By Bertrand Fan
In December, Slack announced a $80 million fund to invest in software projects that complement its technology. As an early adopter of the Slack API, here are some “bets” that I’ve made on the Slack platform:
A bot that plays all of Star Wars Despecialized Edition (Han shoots first!) one frame every ten seconds. It takes about 20 hours to get through the whole thing.

A bot that hosts games of The Resistance (optionally with the Assassin Module from the Hidden Agenda expansion). Secret voting is conducted via DM with the bot, while public actions are done in the channel.

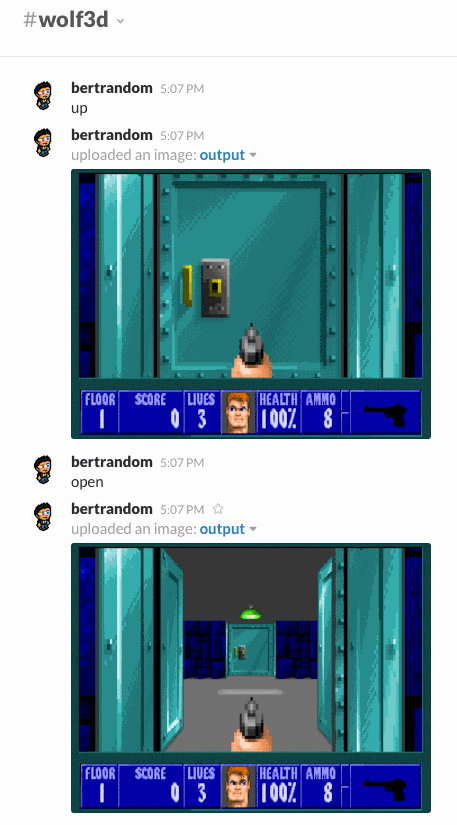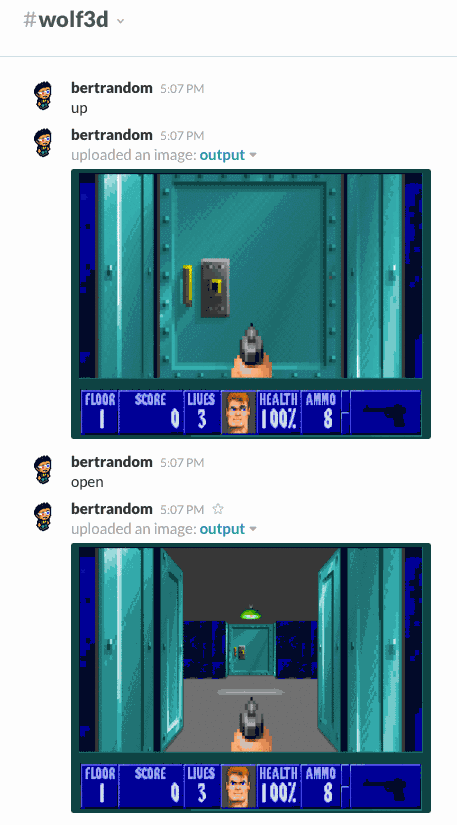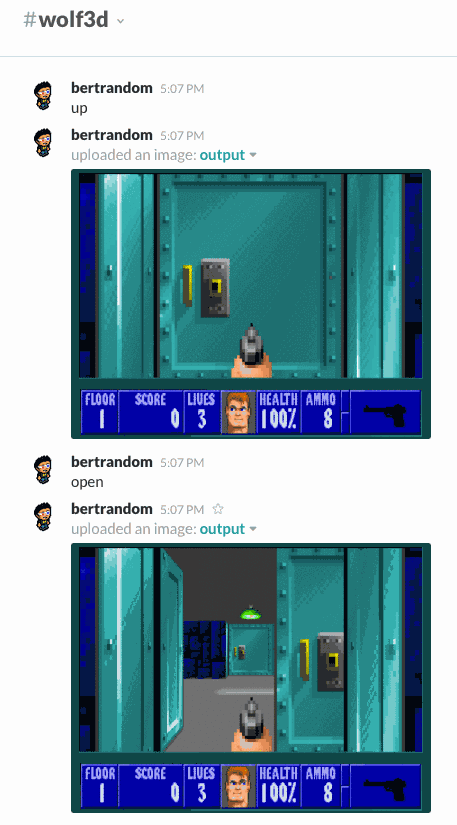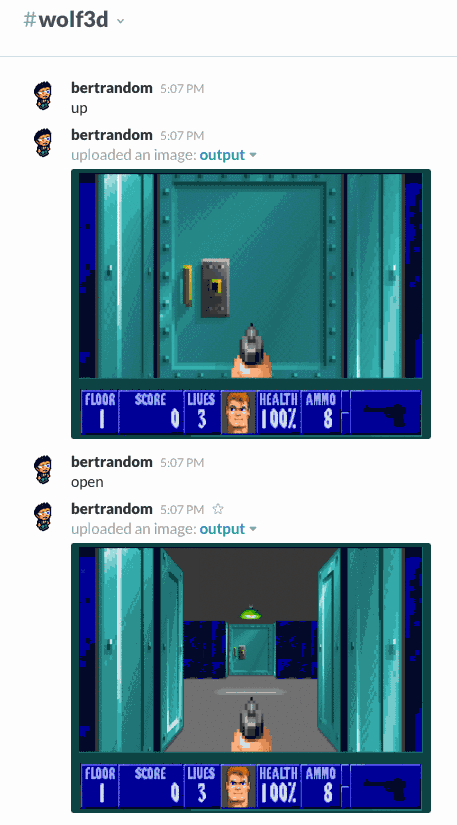
A bot that lets you play Wolfenstein 3D by issuing commands (left, right, up, down, open, and fire). You can optionally specify how many degrees to turn left and right, but by default you turn 45-degrees. I’ve never successfully completed the first level, but I have managed to kill several guards.
I’m happy to announce that I’ve completed my latest bot, Vandelay Industries. Vandelay Industries is a shameless rip-off of Frinkiac that lets you search for animated gifs from every episode of Seinfeld in Slack. It has every line of dialogue ever spoken in Seinfeld.

