
By Maciej Gurban
At Unity, we’ve recently set out to improve our Dashboards — an undertaking which dramatically changed not only our frontend tech stack, but also the ways we work and collaborate.
We’ve developed best practices and tooling to help us scale our frontend architecture, build products with great UX and performance, and to ship new features sooner.
This article gathers these practices and aims to provide as much reasoning behind each decision as possible. But first, some context.
The Legacy
Looking at the number of engineers, Unity more than quadrupled its headcount in the last 4 years. As the company grew both organically and through acquisitions, its product offering grew as well. While the products developed originally at Unity were largely uniform in terms of tech and design language, the newly acquired ones naturally were not.
As a result we had multiple visually distinct dashboards which worked and behaved differently and which shared no common navigational elements. This resulted in poor user experience and frustrated users. In the very literal sense, the state of frontends of our products was costing us revenue.
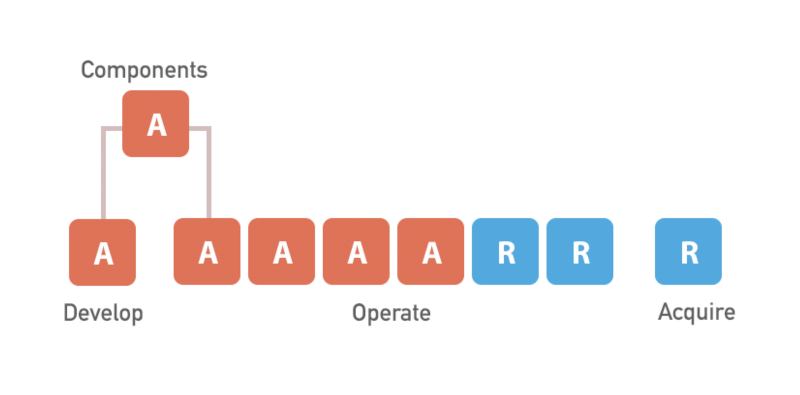
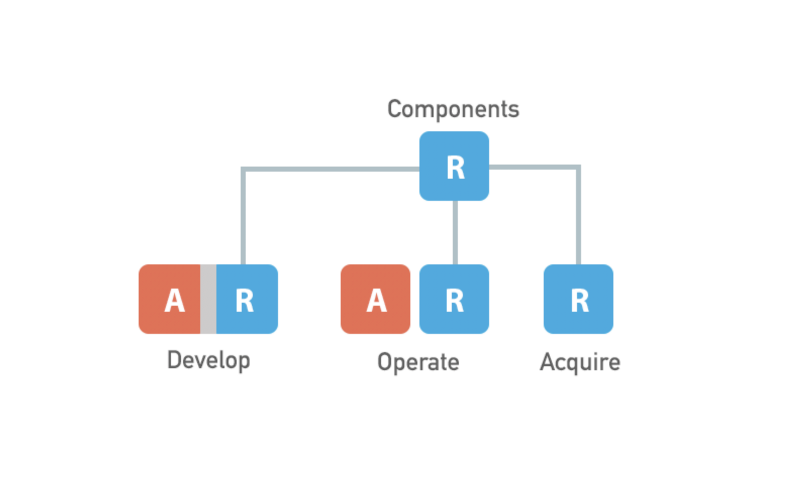
After analyzing the portfolio of our products, we’ve elicited three distinct sections Unity Dashboard would be split into: Develop, Operate and Acquire , each satisfying a different business need and meant for different customer groups, thus containing feature sets largely independent from each other.
This new structure, and the introduction of common navigational elements aimed to solve the first major issue our users were facing — where to find the information and configuration options they’re looking for, and while it all looked good on paper, the journey how to get there were far from obvious.
Considerations
Many of our developers were very excited about the possibility of moving to React and its more modern tech stack. As these solutions had been battle tested in large applications, and had their best practices and conventions mostly ironed out, things looked very promising.
