
By Felipe Hoffa
For this analysis we’ll look at all the PushEvents published by GitHub during 2017. For each GitHub user we’ll have to make our best guess to determine to which organization they belong. We’ll only look at repositories that have received at least 20 stars this year.
Here are the results I got, which you can tinker with in my the interactive Data Studio report.
Comparing the top cloud providers
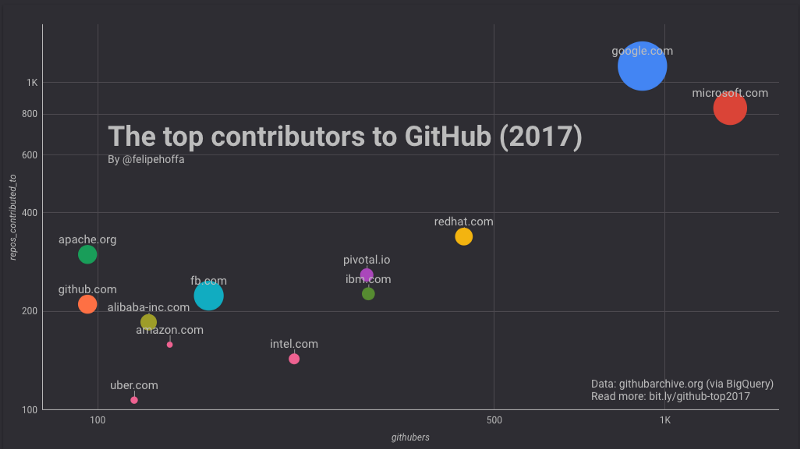
Looking at GitHub during 2017:
- Microsoft appears to have ~1,300 employees actively pushing code to 825 top repositories on GitHub.
