
By Daniel Bourke
I’m working through my own self-created Artificial Intelligence Master’s Degree. The creations which come out of DeepMind fascinate me. When they drop a mixtape with one of the biggest names in gaming in order to push Artificial Intelligence (AI) research forward, I listen to it.
Before we get into the specifics of this collaboration, a quick backstory of the history of AI and gaming.
AlphaGo shocked the world of Go by introducing moves which went against hundreds of years of game-playing strategy while defeating several world champions. DeepBlue did the same for chess in 1997, defeating then world champion Gary Kasparov.
A computer beat a world champion at chess in 1997, why did it take until 2016 to conquer the game of Go? And why StarCraft II now?
Let me shed a little light on the situation.
After 4 moves (2 moves for white and 2 moves for black) in chess, the number of possible board combinations is 8,902. In total, there are more possible board combinations than there are electrons in the observable universe. But the total number of sensible moves (such as, not needlessly sacrificing a Queen to a pawn) in chess is a little lower, in the order of ten duodecillion or 10 followed by 40 zeros.
40,000,000,000,000,000,000,000,000,000,000,000,000,000
For 1997’s fastest supercomputer to calculate the exact winning set of moves for every possible chess board layout (end game) would take, the sun would’ve engulfed Earth several times over. Obviously, a brute force approach like this wasn’t feasible.
How did Deep Blue do it?
Deep Blue used a selective system which would assess the state of the board before choosing a certain sequence of moves to explore. Moves which didn’t maximize the probability of success were eliminated.
This selection strategy combined with parallel processing allowed Deep Blue to calculate 60 billion possible moves within three minutes, the time allowed for each player’s move in classical chess.
This kind of power led Kasparov to accuse IBM of cheating after his dethroning.
Why did Go take almost another two decades to conquer?
Without rules, let’s compare the two game boards. As you can you see, the chess board looks fancy with its colored squares but the Go board has five times more squares.

Remember how there was 8,902 possible moves after the first four moves in chess? Go has 46,655,640 possibles moves after the first three moves. The number of legal Go positions on a 19x19 board has been calculated to be:
208,168,199,381,979,984,699,478,633,344,862,770,286,522,453,884,530,548,425,639,456,820,927,419,612,738,015,378,525,648,451,698,519,643,907,259,916,015,628,128,546,089,888,314,427,129,715,319,317,557,736,620,397,247,064,840,935.
Okay, really big numbers, computing power has increased a bunch since 1997, Go must be easy to take on.
Not entirely.
Go becomes more complex when you consider the goal of incremental influence of the board and capturing an undefined amount of territory rather than trying to capture another players king.
Even with the full power of Moore’s law, brute force wasn’t an option for conquering Go.
How did AlphaGo do it?
A combination of three techniques: advanced tree search, deep neural networks and reinforcement learning.
Tree search is a popular technique used in AI to find the optimal path to a goal. Imagine you’re at the top of a Christmas tree and your goal is find a blue ornament a few branches down, however, you have no idea which branch it’s on. In order to find the ornament, you have to search branches of the tree.
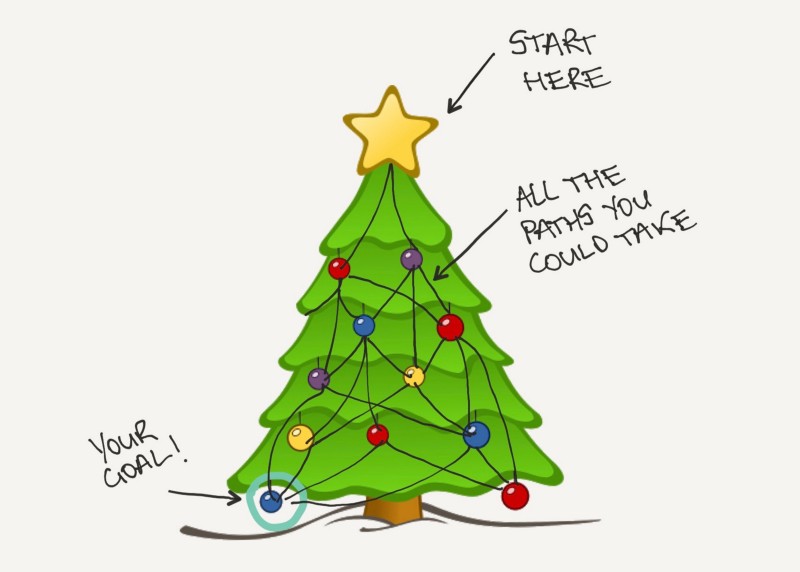
Deep neural networks involve taking a large input data source and performing several mathematical transformations on it. This results in an output data source which is smaller but still within the same probability distribution as the input data.
For example, say you have 1 million examples of how you went about finding the blue ornament in the past, this would be your input data source. The output may be a set of the best and most efficient patterns to find the blue ornament.

For AlphaGo, replace the top of the Christmas tree with your current position on a Go board, the branches are your different move options and the blue ornament is the optimal next move to take.
If you’ve ever given your dog a treat for sitting on command, you’ve practiced a form of reinforcement learning. In the beginning, AlphaGo was was shown millions of examples of how humans play Go so it could establish a foundation level of play. When AlphaGo was training to play, it was rewarded for making good moves.
Combining these techniques and plenty of compute power leads to a very good Go player, the best in the world.
