
By Sanny Kim
From Self-Driving Cars to Alpha Go to Language Translation, Deep Learning seems to be everywhere nowadays. While the debate whether the hype is justified or not continues, Deep Learning has seen a rapid surge of interest across academia and industry over the past years.
With so much attention on the topic, more and more information has been recently published, from various MOOCs to books to YouTube Channels. With such a vast amount of resources at hand, there has never been a better time to learn Deep Learning.
Yet a side effect of such an influx of readily available material is choice overload. With thousands and thousands of resources, which are the ones worth looking at?
Inspired by Haseeb Qureshi’s excellent Guide on Learning Blockchain Development, this is my try to share the resources that I have found throughout my journey. As I am planning on continuously updating this guide (via this GitHub Repo) with updated and better information, I deemed this work in progress an incomplete guide.
As of now, all the resources in this guide are all free thanks to their authors.
Target Audience
- Anybody who wants to dive deeper into the topic, seeks a career in this field, or aspires to gain a theoretical understanding of Deep Learning
Goals of this Article
- Give an overview and a sense of direction within the ocean of resources
- Give a clear and useful path towards learning Deep Learning Theory and Development
- Give some practical tips along the way on how to maximize your learning experience
Outline
This guide is structured in the following way:
- Phase 1: Prerequisites
- Phase 2: Deep Learning Fundamentals
- Phase 3: Create Something
- Phase 4: Dive Deeper
- Phase X: Keep Learning
How long your learning will take depends on numerous factors, such as your dedication, background and time-commitment. And depending on your background and the things you want to learn, feel free to skip to any part of this guide. The linear progression I outline below is just the path I found to be useful for myself.
Phase 1: Pre-Requisites
Let me be clear from the beginning. The prerequisites you need depend on the objectives you intend to pursue. The foundations you need to conduct research in Deep Learning will differ from the things you need to become a Practitioner (both are, of course, not mutually exclusive).
Whether you don’t have any knowledge of coding yet or you are already an expert in R, I would still recommend acquiring a working knowledge of Python as most of the resources on Deep Learning out there will require you to know Python.
Coding
While Codecademy is a great way to start coding from the beginning, MIT’s 6.0001 lectures are an incredible introduction to the world of computer science. So is CS50, Harvard’s infamous CS intro course, but CS50 has less of a focus on Python. For people who prefer reading, the interactive online book How To Think Like A Computer Scientist is the way to go.
Math
If you simply want to apply Deep Learning techniques to a problem you face or gain a high-level understanding of Deep Learning, it is in most cases not necessary to know its mathematical underpinnings. But, in my experience, it has been significantly easier to understand and even more rewarding to use Deep Learning frameworks after getting familiar with its theoretical foundations.
For such intentions, the basics of Calculus, Linear Algebra and Statistics are extremely useful. Fortunately, there are plenty of great Math resources online.
Here are the most important concepts you should know:
Multivariable Calculus
Differentiation
- Chain Rule
Partial Derivatives
Linear Algebra
Definition of Vectors & Matrices
Matrix Operations and Transformations: Addition, Subtraction, Multiplication, Transpose, Inverse
Statistics & Probability
Basic ideas like mean and standard deviation
- Distributions
- Sampling
- Bayes Theorem
That being said, it is also possible to learn these concepts concurrently with Phase 2, looking up the Math whenever you need it.
If you want to dive right into the Matrix Calculus that is used in Deep Learning, take a look at The Matrix Calculus You Need For Deep Learning by Terence Parr and Jeremy Howard.
Calculus
For Calculus, I would choose between the MIT OCW Lectures, Prof. Leonard’s Lectures, and Khan Academy.
The MIT Lectures are great for people who are comfortable with Math and seek a fast-paced yet rigorous introduction to Calculus.
Prof. Leonard Lectures are perfect for anybody who is not too familiar with Math, as he takes the time to explain everything in a very understandable manner.
