

If you've had some experience with NLP, you probably know that tokenization is at the helm of any NLP pipeline.
Tokenization is often regarded as a subfield of NLP but it has its own story of evolution. And now it underpins many state-of-the-art NLP models.
This post is all about training tokenizers from scratch by leveraging Hugging Face’s tokenizers package.
Before we get to the fun part of training and comparing the different tokenizers, I want to give you a brief summary of the key differences between the algorithms.
The main difference lies in the choice of character pairs to merge and the merging policy that each of these algorithms uses to generate the final set of tokens.
BPE Algorithm – a Frequency-based Model
Byte Pair Encoding uses the frequency of subword patterns to shortlist them for merging.
The drawback of using frequency as the driving factor is that you can end up having ambiguous final encodings that might not be useful for the new input text.
But it still has the scope of improvement in terms of generating unambiguous tokens.
Unigram Algorithm – a Probability-based Model
Next we have the Unigram model that approaches solving the merging problem by calculating the likelihood of each subword combination rather than picking the most frequent pattern.
It calculates the probability of every subword token and then drops it based on a loss function that is explained in this research paper.
Based on a certain threshold of the loss value, you can then trigger the model to drop the bottom 20-30% of the subword tokens.
Unigram is a completely probabilistic algorithm that chooses both the pairs of characters and the final decision to merge (or not) in each iteration based on probability.
WordPiece Algorithm
With the release of BERT in 2018, there came a new subword tokenization algorithm called WordPiece which can be considered an intermediary of BPE and Unigram algorithms.
WordPiece is also a greedy algorithm that leverages likelihood instead of count frequency to merge the best pair in each iteration but the choice of characters to pair is based on count frequency.
So, it is similar to BPE in terms of choosing characters to pair and similar to Unigram in terms of choosing the best pair to merge.
With the algorithmic differences covered, I tried to implement each of these algorithms (not from scratch) to compare the output generated by each of them.
How to Train the BPE, Unigram, and WordPiece Algorithms
Now, in order to have an unbiased comparison of outputs, I didn’t want to use pre-trained algorithms as that would bring size, quality, and the content of the dataset into the picture.
One way could be to code these algorithms from scratch using the research papers and then test them out. This is a good approach in order to truly understand the workings of each algorithm but you might end up spending weeks doing that.
I instead used Hugging Face’s tokenizers package that offers the implementation of all of today’s most used tokenizers. It also allowed me to train these models from scratch on my choice of dataset and then tokenize the input string of my own choice.
How to Train the Datasets
I chose two different datasets to train these models. One is a free book from Gutenberg which serves as a small dataset and the other one is the wikitext-103 which is 516M of text.
In the Colab, you can download the datasets first and unzip them (if required):
!wget http://www.gutenberg.org/cache/epub/16457/pg16457.txt
!wget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip
!unzip wikitext-103-raw-v1.zip
Import the Required Models and Trainers
Going through the documentation, you’ll find that the main API of the package is the class Tokenizer.
You can then instantiate any tokenizer with your choice of model (BPE/ Unigram/ WordPiece).
Here, I imported the main class, all the models I wanted to test, and their trainers, as I want to train these models from scratch.
## importing the tokenizer and subword BPE trainer
from tokenizers import Tokenizer
from tokenizers.models import BPE, Unigram, WordLevel, WordPiece
from tokenizers.trainers import BpeTrainer, WordLevelTrainer, \
WordPieceTrainer, UnigramTrainer
## a pretokenizer to segment the text into words
from tokenizers.pre_tokenizers import Whitespace
How to Automate Training and Tokenization
Since I need to perform somewhat similar processes for three different models, I broke the processes into 3 functions. I’ll only need to call these functions for each model and my job here will be done.
So, what are these functions?
Step 1 - Prepare the tokenizer
Preparing the tokenizer requires us to instantiate the Tokenizer class with a model of our choice. But since we have four models (I added a simple Word-level algorithm as well) to test, we’ll write if/else cases to instantiate the tokenizer with the right model.
To train the instantiated tokenizer on the small and large datasets, we will also need to instantiate a trainer, in our case these would be BpeTrainer, WordLevelTrainer, WordPieceTrainer, and UnigramTrainer.
The instantiation and training will need us to specify some special tokens. These are tokens for unknown words and other special tokens that we’ll need to use later on to add to our vocabulary.
You can also specify other training arguments' vocabulary size or minimum frequency here.
unk_token = "<UNK>" # token for unknown words
spl_tokens = ["<UNK>", "<SEP>", "<MASK>", "<CLS>"] # special tokens
def prepare_tokenizer_trainer(alg):
"""
Prepares the tokenizer and trainer with unknown & special tokens.
"""
if alg == 'BPE':
tokenizer = Tokenizer(BPE(unk_token = unk_token))
trainer = BpeTrainer(special_tokens = spl_tokens)
elif alg == 'UNI':
tokenizer = Tokenizer(Unigram())
trainer = UnigramTrainer(unk_token= unk_token, special_tokens = spl_tokens)
elif alg == 'WPC':
tokenizer = Tokenizer(WordPiece(unk_token = unk_token))
trainer = WordPieceTrainer(special_tokens = spl_tokens)
else:
tokenizer = Tokenizer(WordLevel(unk_token = unk_token))
trainer = WordLevelTrainer(special_tokens = spl_tokens)
tokenizer.pre_tokenizer = Whitespace()
return tokenizer, trainer
We’ll also need to add a pre-tokenizer to split our input into words as without a pre-tokenizer, we might get tokens that overlap several words: for instance we could get a "there is" token since those two words often appear next to each other.
Using a pre-tokenizer will ensure no token is bigger than a word returned by the pre-tokenizer.
This function will return the tokenizer and its trainer object which we can use to train the model on a dataset.
Here, we are using the same pre-tokenizer (Whitespace) for all the models. You can choose to test it with others.
Step 2 - Train the tokenizer
After preparing the tokenizers and trainers, we can start the training process.
Here’s a function that will take the file(s) on which we intend to train our tokenizer along with the algorithm identifier.
‘WLV’- Word Level Algorithm‘WPC’- WordPiece Algorithm‘BPE’- Byte Pair Encoding‘UNI’- Unigram
def train_tokenizer(files, alg='WLV'):
"""
Takes the files and trains the tokenizer.
"""
tokenizer, trainer = prepare_tokenizer_trainer(alg)
tokenizer.train(files, trainer) # training the tokenzier
tokenizer.save("./tokenizer-trained.json")
tokenizer = Tokenizer.from_file("./tokenizer-trained.json")
return tokenizer
This is the main function that we’ll need to call for training the tokenizer. It will first prepare the tokenizer and trainer and then start training the tokenizers with the provided files.
After training, it saves the model in a JSON file, loads it from the file, and returns the trained tokenizer to start encoding the new input.
Step 3 - Tokenize the input string
The last step is to start encoding the new input strings and compare the tokens generated by each algorithm.
Here, we’ll be writing a nested for loop to train each model on the smaller dataset first followed by training on the larger dataset and tokenizing the input string as well.
Input string - “This is a deep learning tokenization tutorial. Tokenization is the first step in a deep learning NLP pipeline. We will be comparing the tokens generated by each tokenization model. Excited much?!😍”
small_file = ['pg16457.txt']
large_files = [f"./wikitext-103-raw/wiki.{split}.raw" for split in ["test", "train", "valid"]]
for files in [small_file, large_files]:
print(f"========Using vocabulary from {files}=======")
for alg in ['WLV', 'BPE', 'UNI', 'WPC']:
trained_tokenizer = train_tokenizer(files, alg)
input_string = "This is a deep learning tokenization tutorial. Tokenization is the first step in a deep learning NLP pipeline. We will be comparing the tokens generated by each tokenization model. Excited much?!😍"
output = tokenize(input_string, trained_tokenizer)
tokens_dict[alg] = output.tokens
print("----", alg, "----")
print(output.tokens, "->", len(output.tokens))
And here's the output:

Analysis of the output:
Looking at the output, you’ll see the difference in how the tokens were generated which in turn led to different number of tokens generated.
A simple word level algorithm created 35 tokens no matter which dataset it was trained on.
BPE algorithm created 55 tokens when trained on a smaller dataset and 47 when trained on a larger dataset. This shows that it was able to merge more pairs of characters when trained on a larger dataset.
The Unigram model created similar (68 and 67) numbers of tokens with both the datasets. But you can see the difference in the generated tokens:
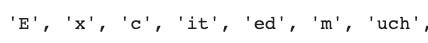
With larger dataset, merging came closer to generating tokens that are better-suited to encode real-world English language words that we often use.

WordPiece created 52 tokens when trained on a smaller dataset and 48 when trained on a larger dataset. The generated tokens have double ## to denote the use of a token as a prefix/suffix.

All three algorithms generated worse and better subword tokens when trained on a larger dataset.
How to Compare the Tokens
To compare the tokens, I stored the output of each algorithm in a dictionary and I’ll turn it into a dataframe to view the differences in tokens better.
Since the number of tokens generated by each model is different, I’ve added a token to make the data rectangular and fit a dataframe.
is basically nan in the dataframe.
import pandas as pd
max_len = max(len(tokens_dict['UNI']), len(tokens_dict['WPC']), len(tokens_dict['BPE']))
diff_bpe = max_len - len(tokens_dict['BPE'])
diff_wpc = max_len - len(tokens_dict['WPC'])
tokens_dict['BPE'] = tokens_dict['BPE'] + ['<PAD>']*diff_bpe
tokens_dict['WPC'] = tokens_dict['WPC'] + ['<PAD>']*diff_wpc
del tokens_dict['WLV']
df = pd.DataFrame(tokens_dict)
df.head(10)
Here's the output:

You can also look at the difference in tokens using sets:


To check out the code, head over to this Colab notebook.
Closing Thoughts and Next Steps
Based on the kind of tokens generated, WPC does seem to generate subword tokens that are more commonly found in the English language – but don’t hold me to this observation.
These algorithms are slightly different from each other and do a somewhat similar job of developing a decent NLP model. But much of the performance depends on the use case of your language model, the vocabulary size, speed and other factors.
This concludes our examination of tokenization algorithms. The next step to deep dive into this is to understand what embeddings are, how tokenization plays a vital role in creating these embeddings, and how they affect a model’s performance.
A further advancement to these algorithms is the SentencePiece algorithm which is a wholesome approach to the whole tokenization problem. But much of this problem is alleviated by HuggingFace, and even better – they have all the algorithms implemented in a single GitHub repo.
References and Notes
If you have questions about my analysis or any of my work in this post, I highly encourage you to check out these resources for a precise understanding of the workings of each algorithm:
Subword regularization: Improving Neural Network Translation Models with Multiple Subword Candidates by Taku Kudo
Neural Machine Translation of Rare Words with Subword Units - Research paper that discusses different segmentation techniques based BPE compression algorithm.
Connect with me
If you’re looking to get started in the field of data science or ML, check out my course on Foundations of Data Science & ML.
If you would like to see more of such content and you are not a subscriber, consider subscribing to my newsletter.
Have something to add or suggest, you can reach out to me via: