
By Patrick Hund
Many people still worry that if you build a websites using tools like React, Angular, or Ember, it will hurt your search engine ranking.
The thinking goes something like this: the web crawlers that search engines use won’t be able crawl a page properly unless it’s completely rendered in the user’s browser. Instead, they’ll only see the HTML code delivered from the backend.
If that HTML code contains nothing more than a couple of meta tags and script tags, the search engine will assume your page is basically blank and rank you poorly.
I commonly see Search Engine Optimization (SEO) consultants recommend that you render your page on the backend, so that web crawlers can see a lot of nice HTML code that they can then index.
To me, this advice seems unreasonable and unrealistic. It’s 2016. Users expect pages to be dynamic and provide them with a snappy user experience. They don’t want to wait for a new HTML page to load every time they click on something.
So is the statement “client-side rendering hurts your page rank” still valid?
Doing The Research

First, a disclaimer: I’m by no means an SEO expert. But I did read up on the topic a bit, and here’s what I found.
Here’s an announcement from Google on their webmaster blog from October 2015:
Today, as long as you’re not blocking Googlebot from crawling your JavaScript or CSS files, we are generally able to render and understand your web pages like modern browsers. To reflect this improvement, we recently updated our technical Webmaster Guidelines to recommend against disallowing Googlebot from crawling your site’s CSS or JS files.
Here’s a Search Engine Land article from in May of 2015:
We ran a series of tests that verified Google is able to execute and index JavaScript with a multitude of implementations. We also confirmed Google is able to render the entire page and read the DOM, thereby indexing dynamically generated content.
SEO signals in the DOM (page titles, meta descriptions, canonical tags, meta robots tags, etc.) are respected. Content dynamically inserted in the DOM is also crawlable and indexable. Furthermore, in certain cases, the DOM signals may even take precedence over contradictory statements in HTML source code. This will need more work, but was the case for several of our tests.
These two sources suggest that it is, indeed, safe to use client-side rendered layout.
The Preactjs.com Test
I recently tweeted a lament about SEO consultants nitpicking about my beloved React. To be precise, I’m in the process of migrating to Preact, a light-weight alternative to Facebook’s React. I got this reply from Jason Miller, one of the developers working on Preact:
Aside from the blog article from Search Engine Land that I’ve quoted above, Jason tweeted a link to a Google search for the Preact home page, which looks like this:

This page is rendered entirely client-side, using Preact, as a look at its source code proves:
<!DOCTYPE html><html><head>
<meta charset="utf-8">
<title>Preact: Fast 3kb React alternative with the same ES6 API. Components & Virtual DOM.</title>
<meta name="viewport" content="width=device-width,initial-scale=1,maximum-scale=1,minimal-ui">
<meta name="mobile-web-app-capable" content="yes">
<meta name="apple-mobile-web-app-capable" content="yes">
<meta name="format-detection" content="telephone=no">
<meta name="theme-color" content="#673AB8">
<link rel="manifest" href="/manifest.json">
<link rel="icon" type="image/png" href="/assets/app-icon-192.png" sizes="192x192">
<script>(function(url){window['_boostrap_'+url]=fetch(url);})('/content'+location.pathname.replace(/^\/(repl)?\/?$/, '/index')+'.md');</script>
<link rel="shortcut icon" href="/favicon.ico">
<link href="/style.6bae35e4ff9d687cb418.css" rel="stylesheet">
</head><body>
<script>(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)})(window,document,'script','//www.google-analytics.com/analytics.js','ga');ga('create', 'UA-6031694-20', 'auto');ga('send', 'pageview');</script>
<script type="text/javascript" src="/bundle.a0afd09fd48712ed0f26.js"></script>
</body></html>
If the Googlebot were not able to read the HTML code rendered by Preact, it wouldn’t show more than the contents of the meta tags.
And yet, here’s what the Google results look like when searching for site:preactjs.com:
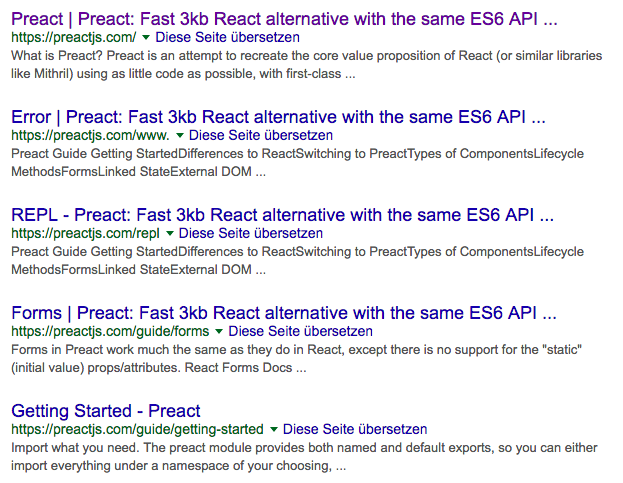
Another article by Andrew Farmer from March 2016 warns about lacking JavaScript support by search engines other than Google:
In my research I couldn’t find any evidence that Yahoo, Bing, or Baidu support JavaScript in their crawlers. If SEO on these search engines is important to you, you’ll need to use server-side rendering, which I’ll discuss in a future article.
So I decided to try out Jason’s test with other search engines:
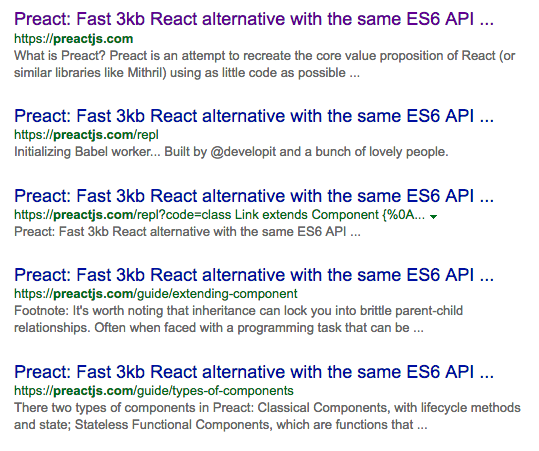
✅ Bing
Andrew’s warning regarding Bing seems insubstantial. Here are the Bing results when searching for site:preactjs.com:
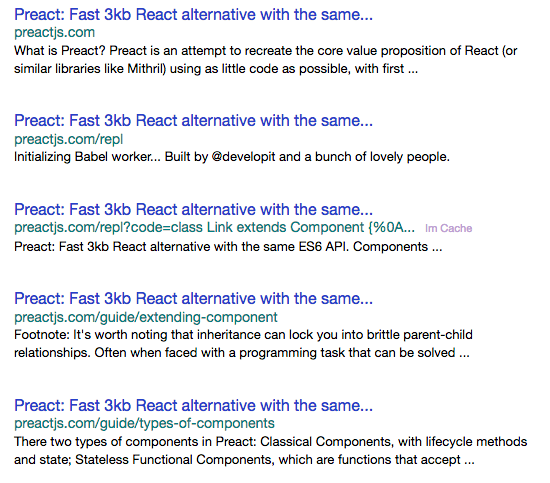
✅ Yahoo
And the Yahoo results when searching for site:preactjs.com:
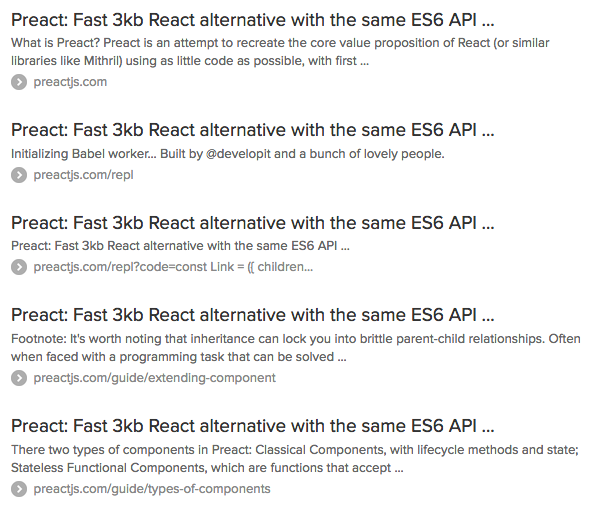
✅ Duck Duck Go
And the Duck Duck Go results when searching for site:preactjs.com:
⚠️ Baidu
Chinese search engine Baidu does have problems with preactjs.com. Here are its results when searching for site:preactjs.com:

So it would seem that unless ranking high in what is essentially a China-only search engine is a priority for you, there’s nothing wrong with rendering your web pages on the client-side using JavaScript, as long as you follow some basic rules (quoted from Andrew Farmer’s blog post):
- Render your components before doing anything asynchronous.
- Test each of your pages with Fetch as Google to ensure that the Googlebot is finding your content
Thanks for reading!
Update 25th October 2016
Andrew Ingram ran the same tests that I ran an came to a different conclusion.
Quote from Andrew:
Here’s how many pages various search engines have indexed using the query “site:preactjs.com”
Google: 17 Bing: 6 Yahoo: 6 Baidu: 1
One of the Google results is an error page, but it presumably can’t be de-indexed automatically due to there not yet being a way of declaring a 404-equivalent in SPAs.
I’ve also read (I can’t recall where) that Google has a latency of a few days when it comes to indexing SPAs compared to server-rendered apps. This may not be a problem for you, but it’s worth knowing about.
His working hypothesis is that search engine robots other than Google are able to index client-side rendered pages, but not crawl them, i.e. follow links and index other pages of a website.
→ Follow the discussion on Hacker News
Acknowlegements
Thanks to Adam Audette (Search Engine Land) and Andrew Farmer for their excellent blog articles from which I quoted, Jason Miller for his input and inspiration, my colleagues from the eBay Classifieds Group for their support and Quincy Larson of Free Code Camp for publishing this article!