Nevertheless, what our developers knew best and what most of our actively developed applications were written in was AngularJS. Deciding to start migrating everything in one go would have been a disaster waiting to happen. Instead we set out to test our assumptions on a much smaller scale first.
Perhaps the most disjointed group of products we’ve had were the Monetization dashboards. These projects, which would eventually end up under the umbrella of the Operate dashboard, were vastly different in almost any way possible: technologies used, approach to UI/UX, development practices, coding conventions — you name it.
Here’s what the situation roughly looked like:
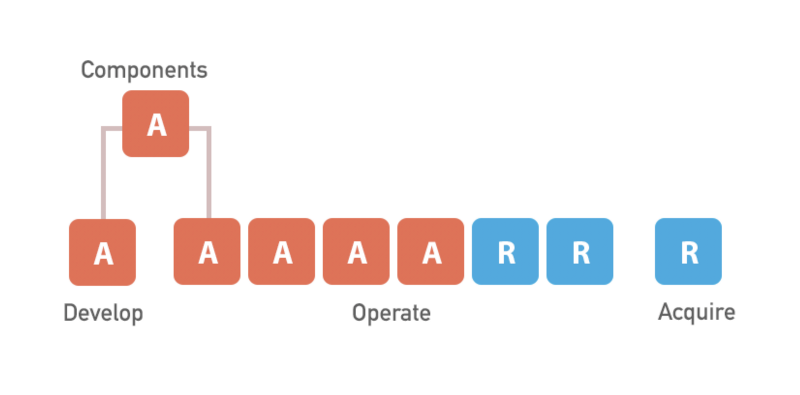
After some brainstorming we identified the main areas which we’d need to work on to bring all the products together:
1. A single product
We needed these dashboards (split across multiple applications, domains and tech stacks) to:
- Feel like a single product (no full page redirects as the user navigates through pages of all the different applications)
- Have a consistent look and feel
- Include common navigational elements are always visible and look the same, no matter which part of the dashboard the user is visiting
2. Legacy support
While we did have a clean slate when it comes to the technology choice of our new frontend solution, we had to accommodate for the legacy projects which needed to be integrated into the new system. A solution, which didn’t involve big refactoring efforts, and which wouldn’t stop feature development, or drag for months without end in sight.
3. Practices and tooling
While nearly all the teams used AngularJS, different tools were being used to address the same set of challenges. Different test runners and assertion libraries, state management solutions or lack thereof, jQuery vs native browser selectors, SASS vs LESS, charting libraries etc.
4. Developer productivity
Since every team had their own solution to developing, testing and building their application, the development environment was often riddled with bugs, manual steps, and inefficiencies.
Additionally, many of our teams work in locations separated by a 10 hour difference (Helsinki, Finland and San Francisco), which makes efficient decision-making on any shared pieces a real challenge.
The New
Our main areas of focus were to:
- Encourage and preserve agile ways of working in our teams, and to let the teams be largely independent from one another
- Leverage and develop common tooling and conventions as much as possible, to document them, and make them easily accessible and usable
We believed that achieving these the goals would significantly improve our time to market and developer productivity. For that to happen, we required a solution which would:
- Build product features with better user experience
- Improve code quality
- Allow for better collaboration without blocking anybody’s work progress in the process.
We also wanted to encourage and ease-in the move to a modern tech stack to make our developers more satisfied with their work, and to over time move away from our antiquated frameworks and tooling.
The ever-evolving result of our work is a React-based SPA built inside a monorepository where all the pages and bigger features get built into largely independent code bundles loaded on demand, and which can be developed and deployed by multiple teams at the same time.
As a means of sandboxing all the legacy applications but still displaying them in the context of the same new application, we load them inside an iframe from within which they can communicate with the main SPA using a message bus implemented using the [postMessage()](https://developer.mozilla.org/en-US/docs/Web/API/Window/postMessage) API.
The monorepository
Here’s the directory structure we started out with:
/src /components /scenes /foo /components package.json foo.js /bar /components package.json bar.js package.json index.js
The package.json in the root directory contains a set of devDependencies responsible for development, test and build environment of the whole application, but also contains dependencies of the core of the application (more on that a bit later).