Lastly, I would recommend Khan Academy for people who just need a refresher or want to get an overview as fast as possible.
Linear Algebra
For Linear Algebra, I really enjoyed Professor Strang’s Lecture Series and its accompanying book on Linear Algebra (MIT OCW). If you are interested in spending more time on Linear Algebra, I would recommend the MIT lectures, but if you just want to learn the basics quickly or get a refresher, Khan Academy is perfect for that.
For a more hands-on coding approach, check out Rachel Thomas’ (from fast.ai) Computational Linear Algebra Course.
At last, this review from Stanford’s CS229 course offers a nice reference you can always come back to.
For both Calculus and Linear Algebra, 3Blue1Brown’s Essence of Calculus and Linear Algebra series are beautiful complementary materials to gain a more intuitive and visual understanding of the subject.
Statistics and Probability
Harvard has all its Stats 110 lectures, which is taught by Prof. Joe Blitzstein, on YouTube. It starts off with Probability and covers a wide range of Intro to Statistics topics. The practice problems and content can be challenging at times, but it is one of the most interesting courses out there.
Beyond Harvard’s course, Khan Academy and Brandon Foltz also have some high-quality material on YouTube.
Similarly to Linear Algebra, Stanford’s CS229 course also offers a nice review of Probability Theory that you can use as a point of reference.
Phase 2: Deep Learning Fundamentals

With the plethora of free deep learning resources online, the paradox of choice becomes particularly apparent. Which ones should I choose, which ones are the right fit for me, where can I learn the most?
MOOCs
Just as important as learning theory is practicing your newfound knowledge, which is why my favorite choice of MOOCs would be a mix of Andrew Ng’s deeplearning.ai (more theoretical) and Jeremy Howard’s and Rachel Thomas’ fast.ai (more practical).
Andrew Ng is excellent at explaining the basic theory behind Deep Learning, while fast.ai is a lot more focused on hands-on coding. With the theoretical foundations of deeplearning.ai, Jeremy Howard’s code and explanations become a lot more intuitive, while the coding part of fast.ai is super helpful to ingrain your theoretical knowledge into practical understanding.
Since deeplearning.ai consists of five courses and fast.ai consists of two parts, I would structure my learning in the following way:
- Watch Deep Learning.ai’s Course Lectures I, II, IV and V
- Take Fast.ai Part I
- Watch Deeplearning.ai Course III
- Optional: Take deeplearning.ai assignments
- Repeat Steps 1–4 or Go to Phase III
The reason I would first skip the deeplearning.ai assignments is that I found fast.ai’s coding examples and assignments to be a lot more practical than the deeplearning.ai assignments.
If you want to reiterate the deeplearning.ai course material (i.e. repetition to strengthen your memory), then give the assignments a try. Unlike fast.ai, which uses PyTorch and its own fastai library, they primarily use Keras. So, it’s a good opportunity to get familiar with another Deep Learning Framework.
Fast.ai Part 2 deals with quite advanced topics and requires a good grasp of theory as well as the coding aspects of Deep Learning, which is why I would put that one in Phase IV of this guide.
Tip: You can freely watch deeplearning.ai videos on Coursera, but you need to purchase the specialization to do the assignments. If you can’t afford the coursera specialization fee, apply for a scholarship!
For people who prefer reading books, Michael Nielsen published a free Intro book on Deep Learning that also incorporates coding examples in Python.
To really take advantage of fast.ai, you will need a GPU. But lucky us, Google offers an environment similar to Jupyter Notebooks called Google Colaboratory that comes with free GPU access. Somebody already made a tutorial on how to use Colab for Fast.ai. So, check that out here. Kaggle has also started providing access to a free Nvidia K80 GPU on their Kernels.
 Google Colaboratory
Google Colaboratory
AWS also provides students with up to $100 in credits (depending on whether your college is part of their program), which you can use for their GPU instances.
Complementary Non-Mooc Material
Do not solely rely on one means of information. I recommend that you combine watching videos with coding and reading.
