By Domenico Angilletta
In this article, I am going to describe how I moved a heavy task like image pre-processing from my application server to a completely serverless architecture on AWS in charge of storing, processing and serving images.
The Problem
Image pre-processing is a task required by many web applications. Each time an application allows a user to upload an image, it is very likely that this image needs to be pre-processed before it is served to a front-end application.
In this article I am going to describe a serverless architecture based on AWS, that is extremely scalable and cost-efficient.
But let’s start from the beginning. In one of my last projects, a marketplace web application where users have to upload an image of a product they want to sell, the original image is first cropped to the correct image ratio (4:3). It is then transformed in three different formats used in different places of the front-end application: 800x600px, 400x300px, and 200x150px.
Being a Ruby on Rails developer, my first approach was to use a RubyGem — in particular Paperclip or Dragonfly, which both make use of ImageMagick for image processing.
Although this implementation is quiet straightforward (since it it mostly just configuration), there are different drawbacks that could arise:
- The images are processed on the application server. This could increase the general response time because of the greater workload on the CPU
- The application server has limited computing power, which is set upfront, and is not well-suited for burst request handling. If many images need to be processed at the same time, the server capacity could be exhausted for a long period of time. Increasing the computing power on the other side would result in higher costs.
- Images are processed in sequence. Again, if many images need to be processed at the same time, speed could be very bad.
- If not correctly configured, these gems save processed images on disk, which could quickly make your server run out of space.
In general, based on how much image processing your application does, this solution is not scalable.
The Solution
Having a closer look to the image pre-processing task, you’ll notice that there is probably no need to run it directly on your application server. In particular this is the case if your image transformations are always the same and do not rely on other information than the image itself. This was the case for me, where I always generated different image sizes together with an image quality/weight optimization.
Once you realize that this task can be easily isolated from the rest of the application logic, thinking about a serverless solution that just takes an original image as input and generates all needed transformations is straightforward.
AWS Lambda turns out to be a perfect fit for this kind of problem. On the one side, it can handle thousands of requests per second, and on the other side, you pay only for the compute time you consume. There is no charge when your code is not running.
AWS S3 provides unlimited storage at a very low price, while AWS SNS provides an easy way of Pub/Sub messaging for microservices, distributed systems, and serverless applications. Finally, AWS Cloudfront is used as the Content Delivery Network for the images stored on S3.
The combination of these four AWS services results in a very powerful image processing solution at a very low cost.
High Level Architecture
The process of generating different image versions from an original image starts with an upload of the original image on AWS S3. This triggers, through AWS SNS, the execution of an AWS Lambda function in charge of generating the new image versions and uploading them again on AWS S3. Here is the sequence in more detail:
- Images are uploaded to a specific folder inside an AWS S3 bucket
- Each time a new image is uploaded to this folder, S3 publishes a message containing the S3 key of the created object on an AWS SNS topic
- AWS Lambda, which is configured as consumer on the same SNS topic, reads the new message and uses the S3 object key to fetch the new image
- AWS Lambda processes the new image, applying the necessary transformations, and uploads the processed image(s) to S3
- The processed images are now served to the final users through AWS Cloudfront CDN, in order to optimize the download speed.
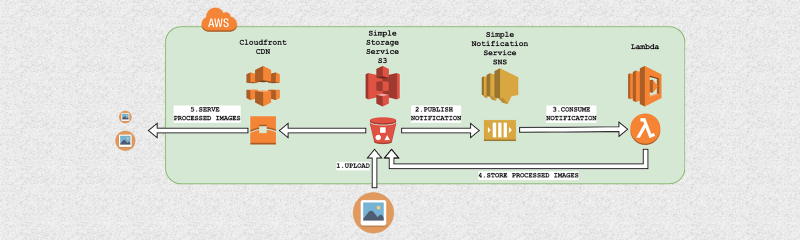
This architecture is very scalable, since each uploaded image will trigger a new Lambda code execution to handle just that request, so that there can be thousands of images being processed in parallel by as many code executions.
No disk space or computation power is used on the application server, because everything is stored on S3 and processed by Lambda.
Finally, configuring a CDN in front of S3 is very easy and allows you to have high download speeds from everywhere in the world.