All the larger UI chunks are referred to as scenes. Each scene contains a package.json where dependencies used by that scene’s components are defined. This makes two things possible:
- Deployment updates only the files which have changed
The build step compiles separate vendor and app bundles for each scene, naming each using a hash which will change only when contents of the file have changed. This means our users only download files which have changed since their last visit, and nothing more. - Scenes are loaded only when needed
We load all scenes asynchronously and on demand which drastically improves the load times of the whole application. The “on demand” here usually means visiting a specific route, or performing a UI action which performs a dynamic module import.
Here’s how such setup looks in practice (simplified for readability):
// In src/routes.jsconst FooLoader = AsyncLoadComponent( () => import(‘src/scenes/foo/foo’), GenericPagePreloader,);
<Route path=”/foo” component={FooLoader) />
// In src/scenes/foo/foo.js<React.Suspense fallback={GenericPagePreloader}> <Component /></React.Suspense>
The AsyncLoadComponent is a thin wrapper around [React.lazy()](https://reactjs.org/docs/code-splitting.html#reactlazy), additionally accepting a preloader component, the same one passed through fallback to [React.Suspense()](https://reactjs.org/docs/code-splitting.html#suspense), and a delay after which the preloader should be rendered if the scene hasn’t finished loading.
This is useful when making sure our users see the same preloader without any interruption or flash of content from the moment a scene is requested to the moment when all of its files have been downloaded, all of the critical API requests have completed, and the component has finished rendering.
Component tiers
As each application grows, its directory structure and abstractions evolve along with it. After roughly half a year of building and moving features to the new codebase, having a single components directory proved insufficient.
We needed our directory structure to inform us about:
- Have the components been developed to be generic, or are they meant only for a specific use-case?
- Are they generic enough to be used across all the application, or should they used only in the certain contexts?
- Who’s responsible for and most knowledgable about the code?
Based on that we’ve defined the following Component Tiers:
1. Application-specific (src/app)
Single-use components which cater to specific use-cases within this application, and which are not meant to be re-used or extracted to the component library (routes, footer, page header etc.).
2. Generic (src/components)
Generic multi-purpose components to be used all across the application and its scenes. Once we’ve arrived at a stable API for these components, they could be moved into the common component library (more on that below)
3. Components of a single scene (src/scenes/my-scene/components)
Components developed with a specific use case in mind; not meant to be used in any other scenes. For cases when a component from one scene needs to be used in another one, we’d use:
4. Multi-scene components (src/scenes/components/my-feature)
Components used across multiples scenes, but not meant to be generic enough to be used anywhere else. To illustrate why simply moving them to src/components isn’t good enough:
Imagine that so far you’ve had a single scene which contained components used to build some rather specific data charts. Your team is now building a second scene which will use different data for the charts, but visually the two will look pretty much the same.
Importing components from one scene into another would break the encapsulation of the scene and would mean that we can no longer be certain whether changes made to a single scene’s components only affect that one scene.
For this purpose, any component or group of components, roughly referred to as a feature, would be placed in src/scenes/components from where it can be imported and used by any other team, however:
Whenever a team would like to start using scene components which another team developed, the best practice would be to reach out to that team first to figure out whether the use case you intend these components for can safely be supported in the future. Giving a heads up to the team who originally developed the code will prevent shipping broken features in the future when code you’ve taken into use inevitably gets changed in ways you didn’t expect (because of course, how could you!), and which might not always be caught by the unit tests.
5. Common library
Components which we’ve battle-tested in production and want to extract to our shared component library, used by other dashboard teams at Unity.
Ode to shared dependencies
While it would be very convenient to be able to build and deploy every piece of our application in a fully isolated environment, certain dependencies — both external libraries and internal application code — are simply going to be used all across the codebase. Things like React itself, Redux and all redux-related logic, common navigational components etc.
