

One of the very interesting and widely used applications of Natural Language Processing is Named Entity Recognition (NER).
Getting insights from raw and unstructured data is of vital importance. Uploading a document and getting the important bits of information from it is called information retrieval.
Information retrieval has always been a major task and challenge in NLP. And we can use NER (or NEL — Named Entity Linking) in several domains like finance, drug research, e-commerce, and more for information retrieval purposes.
In this tutorial post, I’ll show you how you can leverage NEL to develop a custom stock market news feed that lists down the buzzing stocks on the internet.
Pre-requisites
There are no real pre-requisites as such. It would be helpful if you had some familiarity with Python and the basic tasks of NLP like tokenization, POS tagging, dependency parsing, and so on.
I’ll cover the important bits in more detail, so even if you’re a complete beginner you’ll be able to wrap your head around what’s going on.
So, let’s get on with it! Follow along and you’ll have a minimal stock news feed that you can start researching by the end of this tutorial.
What you’ll need to get started:
Google Colab for initial testing and exploration of data and the SpaCy library.
VS Code (or any editor) to code the Streamlit application.
Source of stock market information (news) on which we’ll perform NER and later NEL.
A virtual Python environment (I am using conda) along with libraries like Pandas, SpaCy, Streamlit, Streamlit-Spacy (if you want to show some SpaCy renders.)
Goals of the Project
The goal of this project is to learn and apply Named Entity Recognition to extract important entities (publicly traded companies in our example) and then link each entity with some information using a knowledge base (Nifty500 companies list).
We’ll get the textual data from RSS feeds on the internet and extract the names of buzzing stocks. We'll then pull their market price data to test the authenticity of the news before taking any position in those stocks.
Note: NER may not be a state-of-the-art problem but it has many applications in the industry.
Let's move on to Google Colab for experimentation and testing.
Step 1: How to extract the trending stocks news data
To get some reliable authentic stock market news, I’ll be using the Economic Times and Money Control RSS feeds for this tutorial. But you can also use/add your country’s RSS feeds or Twitter/Telegram (groups) data to make your feed more informative/accurate.
The opportunities are immense. This tutorial should serve as a stepping stone to apply NEL to build apps in different domains solving different kinds of information retrieval problems.
If you go on to look at the RSS feed, it looks something like this:
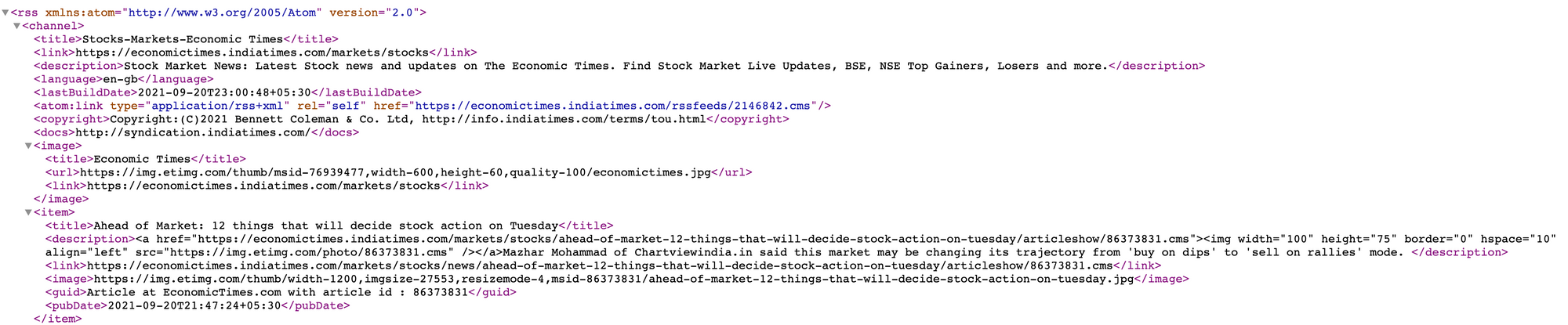
Our goal is to get the textual headlines from this RSS feed and then we’ll use SpaCy to extract the main entities from the headlines.
