
By Valentijn v/den Hout
When I first read the original bitcoin whitepaper published by Satoshi Nakamoto (2008), it clarified a lot of fundamental questions I had regarding the cryptocurrency and blockchains in general. The paper, as many well-read blockchain and crypto professionals will confirm, is a fantastic starting point for anybody looking to learn more about the technology.
The goal of this post is to walk you through the whitepaper while making it as digestible as possible for anybody that is new to the field. I will aim to simplify some parts while maintaining the accuracy of the content.
Let’s stall no longer and dive right in. 🙌
PDF: Bitcoin: A peer-to-peer electronic cash system.
Before we start…
A blockchain is a ledger or database. It is distributed across and maintained by a large number of nodes (computers) in contrast to it being held by a single authority or party. The goal of the technology behind cryptocurrencies such as Bitcoin is to make it possible to reach an agreement (consensus) on the validity of the data in the database and that of data to be added to the database 🤝. Data, in this case, refers mainly to online transaction data that determines ownership of digital assets such as cryptocurrencies or tokens.
The entire distributed ledger is kept up to date and verified, and all participants in the network agree on its validity. Without immediately diving into the technical workings, blockchain protocols such as the one underlying Bitcoin, allow this agreement and validation to be achieved without the need for a third-party intermediary, such as a bank 🏦.
In the past, such a party was necessary in order to verify ownership of money (i.e., can this person spend this money). The party also made sure that an online payment was only spent once. (i.e., that particular money is not used in another transaction). The latter issue is what is referred to as the double-spend problem.
This has always been a major issue for transacting digital assets. It is possible to duplicate the code that makes up the asset and use it in multiple transactions.
The name “blockchain” comes from the way the data is stored. Data are collected in blocks 📦 which are added to a chain ⛓️ of previously validated blocks. With this as an introduction, let us get straight to it and dive into the ever famous whitepaper.

Abstract
The abstract of the whitepaper goes quite deep right of the bet and serves as a small summary of the paper. Do not worry if this goes over your head initially 🙆. We already covered most of what you need to know and will add to this in the next section.
The only takeaway here should be that the paper proposes a peer-to-peer electronic cash system. The system allows us to make online payments directly to each other. There is no need for a bank to solve the problems of ownership and double-spending. 💁 → 💵 → 🙋 and ❌🏦?
“A purely peer-to-peer version of electronic cash would allow online payments to be sent directly from one party to another without going through a financial institution.”
Introduction
“Commerce on the Internet has come to rely almost exclusively on financial institutions serving as trusted third parties to process electronic payments.”
At the time of writing of the Bitcoin whitepaper, financial institutions were necessary to verify ownership and eliminate the double spend problem. This, together with the need for transactions to be reversible (financial institutions have to deal with mediation disputes), increases the costs associated with a transaction. This means that there is a minimum transaction size necessary for these financial institutions to execute on it. Their fee needs to cover the transaction costs at least otherwise it does not make any sense. If it has not been clear before: banks really enjoy making money 💸.
“… limiting the minimum practical transaction size and cutting off the possibility for small casual transactions.”
This eliminates the option for a vast amount of transaction opportunities that theoretically exist but are practically not feasible. An amazing application that is not possible due to this minimum transaction size is the micro-consumption of online content, whether these are web articles, videos, music, and so forth. Instead of having to pay a monthly subscription, which may or may not be worth it depending on the usage by the consumer, micro-transactions would allow for a user to make incredibly small automated payments as the content is being consumed.
This would radically change the way we use the internet. Paying for Medium articles per word, YouTube videos per second, Spotify music per minute, or even consuming internet bandwidth per megabyte.
Another possible application would be to realize micro-payments directly between Internet-of-Things devices. A simple example here would be a parked car paying for its parking spot by the minute. There are countless micro-consumption/transaction applications, many of which will only become more apparent in the future. This is simply not possible if we need a third-party intermediary.
“With the possibility of reversal, the need for trust spreads. Merchants must be wary of their customers, hassling them for more information than they would otherwise need.”

Another reason why the need for trust is not ideal when making online transactions is that in order to obtain said trust, personal information has to be collected, whether this is by the banks or by the merchants via which payments are made. This information is stored by these organizations (often on a single server), giving them control over the personal data and making the data prone to leakage or hacking 👾.
Incredible data hacks have taken place over the last decade — think of Yahoo and Equifax — and they are becoming more prominent by the day. What Bitcoin aims to accomplish is to, in some way, replicate the simplicity of an in-person transaction in an online environment.