Rolling out the changes
At the moment, fully encapsulating the scenes isn’t practical and in many cases simply impossible. It would take either shipping many dependencies multiple times over and in the process slowing down pages loads, or building abstractions meant to make certain libraries work in aways they’ve not been designed to.
As the web development and its ecosystem evolves though, the libraries seem to become more and more standalone and encapsulated, which we hope in the future will mean little to no shared dependencies, and true isolation between all the modules.
Perhaps the biggest drawback of authoring large-scale applications is performing code changes and dependency updates without breaking something in the process
Using a monorepository makes it possible (though not mandatory) to roll out changes and updates to the code in more gradual and safe manner — if a change causes issues, these issues will only affect a small part of the application, not the whole system.
And while for some the ability to perform updates on multiple unrelated areas of the codebase at the same time would come off as a benefit, the reality of having multiple teams working on the same codebase and not knowing all the other teams’ features thoroughly means that a great deal of caution is needed when building the application scaffolding and taking measures to minimize the risk of breakage.
How to avoid breaking things
Perhaps the most fundamental strategy which helps us to do so, other than scene isolation, is having a high unit test coverage.
- Testing
The unit tests aren’t of course everything — many mature products on even a moderate scale do after all invest in suites of integration and e2e tests which do a better job at verifying whether the application works as expected overall. However, as the number of features grows so does the maintenance cost and time needed to run them — a cost which cannot always be justified for less crucial but still important features.
Some lessons we’ve learned from various testing strategies:
- Try to unit test as much of the code as possible, especially: conditional logic, data transformations and function calls
- Invest in and leverage integration tests to their full extent before deciding to write any e2e tests. The initial cost of integration tests is much higher, but pales in comparison to the price of upkeep of an e2e suite
- Try not to over-react by starting to write e2e tests for things that weren’t caught by unit or integration tests. Sometimes, the processes or tooling are at fault
- Let test cases explain UI behavior rather than implementation details
- Automated tests cannot fully replace manual testing
2. Minimize the surface of shared code
Aside from testing, code re-used across the whole application is kept to a reasonable minimum. One of the most useful strategies so far has been to move the most commonly used components and code to a shared component library, from where they are used as dependencies in scenes which need them. This allows us to roll out most of the changes progressively, on a per team- or page-basis.
3. Accountability
Last but not least, a huge factor in multiple teams being able to collaborate within the same codebase comes from encouraging and having developers take personal responsibility and accountability for the product, instead of offloading the responsibility for properly testing that everything works to Q.A., testers or automation.
This carries over to code reviews as well. Making sure each change is carefully reviewed is harder than it might seem on the surface. As team works closely together, a healthy degree of trust is developed between its members. This trust however, can sometimes translate into people being less diligent about changes made by the more experienced or otherwise trustworthy developers.
To encourage diligence, we emphasize that the author of the PR and the reviewer are equally responsible for ensuring everything works.
Component library
To achieve the same look and feel across all the pages of our dashboards, we’ve developed a component library. What stands in our approach, is that new components are almost never developed within that library.
Every component, after being developed within the dashboard’s codebase, is taken into use in a bunch of features within that codebase first. Usually after a few weeks we begin to feel more confident that the component could be moved over, given that:
- The API is flexible enough to support the foreseeable use-cases
- The component has been tested in a variety of contexts
- The performance, responsiveness, and UX are all accounted for
This process follows the Rule of Three and aims to help us release only components which are truly reusable and have been taken into use in a variety of contexts before being moved to our common library.
Some of the examples of the components we’d move over would include: footer, page header, side and top navigation elements, layout building blocks, banners, powered-up versions of buttons, typography elements etc.
In the early days, the component library used to be located in the same codebase as the application itself. We’ve since then extracted it to a separate repository to make the development process more democratized for other teams at Unity — important when driving for its adoption.
