
S-expressions are the base of the Lisp family of programming languages. In this article, I will show you how to create a simple S-expression parser step by step. This can be a base for the Lisp parser.
Lisp is the easiest language for implementation, and creating a parser is the first step. We can use a parser generator for this, but it's easier to write the parser yourself. We'll use JavaScript.
What are S-expressions?
If you're not familiar with the Lisp language, S-expressions look like this:
(+ (second (list "xxx" 10)) 20)
This is a data format, where everything is created from atoms or lists surrounded with parenthesis (where atoms of other lists are separated by spaces).
S-expressions can have different data types, just like JSON:
- numbers
- strings
- symbols – which are like strings but without quotes – can be interpreted
as variable names from different languages.
Additionally, you can use a special dot operator that creates a pair.
(1 . b)
You can represent a list as doted pairs (which indicates that they are in fact a linked list data structure).
This list:
(1 2 3 4)
Can be written as:
(1 . (2 . (3 . (4 . nil))))
nil is the special symbol that indicates the end of the list of an empty list. With this format, you can create any binary tree. But we'll not use this doted notation in our parser so we don't complicate things.
What are S-expressions Used For?
Lisp code is created from S-expressions, but you can also use it as a data exchange format.
They are also part of text representation of WebAssembly. Probably because of the simplicity of the parser, and that you don't need to come up with your format. You can use them for the communication between server and browser, instead of JSON.
How to Implement S-expression Parser in JavaScript
Tokenizer
The tokenizer is part of the parser that splits the text into tokens that then can be parsed.
Usually, a parser is accompanied by Lexer or a tokenizer that generates the tokens.
This is how some parser generators work (like lex and Yacc or flex and bison. The second one is the free and open source software, part of the GNU project).
The simplest way of tokenizing is to use regular expressions. If you're not familiar with regular expressions (or Regex for short) you can read this article:
A Practical Guide to Regular Expressions – Learn Regex with Real Life Examples.
This is the simplest way of tokenization:
'(foo bar (baz))'.split(/(\(|\)|\n|\s+|\S+)/);
This is a union (with a pipe operator) or different cases we need to handle. Parentheses are special characters in Regex, so they need to be escaped by a slash.
It almost works. The first problem is that there are empty strings between the regex matching. Like this expression:
'(('.split(/(\(|\)|\n|\s+|\S+)/);
// ==> [ '', '(', '', '(', '' ]
We have 5 tokens instead of 2. We can solve this problem with an Array::filter.
'(('.split(/(\(|\)|\n|\s+|\S+)/).filter(token => token.length);
// ==> ["(", "("]
If the token is empty, the length will return 0 and will be converted to false, which means that it will filter out all empty strings.
We'll also not need spaces, so we can also filter them out:
'( ('.split(/(\(|\)|\n|\s+|\S+)/).filter(token => token.trim().length);
// ==> ["(", "("]
The second bigger problem is with baz)) as the last token, here is an example:
'(foo bar (baz))'.split(/(\(|\)|\n|\s+|\S+)/).filter(token => token.trim().length);
// ==> ["(", "foo", "bar", "(", "baz))"]
The problem is the expression \S+, which is greedy and matches everything that is not a space. To fix the problem, we can use this expression: [^\s()]+.
It will match everything that is not a space and not a parentheses (same as \S+ but
with parentheses).
(foo bar (baz))'.split(/(\(|\)|\n|\s+|[^\s()]+)/).filter(token => token.trim().length);
// ==> ["(", "foo", "bar", "(", "baz", ")", ")"]
As you can see, the output is correct. Let's write this tokenizer as a function:
const tokens_re = /(\(|\)|\n|\s+|[^\s()]+)/;
function tokenize(string) {
string = string.trim();
if (!string.length) {
return [];
}
return string.split(tokens_re).filter(token => token.trim());
}
We don't need to use length after token.trim() because an empty string is also converted to false value and the filter will remove those values.