YouTube
Just like in his series on Calculus and Linear Algebra, 3Blue1Brown gives one of the most intuitive explanations on Neural Networks. Computer Phile and Brandon also offer great explanations of Deep Learning, each from a slightly different perspective. Lastly, sentdex can be helpful as he instantly puts concepts into code.
- 3Blue1Brown Neural Networks
- Computer Phile Neural Networks
- Brandon Rohrer Neural Networks
- Practical Machine Learning sentdex
Beginner-Friendly Blogs
Blogs are also a phenomenal way of reiterating over newly acquired knowledge, exploring new ideas or going in-depth into a topic.
Distill.pub is one of the best blogs I know in the Deep Learning space and beyond. The way its editors approach topics like Feature Visualization or Momentum is simply clear, dynamic and engaging.
Although not updated anymore, Andrej Karpathy’s old Blog has some classic articles on things such as RNNs that are worth checking out.
Finally, Medium Publications like FreeCodeCamp and Towards Data Science regularly publish interesting posts from Reinforcement Learning to Objection Detection.
Coding
Get familiar with code! Knowing how to graph plots, deal with messy data and do scientific computing is crucial in Deep Learning, which is why libraries such as Numpy or Matplotlib are ubiquitously used. So, practicing and using these tools will definitely help you along the way.
Jupyter Notebook
Jupyter Notebooks can be a great tool but definitely carry some drawbacks. Take a look at Joel Grus’ informative and meme-filled presentation I don’t Like Notebooks to be aware of those pitfalls.
Numpy
Pandas
- Data School Comprehensive Tutorial Series on Data Analysis Pandas
- Code Basics Short Tutorial Series on Pandas
Scikit-learn
Matplotlib
And if you ever get stuck with a concept or code snippet, google it! The quality of the answers will be highly variable, but sites such as Quora, Stackoverflow or PyTorch’s excellent Forum are certainly sources you can leverage. Reddit can sometimes offer nice explanations as well, in formats such as ELI5 (Explain Me Like I’m Five) when you’re completely perplexed by a new topic.
Phase 3: Create Something

While you should definitely play around with code and use it with external datasets/problems while taking the fast.ai course, I think it’s crucial to implement your own project as well. The deeplearning.ai course III is an excellent guide on how to structure and execute a Machine Learning Project.
Brainstorm Ideas
Start with brainstorming ideas that seem feasible to you with the knowledge you just acquired, look at openly available datasets and think about problems you might want to solve with Deep Learning. Take a look at these Projects to get some inspiration!
Or Use Kaggle
Otherwise, an easy way to start with a project is participating in a Kaggle competition (current or past) or exploring their vast amount of open datasets.
Kaggle offers an excellent gateway into the ML community. People share Kernels (their walkthrough of a given problem) and actively discuss ideas, which you can learn from. It becomes especially interesting after the end of a competition, when teams start to post their solutions in the Discussion Forums, which often involves creative approaches to the competition.
Choose a framework
Whatever Deep Learning Framework you feel most comfortable, choose one! I would go for either PyTorch or Keras, as they are both relatively easy to pick up and have a very active community.
Reflect
After completing your project, take a day or so to reflect on what you have achieved, what you have learned and what you could improve upon in the future. This is also the perfect time to write your first blog post! It’s one thing to think that you understand something and another to convey it to other people.
Quincy Larson, the founder of FreeCodeCamp, gave a really helpful presentation on how to write a technical blog post here.
Phase 4: Dive Deeper
 _Fun Fact: The authors of the original Inception Network used this meme in their official paper as a source of inspiration! | [Image Source](https://knowyourmeme.com/memes/we-need-to-go-deeper" rel="noopener" target="blank" title=")
_Fun Fact: The authors of the original Inception Network used this meme in their official paper as a source of inspiration! | [Image Source](https://knowyourmeme.com/memes/we-need-to-go-deeper" rel="noopener" target="blank" title=")
Now that you’ve built some fundamental Deep Learning knowledge and have gone through your first Practical Experience, it’s time to go deeper!