Step-by-Step Tutorial
The implementation of this solution is relatively easy, since it is mostly configuration, except for the Lambda code that performs the image pre-processing. The rest of this article will describe in detail how to setup the AWS architecture, and will provide the code executed by AWS Lambda to resize the uploaded image in order to have a complete working example.
To try it out yourself, you will need an AWS account. If you don’t have one, you can create one for free and take advantage of the AWS Free Tier here.
Step 1: Create a Topic on AWS SNS
First of all, we need to configure a new SNS (Simple Notification Service) topic on which AWS will publish a message each time a new image is uploaded to S3. This message contains the S3 object key used later by the Lambda function to fetch the uploaded image and process it.
From your AWS console visit the SNS page, click on “Create topic,” and enter a topic name, for example “image-preprocessing.”
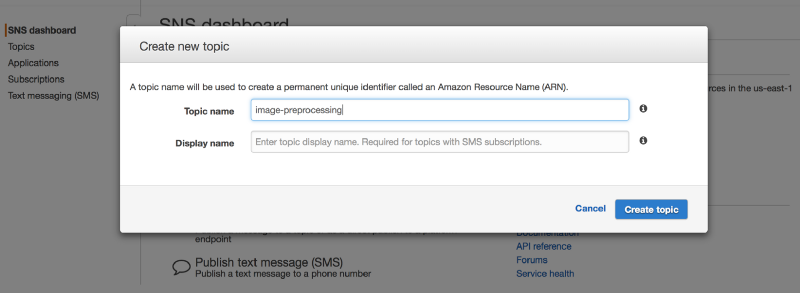
Next, we need to change the topic policy to allow our S3 bucket to publish messages on it.
From the topic page, click on Actions -> Edit Topic Policy, choose Advanced view, add the following JSON block (with your own arns for Resource and SourceArn) to the statement array and update the policy:
{ "Sid": "ALLOW_S3_BUCKET_AS_PUBLISHER", "Effect": "Allow", "Principal": { "AWS": "*" }, "Action": [ "SNS:Publish", ], "Resource": "arn:aws:sns:us-east-1:AWS-OWNER-ID:image-preprocessing", "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:s3:*:*:YOUR-BUCKET-NAME" } }}
You can find an example of a complete policy JSON here.
Step 2: Create AWS S3 folder structure
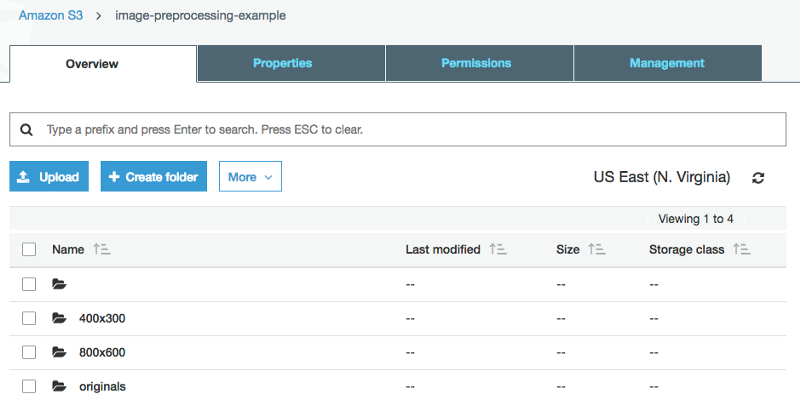
Now we need to prepare the folder structure on S3 that will contain the original and the processed images. In this example, we will generate two resized image versions, 800x600 and 400x300.
From your AWS console, open the S3 page and create a new bucket. I will call mine “image-preprocessing-example.” Then, inside the bucket, we need to create a folder named “originals,” a folder named “800x600,” and another named “400x300.”
Step 3: Configure AWS S3 Events
Every time a new image is uploaded to the originals folder, we want S3 to publish a message on our “image-preprocessing” SNS topic so that the image can be processed.