- Google displays ~900 employees active on GitHub, who are pushing code to ~1,100 top repositories.
- Amazon appears to have only 134 active employees on GitHub, pushing code to only 158 top projects.
- Not all projects are equal: While Googlers are contributing code to 25% more repositories than Microsoft, these repositories have collected way more stars (530,000 vs 260,000). Amazon repositories sum of 2017 stars? 27,000.
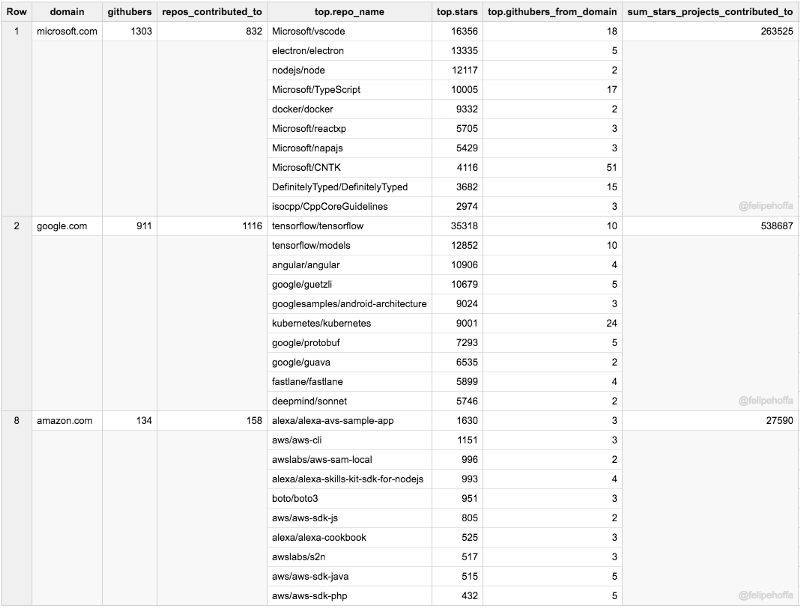
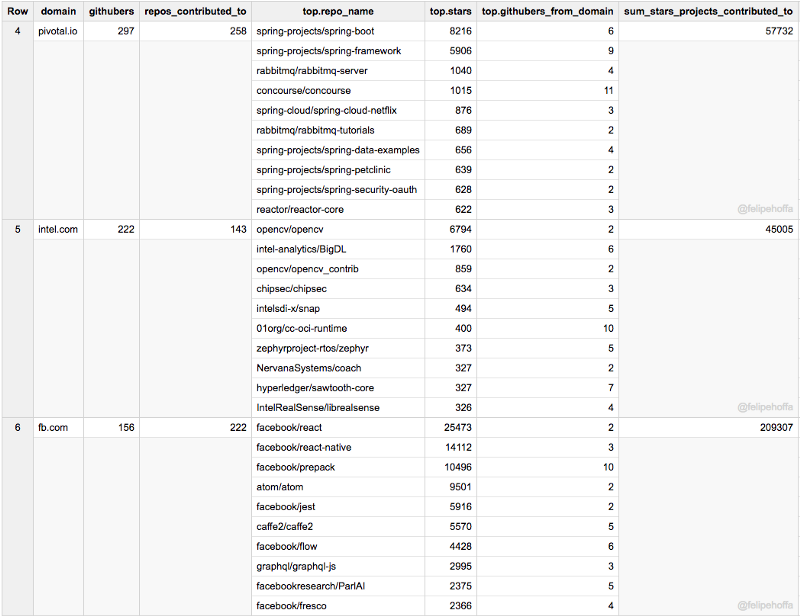
RedHat, IBM, Pivotal, Intel, and Facebook
If Amazon seems so far behind Microsoft and Google — what are the companies in between? According to this ranking RedHat, Pivotal, and Intel are pushing great contributions to GitHub:
Note that the following table combines all of IBM regional domains — while the individual regions still show up in the subsequent tables.
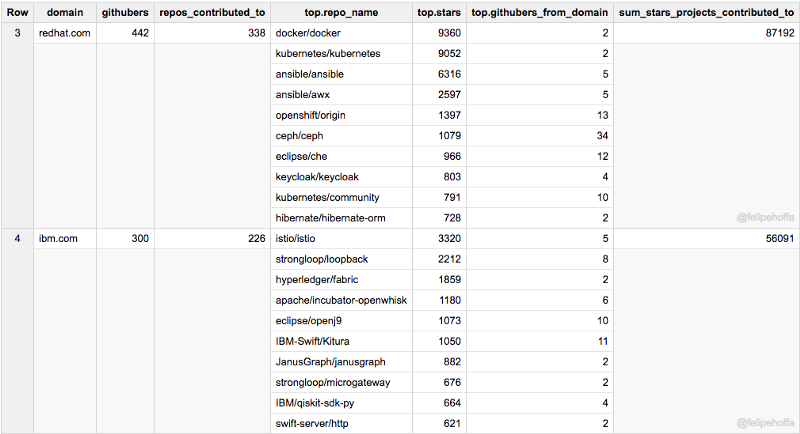
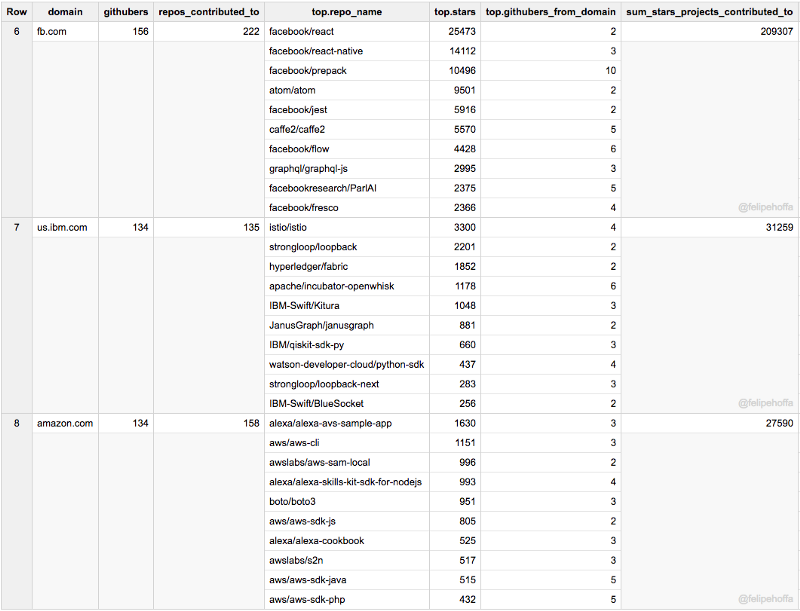
Facebook and IBM (US) have a similar number of GitHub users than Amazon, but the projects they contribute to have collected more stars (especially Facebook):
Followed by Alibaba, Uber, and Wix:
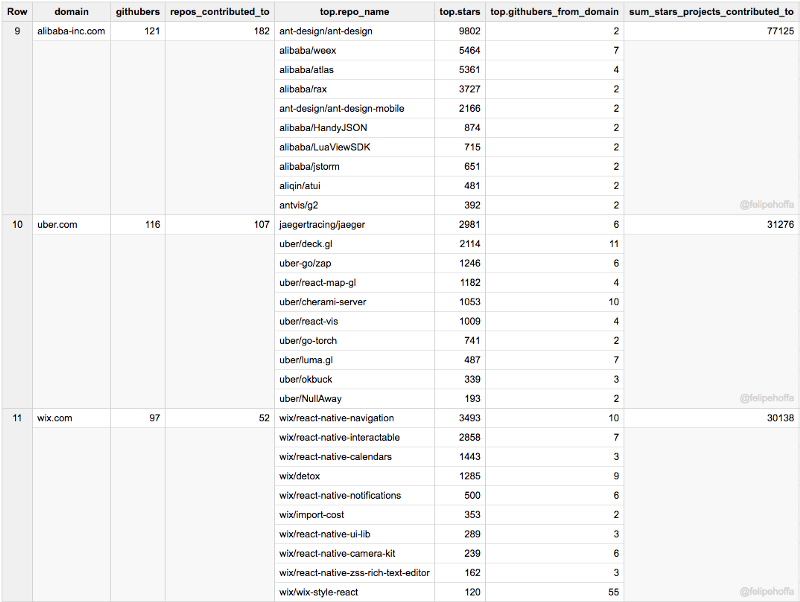
GitHub itself, Apache, Tencent:
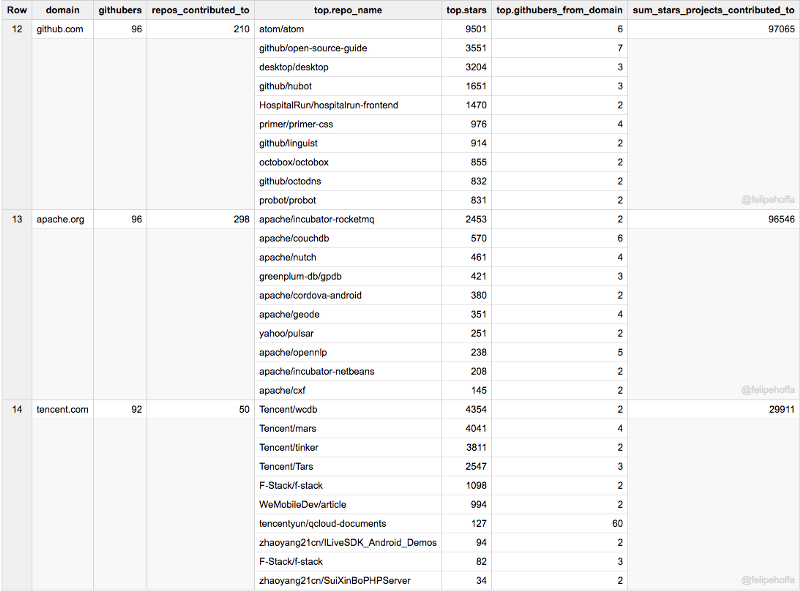
Baidu, Apple, Mozilla:
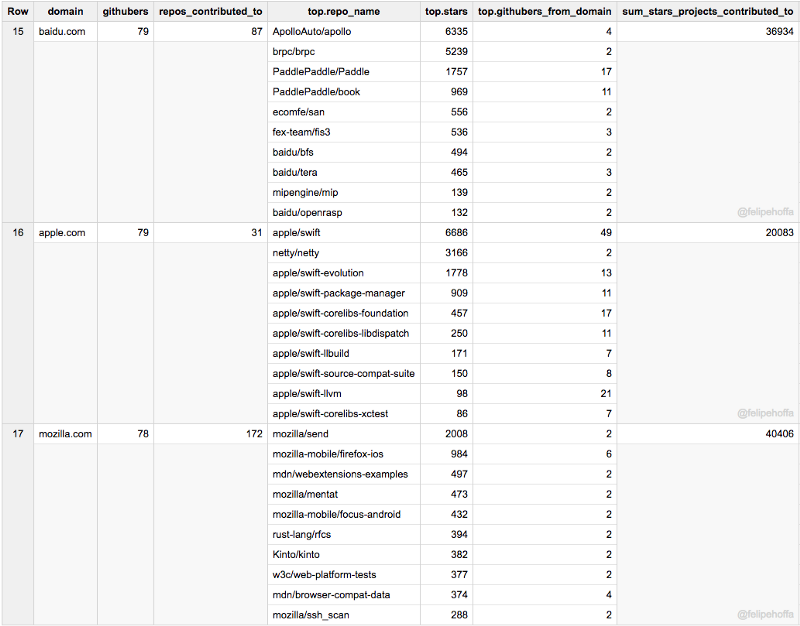
Oracle, Stanford, Mit, Shopify, MongoDb, Berkeley, VmWare, Netflix, Salesforce, Gsa.gov:
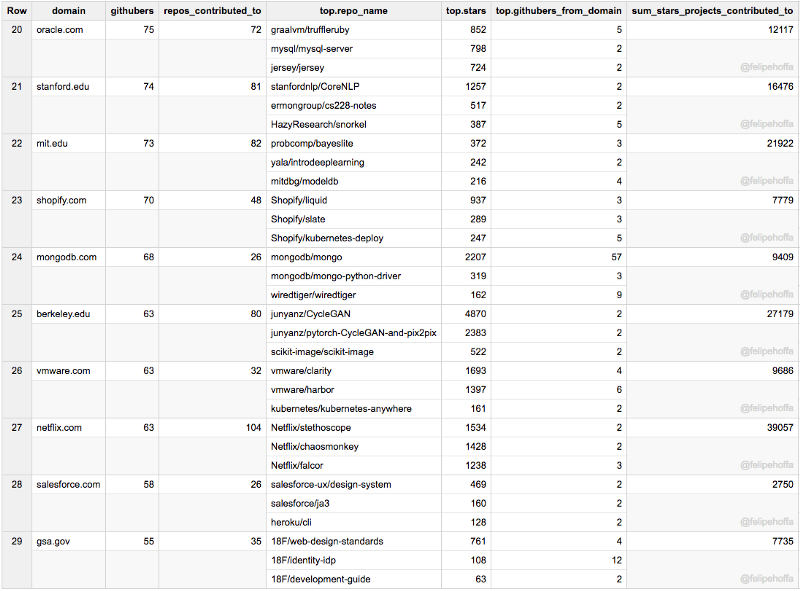
LinkedIn, Broad Institute, Palantir, Yahoo, MapBox, Unity3d, Automattic, Sandia, Travis-ci, Spotify:
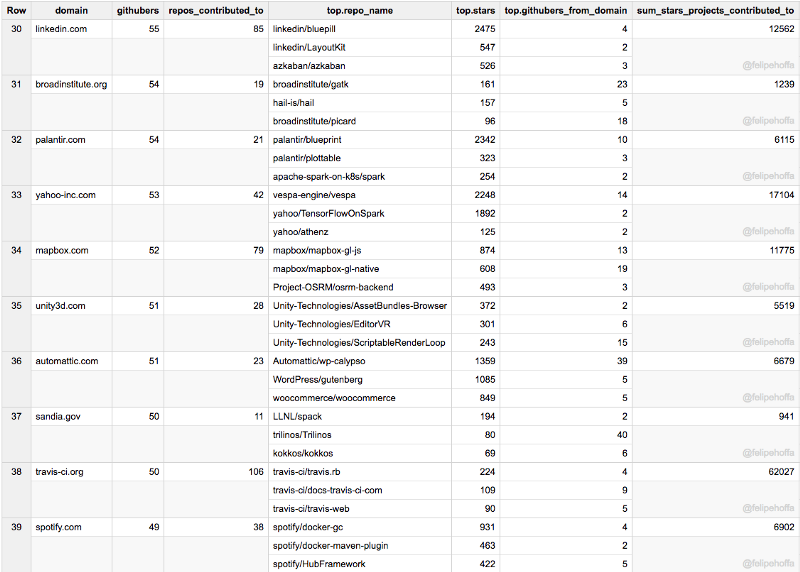
Chromium, UMich, Zalando, Esri, IBM (UK), SAP, EPAM, Telerik, UK Cabinet Office, Stripe:
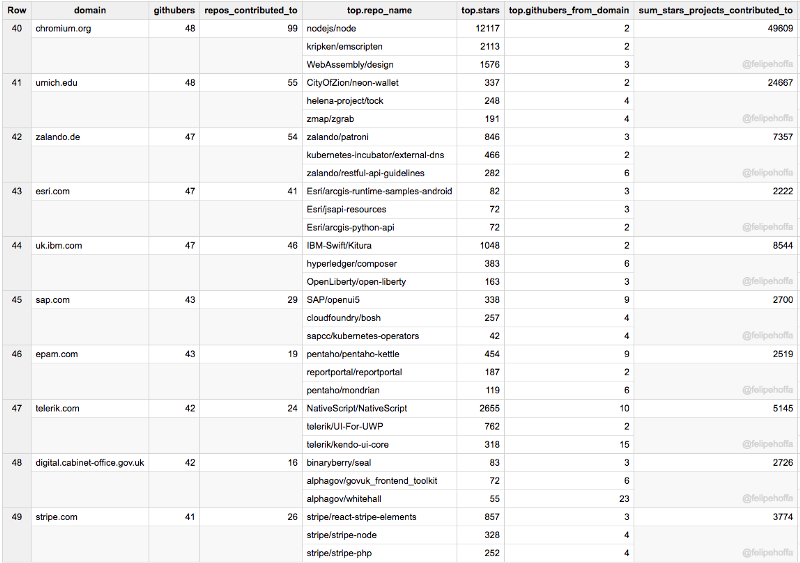
Cern, Odoo, Kitware, Suse, Yandex, IBM (Canada), Adobe, AirBnB, Chef, The Guardian:
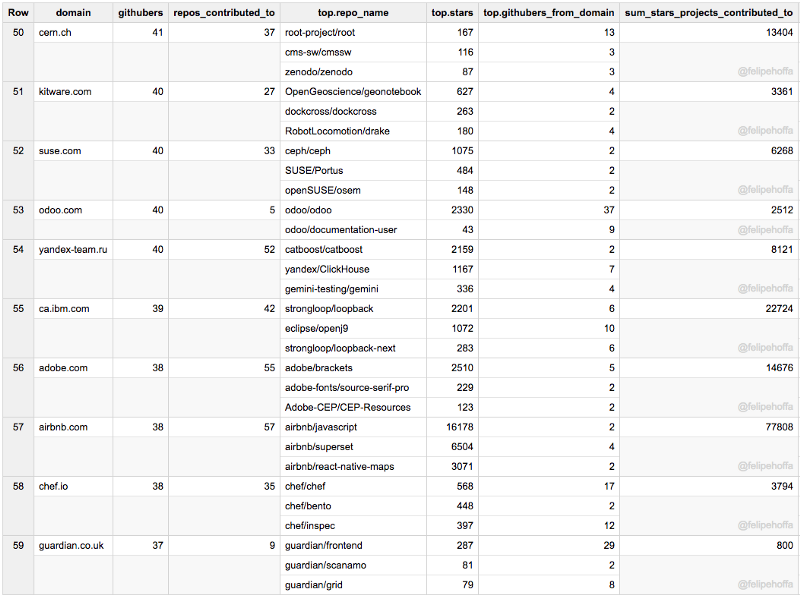
Arm, Macports, Docker, Nuxeo, NVidia, Yelp, Elastic, NYU, WSO2, Mesosphere, Inria