If you’d like to try it out in your Slack team, just go to Vandelay Industries and click Add to Slack. It will ask you for permission to add a new slash command, /vandelay and once authorized, it should be ready to use immediately within Slack.
If you’re interested in the technical details of how it works, keep on reading! If not, you’ve managed to beat the estimated reading time for this article. Congratulations!

Processing
I initially started with 91G of all nine seasons of Seinfeld in surprisingly high quality 720p. I ultimately ended up with 111G worth of animated GIFs which tells you everything you need to know about the efficiency of that file format. This section is all about how I went from one to the other.
The files were in MKV containers, so I was able to use MKVToolNix to extract the subtitles from them. You can use mkvinfo to list the various segment tracks:
mkvinfo Seinfeld.S01E01.The.Seinfeld.Chronicles.mkv
It’s a little hard to read, but the track that we’re interested in is Track number 3, the first subtitles track. After noting the track ID (2), we can extract the subtitles into an SRT file like this:
mkvextract tracks Seinfeld.S01E01.The.Seinfeld.Chronicles.mkv 2:S01E01.srt
The SRT format is fairly straightforward. It contains a counter, start time, end time, and the subtitle text. Using a parser like subtitles-parser, we can easily iterate over the subtitles.
The next step is to loop through each subtitle and extract that time range from the MKV into an animated GIF. There’s an excellent article about using ffmpeg to encode high quality GIF but if you don’t want to read that right now, the trick is to extract a specialized palette from the section of the video that you’re interested in and then use that to encode the GIF.
Here’s a script that I adapted for the purposes of this processing step:
320 refers to how many pixels wide the resulting GIF will be. You’ll notice that instead of specifying a start time and an end time, I instead specify a duration. Although ffmpeg claims to support end times, no matter which version I tried I could not get it to properly extract the right range, so I ended up calculating the duration by subtracting the start time from the end time and abusing the unix epoch like this:
After applying the gifenc.sh script, we’re left with a nice animated GIF of the correct extracted range like this:

But I wanted to display the subtitle text at the bottom of the GIF and after digging through the ImageMagick documentation, I came up with this:
It’s not the most elegant solution, but it gets the job done. Our final gif looks like this:

Now just do that about 104,782 more times and you’re done. Running an entire episode through ffmpeg and ImageMagick took about 30 minutes on my top-of-the-line-in-2011 Macbook Pro. This is the part of the story where I’d like to tell you that I managed to leverage Amazon Elastic Transcoder or made a hadoop job to distribute the load to all the computers in my house, but really what I did was put all of this on my reconditioned budget OVH server and let it run for 5 days while I continued to live my life.
Once it was done encoding all the GIFs, I just let Apache serve them statically with a long Expires header and put Cloudflare in front of the whole domain. Only time will tell if that will actually hold up with traffic demands.
Searching
I installed Elasticsearch and indexed the contents of the SRT files. Here’s where I encountered some non-technical snags: In Season 6, episodes 14 and 15 are an hour-long clip show called Highlights of a Hundred where Jerry Seinfeld shows you a bunch of old clips from previous episodes. And in the final episode of Seinfeld, Season 9, Episode 23, they do a ton of flashbacks to previous episodes. Both of these would routinely get returned in the search results, so I just excluded them from the search query. There’s probably a better way to just lower the quality of those episode scores, but the documentation for doing so in Elasticsearch is about as easy to read as the above mentioned ImageMagick documentation. And at the end of the day, no one wants to see clips from either of those two episodes. Sorry, Larry David, the last episode was terrible.
Slash Command
The final step was just to wrap it all together with a Slack slash command, which is just a simple Express app that acts as a client to the Elasticsearch instance. There’s some OAuth to package the command as a Slack App and handle the Add to Slack button, but I don’t really need to check for authentication when the requests come through so I’m not saving the authorization tokens. The code for the server is available here: vandelayindustries-slack-server.
That’s it! I hope this technical writeup helps the next person that wants to extract GIFs from an entire television show for little to no actual reason.