If Andy hands Brenda a $10 note 💵, Brenda does not have to know anything about Andy (such as personal information, credit scores, net worth, etc.). The only thing she has to know is that the $10 went from being in Andy’s possession to be in her possession and that the $10 did not magically duplicate itself (💵 → 🧙 → 💵💵) and Andy has another (exact) replica to spend.

“In this paper, we propose a solution to the double-spending problem using a peer-to-peer distributed timestamp server to generate computational proof of the chronological order of transactions.”
In order to make this possible, the person (or people, or thing) under the name Satoshi Nakamoto presents an electronic payment system that uses cryptographic proof 👨🏫 that allows its members to reach an agreement (consensus) without the need for a third-party intermediary.
2. Transactions
“Each owner transfers the coin to the next by digitally signing a hash of the previous transaction and the public key.”
In the world of Bitcoin, those that own Bitcoins have what is called a “wallet”. This functions somewhat similar to a classic wallet in that it “holds” your Bitcoin. Associated with the wallet is a public key. This is an address that can be used to send Bitcoin to, just like somebody has an email address or a bank account number.
Also, there is another (VERY important) key that is associated with a wallet that is called a private key 🔐, which sort of functions as its password. Signing with this private key is the only way somebody can prove their ownership of the wallet, and it is what enables them to send the Bitcoins in that wallet. You lose this key (and depending on the type of wallet, your seed words), you lose your BTC 🙈.
Note that the order actually goes as follows:
- When a wallet is set up, that wallet generates a random private key.
- From that private key (using an Elliptic Curve Digital Signature Algorithm) a public key is generated (note that it is not possible to convert this back to its private key; it’s a one-way algorithm).
- From that public key (something we will discuss in the Privacy section) a wallet address is generated.
Owning Bitcoins does not mean you actually have coins sitting in your wallet. A Bitcoin is not a piece of code you own or that is stored somewhere. The value of the BTC associated with a wallet (let’s call it ABC123) is based on how many transactions on the blockchain say “Address EXAMPLE890… sends x amount of BTC to address ABC123” as well as how many say “Address ABC123… sends x amount of BTC to address EXAMPLE453”.
In other words, the Bitcoin blockchain stores an incredible amount of data that specifies who sent how much to what address 📒. This data (who sends, what amount, who receives) is stored in individual transactions. The ownership of Bitcoin is calculated by looking at all the transactions coming into to an address and those that go out.
Now, if address ABC123 wants to spend the BTC that has been received from another address, it has to prove it is allowed to do so by signing the transaction with its private key 🔑 (that conditional data — you can only use it if signed with the correct private key — can be found in the previous transaction that is called upon). A new transaction is generated, the BTC is sent, and we start again. Keep in mind that this is a simplified version; some details will be added later.
Core takeaway: Bitcoins are not actual coins, they are just a combination of transactions that prove you have BTC to spend. Private keys are used to sign transactions and verify ownership.
“The problem of course it that the payee can’t verify that one of the owners did not double-spend the coin.”
“The only way to confirm the absence of a transaction is to be aware of all transactions.”
Confirming the absence of a transaction is done by broadcasting each transaction to the entire network 📡 and creating a shared history of all previous transactions (chronologically).
3. Timestamp Server
“A timestamp server works by taking a hash of a block of items to be timestamped and widely publishing the hash…”
The idea here is to collect the transactions that have been publicly broadcast into blocks, timestamp them (adding a time value 🕔), adding some more relevant data (we’ll get to this later) and then running it through a SHA256 hashing algorithm ⏩.
What this basically does is it converts the block and its data into a string of characters that can be used to uniquely identify that block (only that combination of data will get you that hash value). Each new block (before being added and run through a SHA256) can now refer back to the hash of the previous block in the chain, creating a chain of blocks in chronological order. This way, everybody can see which blocks (and its transactions) have taken place in the past and in what order.
This chain of blocks that are linked via their hash value is what makes up the actual blockchain (“blockchain” is often used to refer to entire protocols and systems but really it is the actual chain of blocks itself; the actual database).
4. Proof-of-Work & 5. Network
All right. Seems great! Though, how do we make sure the data that is added to the chain is actually correct? Can anybody just add blocks with transactions that do not exist? 🤔
“To implement a distributed timestamp server on a peer-to-peer basis, we will need to use a proof-of-work system…”
What is needed is a system that demands some work to be done before being able to add or suggest a new block to the blockchain. Just like the infamous CAPTCHA on the web, the goal is to create a barrier where it becomes harder (and infeasible) to spam the system (or in Bitcoins case, suggest false data). Bitcoin does this as follows.