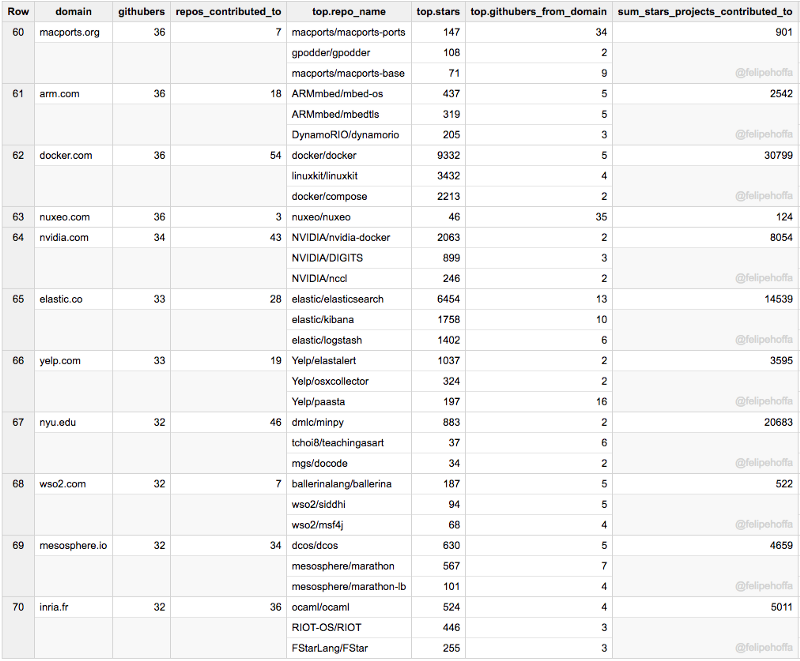
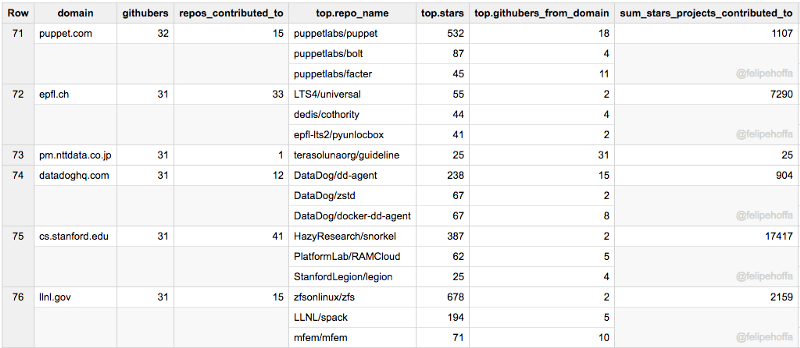
Puppet, Stanford (CS), DatadogHQ, Epfl, NTT Data, Lawrence Livermore Lab:
My Methodology
How I linked GitHub users to companies
Determining the organization to which each GitHub user belongs it’s not easy — but we can use the email domains that show up in each commit message contained on PushEvents:
- The same email can show up in more than one user, so I only considered GitHub users able to push code to GitHub projects with more than 20 stars during the period.
- I only counted GitHub users with more than 3 pushes during the period.
- Users pushing code to GitHub can display many different emails on their pushes — part of how Git works. To determine the organization for each user, I looked into the email their pushes shows up most frequently.
- Not everyone uses their organization email on GitHub. There are a lot of gmail.com, users.noreply.github.com, and other email hosting providers. Sometimes the reason for this is anonymity and protecting their corporate inboxes — but if I couldn’t see their email domain, I couldn’t count them. Sorry.
- Sometimes employees switch organizations. I assigned them to the one that got the more pushes according to these rules.
