

Hello everyone! I'm a Software engineer who's interested in low-level programming, compilers, and tool development.
At the end of 2023, I published my first article on freeCodeCamp about how I created a SQL-like Language to run queries on local Git repositories. If you want a bit more context, give it a read.
At the start of 2024, the project got bigger and bigger with more features and amazing contributors, and I started to think: what if I could run SQL-like queries not only on .git files but on any kind of local and remote data?
In my last article about How to Run SQL-Like Queries on Files, I explained the internal design of the GitQL SDK components and how to use it with any kind of data in general and how to implement the FileQL project.
In this article, I will explain how I used the GitQL SDK to implement the ClangQL (Clang Query Language) project, which is a tool that helps you run SQL-like queries on local C/C++ files.
How I Came Up with the ClangQL Project
As I mentioned in my past articles, GitQL SDK can run SQL-like queries on any local or remote structured data. Also, the compiler parses your code into an AST (Abstract Syntax Tree) Data structure. So the question that jumped into my mind was, why not run the query on the Abstract Syntax Tree?
There were no limitations I could think of for implementing this idea, so I started to think of the two main requirements for using GitQL: creating the Data Schema to describe the table structures and columns types, and implementing the Data Provider component to provide the data which in our case is the ATS information and mapping it to the Engine format.
The Data Schema for the C/C++ Code
You can think of the Data Schema as the place where we put structure and relationships of our data – for example, which tables we have, and for each table what columns they contain, and finally the types of each column.
This information is very useful when you're performing type checking and detecting if the user has written the wrong column name, for example, which is not defined in the selected table they want to use.
In our case, the tables can be classes, structs, enumerations, functions, variables and any other data that can be read from C++ such as macros and so on. But I decided to start simple with functions and variables only, then I planned to add other kinds.
So for the functions table, let's define what columns we need to include. The columns and types are not hard to guess, so let's take a normal function as an example. It has the name Text, and it returns type as Text, the number of parameters as Int, other C++ flags as Booleans (for example, is it a virtual function is_virtual or a pure virtual function is_pure_virtual?), and another flag to tell you if it is a static function is_static.
So to create a Data Schema you need to define two things: what tables you have, and what columns there are in this table. For example, in the functions table it will look like this:
lazy_static! {
pub static ref TABLES_FIELDS_NAMES: HashMap<&'static str, Vec<&'static str>> = {
let mut map = HashMap::new();
map.insert(
"functions",
vec![
"name",
"signature",
"args_count",
"return_type",
"class_name",
"is_method",
"is_virtual",
"is_pure_virtual",
"is_static",
"is_const",
"has_template",
"access_modifier",
"is_variadic",
"file",
"line",
"column",
"offset",
],
);
}
}
You also need to define the expected data type for each column:
lazy_static! {
pub static ref TABLES_FIELDS_TYPES: HashMap<&'static str, DataType> = {
let mut map = HashMap::new();
map.insert("name", DataType::Text);
map.insert("type", DataType::Text);
map.insert("signature", DataType::Text);
map.insert("args_count", DataType::Integer);
map.insert("return_type", DataType::Text);
map.insert("class_name", DataType::Text);
map.insert("is_method", DataType::Boolean);
map.insert("is_virtual", DataType::Boolean);
map.insert("is_pure_virtual", DataType::Boolean);
map.insert("is_static", DataType::Boolean);
map.insert("is_const", DataType::Boolean);
map.insert("has_template", DataType::Boolean);
map.insert("access_modifier", DataType::Integer);
map.insert("is_variadic", DataType::Boolean);
map
};
}
Now let's move on to the most exciting part: the Data Provider.
The Data Provider for the C/C++ Code
The data provider component is used to tell the engine how to load the target data – for example from where and on which thread – and provide these data in a format that is known by our GitQL Engine. So how we can extract that information from our C/C++ code?