But what about string expressions (those in quotes)? Let's see what will happen:
tokenize(`(define (square x)
"Function calculate square of a number"
(* x x))`);
// ==> ["(", "define", "(", "square", "x", ")", "\"Function", "calculate", "square",
// ==> "of", "a", "number\"", "(", "*", "x", "x", ")", ")"]
NOTE: This is a function in the Scheme dialect of Lisp. We used template literals so we could add newline characters inside the Lisp code.
As you can see from the output, the single stings are all split by spaces. Let's fix that:
Regular Expressions for Strings
We need to add string literals as an exception to our tokenizer. The best is the first item in the union in our regex.
The expression that handles string literals looks like this:
/"[^"\\]*(?:\\[\S\s][^"\\]*)*"/
It handles escaped quotes inside a string.
This is how the full regular expression should look like:
const tokens_re = /("[^"\\]*(?:\\[\S\s][^"\\]*)*"|\(|\)|\n|\s+|[^\s()]+)/;
NOTE: We can also add Lisp comments, but because this is not a Lisp parser but S-expression, we'll not do that here. JSON doesn't support comments as well. If you want to create a Lisp parser, you can add them as an exercise.
Our tokenizer now works correctly:
tokenize(`(define (square x)
"Function calculate square of a number"
(* x x))`);
// ==> ["(", "define", "(", "square", "x", ")",
// ==> "\"Function calculate square of a number\"",
// ==> "(", "*", "x", "x", ")", ")"]
Parser
We'll create our parser using a stack data structure (LIFO - Last In First Out).
To fully understand how the parser works, it is good to know about data structures, like linked lists, binary trees, and stacks.
Here is the first version of our parser:
function parse(string) {
const tokens = tokenize(string);
const result = []; // as normal array
const stack = []; // as stack
tokens.forEach(token => {
if (token == '(') {
stack.push([]); // add new list to stack
} else if (token == ')') {
if (stack.length) {
// top of the stack is already constructed list
const top = stack.pop();
if (stack.length) {
// add constructed list to previous list
var last = stack[stack.length - 1];
last.push(top);
} else {
result.push(top); // fully constructed list
}
} else {
throw new Error('Syntax Error - unmached closing paren');
}
} else {
// found atom add to the top of the stack
// top is used as an array we only add at the end
const top = stack[stack.length - 1];
top.push(token);
}
});
if (stack.length) {
throw new Error('Syntax Error - expecting closing paren');
}
return result;
}