My query
#standardSQLWITHperiod AS ( SELECT * FROM `githubarchive.month.2017*` a),repo_stars AS ( SELECT repo.id, COUNT(DISTINCT actor.login) stars, APPROX_TOP_COUNT(repo.name, 1)[OFFSET(0)].value repo_name FROM period WHERE type='WatchEvent' GROUP BY 1 HAVING stars>20), pushers_guess_emails_and_top_projects AS ( SELECT * # , REGEXP_EXTRACT(email, r'@(.*)') domain , REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain FROM ( SELECT actor.id , APPROX_TOP_COUNT(actor.login,1)[OFFSET(0)].value login , APPROX_TOP_COUNT(JSON_EXTRACT_SCALAR(payload, '$.commits[0].author.email'),1)[OFFSET(0)].value email , COUNT(*) c , ARRAY_AGG(DISTINCT TO_JSON_STRING(STRUCT(b.repo_name,stars))) repos FROM period a JOIN repo_stars b ON a.repo.id=b.id WHERE type='PushEvent' GROUP BY 1 HAVING c>3 ))SELECT * FROM ( SELECT domain , githubers , (SELECT COUNT(DISTINCT repo) FROM UNNEST(repos) repo) repos_contributed_to , ARRAY( SELECT AS STRUCT JSON_EXTRACT_SCALAR(repo, '$.repo_name') repo_name , CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64) stars , COUNT(*) githubers_from_domain FROM UNNEST(repos) repo GROUP BY 1, 2 HAVING githubers_from_domain>1 ORDER BY stars DESC LIMIT 3 ) top , (SELECT SUM(CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64)) FROM (SELECT DISTINCT repo FROM UNNEST(repos) repo)) sum_stars_projects_contributed_to FROM ( SELECT domain, COUNT(*) githubers, ARRAY_CONCAT_AGG(ARRAY(SELECT * FROM UNNEST(repos) repo)) repos FROM pushers_guess_emails_and_top_projects #WHERE domain IN UNNEST(SPLIT('google.com|microsoft.com|amazon.com', '|')) WHERE domain NOT IN UNNEST(SPLIT('gmail.com|users.noreply.github.com|qq.com|hotmail.com|163.com|me.com|googlemail.com|outlook.com|yahoo.com|web.de|iki.fi|foxmail.com|yandex.ru|126.com|protonmail.com', '|')) # email hosters GROUP BY 1 HAVING githubers > 30 ) WHERE (SELECT MAX(githubers_from_domain) FROM (SELECT repo, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo GROUP BY repo))>4 # second filter email hosters)ORDER BY githubers DESC
FAQ
If an organization has 1,500 repositories, why do you only count 200? If a repository has 7,000 stars, why do you only show 1,500?
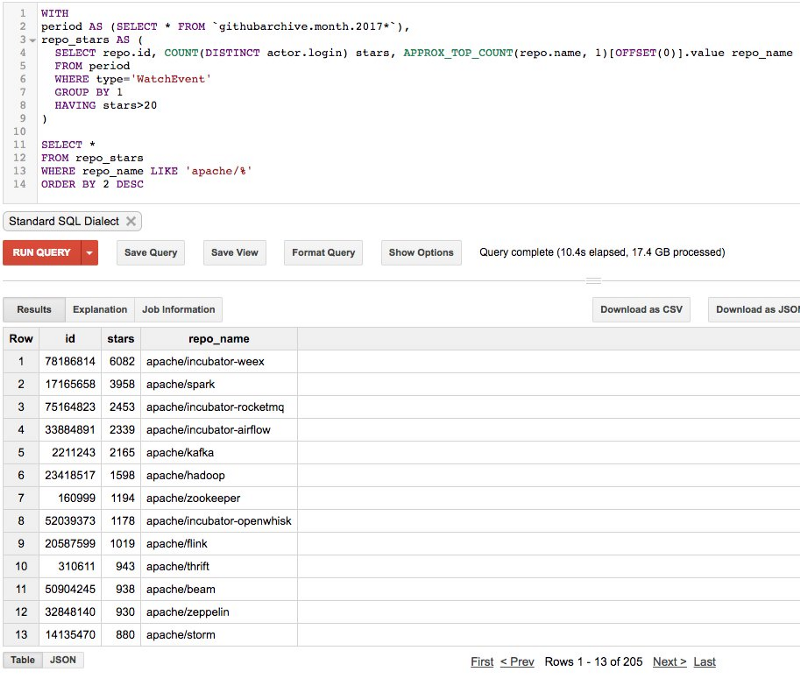
I’m filtering for relevancy. I’m only counting stars given during 2017. For example, Apache has >1,500 repositories on GitHub, but only 205 have received more than 20 stars this year.