To do that, open your S3 bucket from the AWS console, click on Properties -> Events -> + Add notification and fill in the following fields:
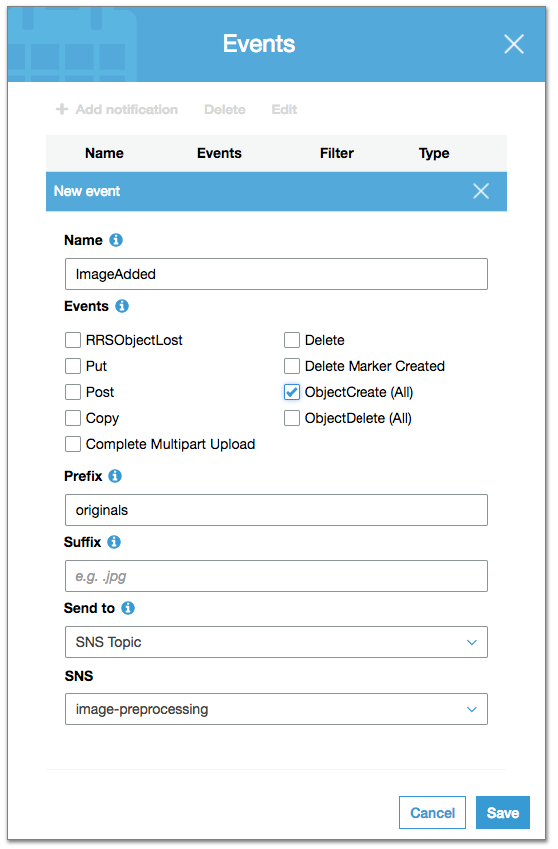
Here we are telling S3 to generate an event each time a new object is created (ObjectCreate) inside the originals folder (prefix), and to publish this event on our SNS Topic “image-preprocessing.”
Step 4: Configure IAM role to allow Lambda to access the S3 folder
We want to create a Lambda function that fetches image objects from S3, processes them, and uploads the processed versions again to S3. To do that, we need first to setup an IAM role that will allow our Lambda function to access the needed S3 folder.
From the AWS Console IAM page:
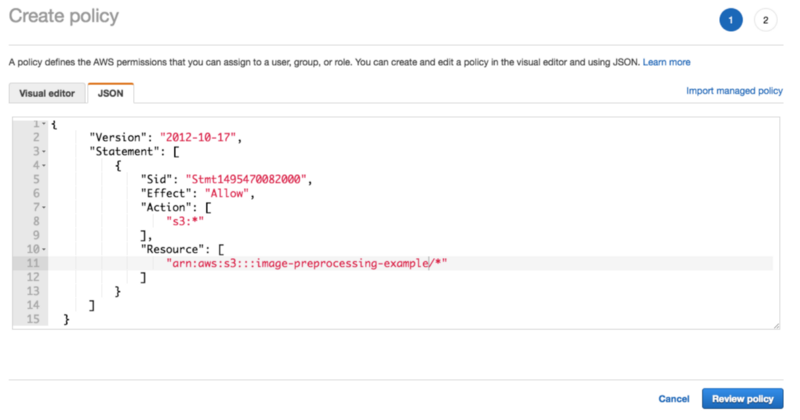
- Click on Create Policy
- Click on JSON and type in (replace YOUR-BUCKET-NAME)
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Stmt1495470082000", "Effect": "Allow", "Action": [ "s3:*" ], "Resource": [ "arn:aws:s3:::YOUR-BUCKET-NAME/*" ] } ]}
where the resource is our bucket on S3. Click on review, enter the policy name, for example AllowAccessOnYourBucketName, and create the policy.