The headlines are present inside the <title> tag of the XML here.
Firstly, we need to capture the entire XML document and we can use the **requests** library to do that. Make sure you have these packages installed in your runtime environment in colab.
You can run the following command to install almost any package right from a colab’s code cell:
!pip install <package_name>
Send a GET request at the provided link to capture the XML doc.
import requests
resp = requests.get("https://economictimes.indiatimes.com/markets/stocks/rssfeeds/2146842.cms")
Run the cell to check what you get in the response object.
It should give you a successful response with HTTP code 200 as follows:

Now that you have this response object, we can pass its content to the BeautifulSoup class to parse the XML document as follows:
from bs4 import BeautifulSoup
soup = BeautifulSoup(resp.content, features='xml')
soup.findAll('title')
This should give you all the headlines inside a Python list:
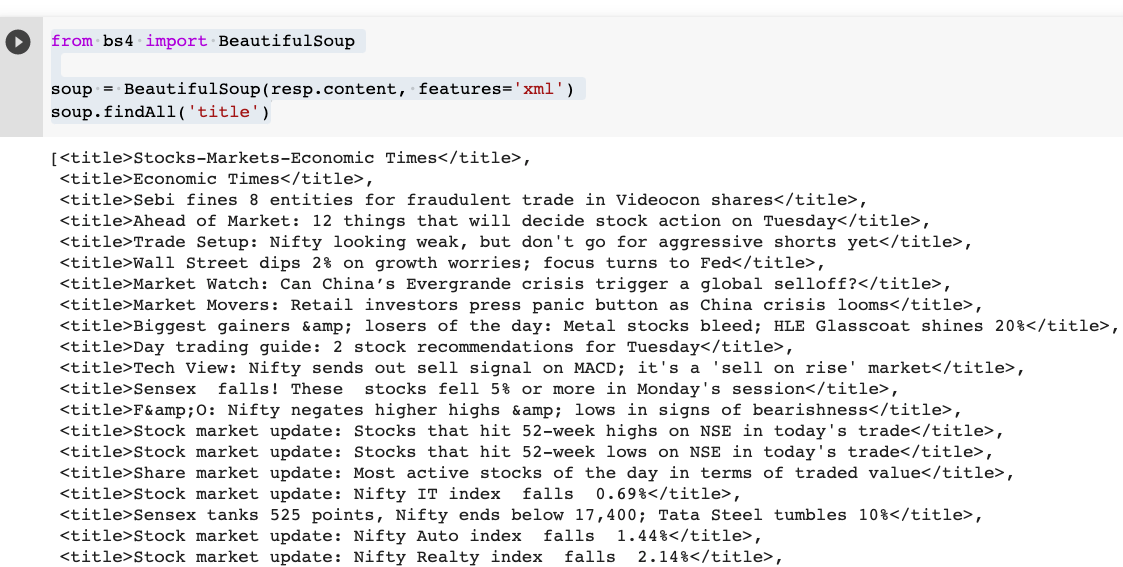
Awesome – we have the textual data out of which we will extract the main entities (which are publicly traded companies in this case) using NLP.
It’s time to put NLP into action.
Step 2: How to extract entities from the headlines
This is the exciting part. We’ll be using a pre-trained core language model from the **spaCy** library to extract the main entities in a headline.
Let's talk a little more about spaCy and the core models.
spaCy is an open-source NLP library that processes textual data at a superfast speed. It is the leading library in NLP research which is being used in enterprise-grade applications at scale.
spaCy is well-known for scaling with the problem. And it supports more than 64 languages and works well with both TensorFlow and PyTorch.
Talking about core models, spaCy has two major classes of pre-trained language models that are trained on different sizes of textual data to give us state-of-the-art inferences.
Core Models — for general-purpose basic NLP tasks.
