
By Burke Holland
“In science, computing, and engineering, a black box is a device, system or object which can be viewed in terms of its inputs and outputs (or transfer characteristics), without any knowledge of its internal workings. Its implementation is “opaque” (black). Almost anything might be referred to as a black box: a transistor, an algorithm, or the human brain.”
— Shamelessly lifted from Wikipedia by me
A few weeks ago I watched an HBO documentary (because I’m old and that’s what old people do — we watch documentaries) on Traumatic Brain Injury.

In the film, they follow four people who have awakened from comas caused by a physical injury. All of the patients are in various stages of recovery. They have limited ability to move, speak, or even hear. Anything you need your brain for may or may not work. Which is why I was shocked when the doctors asked one of these patients if anything had changed since before their accident, and they said “No.”
They are unable to walk, unable to hold their head up — both things they could do only a few months ago and yet their brain was unable to process that anything had changed.
This is the definition of a black box—data goes in, but what comes out is not what we expect. And there is nothing we can do about it because you can’t “debug” a brain. If you could I would put a breakpoint in there and find out why the “Beer And Chicken Wings” line executes EVERY SINGLE NIGHT.

That’s why it took six months to figure out why this same patient could not hear. SIX MONTHS. All they can do is try different things until something works or doesn’t work and they can narrow it down.
It’s all trial and error. For people with brain injuries, much of the recovery process is exactly this: trying different inputs over and over until something works. Which, sadly enough, is exactly how much of Serverless development currently goes.
Serverless Sadness
The current state of Serverless is much like the human brain. It’s a cool technology, but it’s internals are obscured from developers and we are left to make educated guesses as to what is actually happening.
This is an incredibly difficult way to build applications, and it’s nearly difficult enough to eclipse any cost benefits Serverless would provide.
“My Serverless function only costs me $1 a month! It took me 6 months to build it, but LOOK AT HOW CHEAP IT IS!”
I made this highly scientific and useful graph to visualize the cost/benefit of Serverless over development time.
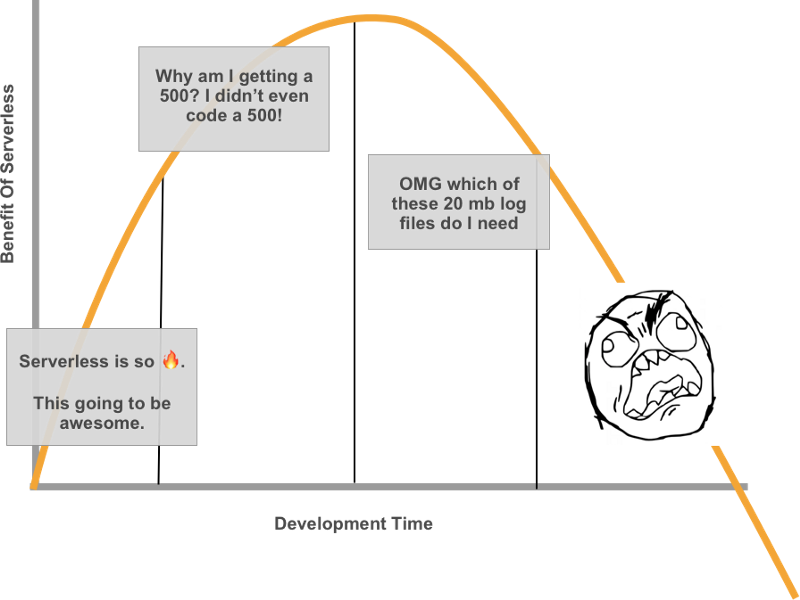
Part of the reason why this is the case is that the whole point of Serverless is to abstract away the runtime — it’s the next walk up that wonderful stack of abstractions. And when you abstract, you lose some amount of control.
But we like abstractions.
JavaScript is an abstraction that eventually gets executed as machine code. That means we lose control over things like memory management, but HAHAHAHAHA nobody cares because, JavaScript.