Well, we need to get the AST after parsing the C/C++ code. So the first option is to write a C/C++ parser to parse the files and provide the AST. But this option has some problems here: it'll require a lot of hard work, as C++ is a large language. To write a parser from scratch means you need to support every new feature, and handle errors, and so on.
The other option is to take a well-written C/C++ parser from any Compiler that provides the parser as a library and use it to provide the AST. After some searching, I found that the Clang Compiler is well-designed and can provide the parser as a library to use it to build other tools such as code formatter and linter.
LibClang is written in C++ so I used binding for the Rust Programming language to parse the source file as a TranslationUnit. This is the parent node that contains information about classes, functions, and so on.
LibClang provides more than one way to visit the TranslationUnit and all of the children of it. One of them is using the clang_visitChildren function. It takes a function pointer that gives you the Node and its parent and returns the flag as int. Using this flag, you can control if you want to break, continue, or walk inside this node using the return type.
For example if you are visiting the Class or Struct node and want to visit the methods inside them, you need to return CXChildVisit_Recurse – and clang_visitChildren will provide the methods for you. But if you want to just read class info then you need to return CXChildVisit_Continue to continue to other nodes. Using those flags in the wrong way can lead to performance issues and visiting many nodes that aren't useful.
So to get a function's info, we need to call clang_visitChildren as we pass a pointer to our data to save the information we got. For example:
let mut functions: Vec<FunctionNode> = Vec::new();
let data = &mut functions as *mut Vec<FunctionNode> as *mut c_void;
let cursor = clang_getTranslationUnitCursor(translation_unit);
clang_visitChildren(cursor, visit_children, data);
We passed visit_children that point to the function that extracts the C/C++ function's information. It will look like this:
extern "C" fn visit_children(
cursor: CXCursor,
parent: CXCursor,
data: *mut c_void,
) -> CXChildVisitResult {
let cursor_kind = clang_getCursorKind(cursor);
if cursor_kind == CXCursor_FunctionDecl
|| cursor_kind == CXCursor_CXXMethod
|| cursor_kind == CXCursor_FunctionTemplate
{
let function_name = clang_getCursorSpelling(cursor);
let function_type = clang_getCursorType(cursor);
let result_type = clang_getResultType(function_type);
let arguments_count = clang_getNumArgTypes(function_type);
// ... Extracing more and more information
return CXChildVisit_Continue
}
CXChildVisit_Recurse
}
Also, if you want to refactor or build advanced searching tools on top of ClangQL, you'll need to get the source code location. For example, where exactly does the function you're searching for exist – on which file and line?
So to get them from Clang, you can use the below code. It provides the file name, line, column and offset data of the selected node:
let cursor_location = clang_getCursorLocation(cursor);
let mut file: CXFile = std::ptr::null_mut();
let mut line: u32 = 0;
let mut column: u32 = 0;
let mut offset: u32 = 0;
clang_getFileLocation(
cursor_location,
&mut file,
&mut line,
&mut column,
&mut offset,
);
let file_name = clang_getFileName(file);
let file_name_str = CStr::from_ptr(clang_getCString(file_name)).to_string_lossy();
The source code of visit_children is too large to include because, as you can see, the function node contains a lot of information. So you can check the full and updated code for all visitors from this file in the ClangQL repository: DataProviderFile.
The LibClang creators provide clear documentation on how to walk through the Translation Unit and extract the needed data.