Starter Models — for niche applications that require transfer learning. We can leverage the model’s learned weights to fine-tune our custom models without having to train the model from scratch.
Since our use case is basic in this tutorial, we are going to stick with the en_core_web_sm core model pipeline.
So, let’s load this into our notebook:
nlp = spacy.load("en_core_web_sm")
Note: Colab already has this downloaded for us, but if you try to run it in your local system, you’ll have to download the model first using the following command:
python -m spacy download en_core_web_sm
en_core_web_sm is basically an English pipeline optimized for CPU which has the following components:
tok2vec — token to vector s(performs tokenization on the textual data),
tagger — adds relevant metadata to each token. spaCy makes use of some statistical models to predict the part of speech (POS) of each token. More in the documentation.
parser — dependency parser establishes relationships among the tokens.
Other components include senter, ner, attribute_ruler, and lemmatizer.
Now, to test what this model can do for us, I’ll pass a single headline through the instantiated model and then check the different parts of a sentence.
# make sure you extract the text out of <title> tags
processed_hline = nlp(headlines[4].text)
The pipeline performs all the tasks from tokenization to NER. Here we have the tokens first:
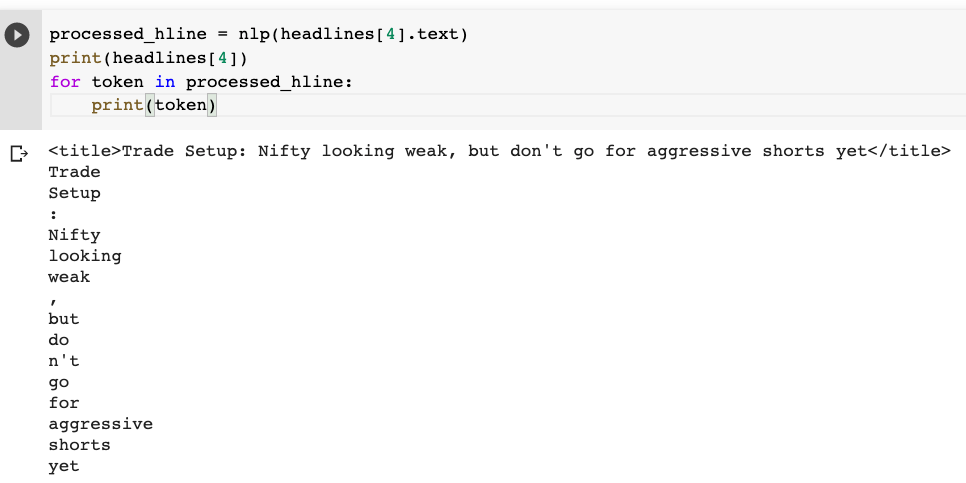
You can look at the tagged part of speech using the pos_ attribute.

Each token is tagged with some metadata. For example, Trade is a Proper Noun, Setup is a Noun, : is punctuation, so on, and so forth. The entire list of Tags is given here.
And then, you can look at how they are related by looking at the dependency graph using the dep_ attribute:
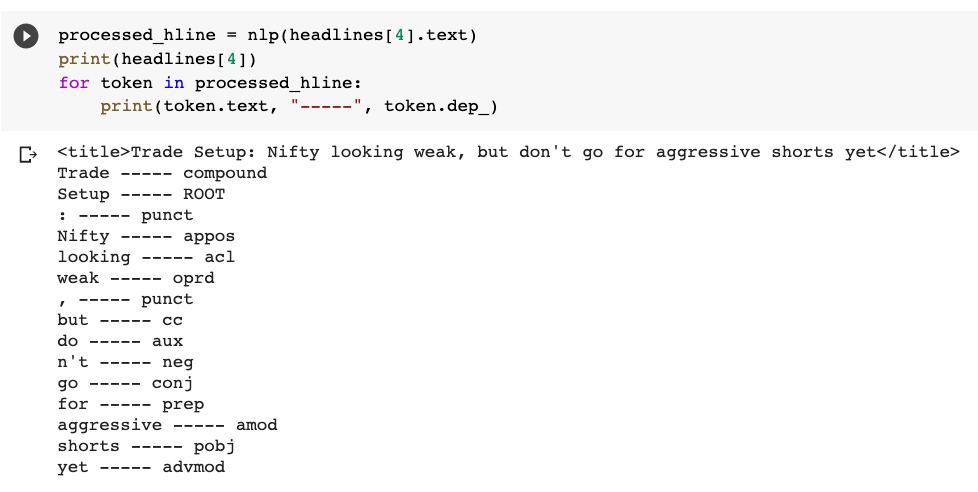
Here, Trade is a Compound, Setup is Root, Nifty is an appos (Appositional modifier). Again, all the syntactic tags can be found here.