In the case of Serverless, it’s great that the abstraction is moved into a cloud somewhere, but we need access to that abstraction at development time. Most Serverless providers offer an online editor as the primary interface for development. That’s cool and all, but you can’t really build server applications in an online editor because you don’t have any access to, you know, THE SERVER. And therein lies the proverbial (and literal) box.
So let me rephrase that: We like abstractions, until we don’t.
When We Don’t Like Abstractions
Let’s start with what a basic Serverless experience is like.
If you were to create a new Serverless project with something like Azure Functions, you get dropped into the online editor experience.
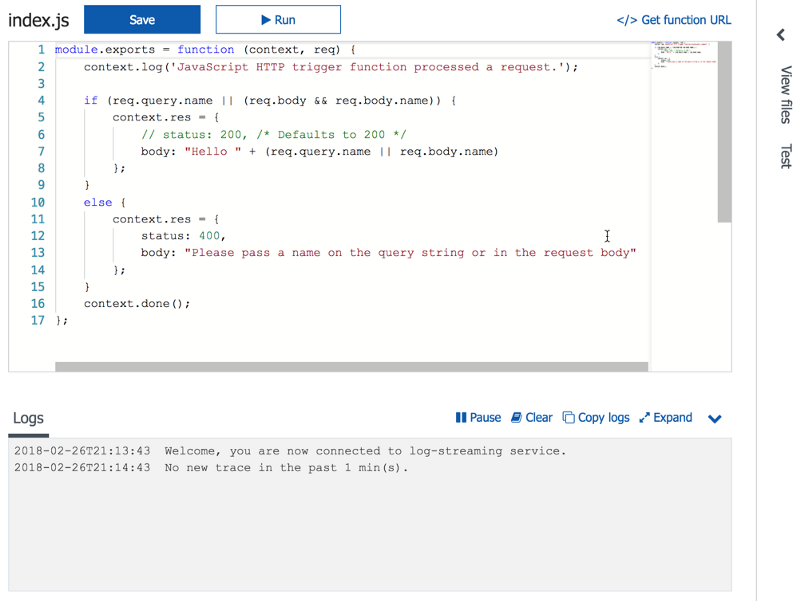
This is pretty convenient. There’s nothing like being able to just start writing code directly. Or if you’re me, “copying and pasting from Stack Overflow.”

You can even test the function online. All in all, it’s a nice first experience.
This has serious limitations, though. What if we wanted to install a Node package? I don’t know which one, but probably left-pad. How do you do that? We can’t quickly switch between files. We can’t lint the code and we sure as hell can’t add any breakpoints.
Now anyone who is serious about Serverless (or just building anything at all for that matter) doesn’t take the online editor experience too seriously. To build anything of consequence, we need to develop locally.
Local Serverless Development
Most Serverless providers offer some sort of local development experience. That’s usually accomplished by shipping the user an emulator . This is not the final runtime, which means that you have to make some assumptions about things you just don’t know.
For instance, you can develop a serverless function locally with a simple Node web server, but it’s highly likely that’s not how your code is going to be called in production. This means that the inputs and possibly even the entire context of the function could….WILL be different when you deploy.
Azure Functions handles this a bit differently. Instead of giving you an emulator for local development, they give you the runtime. Thats right, you get the whole box.
Local Development With Azure Functions
When you install the Azure Functions Core Tools, you are installing the same runtime that Azure uses. Because you get the whole runtime, you can build any kind of function locally. Not just HTTP triggers.
