
By Aayush Joglekar
What is Depth First Search?
Depth first search is a popular graph traversal algorithm. One application of depth first search in real world applications is in site mapping.
A site map is a list of pages of a web site. They are organised in a hierarchical manner and describe the whole structure of a website starting from a root node.
The Algorithm
Site mapping involves loading a root link, parsing the internal links on the page and then recursively applying the same process to those links. This gives us a graph data structure, but for simplicity, we can assume that it's a tree.
The Problem
If we implemented the algorithm that way, loading and parsing HTML pages takes time and blocks the whole traversal process.
Suppose an HTTP response takes an average of 300ms and there are 100 pages on the site to map. 300*100 = 30000ms => 30 seconds. So, the process will remain idle for 300 seconds.
How Can We Improve This?
In the time that a page loads, you can send multiple HTTP requests and parse the received HTML pages if you implement a multi-threaded architecture.
This concurrent method is 7x faster than the one previously mentioned.
Implementing threads may set off the alarm bell in many developers' mind. However, Golang provides you with a beautiful set of concepts like goroutines, channels, and synchronization utilities to make the job much easier.
I talked about site mapping earlier, however, it is much better and simpler if you learn how to program a depth first search algorithm for a binary tree. You can apply what you'll learn in this article to a lot of different things.
Let's get started!
You can find the code used in this article here on GitHub.
Setting Up the Tree
Node Definition
A node struct is the basic building block of your binary tree. It has a data, a left child and right child pointer. To simulate the delay in processing a node, you have to assign a random sleep time in microseconds.
type Node struct {
Data interface{}
Sleep time.Duration
Left *Node
Right *Node
}
Node Generator Function
NewNode() returns a pointer to the a new node. Sleep is assigned a duration of 0-100 microseconds.
func NewNode(data interface{}) *Node {
node := new(Node)
node.Data = data
node.Left = nil
node.Right = nil
rand.Seed(time.Now().UTC().UnixNano())
duration := int64(rand.Intn(100))
node.Sleep = time.Duration(duration) * time.Microsecond
return node
}
Now you've set up your tree and can implement the depth first search and a function to process the node.
Single-Threaded Depth First Search
ProcessNode()
ProcessNode() is a function that will be invoked when the node has to be processed during a traversal.
Normally you would print or store the node's value. However, to show the benefits of goroutines, you'll have to implement a compute intensive task that takes somewhere around 1 second.
During each iteration, the node sleeps for n.Sleep microseconds and prints out Node <data> ✅ once the task completes.
func (n *Node) ProcessNode() {
var hello []int
for i := 0; i < 10000; i++ {
time.Sleep(n.Sleep)
hello = append(hello, i)
}
fmt.Printf("Node %v ✅\n", n.Data)
}
Depth First Search Recursive Function
This is a single-threaded depth first search function implemented via recursion — it might look familiar to those who have written it before.
func (n *Node) DFS() {
if n == nil {
return
}
n.Left.DFS()
n.ProcessNode()
n.Right.DFS()
}
Implementing the main() Function
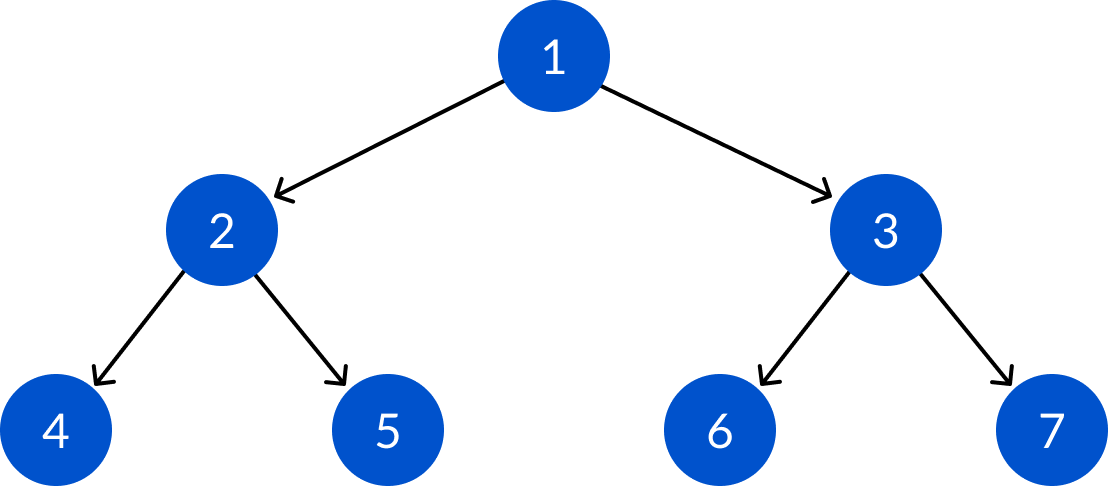
In the main function, create a complete binary tree that consists of 7 nodes.