The function returns an array of our structures in the form of arrays. If we need to parse more than one S-expressions, we will have more items in an array:
parse(`(1 2 3) (1 2 3)`)
// ==> [["1", "2", "3"], ["1", "2", "3"]]
Although we don't need to handle dots, S-expressions can be in this form:
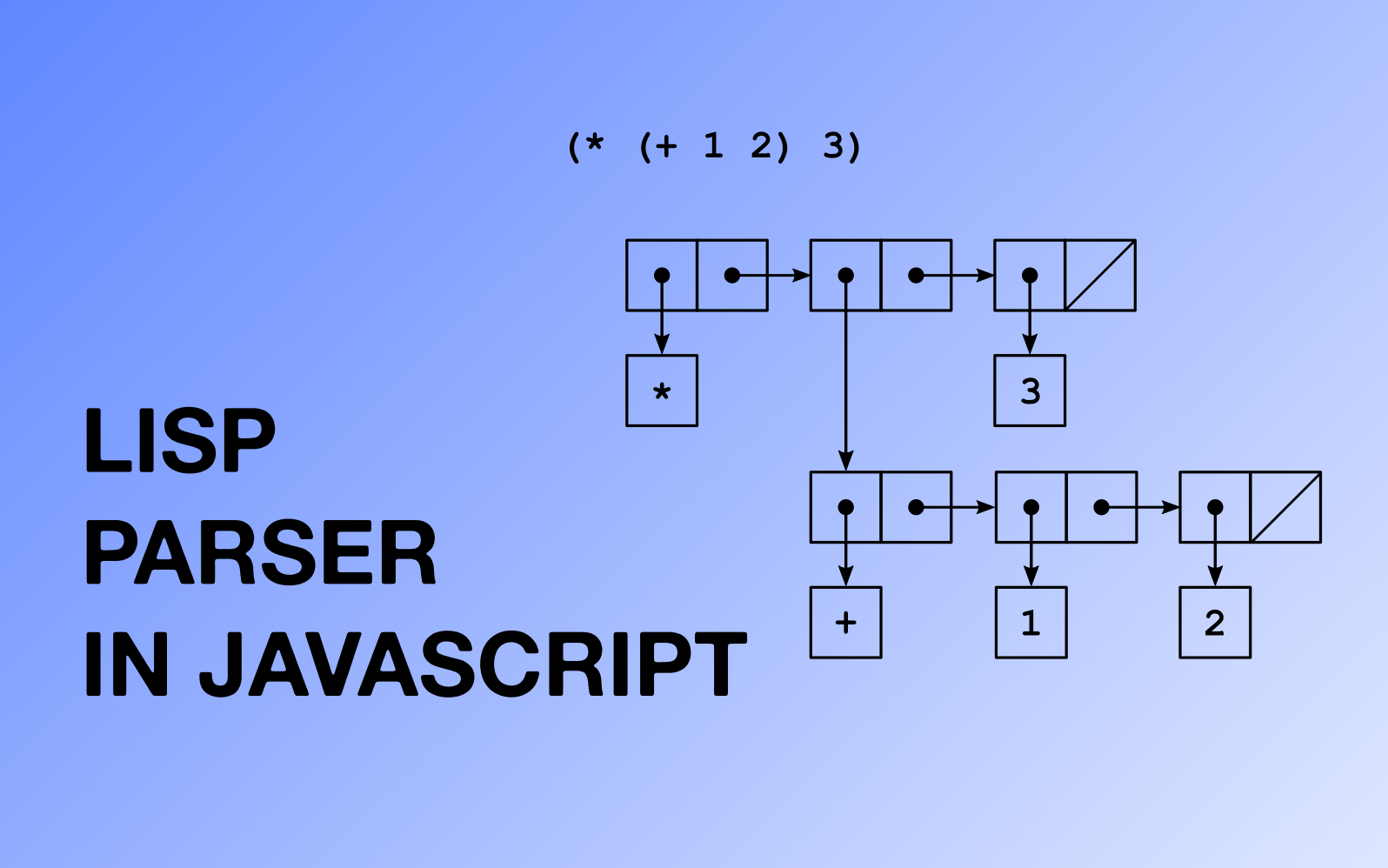
((foo . 10) (bar . 20))
We don't need to create a special structure for our lists to have a working parser. But it's a good idea to have this structure from the beginning (so you can use this as a base for a Lisp interpreter). We will use a Pair class, so we'll be able to create any binary tree.
class Pair {
constructor(head, tail) {
this.head = head;
this.tail = tail;
}
}
We will also need something that will represent the end of the list (or an empty list). In Lisp language, it's usually nil:
class Nil {}
const nil = new Nil();
We can create a static method that will convert an array into our structure:
class Pair {
constructor(head, tail) {
this.head = head;
this.tail = tail;
}
static fromArray(array) {
if (!array.length) {
return nil;
}
let [head, ...rest] = array
if (head instanceof Array) {
head = Pair.fromArray(head);
}
return new Pair(head, Pair.fromArray(rest));
}
}
To add this to our parser, all we have to do is to add it at the end:
result.map(Pair.fromArray);
NOTE: If you would like to add a dot operator later, you will need to create pairs by hand, inside the parser.
We didn't convert the whole array because this will be the container for our S-expressions. Each element in an array should be a list, that's why we used Array::map.
Let's see how it works:
parse('(1 (1 2 3))')
The output will be a structure like this (this is the output of JSON.stringify with inserted value of nil).
{
"head": "1",
"tail": {
"head": {
"head": "1",
"tail": {
"head": "2",
"tail": {
"head": "3",
"tail": nil
}
}
},
"tail": nil
}
}
The last thing that we can add is to stringify the List, by adding a toString method to our Pair class:
class Pair {
constructor(head, tail) {
this.head = head;
this.tail = tail;
}
toString() {
const arr = ['('];
if (this.head) {
const value = this.head.toString();
arr.push(value);
if (this.tail instanceof Pair) {
// replace hack for the nested list
// because the structure is a tree
// and here tail is next element
const tail = this.tail.toString().replace(/^\(|\)$/g, '');
arr.push(' ');
arr.push(tail);
}
}
arr.push(')');
return arr.join('');
}
static fromArray(array) {
// ... same as before
}
}
Let's see how it works:
parse("(1 (1 2 (3)))")[0].toString()
// ==> "(1 (1 2 (3)))"
The last problem is that the output structure doesn't have numbers. Everything is a string.