You can also visualize the relationship dependencies among the tokens using the following displacy render() method:
spacy.displacy.render(processed_hline, style='dep',
jupyter=True, options={'distance': 120})
which will give this graph:
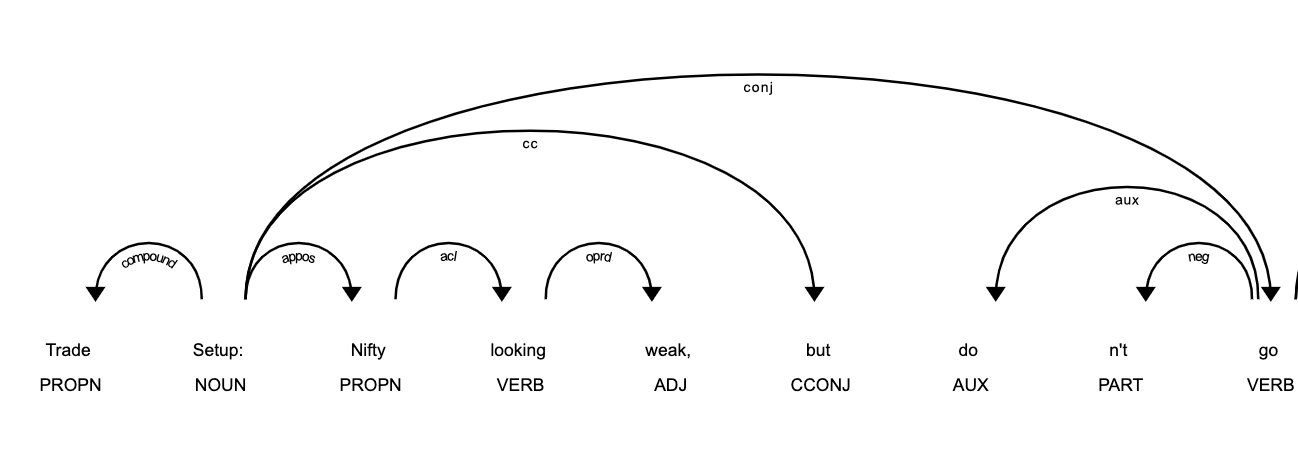
Entity extraction
And to look at the important entities of the sentence, you can pass **'ent’** as style in the same code:

We have different tags for different entities like the day has DATE, and Glasscoat has GPE which can be Countries/Cities/States. We are primarily looking for entities that have the ORG tag that’ll give us Companies, agencies, institutions, and so on.
