
By Gajus Kuizinas
Zero-configuration, out of process transports and adheres to the Twelve Factors
The past 8 months I have been creating GO2CINEMA. This web application allows users to discover showtimes. They can also book cinema tickets across the world.
The platform grew to over +50 distinct services. The services support data aggregation, normalization, validation, analysis, distribution, invalidation, and more. Some of these services run in high replication environments, into the hundreds.
I needed to know when things break. And I needed to be able to correlate logs across all these services to identify the issue.
I needed a logger that did not exist.
Existing loggers
For a long time I have been a big fan of using debug. Debug is simple to use, works in Node.js and browsers, does not require configuration and it is fast. However, problems arise when you need to parse logs. Anything but one-line text messages cannot be parsed in a safe way.
To log structured data, I have been using Winston and Bunyan. These packages are great for application-level logging. I have preferred Bunyan because of the Bunyan CLI program used to pretty-print logs.
However, these packages require program-level configuration. When constructing an instance of a logger, you need to define the transport and the log-level. This makes them unsuitable for use in code designed for use by other applications.
Then there is pino. Pino is a fast JSON logger. It’s CLI program is equivalent to Bunyan. It decouples transports, and it has a sane default configuration. Yet you still need to instantiate logger instance at the application-level. This makes it more suitable for application-level logging like Winston and Bunyan.
I needed a logger that:
- Separates code from configuration
All configuration is stored in the environment variables - Produces structured data
- Decouples transports
- Has a CLI program
- Works in Node.js and browser
In other words a logger that:
- I can use in an application code and in dependencies
- allows me to correlate logs between the main application code and the dependency code
- works well with transports in external processes
… and it needs to be loud when things really break.
Roarr is this logger.