Is this the state of open source?
Note that analyzing GitHub doesn’t include top communities like Android, Chromium, GNU, Mozilla, nor the the Apache or Eclipse Foundation, and other projects that choose to run most of their activities outside of GitHub.
You were unfair to my organization.
I can only count what I can see. Please challenge my assumptions and tell me how you would measure things in a better way. Working queries would be the best way.
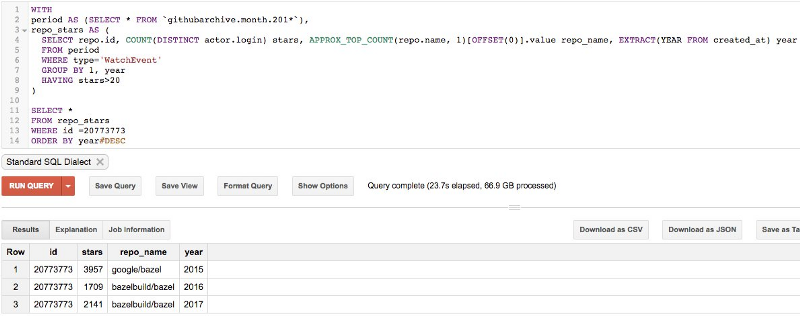
For example, see how their ranking changes when I combine IBM’s region-based domains into their top one with one SQL transformation:
SELECT *, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
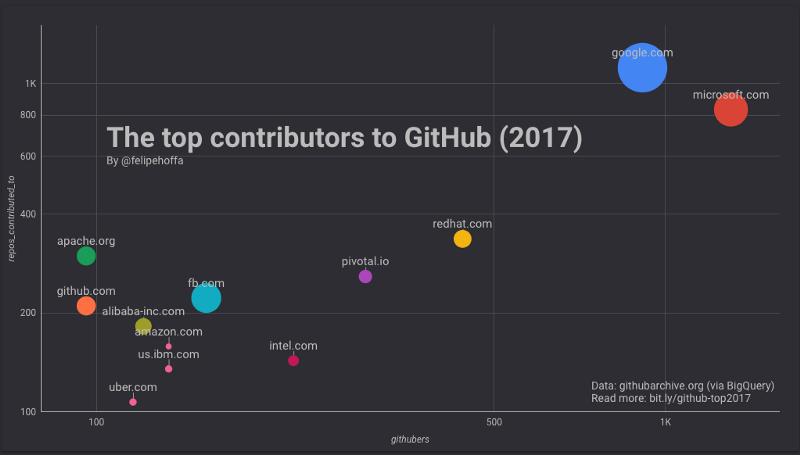
 IBM’s relative position moves significantly when you combine their regional email domains.
IBM’s relative position moves significantly when you combine their regional email domains.
Reactions
Some thoughts on "the top contributors to GitHub 2017".
_Yesterday Felipe Hoffa from the Google Dev Rel team published some interesting research looking at corporate usage of…_redmonk.com
Next steps
I’ve been wrong before — and it will probably happen again. Please take a look at all the raw data available and question all my assumptions — it will be cool to see what results you get.
Play with the interactive Data Studio report.
Thanks to Ilya Grigorik for keeping GitHub Archive well fed and full of GitHub data all these years!
Want more stories? Check my Medium, follow me on twitter, and subscribe to reddit.com/r/bigquery. And try BigQuery — every month you get a full terabyte of analysis for free.
Leading with commas — ugly or efficient? An investigation over 320 GB of SQL code
_Winning arguments with data: Let’s analyze 320 Gigabytes of open source SQL code to determine if we should use trailing…_hackernoon.comSome coders like it hot — but most prefer colder climates
_Previously we found some of the major concentration of open source coders around pretty cold places (Iceland, Sweden…_hackernoon.com