Parsing of Atoms
We'll use the regular expressions below:
const int_re = /^[-+]?[0-9]+([eE][-+]?[0-9]+)?$/;
const float_re = /^([-+]?((\.[0-9]+|[0-9]+\.[0-9]+)([eE][-+]?[0-9]+)?)|[0-9]+\.)$/;
if (atom.match(int_re) || atom.match(float_re)) {
// in javascript every number is float but if it's slow you can use parseInt for int_re
return parseFloat(atom);
}
Next, we can parse strings. Our strings are almost the same as those in JSON, the only difference is that they can have newlines (this is usually how strings are handled in Lisp dialects). So we can use JSON.parse and only replace \n with \\n (escape the new line).
if (atom.match(/^".*"$/)) {
return JSON.parse(atom.replace(/\n/g, '\\n'));
}
So with this, we can have all escape characters for free (that is: \t or Unicode characters \u).
The next element of S-expressions are symbols. They are any character sequences that are not numbers or strings. We can create an LSymbol class, to distinguish from Symbol from JavaScript.
class LSymbol {
constructor(name) {
this.name = name;
}
toString() {
return this.name;
}
}
The function for parsing atoms can look like this:
function parseAtom(atom) {
if (atom.match(int_re) || atom.match(float_re)) { // numbers
return parseFloat(atom);
} else if (atom.match(/^".*"$/)) {
return JSON.parse(atom.replace(/\n/g, '\\n')); // strings
} else {
return new LSymbol(atom); // symbols
}
}
Our parser function with add the parseAtom:
function parse(string) {
const tokens = tokenize(string);
const result = [];
const stack = [];
tokens.forEach(token => {
if (token == '(') {
stack.push([]);
} else if (token == ')') {
if (stack.length) {
const top = stack.pop();
if (stack.length) {
const last = stack[stack.length - 1];
last.push(top);
} else {
result.push(top);
}
} else {
throw new Error('Syntax Error - unmached closing paren');
}
} else {
const top = stack[stack.length - 1];
top.push(parseAtom(token)); // this line was added
}
});
if (stack.length) {
throw new Error('Syntax Error - expecting closing paren');
}
return result.map(Pair.fromArray);
}
We can also improve the toString method on Pair to use JSON.stringify for strings to distinguish from symbols:
class Pair {
constructor(head, tail) {
this.head = head;
this.tail = tail;
}
toString() {
const arr = ['('];
if (this.head) {
let value;
if (typeof this.head === 'string') {
value = JSON.stringify(this.head).replace(/\\n/g, '\n');
} else {
// any object including Pair and LSymbol
value = this.head.toString();
}
arr.push(value);
if (this.tail instanceof Pair) {
// replace hack for the nested list because
// the structure is a tree and here tail
// is next element
const tail = this.tail.toString().replace(/^\(|\)$/g, '');
arr.push(' ');
arr.push(tail);
}
}
arr.push(')');
return arr.join('');
}
static fromArray(array) {
// ... same as before
}
}
And this is a whole parser. What's left are true and false values (and maybe null), but they are left as an exercise for the reader. The full code can be found on GitHub.
Different Approaches to Lisp parser in JavaScript
The above code is good for simple Lisp implementation. I used a similar code as the initial implementation of LIPS Scheme, which can still be found on CodePen.
Right now, LIPS uses a more advanced Lexer (using state machine) instead of a tokenizer. The Lexer was rewritten because the approach with stack was too difficult to modify.
NOTE: This article first appeared on the Polish blog Głównie JavaScript (ang. Mostly JavaScript), the article was titled: Parser S-Wyrażeń (języka LISP) w JavaScript.