Strict API
A logger must have an API that is simple to remember and produces predictable results. Roarr achieves this by restricting the surface of the API.
Configuration
Roarr logging is disabled by default. To enable logging, you must start the program with an environment variable ROARR_LOG set to true:
ROARR_LOG=true node ./index.js
All Roarr configuration is done using environment variables. The developer cannot disable logging or set logging level at the application level. This is a good thing – filtering, formatting and augmenting logs belongs to the out of process transports. This ensures that you never need to touch the code to change the logging behavior.
The logger function
Roarr API is restricted to two parameters (plus printf formatting arguments).
- The first parameter can be either a string (message) or an object. If the first parameter is an object (context), the second parameter must be a string (message).
- Arguments after the message parameter are used to enable printf message formatting. Printf arguments must be of a primitive type (
string | number | boolean | null). There can be up to 9 printf arguments (or 8 if the first parameter is the context object).
In practice, this translates to the following usage:
import log from 'roarr';log('foo');log('bar %s', 'baz');const debug = log.child({ level: 'debug'});debug('qux');debug({ quuz: 'corge'}, 'quux');
The context parameter contains arbitrary user-defined data used to identify the context in which a log message was produced. It can contain application name, package name, task ID, host name, program instance name and other data.
This produces an output:
{"context":{},"message":"foo","sequence":0,"time":1506776210000,"version":"1.0.0"}{"context":{},"message":"bar baz","sequence":1,"time":1506776210000,"version":"1.0.0"}{"context":{"level":"debug"},"message":"quux","sequence":2,"time":1506776210000,"version":"1.0.0"}{"context":{"level":"debug","quuz":"corge"},"sequence":3,"message":"quux","time":1506776210000,"version":"1.0.0"}
This output is designed for consumption of the log transports.
Inspecting the logs
To inspect the logs at the development time, use **roarr pretty-print** program.
The output that the pretty-print CLI program produces looks like this:
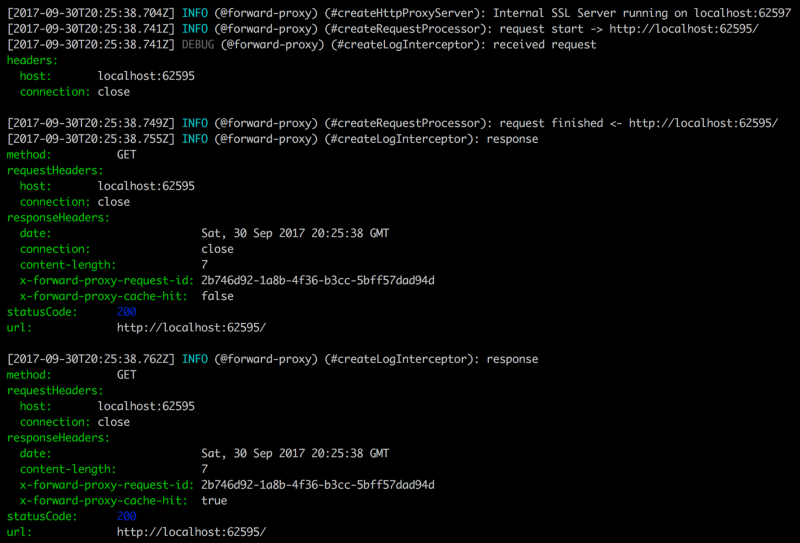
The CLI program relies on a set of conventions to structure the data.
Roarr CLI program has a couple of other commands and options. See roarr --help for more information.
Usage patterns
To avoid code duplication, you can use a singleton pattern to export a logger instance with predefined context properties. For instance, describing the application.
Using Roarr in an application
I recommend to create a file Logger.js in the base project directory. You can use this file to create a child instance of Roarr with context parameters describing the project and the initialization.
/** * @file Example contents of a Logger.js file. */
import Roarr from 'roarr';import ulid from 'ulid';
// Instance ID is useful for correlating logs in high concurrency environment.//// See `roarr augment --append-instance-id` option as an alternative way to// append instance ID to all logs.const instanceId = ulid();
// The reason we are using `global.ROARR.prepend` as opposed to `roarr#child`// is because we want this information to be prepended to all logs, including// those of the "my-application" dependencies.global.ROARR.prepend = { ...global.ROARR.prepend, application: 'my-application', instanceId};
export default Roarr.child({ // .foo property is going to appear only in the logs that are created using // the current instance of a Roarr logger. foo: 'bar'});
Using Roarr in a dependency
If you are developing a code designed to be consumed by other applications and modules, you should avoid using global.ROARR. Although there are valid use cases.
You should still start the project by defining a Logger.js file and use log.child instead.
/** * @file Example contents of a Logger.js file. */
import Roarr from 'roarr';
export default Roarr.child({ domain: 'database', package: 'my-package'});
Roarr does not have reserved context property names. However, I encourage use of the conventions.
The roarr pretty-print CLI program is using the context property names suggested in the conventions. This will pretty-print the logs for the developer inspection purposes.
Filtering logs
Roarr is designed to print all or no logs. Refer to the **ROARR_LOG** environment variable documentation.
To filter logs you need to use a JSON processor, such as jq.
jq allows you to filter JSON messages using [select(boolean_expression)](https://stedolan.github.io/jq/manual/#select(boolean_expression)):
ROARR_LOG=true node ./index.js | jq 'select(.context.logLevel == "warning" or .context.logLevel == "error")'
The result is the only log message that has either a “warning” or “error” log level. You can combine jq with the Roarr CLI program to focus on a specific error message:
ROARR_LOG=true node ./index.js | jq 'select(.context.package == "usus")' | roarr pretty-print
Manipulating the log message context globally
By now you probably have a hang of what a log message “context” is. It is a key-value object defining environment variables at the time of logging the message.
In some cases, it might be useful to prepend properties to the context object globally for all messages at runtime. For instance, you have a task running program and you want to associate all logs that have printed during the time of the task execution.
You can do this using global.ROARR.prepend:
import log from 'roarr';import foo from 'foo';const taskIds = [ 1, 2, 3];for (const taskId of taskIds) { global.ROARR = global.ROARR || {}; global.ROARR.prepend = { taskId }; log('starting task ID %d', taskId); // In this example, `foo` is an arbitrary third-party dependency that is using // roarr logger. foo(taskId); log('successfully completed task ID %d', taskId); global.ROARR.prepend = {};}
Produces output:
{"context":{"taskId":1},"message":"starting task ID 1","sequence":0,"time":1506776210000,"version":"1.0.0"}{"context":{"taskId":1},"message":"foo","sequence":1,"time":1506776210000,"version":"1.0.0"}{"context":{"taskId":1},"message":"successfully completed task ID 1","sequence":2,"time":1506776210000,"version":"1.0.0"}[...]
If you are using a central log aggregator, you can easily find all logs associated with a particular task. This is useful if you are investigating an error that has terminated a task early.
Transports
In most logging libraries a transport runs in-process to perform an operation with the finalized log line. For example, a transport might send the log line to a standard syslog server after processing and reformatting it.
Roarr does not support in-process transports because Node processes are single threaded processes. Roarr offloads the handling of logs to external processes so the threading capabilities of the OS or other CPUs can be used.
Depending on your configuration, consider one of the following log transports:
- Beats
For aggregating at a process level
Written in Go - logagent
For aggregating at a process level
Written in JavaScript - Fluentd
For aggregating logs at a container orchestration level such as Kubernetes
Written in Ruby
In the case of Fluentd and Kubernetes, aggregating all logs to ElasticSearch is as simple as creating a single DaemonSet.
The future of Roarr
Roarr codebase is not complicated. The success of the project such as Roarr depends a lot on the scale effect. The more dependencies use Roarr, the more value it provides.
Enabling logging allows instant gathering of all the data about applications. Their components required to monitor application health and trace issues.
In a sense, I am lucky. Over many years, I have developed an abstraction for almost every component that composes my Node.js and browser applications.
These range from database client, DOM evaluator, HTTP server process manager, and so forth. This allows me to quickly reap the benefits of a package such as Roarr.
Time will show whether the rest of the community adopts Roarr with equal passion.
What about the name?
I got some initial critique about the use of a generic, “cutesy” name such as “roarr”. The primary reason for choosing the name is to identify the package as loud. Roarr logs cannot be suppressed, just like the roar of a tiger.

From the practical perspective, “ROARR” is a safe term to grep and reserve in the global environment.
Roarr!
I am standardizing Roarr across all Node.js applications and packages that I maintain.
I expect that this will improve my ability to quickly detect issues. It will help me to reconfigure logging settings of the existing applications — without modifying the source code to adjust the log volumes. And it will improve my day-to-day experience of tailing application logs.

Logging is one of the scariest parts of the application development. Roarr makes it less scary.
You like to read, I love to write
You can support my open-source work and me writing technical articles through Buy Me A Coffee and Patreon. You’ll have my eternal gratitude ?