From here on, there are tons of things you can do. But the first thing I would do is go through Fast.ai Part 2 Cutting Edge Deep Learning For Coders. As the name suggests, you’ll learn some of the cutting edge stuff in Deep Learning: from GANs to Neural Translation to Super Resolution! The course will give you an overview of some of the hottest topics in Deep Learning right now with a strong focus on Computer Vision and Natural Language Processing (NLP). I particularly appreciate the course as Jeremy Howard not only gives very clear explanations but also really goes into the code that is needed to enable these ideas.
After fast.ai, here are some of the things you can do:
- Take a deep dive into one topic such as Computer Vision, NLP or Reinforcement Learning
- Read papers and/or reimplement ideas from a paper
- Do more projects and/or gain work experience in Deep Learning
- Follow blogs, listen to podcasts and stay up to date
Deep Dives
Computer Vision
The best place to continue your Computer Vision path is definitely Stanford’s CS231n Course, also called Convolutional Neural Networks for Visual Recognition. They not only have all their lecture videos online, but their website also offers course notes and assignments! Fast.ai Part 2 and deeplearning.ai will give you a good foundation for the course, as CS231n will go a a lot further in terms of the theory behind CNNs and related topics.
While both versions cover mostly the same topics, which also means choose whichever version’s teaching style you like better, the final lectures differ slightly. For example, 2017 incorporates a Lecture on Generative Models and 2016 has a guest lecture by Jeff Dean on Deep Learning at Google. If you want to see how Computer Vision was before Deep Learning took off, the University of Central Florida (UCF) has a Computer Vision course from 2012 teaching about concepts such as SIFT features.
Natural Language Processing
Stanford has quite an extensive course called CS224n Natural Language Processing with Deep Learning, which similarly to CS231n not only uploaded its lecture videos but also hosts a handy website with lecture slides, assignments, assignment solutions and even students’ Class Projects!
Oxford also has a very nice lecture series on NLP in cooperation with DeepMind. While it does have a helpful GitHub repository with slides and pointers to further readings, it lacks the assignment part of Stanford’s CS224. The courses overlap to some extent, but not to the extent that it’s not worth looking at both courses.
General Deep Learning
For people who are still unsure about what in Deep Learning excites them the most, Carnegie Mellon University (CMU) has a course on Topics in Deep Learning, which introduces a broad range of topics from Restricted Boltzmann Machines to Deep Reinforcement Learning. Oxford also has a Deep Learning Course, which can give you a firmer mathematical grasp of concepts you learned in deeplearning.ai and fast.ai, meaning things such as Regularization or Optimization.
A book that could help you in any Deep Learning field is The Deep Learning Book by Ian Goodfellow et al., which is the most comprehensive book on Deep Learning theory I know of. Classes such as Oxford’s NLP course also use this book as complementary material.
Noteworthy as well is that top-tier research conferences such as NIPS or ICML, which disseminate the state-of-the-art Deep Learning papers, regularly publish their keynote and tutorial videos.
- CMU Topics in Deep Learning Course (2017)
- Oxford Deep Learning Course (2015)
- Deep Learning Book by Ian Goodfellow et al.
- NIPS (2017), ICML (2017), ICLR (2018) Conference Videos
Reinforcement Learning
As Reinforcement Learning (RL) is neither covered by deeplearning.ai nor fast.ai, I would first watch Arxiv Insight’s Intro to RL and Jacob Schrum’s RL videos, which are extremely understandable explanations of the topic. Then head to Andrej Karpathy’s blog post on Deep Reinforcement Learning and read Chapter 1–2 of Andrew Ng’s PhD Thesis (as suggested by Berkeley’s CS 294 website) to get a primer on Markov Decision Processes. Afterward, David Silver’s (Deep Mind) Course on RL will give you a strong foundation to transition to Berkeley’s CS294 Course on Deep RL.
