

Word embeddings serve as the foundation for many applications, from simple text classification to complex machine translation systems. But what exactly are word embeddings, and how do they work? Let's find out.
What Are Word Embeddings?
Word embeddings serve as the digital DNA for words in the world of natural language processing (NLP). In essence, word embeddings convert words into numerical vectors (a fancy term for arrays of numbers). These vectors can be processed by machine learning algorithms.
Think of these vectors as a numeric fingerprint for each word. For example, the word “apple” might be represented by a numerical vector like [0.2, -0.4, 0.7].
The main benefit of word embeddings is their ability to capture the semantic essence of words. In simpler terms, they help machines understand the meaning and nuances behind each word.
For example, if “apple” is close to “fruit” in this numerical space but far from “car,” the machine understands that an apple is more related to fruits than to vehicles.
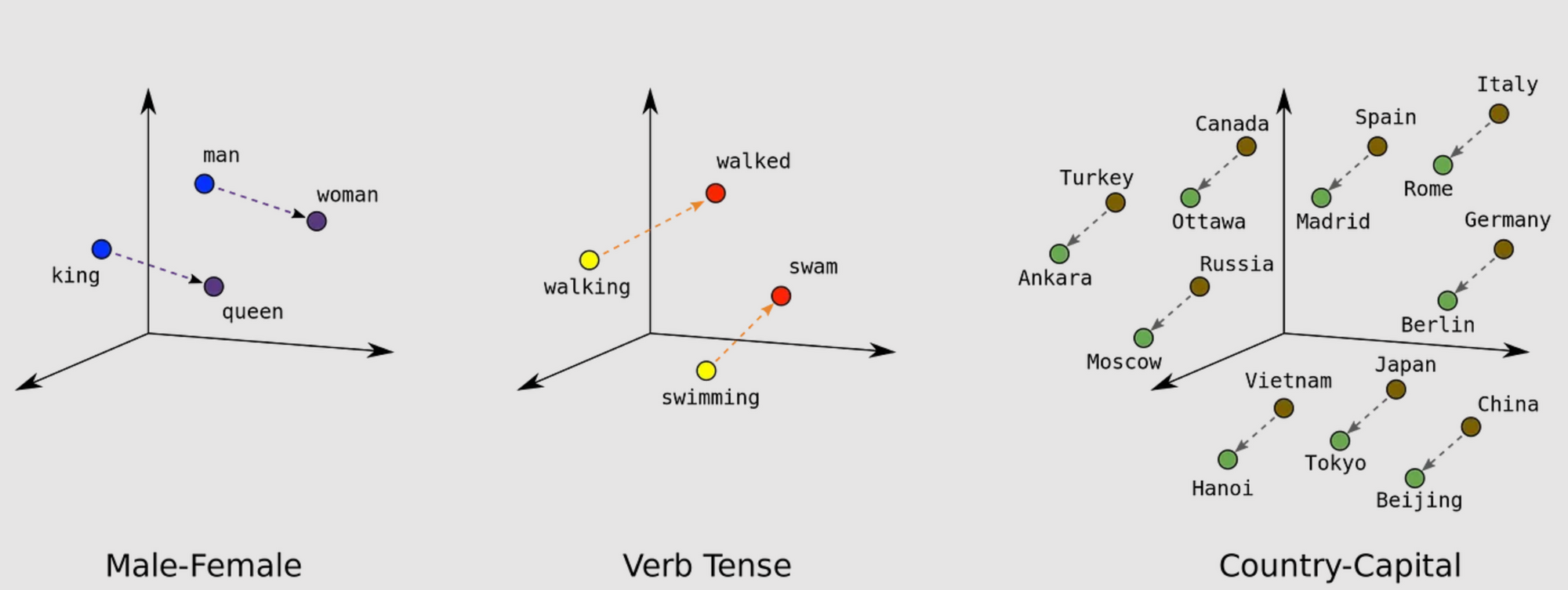
Beyond individual meaning, word embeddings also encode relationships between words. Words that often appear together in the same context will have similar or ‘closer’ vectors.
 Word embeddings
Word embeddings
For example, in the numerical space, the vectors representing “king” and “queen” might be closer to each other than those representing “king” and “apple.” This is because the algorithm has learned from numerous texts that “king” and “queen” often appear in similar settings, such as discussions about royalty, while “king” and “apple” do not.
