyed distributed computing on Spark. Without it I could not have completed my project. It was quite easy to take my existing app and have it run on Spark. I definitely would recommend anyone to give it a try.
Originally published at siddheshrane.github.io.