Modular component design
For the longest time, building reusable components meant dealing with multiple challenges, many of which often didn’t have good solutions:
- How to easily import the component along with its styles, and only that
- How to override default styles without selector specificity wars
- In bigger components consisting of multiple smaller ones, how to override the styling of the smaller component
Our dashboard, as well as our component library heavily depend on and utilize Material UI. What’s uniquely compelling in Material UI’s styling solution is the potential brought by JSS and their Unified Styling Language (well worth the read), which make it possible to develop UIs encapsulated by design like in the case of CSS Modules, and solve of the above mentioned issues in a stride.
This differs significantly from approaches like BEM which provide encapsulation by convention which tend to be less extensible and less encapsulated.
Living styleguide
A component library wouldn’t be complete without a way to showcase the components it contains and being able to see the components as they change throughout the releases.
We’ve had pretty good experience with Storybook which was ridiculously easy to setup and get started with, but after some time we realized a more robust and end-to-end solution was needed. Pretty close to what Styleguidist offers, but more tailored to our needs.
Existing design docs
The documentation serving as the main source of information about the latest design specification was located in Confluence, where designers kept an up-to-date specification for each component using screenshots illustrating permitted use-cases, states and variations the component could be in, listed best practices, as well as details like dimensions, used colors etc. Following that approach we’ve faced a number of challenges:
- Material design specification keeps evolving and because of that we oftentimes found ourselves either spending time on updating all the screenshots and guidelines, or let our design guidelines become outdated
- Figuring out which is more correct: implementation or specification wasn’t always an easy task. Because we’ve been publishing Storybook demos of every component and for every library version, we could see what and how changed. We couldn’t do the same for the design spec.
- Screenshots and videos can only communicate as much. To provide components of high quality and which can be used by multiple teams it’s necessary to review whether each component works in all resolutions, is bug-free and has good UX — this was difficult without having the designer sit literally next to you to see the implementation demo being shown on the screen
Component documentation app
Our documentation app aims to provide the means of efficient collaboration between designers and engineers to make it simpler and less time-consuming for both parties to document, review and develop components. To be more specific, we needed to:
- Have a single point of reference showcasing the components, how should they look, behave, and be used — provided for every release — replacing detailed descriptions with live demos
- Make it as easy for designers and developers to collaborate on components and their docs and do so before the components are released — without the need of sharing videos, screenshots, or being physically in the same location
- Separate the designs into what we plan to do vs what has been done
Similarly like before, each release of the component library causes a new version of the living styleguide to be published. This time over however, there are a few differences:
- Designers contribute to component documentation directly by editing documentation files through the Github UI, committing changes to the latest release.
- Component demos as WYSIWYG — the same code you see as an example of how to implement the component is used to render the demo, including any intermediate file imports, variable declarations etc. As an added bonus, components wrapped in
withStyles()are displayed correctly (issue present in Storybook at the moment). - Changes to the docs and the code are almost instantly visible without checking out the branch locally and starting the documentation app — the app is rebuilt and published on and for every commit.
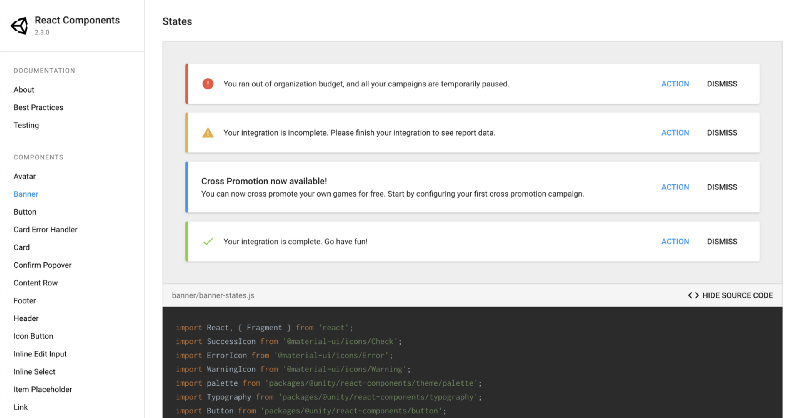
Development experience
One of the main goals of code reviews is making sure that each change is carefully reviewed, considered and tested before being merged and deployed.