To see how much time has elapsed, initiate start and then begin the DFS at the root. Once it completes, main() prints out the time that has elapsed.
var wg sync.WaitGroup
func main() {
root := NewNode(1)
root.Left = NewNode(2)
root.Right = NewNode(3)
root.Left.Left = NewNode(4)
root.Left.Right = NewNode(5)
root.Right.Left = NewNode(6)
root.Right.Right = NewNode(7)
start := time.Now()
root.DFS()
fmt.Printf("\nTime elapsed: %v\n\n", time.Since(start))
}
Output
It took 8.75s for the depth first search to complete.
Most of the time, the processor was idle as each node was being processed. It also prevented other nodes from processing while it completed its sleep time.
In the real world, this situation occurs during I/O or external HTTP calls.
Node 4 ✅
Node 2 ✅
Node 5 ✅
Node 1 ✅
Node 6 ✅
Node 3 ✅
Node 7 ✅
Time elapsed: 8.75086767s
Supercharge Your Depth First Search with Goroutines
{kind=link}
Converting the process and depth first search functions involves only minor changes when compared to other programming languages:
- Calling the recursive function with the
gocommand. - Maintaining a
waitGroupwhich keeps track of the in process function so the program doesn't exit without all of them completing.
DFSParallel()
wg.Add(1): Before going into recursion, add the goroutine that will be started to the waitGroup.
You can also run wg.Add(3) and then start the three goroutines and it will do the job. However, this is more aesthetic and clearly denotes what is going to happen.
defer wg.Done(): decreases the waitGroup counter by 1 when the function returns. This conveys that the routine has completed.
go: Starts the function in a new goroutine.
func (n *Node) DFSParallel() {
defer wg.Done()
if n == nil {
return
}
wg.Add(1)
go n.Left.DFSParallel()
wg.Add(1)
go n.ProcessNodeParallel()
wg.Add(1)
go n.Right.DFSParallel()
}
ProcessNodeParallel()
Nothing much to be done here, just add a defer wg.Done() after the function starts. It'll inform waitGroup that this goroutine has finished.
func (n *Node) ProcessNodeParallel() {
defer wg.Done()
var hello []int
for i := 0; i < 10000; i++ {
time.Sleep(n.Sleep)
hello = append(hello, i)
}
fmt.Printf("Node %v ✅\n", n.Data)
}
###
Calling DFSParallel() in main()
GOMAXPROCS tells the Go compiler to run threads on all logical cores available on the computer.
This will help you to process multiple nodes as well. The concurrent design pattern that has been implemented here shows the benefit of having multiple cores on the computer. Not only can the program process other nodes while one is sleeping, but it can also process multiple nodes at the same time.
You can start the DFSParallel() as a goroutine as before and add it to the wait group.
wg.Wait() waits for all goroutines to be completed. It waits for the goroutines count to be 0 and then moves the control forward.
...