Alternatively, there are recorded sessions of a Deep RL Bootcamp at Berkeley and an RL Summer School at the Montreal Institute for Learning Algorithms with speakers like Pieter Abbeel and Richard Sutton. The latter also co-authored an introductory textbook on RL, which currently can be accessed openly in its 2nd edition as a draft (chapter 3 & 4 are pre-readings for CS294).
Additionally, Udacity has a fabulous GitHub repo with tutorials, projects and a cheatsheet from their paid Deep RL course. Another resource that was published recently is Thomas Simonini’s ongoing Deep RL course that is very easy to follow and hands-on in its coding methodology.
- Arxiv Insight’s Intro To RL Video
- Jacob Schrum’s Intro To RL
- Andrej Karpathy’s Blog Post on Deep Reinforcement Learning
- Chapter 1–2 of Andrew Ng’s PhD Thesis on Markov Decision Processes
- David Silver’s Course on Reinforcement Learning
- Berkeley CS294 Deep Reinforcement Learning Course(2017)
- Berkeley CS294 Deep Reinforcement Learning (2018, ongoing session)
- Reinforcement Learning: An Introduction (Book Draft, 2018)
- Berkeley Deep RL Bootcamp (2017)
- MILA Reinforcement Learning Summer School (2017)
- Udacity Deep RL GitHub Repo
- Thomas Simonini’s Deep RL Course
Machine Learning (that is not necessarily Deep Learning)
There is certainly value to knowing various Machine Learning ideas that came before Deep Learning. Whether Logistic Regression or Anomaly Detection, Andrew Ng’s classic Machine Learning Course is a great starting point. If you want a more mathematically rigorous course, Caltech has a superb MOOC that is more theoretically grounded. Professor Ng is also writing a book with ML best practices, for which you can access the first chapters of his draft.
- Andrew Ng’s Machine Learning course (2012)
- Caltech CS156 Machine Learning course (2012)
- Machine Learning Yearning Book by Andrew Ng
Self-Driving Cars
Self-Driving Cars are one of the most interesting areas of application for Deep Learning. So, it’s quite amazing that MIT offers its own course on that topic. The course will give you a breadth of introductions to topics such as perception and motion planning as well as provide you with insights from industry experts such as the Co-Founder of Aurora.
If you’re further interested in the Computer Vision part of Autonomous Driving, a few researchers from ETH Zurich and the Max Planck Institute for Intelligent Systems have written an extensive survey on the subject matter. Moreover, ICCV uploaded the slides from an 8-Part Tutorial Series, which have some useful information on Sensor Fusion and Localization.
Regarding projects I would take a look at projects from Udacity’s paid Self-Driving Car Nanodegree, which you can freely find on GitHub. Udacity does consistently offer scholarships. For instance, last year in cooperation with Lyft for its Self-Driving Cars Intro Course. So, be on the lookout for that as well!
- MIT Self-Driving Cars Course (2018)
- Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art (2017)
- ICCV Tutorial on Computer Vision for Autonomous Driving (2015)
- Udacity Self-Driving Car Project Ideas
Strengthen your understanding of Fundamental Concepts
You will keep encountering fundamental concepts such as Losses, Regularizations, Optimizers, Activation Functions and Gradient Descent, so gaining an Intuition for them is crucial. Two posts that expound Gradient Descent and Backpropagation very well:
Read Papers
While Arxiv is of paramount importance in the fast and open dissemination of Deep Learning research ideas, it can get overwhelming very quickly with the influx of papers on the platform.
For that reason, Andrej Karpathy built Arxiv Sanity, a tool that lets you filter and track papers according to your preferences.
Here are just a few seminal papers from recent years, starting with the ImageNet Papers (AlexNet, VGG, InceptionNet, ResNet) that have had a tremendous influence on the trajectory of Deep Learning.