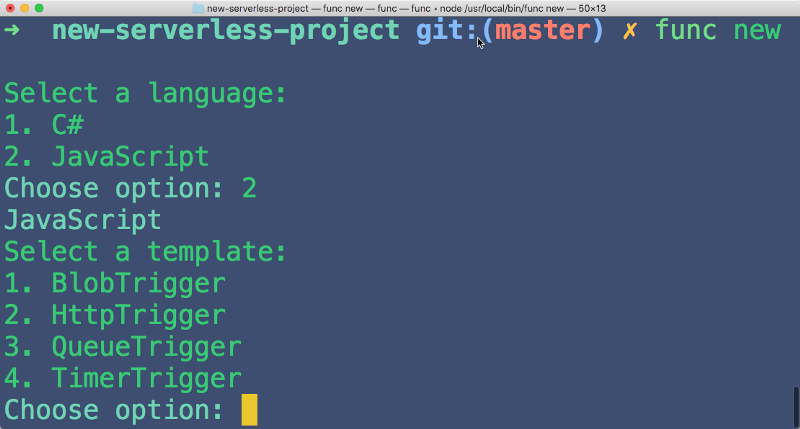
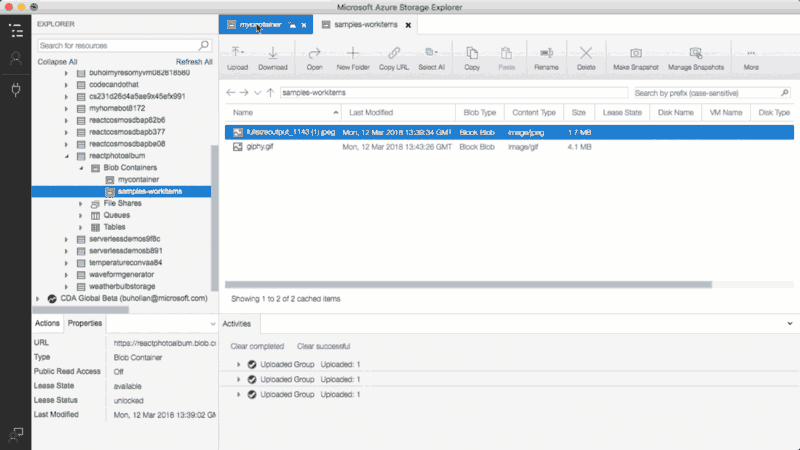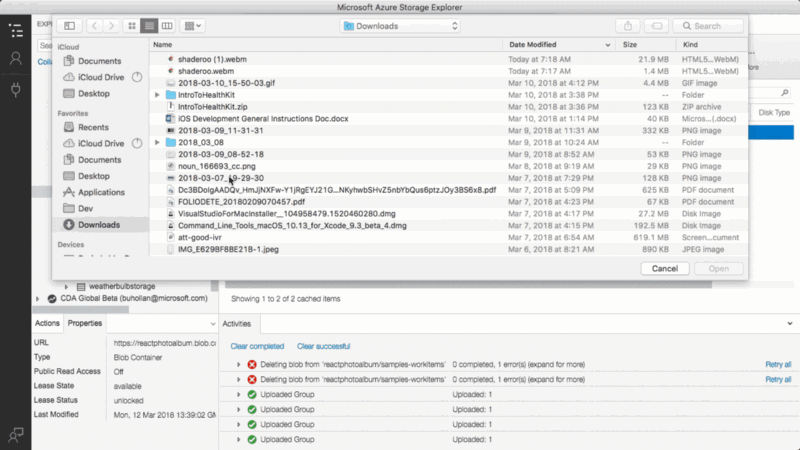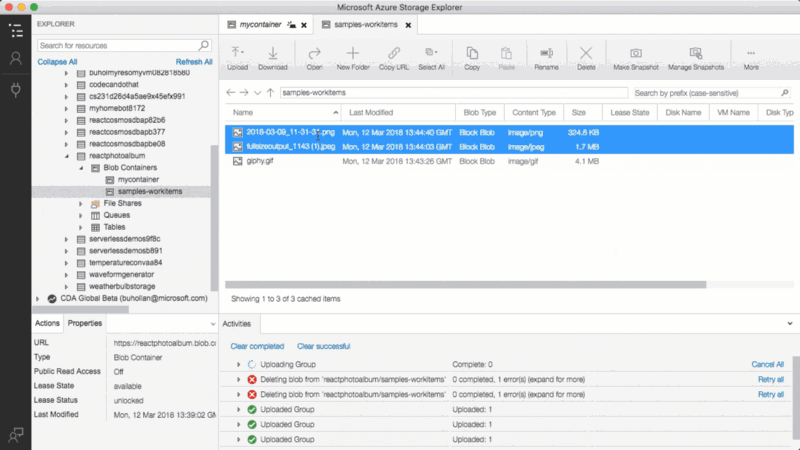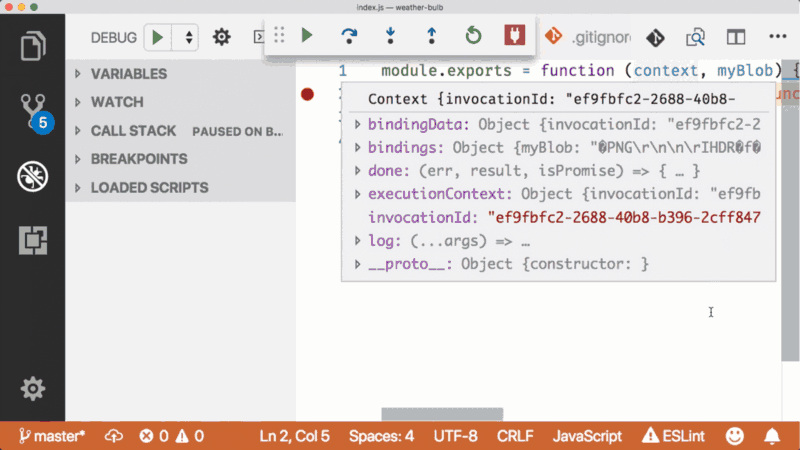
Note that you can do Blob and Queue Triggers as well. If you drop a file in Azure Blob storage, your local function gets triggered. If you put a message in the Azure Message Queue, your local function triggers. That’s great because otherwise, how on earth would you test blog or queue triggers? You wouldn’t. You would just Hail Mary it up into the cloud and pray.

Hail Mary’s only work for Aaron Rodgers. That’s two football references in a row and I’m sorry. You deserve better.