I mentioned above that transactions are broadcast to the entire network. At this point, they are not yet added to the chain. Miners (those that are going to perform the “work” to add the block to the chain) are going to perform the previously mentioned hashing. They collect these transactions and put them in a block (as Merkle Root, we’ll discuss that later) together with the aforementioned timestamp, previous block hash, and some other relevant data like block height (what block # in the chain), and more.
Having collected all this data in a block, they run it through the SHA256 hashing algorithm. Again, what this basically does is it converts all that data into a string of characters that uniquely identifies that block and its data. Change a tiny thing in the block’s data and the entire hash changes (there is no known pattern for this but it is not random; change it back and you will get exactly the same hash).
Look at how the hash changes when I add the number “1” to the string of characters.
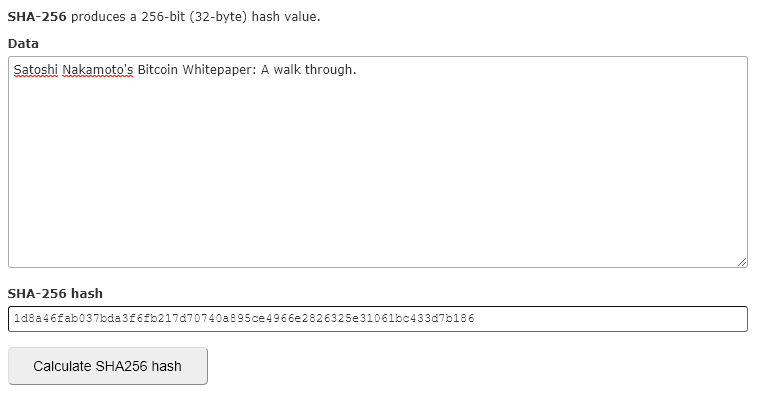

The Bitcoin blockchain does not demand just a hash; it wants a hash that starts with (at the moment of writing) seventeen 0’s 😲.
For example: 000000000000000006fb217d70740a895ce4966e2826325e31061bc433d7b186
How do miners get that hash? They need to add a number to the block’s data which is called a ‘nonce’ (they add it just like I added the “1”). Nobody knows what number is needed to find the correct hash 🤷. The only way to find it is through trial-and-error: guessing.
“… we implement the proof-of-work by incrementing a nonce in the block until a value is found that gives the block’s hash the required zero bits.”
This process, guessing the right nonce, is what is referred to as ‘mining’ ⛏️. The miners with the largest CPU resources (most computational power) have the highest chance of being the first to find that correct nonce.
As long as more than 51% of the CPU power is in the hands of honest nodes, it will be impossible for a malicious miner to consistently win the mining process and add false data to the chain. The longest chain is always the chain that is taken as the truthful chain.
“… the proof of work difficulty is determined by a moving average targeting an average number of blocks per hour. If they’re generated to fast, the difficulty increases.”
This process of adding a new block to the blockchain happens every 10 minutes or so. This is kept stable by the protocol adjusting the mining difficulty (# of starting 0’s) — also called “difficulty bomb” 💣 — accordingly as computational power grows over time.
6. Incentive
Why would miners go through all that effort and pay a lot of money to obtain the computational power to mine?
Once the block is agreed upon, an extra transaction is added to the beginning of the block (often referred to as the ‘coinbase transaction’) which allocates newly created BTC to the winning miner’s wallet address, rewarding them for the work put in and providing a way to distribute coins into circulation 💰. On top of that, each transaction in the block has a small — at least that was the goal — transaction fee associated with it which also goes to the winning miner.
“Once a predetermined number of coins have entered the circulation, the incentive can transition entirely on transaction fees and be completely inflation free.”
We are going to skip over part 7 (Reclaiming Disk Space) and part 8 (Simplified Payment Verification) and will briefly discuss these sections at the end. Although they are an important part of how Bitcoin operates, for the sake of understanding the core of the paper, they are less so.
9. Combining and Splitting Value
“To allow value to be split and combined, transactions contain multiple inputs and outputs. Normally, there will be either a single input from a larger previous transaction or multiple inputs combining smaller amounts, and at most two outputs: one for the payment, and one returning the change, if any, back to the sender.”
Something we already touched upon a bit earlier is how transactions are made up and how address value is calculated.
The BTC value held in an address is basically the sum of all its potential input transactions (i.e., the value of all the transactions towards that address that have not been spent). When the address holder wants to spend its BTC, they cannot just take exactly that amount and send it. They have to use their input transactions as whole pieces to do so (kind of like how you need to pay with an entire dollar note and can’t cut it in pieces to pay with). So what does that mean in the practical sense?