- AlexNet (2012), VGG (2014), InceptionNet (2014), ResNet (2015)
- Generative Adversarial Networks (2014)
- Yolo Object Detection Paper (2015)
- Playing Atari with Deep Reinforcement Learning (2013)
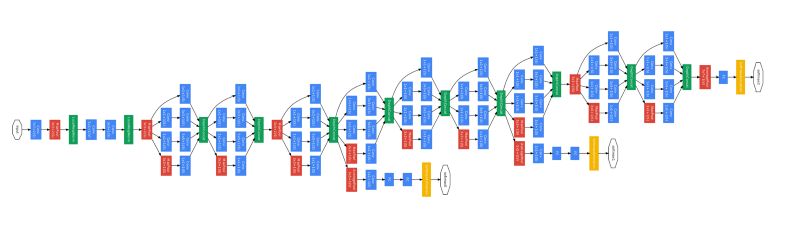 _Original InceptionNet Architecture | [Image Source](http://joelouismarino.github.io/images/blog_images/blog_googlenet_keras/googlenet_diagram.png" rel="noopener" target="blank" title=")
_Original InceptionNet Architecture | [Image Source](http://joelouismarino.github.io/images/blog_images/blog_googlenet_keras/googlenet_diagram.png" rel="noopener" target="blank" title=")
YouTube Channels
Arxiv Insights, CodeEmperium and Yannic Kilcher are the most under-appreciated YouTube Channels on Deep Learning with some of the clearest explanations on Autoencoders and Attention.
Another YouTube Channel that should be mentioned is Lex Fridman, who is the main instructor MIT’s Self-Driving Course. He also taught MIT’s course on Artificial General Intelligence, which has some fascinating lectures on Meta-Learning, Consciousness and Intelligence.
And finally, no such YouTube list could leave out Siraj Rival. Some hate him, some love him. It really depends on what you prefer and what you want to get out of such videos. For me, I’m not that compatible with his way of teaching, but I do appreciate the variety of content he publishes and the entertainment value he provides.
Podcasts
Podcasts are quite a nice way to hear from various people on a diverse range of topics. Two of my favorite podcasts, which produce a lot of Deep Learning related content, are Talking Machines and This Week in ML & AI (TWiML&AI). For example, listen to Talking Machine’s recent podcast at ICML 2018 or TWiML’s podcast with OpenAI Five’s Christy Dennison!
OpenAI Five with Christy Dennison - TWiML Talk #176
_Today we're joined by Christy Dennison, Machine Learning Engineer at OpenAI. Since joining OpenAI earlier this year…_twimlai.com
Blogs
As mentioned previously, I am a huge fan of Distill.pub, and one of its Editors, Chris Olah, has some other high-quality posts on his personal blog as well.
Another really promising blog is The Gradient, which provides well-written and clear overviews of the newest research findings as well as perspectives on the future of the field. Sebastian Ruder is one of the contributing authors of The Gradient and, like Chris Olah, his blog has some awesome content as well, in particular for NLP-related topics. The last blog is not really a blog, but rather a hub for study plans to specific papers such as AlphaGo Zero or InfoGans.
For each of these topics, Depth First Learning publishes curriculums that allow you to learn the ideas of the papers at their cores.
Requests for Research
In case you want to get started with your own research, here are some pointers to topics other people have requested for research.
Stay Up to Date
Believe it or not, but one of the best ways to stay updated on the progress of Deep Learning is Twitter. Tons of researchers use the platform to share their publications, discuss ideas and interact with the community.
Some of the people worth following on Twitter:
Phase X: Keep Learning
The field is changing rapidly, so keep learning and enjoy the ride.
GitHub Repo
Since the above guide is a snapshot of the resources I like at the moment, it will surely change and evolve over the next years. So, to update this guide in the future with better information and more feedback from others, I created this GitHub Repo, which I will try to maintain regularly.
Feel free to contribute to the guide and send pull requests!