Having the full runtime also makes local debugging easy if you’re using VS Code. It kind of helps that Microsoft makes both of these things.
Debugging Serverless Functions With VS Code
You can install the Azure Functions extension for VS Code which automatically enables local function debugging.
This puts a new panel in VS Code for Azure Functions. You can see all of your different functions projects in this space.
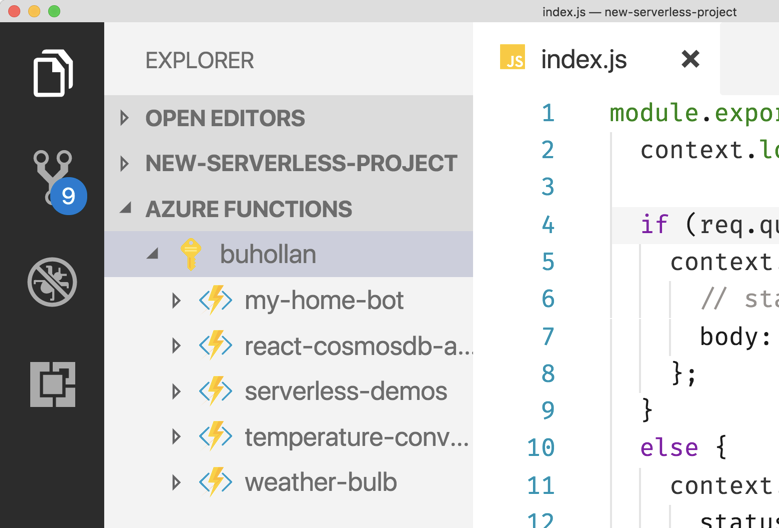
More importantly, it adds a built-in launch configuration for debugging. If you were to open an Azure Functions project in VS Code, the extension recognizes that and prompts you to setup this project for use with the extension.