// Go will use maximum number of processors available to process goroutines
processors := runtime.GOMAXPROCS(runtime.NumCPU())
fmt.Printf("\nTime elapsed: %v\n\n", time.Since(start))
// Starts the timer
start = time.Now()
// Adds one goroutine the WaitGroup
wg.Add(1)
// Start the DFS Goroutine
go root.DFSParallel()
// Waits for all goroutines to complete
wg.Wait()
fmt.Printf("\nProcessors: %v Time elapsed: %v\n", processors, time.Since(start))
}
Output
Node 7 ✅
Node 4 ✅
Node 2 ✅
Node 6 ✅
Node 5 ✅
Node 1 ✅
Node 3 ✅
Processors: 8 Time elapsed: 1.295332809s
As expected, the depth first search algorithm completes in just 1.3 seconds as opposed to the 8.7 seconds in the previous implementation.
Explanation
Normal Implementation
The functions were running serially in a pre-ordered manner as you would expect. Each function was taking ~1.1 seconds to complete leading to the long run time.
However, each node sleeps for ~1 second as well, during which the processors remain idle as everything is running in one thread.
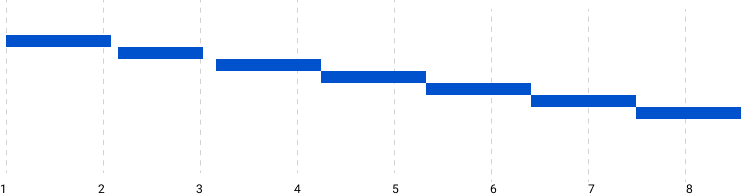 Normal Implementation Time Graph (x-axis in Seconds)
Normal Implementation Time Graph (x-axis in Seconds)
Concurrent Implementation
The functions were running independently and almost every one of them started at roughly ~ 0th second. They ran for 1 second and every thread completed.
However you can see that the order is not the same as the previous implementation. This is because they are running independently and finish at different times. Since they all started at roughly the same time, the traversal completed in roughly the duration of a single function's runtime.
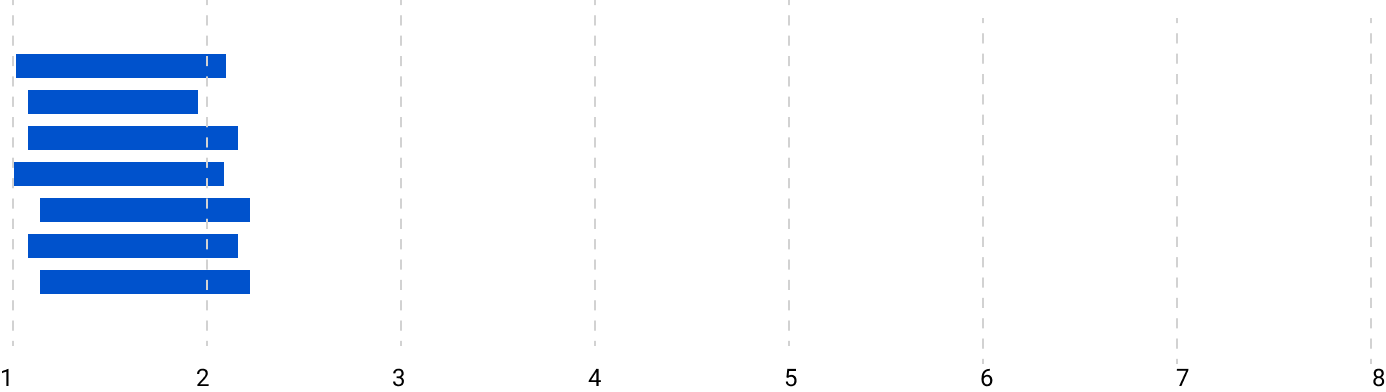 Concurrent Implementation (x-axis in seconds)
Concurrent Implementation (x-axis in seconds)
Conclusion
I found this result to be pretty amazing since it didn't take me more than a few concepts and 5-6 extra lines to make this program 7x faster.
This technique can prove to be a major boost to your Go program if you can identify functions which can run independently at the same time. If your functions require synchronization, you can use channels to achieve that task.
You can find the code used in this article here on GitHub.