We are now capable of extracting entities from the text. Let’s get down to extracting the organizations from all the headlines using ORG entities.
ent.py
companies = []
for title in headlines:
doc = nlp(title.text)
for token in doc.ents:
if token.label_ == 'ORG':
companies.append(token.text)
else:
pass
This will return a list of all the companies as follows:
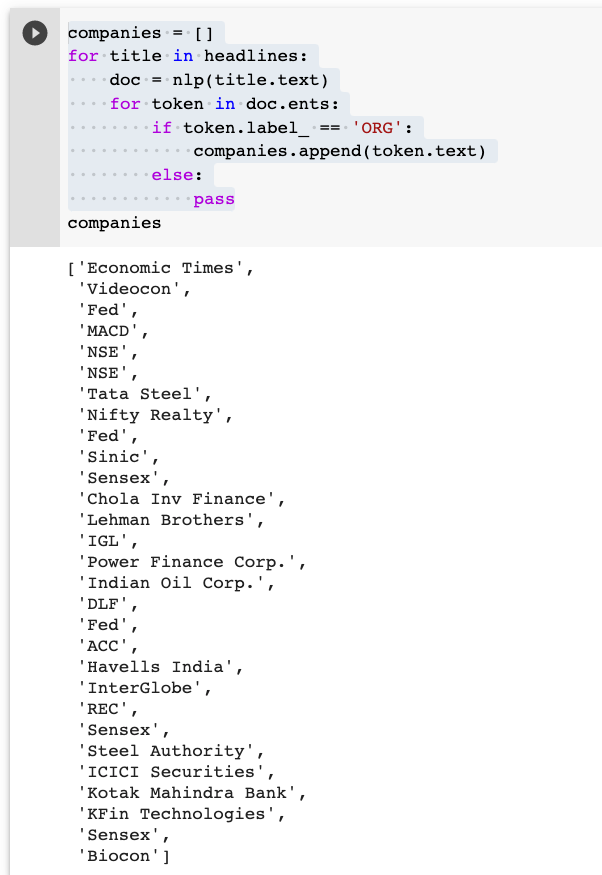
So easy, right?
That’s the magic of spaCy now!
The next step is to look up all these companies in a knowledge base to extract the right stock symbol for that company. Then we'll use libraries like yahoo-finance to extract their market details like price, return, and so on.
Step 3 — Named Entity Linking
Learning about what stocks are buzzing in the market and getting their details on your dashboard are the goals for this project.
We have the company names, but in order to get their trading details, we’ll need the company’s trading stock symbol.
Since I am extracting the details and news of Indian Companies, I am going to use an external database of Nifty 500 companies (a CSV file).
For every company, we’ll look it up in the list of companies using pandas, and then we’ll capture the stock market statistics using the yahoo-finance library.
import yfinance as yf
## collect various market attributes of a stock
stock_dict = {
'Org': [],
'Symbol': [],
'currentPrice': [],
'dayHigh': [],
'dayLow': [],
'forwardPE': [],
'dividendYield': []
}
## for each company look it up and gather all market data on it
for company in companies:
try:
if stocks_df['Company Name'].str.contains(company).sum():
symbol = stocks_df[stocks_df['Company Name'].\
str.contains(company)]['Symbol'].values[0]
org_name = stocks_df[stocks_df['Company Name'].\
str.contains(company)]['Company Name'].values[0]
stock_dict['Org'].append(org_name)
stock_dict['Symbol'].append(symbol)
stock_info = yf.Ticker(symbol+".NS").info
stock_dict['currentPrice'].append(stock_info['currentPrice'])
stock_dict['dayHigh'].append(stock_info['dayHigh'])
stock_dict['dayLow'].append(stock_info['dayLow'])
stock_dict['forwardPE'].append(stock_info['forwardPE'])
stock_dict['dividendYield'].append(stock_info['dividendYield'])
else:
pass
except:
pass
## create a dataframe to display the buzzing stocks
pd.DataFrame(stock_dict)
One thing that you should notice here is that I’ve added a “.NS” after each stock symbol before passing it to the Ticker class of the yfinance library. This is because Indian NSE stock symbols are stored with a .NS suffix in yfinance.