Why Do We Need Word Embeddings?
Traditional language models treated words as separate, isolated entities.
For instance, the word “dog” might be represented as a unique identifier, say 1, while the word "cat" as 2. This approach fails to capture the relationship between "dog" and "cat," which are both animals and pets.
Word embeddings solve this problem by placing words with similar meanings or contexts close to each other in a multi-dimensional space.
Algorithms for Generating Embeddings
Word2Vec
Researchers at Google developed Word2Vec, which employs neural networks to generate word embeddings. The model processes a large text corpus and outputs high-quality word vectors.
It determines these embeddings by analyzing the context in which words appear, based on the idea that words found in similar contexts likely share semantic meaning.
GloVe (Global Vectors for Word Representation)
Stanford researchers developed GloVe, which constructs a large table to monitor the frequency with which words co-occur in a text dataset. The model then employs mathematical methods to simplify this table, generating numerical vectors for individual words.
These vectors encapsulate both the meaning and the relationships among words, laying the groundwork for various machine-learning tasks related to language.
FastText
Facebook’s AI Research lab created FastText, which improves upon the Word2Vec model by viewing words as assemblies of smaller character strings, or character n-grams.
This method enables the model to more effectively capture the intricacies of languages that have complex word structures and to incorporate words not present in the original training data. Consequently, FastText yields a more adaptable and comprehensive language model useful for a diverse set of machine-learning tasks.
Word Embeddings and GPTs
 Word embeddings and GPTs
Word embeddings and GPTs
Word embeddings are a foundational component in GPT models like GPT-2, GPT-3, and GPT-4. However, the architecture and approach are a bit more advanced compared to simpler models that solely rely on word embeddings.
In traditional models that use word embeddings like Word2Vec or GloVe, each word is converted into a fixed vector in a pre-defined space. These vectors are then used as the input to other machine learning algorithms for tasks like classification, clustering, or even in sequence-to-sequence models for machine translation.
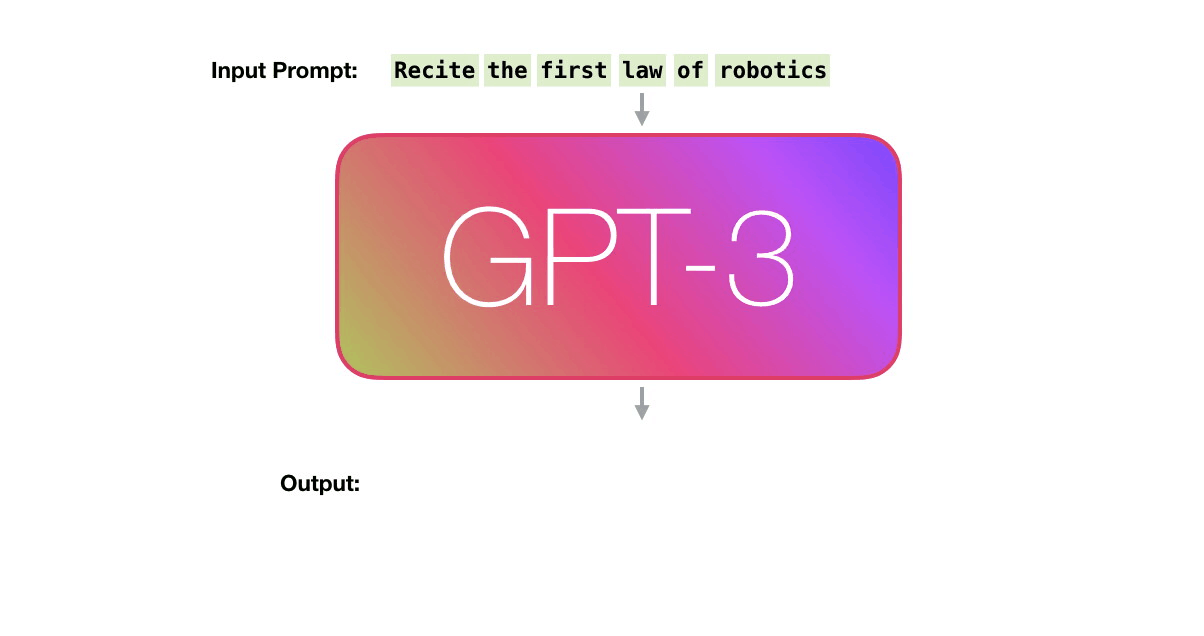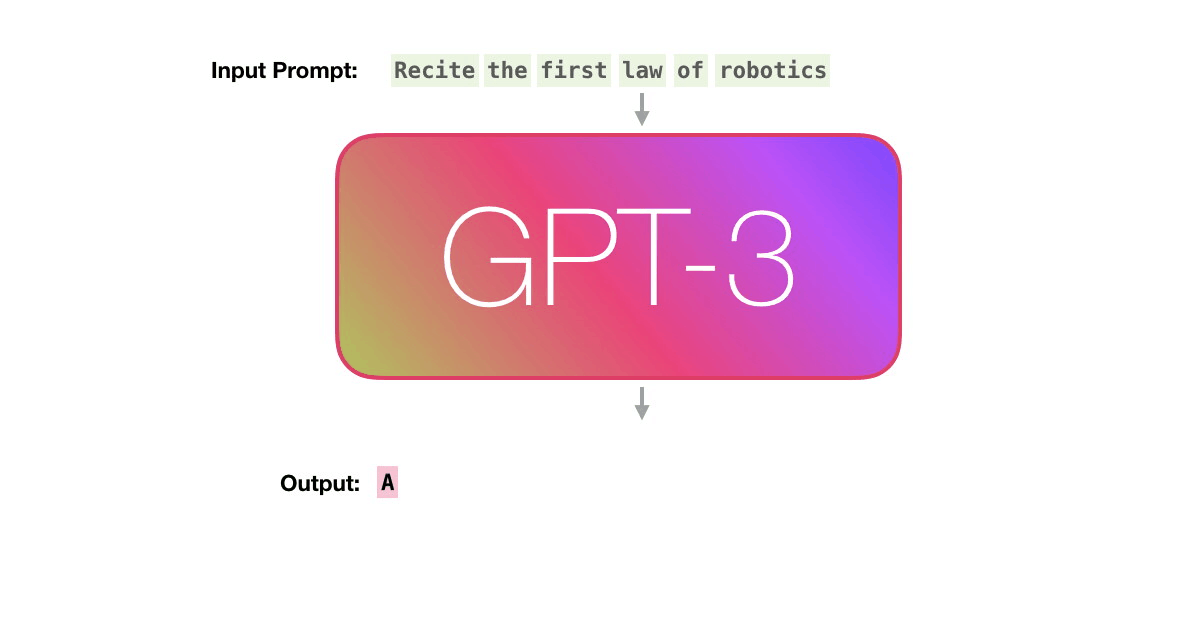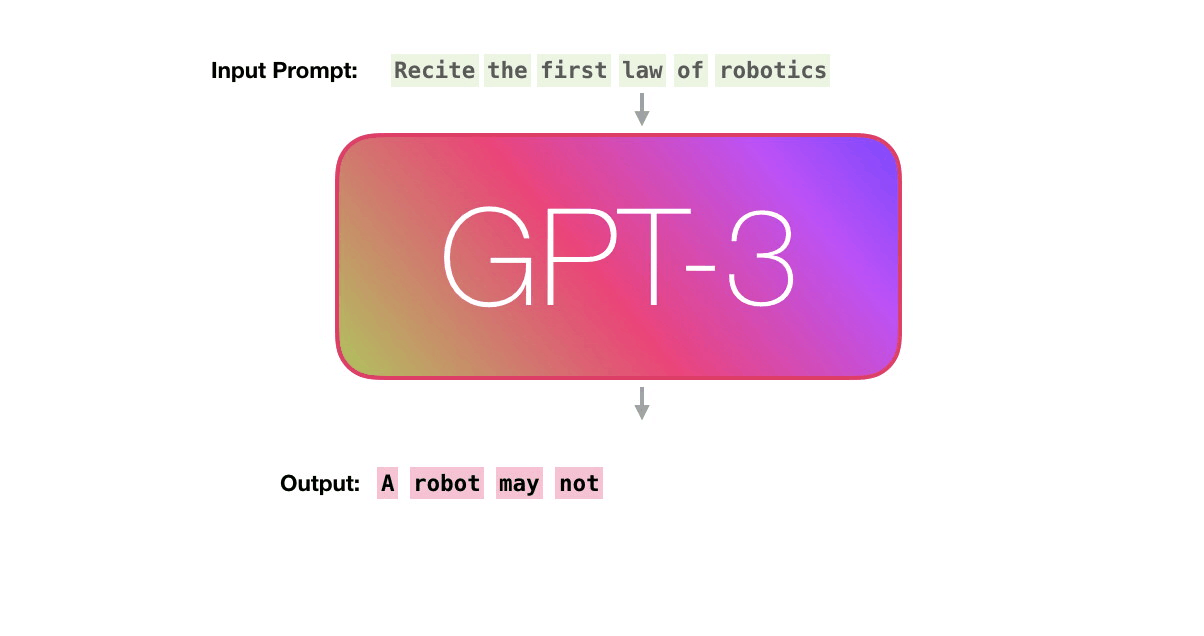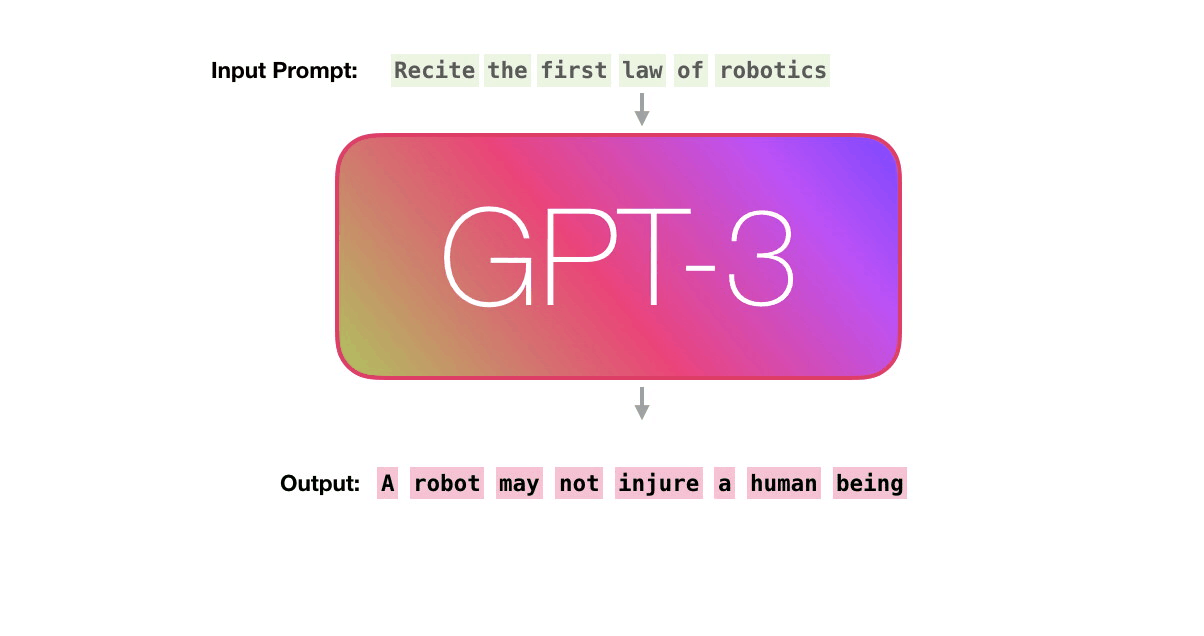
In contrast, GPT models use a variant known as “transformer embeddings,” which not only embeds individual words but also considers the context in which a word appears.
This is essential for understanding the meaning of words that can change based on their surrounding words. For example, the word “bank” could mean a financial institution or the side of a river, depending on the context.
The GPT architecture takes a sequence of words (or more precisely, tokens) as input and processes them through multiple layers of transformer blocks. These blocks output a new sequence of vectors that represent not just the individual words, but also their relationships with all other words in the input sequence.
This sequence is then used for NLP tasks, from text completion to translation and summarization.
So, while GPT models do use embeddings, they are far more dynamic and context-aware than traditional word embeddings. The embeddings in GPT models are part of a larger, more complex system designed to understand and generate human-like text based on the input it receives.
Conclusion
Word embeddings offer an effective and computationally efficient way to represent words as vectors, capturing the intricacies of language in a form that machines can understand. They lie at the heart of many NLP applications, improving the accuracy and sophistication of language models.
As technology continues to evolve, so will the methods for generating and utilizing word embeddings, promising even more robust and nuanced language processing capabilities in the years to come.
If you found this article interesting, join my newsletter and I'll send you an email with my content every Friday.