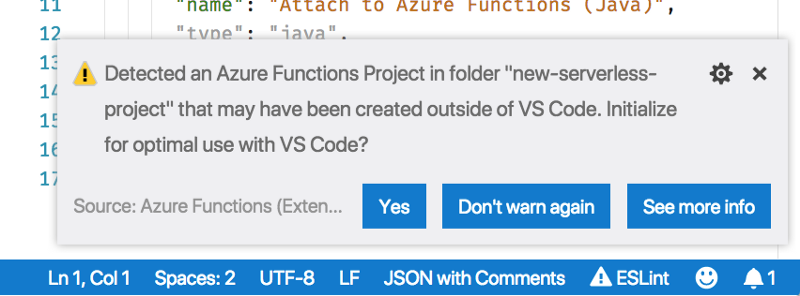
This tweaks your project so that to run and debug this function, put a breakpoint in the gutter and hit the green button in the debug panel.
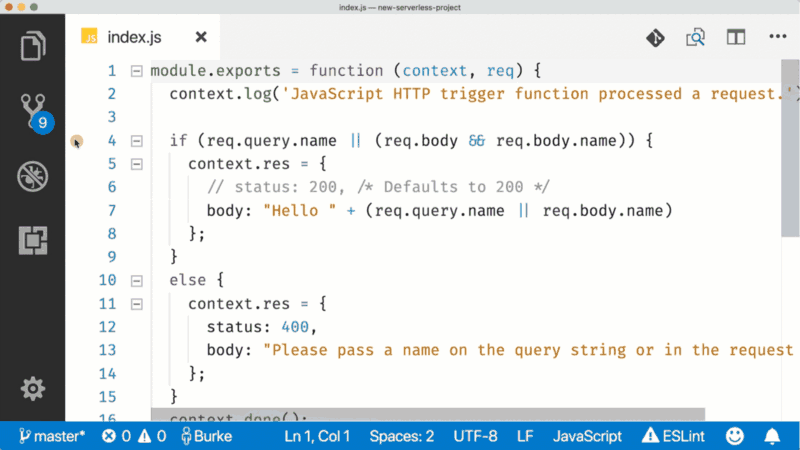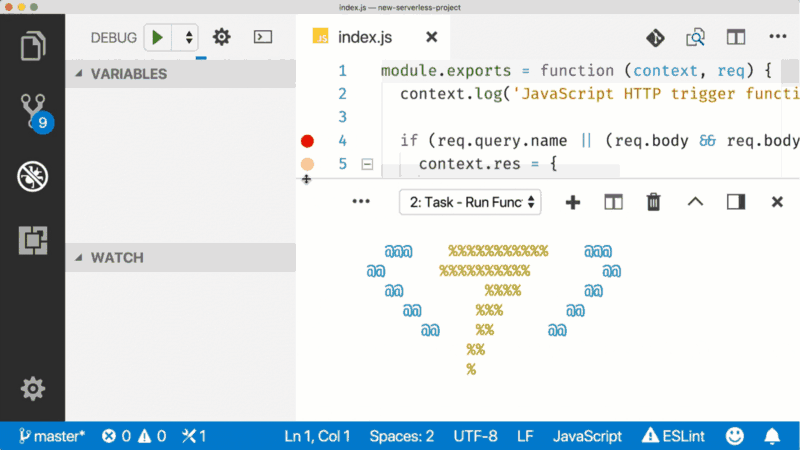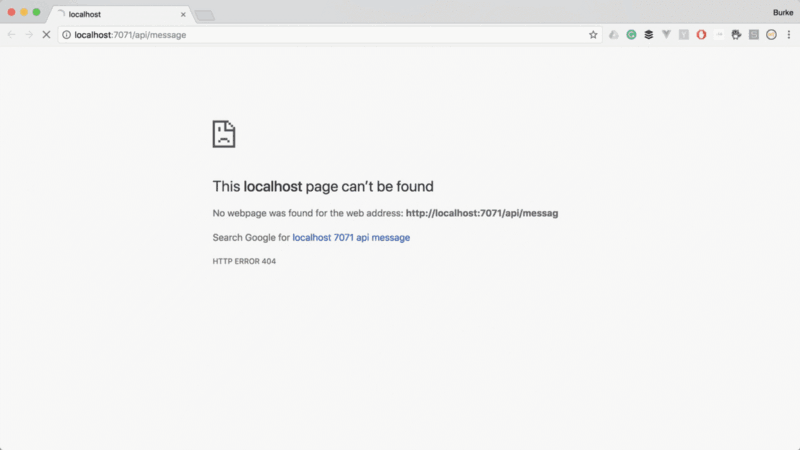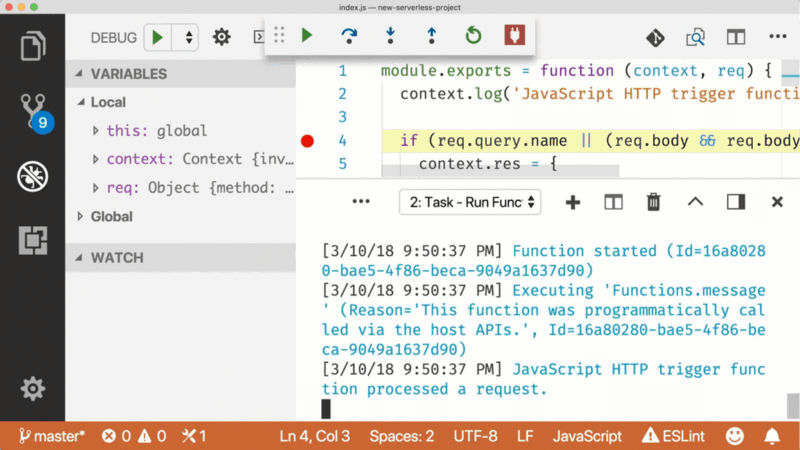
In the case of a Timer Trigger, you get the Timer that Azure Functions uses, along with the next scheduled run times.
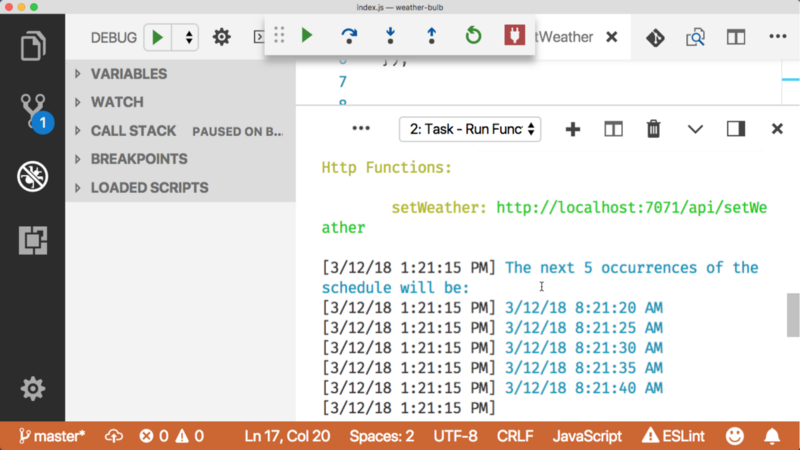
I already mentioned the blob and queue triggers, but just in case you are like me and “pics or it didn’t happen”…
Black Boxes Are For Brain Surgeons
Actually, there is no job called “Brain Surgeon”. It’s called Neurosurgeon, and as of 2015, the average salary is $609,639 per year. Yeah. Seriously.
Well, I’m not a brain surgeon and I’m sure as heck not getting paid enough to mess with black boxes all day. Serverless has a bright future, but only when it provides the same productivity as it does cost value. Refer to the chart in this post if you have any questions on that equation.