Andy is back 👋 but now he has a wallet with 0.5BTC. This value comes from three unspent transaction outputs (UTXO) (or future input transactions; the UTXO function as a reference for the input transaction for a new transaction):
a) 0.15BTC
b) 0.27BTC
c) 0.08BTC
Andy wants to send 0.38BTC to Brenda (lucky Brenda… 🙅). When he generates this transaction, the Bitcoin protocol will take the needed inputs that together are equal to or higher than (≥) the payment to Brenda and will use those as whole pieces to generate two output transactions.
In our example, the input transactions a and b are used (0.15 + 0.27 = 0.42) to generate the payment output transaction of 0.38BTC to Brenda, as well as another output transaction to Andy’s own address which returns the change (0.42–0.38 = 0.04). Both these output transactions can function as new input transactions for future payments by the address holders.
Note: There is also a miner/transaction fee involved that is taken out of the equation. So, the change that is returned is a bit less.
Core takeaway: Output transactions require whole input transactions that together are at least equal to or more than the output value. Any excess (Inputs -(payment+miners fee)) is returned as change and can be used as a new input transaction.
10. Privacy
We already discussed the existence and usage of wallets, public keys, and private keys earlier. In the situation where a third-party stores our information (like a bank), privacy is obtained by limiting the access to that information by handling permissions and securing the servers on which it is stored.
However, as mentioned before, these provide a single point of failure and attack, making it prone to loss and hacking. So, how does the Bitcoin go about providing privacy if all transactions are openly broadcast to the entire network? 🙃

“The necessity to announce all transactions publicly precludes this method, but privacy can still be maintained by breaking the flow of information in another place: by keeping public keys anonymous.”
The idea here is to keep the public key anonymous 🕵️. As long as people cannot associate a public key with a particular person, there is no way to reveal its identity.
A way of doing this that is currently used in the protocol is via the generation of wallet addresses, with a wallet being able to hold multiple addresses. Instead of showing public keys in the transaction data, wallet addresses are used. Just like public keys are created based on private keys using a one-way algorithm, the same is done to generate a wallet address from a public key (using the SHA256 followed by a RIPEMD160). What we are left with (after running it through a BASE58CHECK to make it more readable) is a wallet address that is used in the transaction data.
“As an additional firewall, a new key pair should be used for each transaction to keep them from being linked to a common owner.”
Without diving into to much detail, multiple addresses can be generated from a single private key by implementing a counter and adding an incrementing value in order to create sub-private keys (which can be used to create public keys that in its turn can be used to generate wallet addresses). This way, a single private key can give access to a wallet that has transactions going in and out of multiple addresses (this is referred to as a deterministic wallet).
Many Bitcoin software and services handle this auto-creation of wallet addresses when executing a transaction, making it nearly impossible to reveal the identities behind a publicly broadcast transaction.
We will briefly walk through the leftover pieces of the whitepaper, and then wrap it up.
7. Reclaiming Disk Space
“Once the latest transaction in a coin is buried under enough blocks, the spent transactions before it can be discarded to save disk space.”
When a transaction is buried under enough blocks, meaning it has been thoroughly validated by the system, it does not necessarily need to keep storing all the transaction data in the block. This is possible without breaking the hash by including only the Merkle Root of all transactions in the block’s hash, and not the individual transaction data. For more information on Merkle Trees 🌲, check out Wikipedia.
In short, all transactions are hashed and those hashes are paired before being hashed again, and so forth until you reach the parent hash of all transactions, called the Merkle Root.
8. Simplified Payment Verification
In order to verify a payment, a user only needs to be able to link the transaction to a place in the chain by querying the longest chain of blocks and pulling the Merkle branch in which the transaction exists. If that user can do so, they can trust that the transaction has been valid given that the network has included it and further blocks have been build on it.
11. Calculations
This dives into the more mathematical background of why the network will be secure when more than half of the network consists of honest nodes.
Basically, as long as there are more honest nodes than malicious nodes, as the chain grows it becomes harder and harder for an attacker to generate an alternate chain that allows them to take back payments they have made. The more blocks that are added on top of a particular transaction, the lower the probability becomes that an attacker can catch up with an alternate chain.
That is why we often see the number 6 when talking about (block) confirmations, which basically refers to 6 blocks that are added after the transaction was included, and functions as the complete confirmation threshold.
Done
There we are! 👏 We have covered pretty much the entire original Bitcoin whitepaper. This paper has functioned as the genesis of the blockchain technologies that we see today. Getting a better grasp of its contents will definitely help you understand the current ecosystem of the industry.
I really hope this article has helped you out. If so, claps would be greatly appreciated and do let me know in the comment section below what your thoughts are on the piece. I would love to hear what you think. Any suggestions, corrections, or feedback is all greatly appreciated.
All the best,
Valentijn | @vvdhout
