
By Kavita Ganesan
In natural language processing (NLP) and text mining applications, stop words are used to eliminate unimportant words, allowing applications to focus on the important words instead.
Stop words are a set of commonly used words in any language. For example, in English, “the”, “is”, and “and” would easily qualify as stop words.
While there are various published stop words that one can use, in many cases these stop words are insufficient as they are not domain-specific. For example, in clinical texts, terms like “mcg” “dr.” and “patient” occur in almost every document that you come across. So, these terms may be regarded as potential stop words for clinical text mining and retrieval.
Similarly, for tweets, terms like “#”, “RT”, “@username” can be potentially regarded as stop words. The common language specific stop word list generally does not cover such domain-specific terms.
The good news is that it is actually fairly easy to construct your own domain-specific stop word list. Here are a few ways of doing it assuming you have a large corpus of text from the domain of interest, you can do one or more of the following to curate your stop word list:
1. Most frequent terms as stop words
Sum the term frequencies of each unique word (w) across all documents in your collection. Sort the terms in descending order of raw term frequency. You can take the top K terms to be your stop words.
You can also eliminate common English words (using a published stop list) prior to sorting so that you target the domain-specific stop words.
Another option is to treat words occurring in more X% of your documents as stop words. I have found eliminating words that appear in 85% of documents to be effective in several text mining tasks. The benefit of this approach is that it is really easy to implement. The downside, however, is if you have a particularly long document, the raw term frequency from just a few documents can dominate and cause the term to be at the top. One way to resolve this is to normalize the raw term frequency using a normalizer such as the document length — the number of words in a given document.
2. Least frequent terms as stop words
Just as terms that are extremely frequent could be distracting terms rather than discriminating terms, terms that are extremely infrequent may also not be useful for text mining and retrieval. For example, the username “@username” that occurs only once in a collection of tweets, may not be very useful. Other terms like “yoMateZ!” which could just be made-up terms by people again may not be useful for text mining applications.
Note: certain terms like “yaaaaayy!!” can often be normalized to standard forms such as “yay”.
However, despite all the normalization, if a term still has a frequency count of one you could remove it. This could significantly reduce your overall feature space.
3. Low IDF terms as stop words
Inverse document frequency (IDF) refers to the inverse fraction of documents in your collection that contains a specific term (ti). Let us say:
- you have N documents
- term ti occurred in M of the N documents.
The IDF of ti is thus computed as:
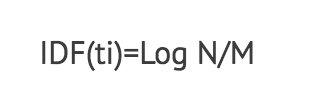
So, the more documents ti appears in, the lower the IDF score. This means terms that appear in every document will have an IDF score of 0.
If you rank each ti in your collection by its IDF score in descending order, you can treat the bottom K terms with the lowest IDF scores to be your stop words.
Again, you can also eliminate common English words using a published stop list prior to sorting so that you target the domain-specific low IDF words. This is not necessary if your K is large enough that it will prune both general stop words as well as domain-specific stop words. You will find more information about IDFs here.
So, would stop words help my task?
How would you know if removing domain specific stop words would be helpful in your case? Easy — test it on a subset of your data. See if whatever measure of accuracy and performance improves, stays constant, or degrades. If it degrades, needless to say, don’t do it unless the degradation is negligible and you see gains in other forms such as a decrease in size of model, or the ability to process things in memory.