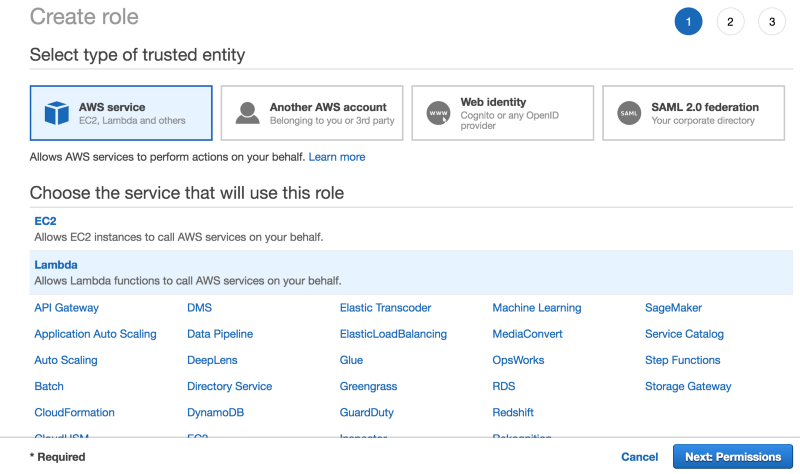
- Click on Roles -> Create role
- Choose Aws Service -> Lambda (who will use the policy)
- Select the previously created policy (AllowAccessOnYourBucketName)
- Finally, click on review, type in a name (LambdaS3YourBucketName), and click create role
 Create Lambda Role
Create Lambda Role
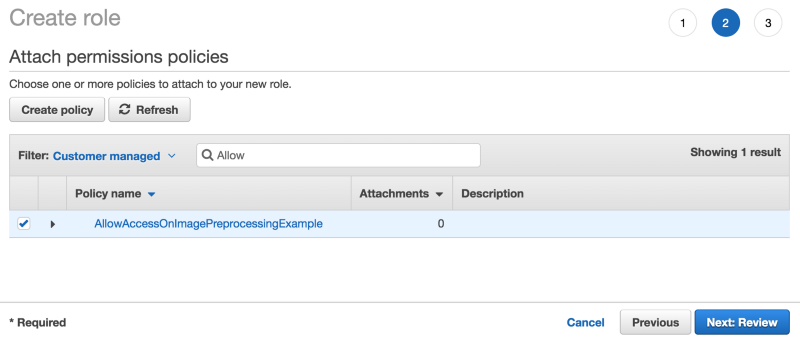 Attach Policy to Lambda Role
Attach Policy to Lambda Role
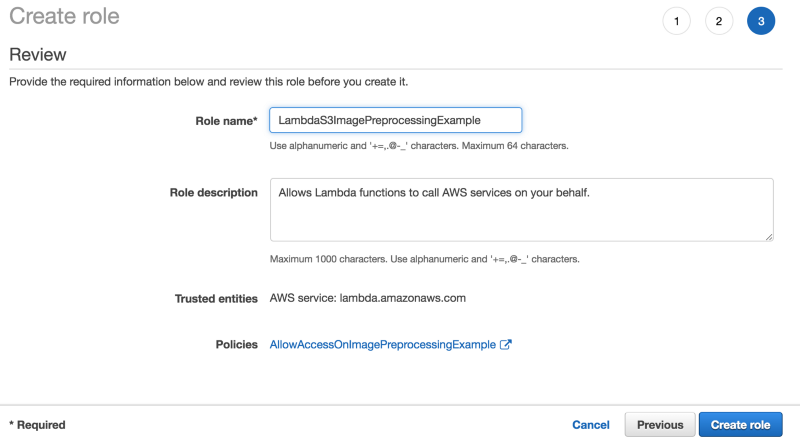 Save Role
Save Role
Step 5: Create the AWS Lambda function
Now we have to setup our Lambda function to consume messages from the “image-preprocessing” SNS Topic and generate our resized image versions.
Let’s start with creating a new Lambda function.
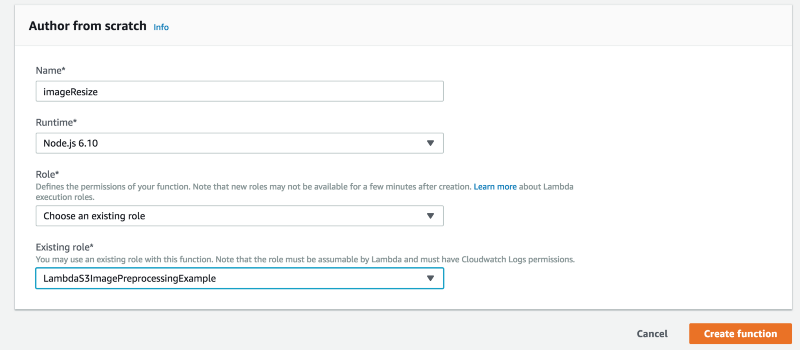
From your AWS console, visit the Lambda page, click on “Create function,” and type in your function name, for example ImageResize, choose your runtime, in this case Node.js 6.10, and the previously created IAM role.