So now we have our Data Schema and Provider, and we can perform a query like SELECT * FROM functions. The result will be likes this:
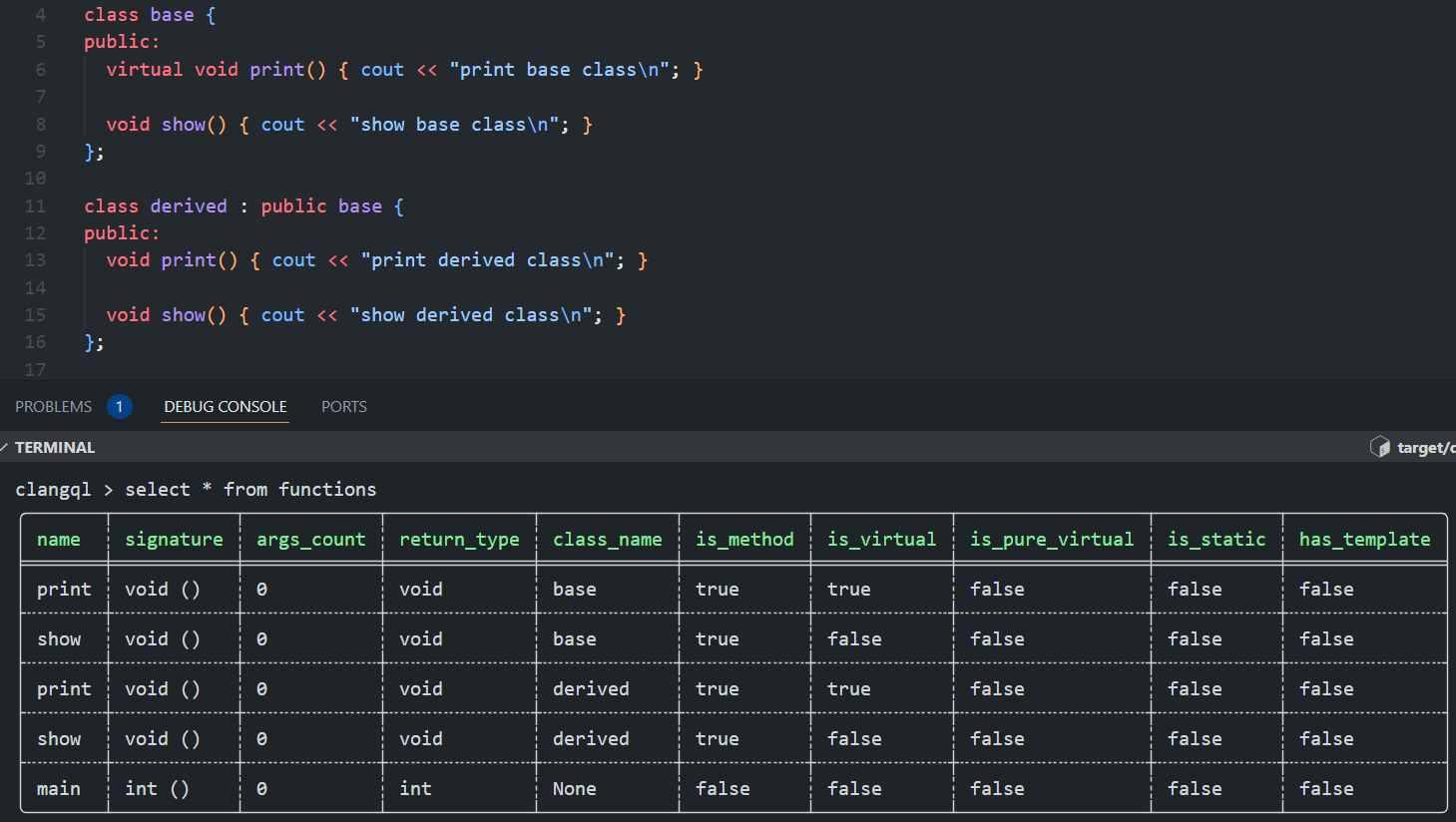
The result of running a query to select all function information from one file
So after that I decided to name the project ClangQL which stands for Clang Query Language. Now I'm working on extracting more and more important information from the AST (feel free to contribute).
You can find the full source code with all customizations in the ClangQL repository.
Conclusion
You can check out the ClangQL project as a full sample created only in three files.
If you liked the project, you could give it a star ⭐ on GitQL and ClangQL.
You can check out the website for how to download and use the project on different operating systems.
The project is not done yet – this is just the start. Everyone is welcome to join and contribute to the project and suggest ideas or report bugs.
You can sponsor my work on GitHub ❤️.
Thanks for reading