And the buzzing stocks would turn up in a dataframe like below:
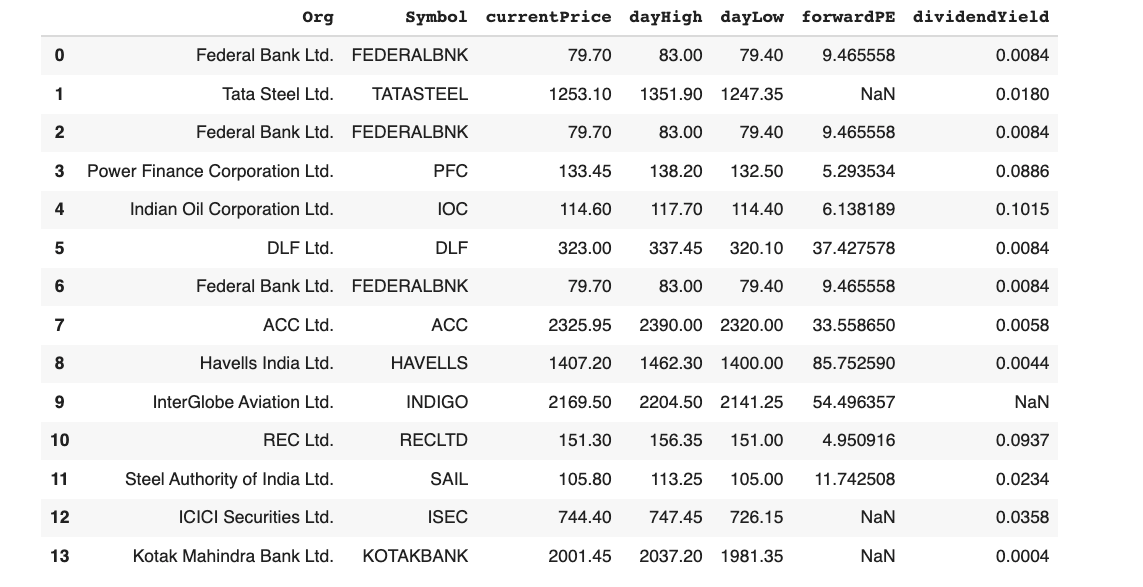
Voilà! Isn’t this great? Such a simple yet profound app that could point you in the right direction with the right stocks.
Now to make it more accessible, we can create a web application out of the code that we have just written using Streamlit.
Step 4 — How to build a web app using Streamlit
It’s time to move to an editor and create a new project and virtual environment for the NLP application.
Getting started with Streamlit is super easy for such demo data applications. Make sure you have streamlit installed.
pip install Streamlit
Now, let’s create a new file called app.py and start writing functional code to get the app ready.
Import all the required libraries at the top like this:
import pandas as pd
import requests
import spacy
import streamlit as st
from bs4 import BeautifulSoup
import yfinance as yf
Add a title to your application:
st.title('Buzzing Stocks :zap:')
Test your app by running streamlit run app.py in your terminal. It should open up an app in your web browser.
I have added some extra functionality to capture data from multiple sources. Now, you can add an RSS feed URL of your choice into the application and the data will be processed and the trending stocks will be displayed in a dataframe.
To get access to the entire code base, you can check out my repository here:
https://github.com/dswh/NER_News_Feed
If you want to follow me step-by-step, watch me code this application here:
You can add multiple styling elements, different data sources, and other types of processing to make it more efficient and useful.
My app in its current state looks like the image in the banner.
Next Steps
Instead of picking a financial use case, you can also pick any other application of your choice – healthcare, e-commerce, research, and many others. All industries require documents to be processed and important entities to be extracted and linked. Try out another idea.
A simple idea is extracting all the important entities of a research paper and then creating a knowledge graph of it using the Google Search API.
Also, if you want to take the stock news feed app to another level, you can add some trading algorithms to generate buy and sell signals as well.
I encourage you to go wild with your imagination.
How you can connect with me
If you liked this post and would like to see more of such content, you can subscribe to my newsletter or my YouTube channel where I’ll keep sharing such useful and quick projects that one can build.
If you’re someone who is just getting started with programming or want to get into data science or ML, you can check out my course at WIP Lane Academy.