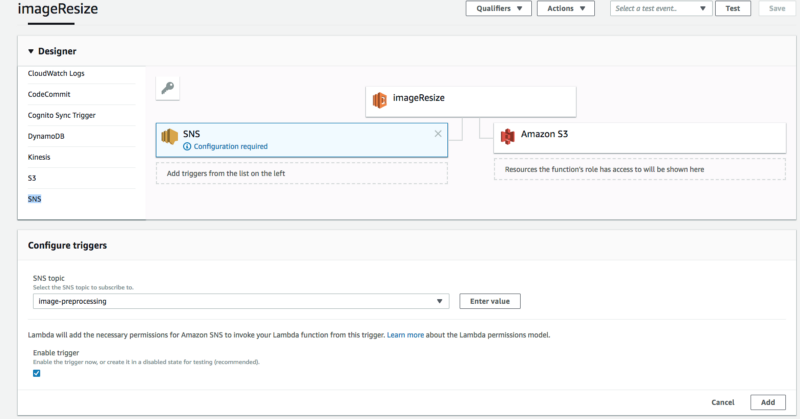
Next we need to add SNS to the function triggers, so that the Lambda function will be called each time a new message is published to the “image-preprocessing” topic.
To do that, click on “SNS” in the list of triggers, select “image-preprocessing” from the SNS topic list, and click “add.”
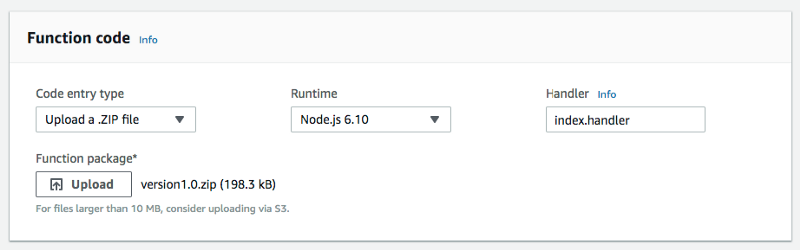
Finally we have to upload our code that will handle the S3 ObjectCreated event. That means fetching the uploaded image from the S3 originals folder, processing it, and uploading it again in the resized image folders.
You can download the code here. The only file you need to upload to your Lambda function is version1.1.zip, which contains index.js and the node_modules folder.
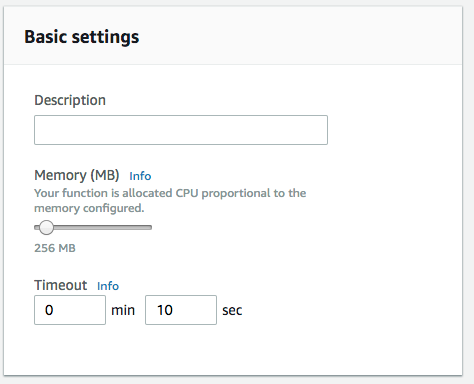
In order to give the Lambda function enough time and memory to process the image, we can increase the memory to 256 MB and the timeout to 10 sec. The needed resources depend on the image size and the transformation complexity.
The code itself is quiet simple, and just has the purpose of demonstrating the AWS integration.
First, a handler function is defined (exports.handler). This function is called by the external trigger, in this case the message published on SNS which contains the S3 object key of the uploaded image.
It first parses the event message JSON to extract the S3 bucket name, the S3 object key of the uploaded image, and the filename that is just the final part of the key.