Go is conquered, what’s next?
StarCraft II is a real-time strategy game. Players build armies to go head to head in hopes of taking over the battlefield. But don’t let the simplicity of this description fool you.
If you thought Go was a step up from Chess, StarCraft II turns it up to 11.
Why is StarCraft II such a big step?
To start with, armies can contain a variety of different characters and the game interface is in color. Chess and Go only have two characters and colors, black and white.
The battlefield isn’t entirely visible, portions of the map are hidden unless a player has explored that territory. Imagine trying to plan a move in Chess if you can only see your side of the board.
Delayed credit assignment — some moves aren’t rewarded until later in the game. Chess and Go both have this but nowhere near the level of StarCraft II.
Opponents can be one or many. Chess and Go are both played one on one. Imagine trying to take on three people at once in Chess, except all three have a different rule set to you. This is the equivalent of taking on different armies in StarCraft II.
These factors make StarCraft II a worthy endeavour indeed. But what’s the point?
Why create intelligent systems to play games?
DeepMind’s goal is to solve intelligence and use it to make the world a better place. Creating systems which can learn to solve complex problems is a fundamental step towards completing this goal.
Enter games.
Games are very repeatable states. This means I can play the same game you’re playing and we can both understand what it takes to win and what it means to be a good player. They are also becoming increasingly complex as game development improves alongside technology.
Even with increasingly complex game development, one fundamental aspect of games will always remain, the requirement to solve problems.
A game provides a rich opportunity for repeatable problem-solving. Go was considered a challenge because of the big numbers you saw above. What these big numbers don’t convey is that all of them are solutions to problems.
Systems which learn to play games might seem like a waste of time. But these systems aren’t playing games, they’re learning to solve problems.
Creating intelligent systems which learn to play games such as Go and StarCraft II is a crucial step towards creating systems which are adaptable in the ultimate game, real life.
The outside world is far more complex than any game but it is still comprised of a series of problem-solving. Each day you wake up, you have to solve the problem of how you’re going to get to the bathroom, solve the problem of deciding what to have for breakfast. We’ve gotten used to these things because we’ve done them thousands of times. When we face a problem we haven’t solved before, the difficulty is increased.
Once an intelligent system learns to solve a problem over and over again, it slowly loses its image of being intelligent. This is becoming the case for AlphaGo.
Humans have the capability to transfer their problem solving abilities from one domain to another. So far, intelligent systems fall down in this area.
We know AlphaGo can play Go better than any other human, but can it learn to ride a bike? A human can easily go from playing Go to riding a bike. AlphaGo cannot.
In order to achieve this ability of transfer learning or what some may refer to as Artificial General Intelligence (AGI), intelligent systems must learn to solve new and more complex problems.
Enter the StarCraft II Learning Environment (SC2LE).
DeepMind, in collaboration with Blizzard (the makers of StarCraft II), has released SC2LE with the goal of catalyzing AI research in a game not specifically designed for this purpose.
You can imagine SC2LE as a gym where intelligent systems can go and train in the hopes of being able to defeat a professional human player.
Tools one can find in SC2LE include a Machine Learning API developed by Blizzard to allows researchers to dig deeper into the game mechanics, an initial dataset of 60,000+ game replays, and PySC2, an open source Python library created by DeepMind to take advantage of Blizzard’s feature-layer API.
A joint paper from Blizzard and DeepMind showed some surprising results. Even the best problem-solving systems out of the DeepMind lab failed to complete even one full game of StarCraft II. This includes the Deep Reinforcement Learning algorithm DeepMind crafted which achieved superhuman scores on 49 different Atari games in 2015.
Even in the StarCraft II minigames (released in SC2LE), a simplified version of the full game, none of the intelligent systems in the original paper achieved anywhere near the scores of a human professional playing the same game. Some of the agents did, however, achieve comparable results to a novice player in simpler minigames.
These initial findings are exciting. The fact current intelligent systems fail to produce optimal results on even a simplified version of StarCraft II means there is plenty of room to improve.
The release of SC2LE and the joint paper provides a baseline performance level for AI researchers to challenge in the future.
Where to next?
With the open access to SC2LE, DeepMind and Blizzard hope the community will contribute to building intelligent systems which humans can consider to be worthwhile StarCraft II opponents.
Future updates promise the removal of simplifications to the game, making it more like how a human would play and access to more human game replays to help train reinforcement learning agents.
I’ve always been a gamer. I played RuneScape relentlessly as kid. This kind of game playing research fascinates me. However, building the best game players in the world is not what excites me the most.
The real value will be gained when an intelligent system is able to learn to adapt the principles it has learned from one game to another, or even a completely different environment without having to start over again.
If an intelligent system can learn how to play StarCraft II, what other problems could it learn to solve?
For those looking to learn more about the SC2LE, you can read more about the full release on DeepMind’s blog and Siraj Raval has a great introductory video on how to get started with it on his YouTube channel.
DeepMind is taking on challenges which make me want to get out of bed in the morning. As I write this article, they released a paper on AlphaGo Zero, the most advanced version of AlphaGo yet which learned to play Go with zero human intervention.
I’ll be deconstructing AlphaGo Zero in the coming weeks, be sure to follow me if you’re interested in learning more.
If you would like to join me on my mission of deconstructing intelligence, I post a weekly video on YouTube documenting my journey through my self-created AI Master’s Degree.