
By Pramono Winata
Have you ever gotten into trouble trying to handle a single process that's really huge or heavy? If so, I can help you figure out how to better manage it.
In this article I will be sharing how I'm currently managing a single message that is too big to be processed on a single process. I've split it into different chunks, which results in separate processes.
I won't go into much technical detail, but more of the architectural process.
I'll discuss some bits about caching usage and pubsub, but I will not go into details on the implementation. Instead, I'll focus on the pattern itself.
The Problem

Perhaps the first question that comes to your mind is why we need to split a single process into several concurrent processes?
There might be several reasons to do this. In my case, though, I did it because the message was just too big.
To give you some idea about my situation, let me brief you a bit with this simple diagram:
 I'm not a great diagram maker, but this should get the point across
I'm not a great diagram maker, but this should get the point across
To simplify it with words, imagine two separate services, service A and service B, with a pubsub service in the middle of it.
If you are not sure what a pubsub service is, just imagine it as a broker that helps the message from one service reach the other service.
Service A will then publish a message and through the pubsub, service B will then process it. After it has finished the process, it will do another process to mark that the message has been processed.
Simple enough right?
It's just that in some cases when the message is too big, it will not successfully publish the message because of the pubsub service's limitations.
Alright, this should give you an overview of the issues that I've encountered. So how did I fix this problem? In the next section, I will run you through my solution.
My First Approach

The first thing that came to my mind was increasing the size that the pubsub service can handle, which is doable with a single config change.
But life won't be too interesting if it's that easy right? What happens if the message just keeps getting bigger? Do we keep increasing the size of the pubsub?
Turns out that doing so can result in a lot of scalability issues. Not good for a long term solution.
Then I came up with another solution that I thought might solve it: I split that message into several messages and tried to process those parts separately.
Now, the system looked like this:
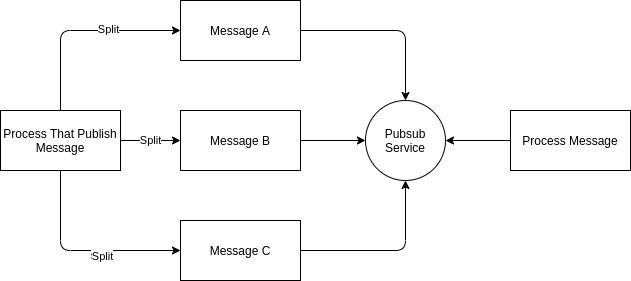 My updated system/process
My updated system/process
As you can see from the diagram, the message gets split into several smaller messages. How it's split and which part of the message needs to be split might differ for each case and flow.
In my case, though, my message actually contains a list of items so I can split it by each item.
Let's say that I have 10 items. Previously, it would publish all 10 items in one message. But now after splitting the message up, it will turn that message into 10 messages.
This results in a single process becoming several processes all together. A single publish will turn into 10 publishes which in turn will turn that single process into 10 processes.
This might not look ideal when you look at it that way, but this is the best solution I came up with and it sure does work.
So is that all, only splitting it up?
Not really – remember that final part where it marks the process as finished?
If so, you might wonder why that part is missing from my new diagram.
Don't worry – it's not that I forgot about it. I intentionally left it out for the next part.
The thing is, when you split the message and break it into several processes, your system might not know if the whole process is actually finished. This is another major issue that we need to tackle, and thankfully I managed to find a solution for that, too.
How to Handle Finishing Processes

So how exactly do I know if the process has finished, since those processes are happening concurrently?
The solution that I came up with is storing the number of processes that need to be done and decrementing it each time a process finishes. This way we will be able to know if the last process has finished.
It sure sounds simple enough, as long as we have a reliable place to store that data.
And actually there quite a lot of options for that. One of them is called Redis, and I am using that to deal with my issue here.
If you are not familiar with Redis, it is a service that is generally used as a cache.
We will manage our Redis mechanism like this:
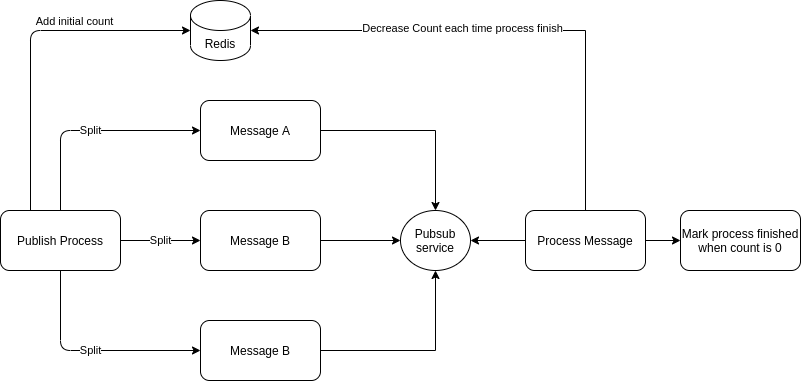 Adding Redis to mark our process
Adding Redis to mark our process
The process looks exactly the same as before, but with the addition of Redis in the middle. You need to make sure you have a valid initial count for this case.
In my case, since I'm publishing a list, I can easily put the length of my list as my initial counter. And for the counter, I can just decrease it by one each time a process has finished. Then I will be able to know if I have finished all my processes simply by referring to my Redis counter. If it has reached 0, it means that I can safely mark that all of my processes are done.
Wrapping Up
To sum it all up, I split the message into several messages which will be processed all together in several processes. To manage the message processes, I use Redis caching.
The solution that I have described above will not be a silver bullet every time you have a problem processing a very big message. There are other ways like streaming your message, but that will be a story for another day.
Thanks for reading my article through to the end! I sincerely hope that you enjoyed and found my article interesting and, most importantly, that it was useful.