Once it has the bucket and object key, the uploaded image is fetched using s3.getObject and then passed to the resize function. The SIZE variable holds the image sizes we want to generate, which correspond also to the S3 folder names where the transformed images will be uploaded.
var async = require('async');var AWS = require('aws-sdk');var gm = require('gm').subClass({ imageMagick: true });var s3 = new AWS.S3();
var SIZES = ["800x600", "400x300"];
exports.handler = function(event, context) { var message, srcKey, dstKey, srcBucket, dstBucket, filename; message = JSON.parse(event.Records[0].Sns.Message).Records[0];
srcBucket = message.s3.bucket.name; dstBucket = srcBucket; srcKey = message.s3.object.key.replace(/\+/g, " "); filename = srcKey.split("/")[1]; dstKey = ""; ... ... // Download the image from S3 s3.getObject({ Bucket: srcBucket, Key: srcKey }, function(err, response){ if (err){ var err_message = 'Cannot download image: ' + srcKey; return console.error(err_message); } var contentType = response.ContentType;
// Pass in our image to ImageMagick var original = gm(response.Body);
// Obtain the size of the image original.size(function(err, size){ if(err){ return console.error(err); }
// For each SIZES, call the resize function async.each(SIZES, function (width_height, callback) { var filename = srcKey.split("/")[1]; var thumbDstKey = width_height +"/" + filename; resize(size, width_height, imageType, original, srcKey, dstBucket, thumbDstKey, contentType, callback); }, function (err) { if (err) { var err_message = 'Cannot resize ' + srcKey; console.error(err_message); } context.done(); }); }); });
}
The resize function applies some transformations on the original image using the “gm” library, in particular it resizes the image, crops it if needed, and reduces the quality to 80%. It then uploads the modified image to S3 using “s3.putObject”, specifying “ACL: public-read” to make the new image public.
var resize = function(size, width_height, imageType, original, srcKey, dstBucket, dstKey, contentType, done) {
async.waterfall([ function transform(next) { var width_height_values = width_height.split("x"); var width = width_height_values[0]; var height = width_height_values[1];
// Transform the image buffer in memory original.interlace("Plane") .quality(80) .resize(width, height, '^') .gravity('Center') .crop(width, height) .toBuffer(imageType, function(err, buffer) { if (err) { next(err); } else { next(null, buffer); } }); }, function upload(data, next) { console.log("Uploading data to " + dstKey); s3.putObject({ Bucket: dstBucket, Key: dstKey, Body: data, ContentType: contentType, ACL: 'public-read' }, next); } ], function (err) { if (err) { console.error(err); } done(err); } );};
Step 6: Test
Now we can test that everything is working as expected by uploading an image to the originals folder. If everything was implemented correctly, then we should find a resized version of the uploaded image in the 800x600 folder and one in the 400x300 folder.
In the video below, you can see three windows: on the left the originals folder, in the middle the 800x600 folder, and on the right the 400x300 folder. After uploading a file to the original folder, the other two windows are refreshed to check if the images were created.
And voilà, here they are ;)
(Optional) Step 6: Add Cloudfront CDN
Now that the images are generated and uploaded to S3, we can add Cloudfront CDN to deliver the images to our end users, so that download speed is improved.
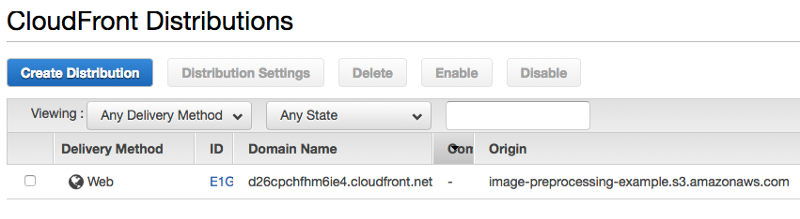
- Open the Cloudfront Page
- Click on “Create Distribution”
- When asked for the delivery method, choose “Web Distribution”
- Choose your S3 bucket as “Origin Domain Name” and click on “Create Distribution”
The process of creating the distribution network is not immediate, so you will have to wait until the status of your CDN changes from “In Prog” to “Deployed.”
Once it is deployed you can use the domain name instead of your S3 bucket URL. For example if your Cloudfront domain name is “1234-cloudfront-id.cloudfront.net”, then you can access your resized image folder by “https://1234-cloudfront-id.cloudfront.net/400x300/FILENAME” and “https://1234-cloudfront-id.cloudfront.net/800x600/FILENAME”
Cloudfront has many other options that should be set, but those are out of the scope of this article. For a more detailed guide to setting up your CDN, take a look at Amazon’s getting started guide.
And that’s it! I hope you enjoyed this article. Please leave a comment below, and let me know what you think!