To make this task as obstacle-free as possible we’ve developed a Preview Server capable of creating a new build of our application every time a PR is created or updated.
Our designers, product managers and engineers can test each change before merging it in, in both staging and production environments and within minutes of making the change.
Closing words
It’s been nearly a year since we’ve undertaken to consolidate our dashboards. We’ve spent that time learning how to grow a large but healthy software project, how to get better at collaboration and communication, and how to raise the quality bar for ourselves.
We scaled a frontend project not only in terms of lines of code, but also in terms of number of engineers who work within its codebase — a number which quadrupled since the beginning.
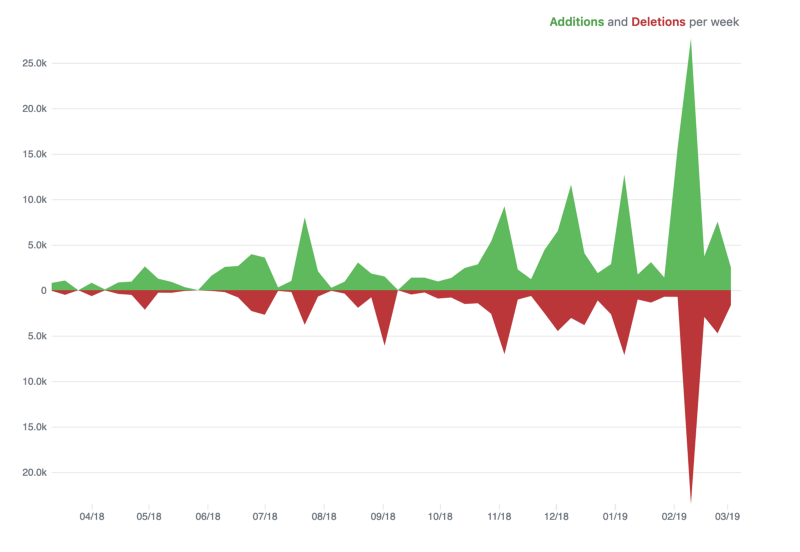
We did a 180 degree change in dealing with time differences between our teams, moving away from a model where our teams worked in full isolation to one where close collaboration and communication are an everyday occurrence.
While we still have a long road ahead to ensure we can scale our approach to more teams and to bigger challenges, we’ve noticed a number of improvements already:
- Roadmap and work visibility
Due to having one place where all the work is happening, the progress gets tracked, and all the issues are gathered in - Development velocity and time-to-market
New features can be created in large part from already existing and well-tested components — easily findable through our documentation app - Code quality & test coverage
When building new things, a solution to a similar problem usually already exists and is at a hand’s reach, along with examples how to test it - Overall quality & UX
Testing features and ensuring their quality is now easier than ever, as designers, product managers and other stakeholders can test each change on their own machine, with their own accounts and data sets
Naturally, along the way we’ve encountered a number of challenges which we need to solve, or which will need solving in the future:
- Build & CI performance
As the numbers of dependencies, build bundles, and tests grow, as does the time needed to do a deployment. In the future, we’ll need to develop tooling to help us only build, test and deploy the pieces which changed. - Development culture
To build healthy software, we need to continuously work on healthy ways of communicating and exchanging ideas, and text-based communications make this task more difficult. We’re working to address this issue through a series regular leadership training sessions and embracing a more open-source ways of working, as well as organizing a few get together sessions per year for the teams to meet each other face to face. - Breakage isolation & updates
As the number of features and pages grows, we’ll need a more robust way of isolating our application modules to prevent damage from spreading for when things go wrong. This could be achieved by versioning all the shared code (redux logic, src/components), or in extreme cases producing standalone builds of certain features.
State then, now and in the future
The migration has involved moving away from AngularJS to React. Here’s how the situation changed over the past year:

It’s a wrap! Thank you for reading! You can find me on LinkedIn here.
If working on similar challenges sounds interesting to you, we’re always looking for talented engineers to join our teams all around the world.