

Data science models are all around you.
They could impact your admission to a school, whether you get hired (or fired), your work schedule, whom you date, whether you get a loan, what ads are shown to you, what social media posts you see, and so on.
I have created a talk discussing the ethics behind data science, from data acquisition to modeling and algorithms.
In this course, I discuss what could go wrong from a moral standpoint, what has gone wrong in the past, and what guidelines the computer science community has created to combat unethical conduct.
This content is adapted from OpenDS4All. OpenDS4All is a project created to accelerate the creation of data science curricula at academic institutions.
OpenDS4All attempts to provide a combination of lectures, recitation or flipped classroom activities, and hands-on assignments to deliver data science and data engineering education.
Now, let's explore into how ethics plays a role in modern day data acquisition and algorithms.
For a deep dive into the ethics of data science, you can watch the talk here. If you want to briefly learn more about ethics in data science and understand what the talk is about, read on.
Why Should We Care About Ethics in Tech?
"With great power comes great responsibility". Ah, the Peter Parker principle. Data science has so much influence now over peoples' lives. A good data scientist needs to understand the ethical issues surrounding the data they obtain or use, the algorithms they employ, and its impact on people.
People do the right thing for a few different reasons. Ethics comes into play here. Ethics are rules that we all voluntarily follow because it makes the world a better place for all of us.
However, sometimes it's not clear in the moment what the right thing even is. Sometimes, it's only evident in retrospect. However, these experiences and consequences are what shape our understanding and expectations for the future.
Ethics and Data
Data is constantly being collected about us. Cameras are everywhere. Cell phones report locations. Social media follows our clicks.
Informed Consent
In human subject research, there is a notion of informed consent. We understand what is being done, we voluntarily consent to the experiment, and we have the right to withdraw consent at any time.
However, this is more vague in "ordinary conduct of business", such as A/B testing. For example, Facebook may perform these tests all the time without explicit consent or even knowledge!
In the video, I discuss a mood manipulation experiment done by Facebook in 2012 and a "Love Is Blind" experiment done by OKCupid in 2015.
Informed consent is often buried in the fine print and many of us do not necessarily read those lengthy terms and conditions. In addition, it is hard to control how data is used in the future and how it is controlled.
Furthermore, big data sets are sometimes very vague about how they are protected. For example, Wikipedia, Yelp, Rotten Tomatoes, a clinical data set, a company's data, your gene sequence...
Privacy
There is also a concern over privacy. Privacy is a basic human need. Loss of privacy occurs when there's a loss of control over personal data. In the video, I discuss a 2016 OKCupid controversy where user profile data was released.
In some cases, even when identifiable information is removed from data – like name, phone number, address, and so on – it may not be sufficient to protect individuals' identities.
There have been many cases of de-anonymization, where AOL users are identified based on search history, or peoples' health records are identified based on ZIP code, birth date, and sex.
From these concerns over safety of released data, the concept of "differential privacy" has come into play. Essentially, the goal is to provide as much statistical information as possible while guaranteeing the anonymity of the contributing individual.
Ethics and Algorithms
An algorithm cannot be neutral. An algorithm naturally encodes biases that we feed it. For example, our training data might not represent the entire population. The past population may not represent the future population.
It's possible to get "bad" results from "good" data.
Common Algorithm Mishaps
There may be correlated attributes that get in the way. In the video, I discuss an example of one time when Staples was attempting to beat their competitors, but ended up offering cheaper deals to wealthier neighborhoods.
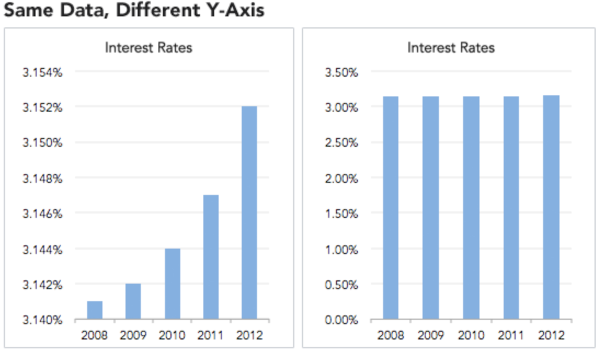
In addition, results can sometimes be presented in a misleading fashion. In the example below, we can see how the same data with different y-axes can lead to different conclusions:
It's also possible to p-hack to find patterns in data that can be presented as statistically significant. But in reality, you may have just done many statistical tests on many experiments and only reported the ones with significant results.
If you do infinitely many experiments, there is bound to be one that comes back with significant results just by chance.
FAT* – Fairness, Accountability, Transparency
In the computer science community, one important research area that has emerged is FAT* (Fairness, Accountability, Transparency). This involves determining fair decisions according to our notions of social justice, ethical use of data, and interpretable decisions from machine learning.
Here is a good resource for learning more about this in depth.
Fairness is a trendy topic in theoretical computer science right now. There are two types of discrimination that may occur: discrimination of an individual and discrimination in aggregate outcome.
Discrimination of an individual may occur when an individual from the target group gets treated differently from an otherwise identical individual not from the target group.
Discrimination in aggregate outcome may occur when the percentage success of the target group may differ compared to that of the general population.
Here is a great resource for further discussion.
In the video, I discuss the controversial role of algorithms in sentencing and parole. These algorithms seem to show racial disparities in favor of white defendants and in opposition to black defendants.

In addition to being fair, we also want our algorithms to be reproducible. In general, "transparency" means full transparency. The entire pipeline of data collection, raw data, and research analyses should be made available, thus contributing to potential reproducibility.
However, sometimes the data cannot be shared, and algorithms may be fairly complex and difficult to understand, especially if they are black box algorithms.
To help with this issue, the "FAIR" principles – findable, accessible, interoperable, reusable – have been proposed. Check out this article to find out more.
Want to Learn More?
In summary, codes of conduct for research are fairly well understood. In general, experiments want to obtain informed consent, protect the privacy of subjects, and maintain the confidentiality of data collected while minimizing harm.
Conversely, the concept of what is fair is slightly more subtle. Sometimes it is not necessarily clear what exactly is fair treatment of a group from a quantitative standpoint.
There may be a trade-off between optimizing outcomes and avoiding discrimination against a group. However, the computer science community has been actively setting up guidelines to help protect individuals, data, and models.
Want to learn more? Watch the talk to dive into the nuances of ethics in data science!
Thank you OpenDS4All!