
By Alex Nadalin
An Introduction to Web Application Security

Let’s open this series on Web Application Security with an explanation of what browsers do and how they do it. Since most of your customers will interact with your web application through a browser, it’s imperative to understand the basics of these wonderful programs.
The browser is a rendering engine. Its job is to download a web page and render it in a way that’s understandable by a human being.
Even though this is an almost-criminal oversimplification, it’s all we need to know for now.
- The user enters an address in the browser bar.
- The browser downloads the “document” at that URL and renders it.
You might be used to working with one of the most popular browsers such as Chrome, Firefox, Edge or Safari, but that does not mean that there aren’t different browsers out there.
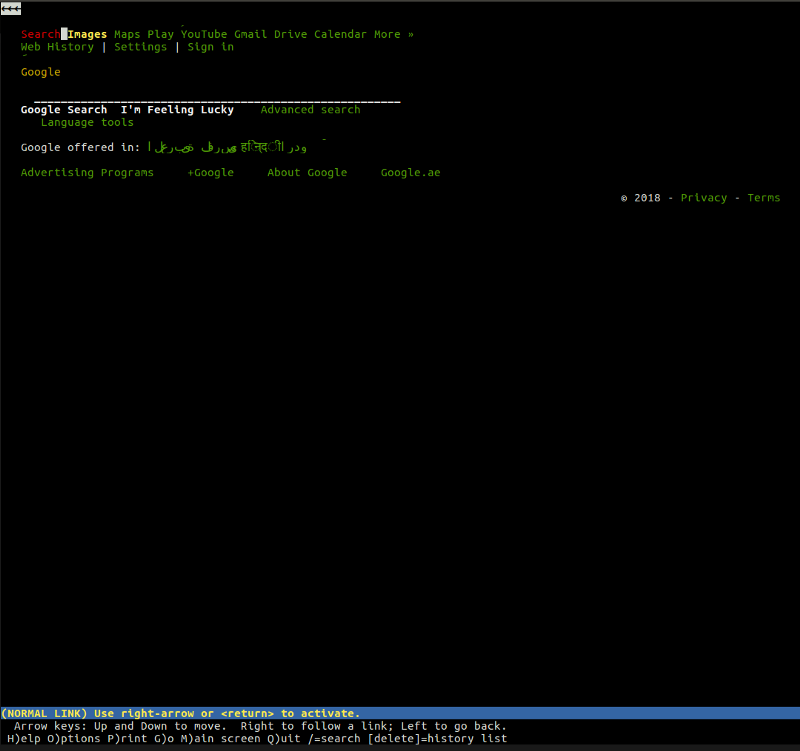
lynx, for example, is a lightweight, text-based browser that works from your command line. At the heart of lynx lies the same exact principles that you would find in any other “mainstream” browsers. A user enters a web address (URL), the browser fetches the document and renders it — the only difference being the fact that lynx does not use a visual rendering engine but rather a text-based interface, which makes websites like Google look like this:
We broadly understand what a browser does, but let’s take a closer look at the steps these ingenious applications do for us.
What does a browser do?
Long story short, a browser’s job mainly consists of:
- DNS resolution
- HTTP exchange
- Rendering
- Rinse and repeat
DNS Resolution
This process makes sure that once the user enters a URL, the browser knows which server it has to connect to. The browser contacts a DNS server to find that google.com translates to 216.58.207.110, an IP address the browser can connect to.
HTTP Exchange
Once the browser has identified which server is going to serve our request, it will initiate a TCP connection with it and begin the HTTP exchange. This is nothing but a way for the browser to communicate with the server what it needs, and for the server to reply back.
HTTP is simply the name of the most popular protocol for communicating on the web, and browsers mostly talk via HTTP when communicating with servers. An HTTP exchange involves the client (our browser) sending a request, and the server replying back with a response.
For example, after the browser has successfully connected to the server behind google.com, it will send a request that looks like the following:
GET / HTTP/1.1Host: google.comAccept: */*
Let’s break the request down, line by line:
GET / HTTP/1.1: with this first line, the browser asks the server to retrieve the document at the location/, adding that the rest of the request will follow the HTTP/1.1 protocol (it could also use1.0or2)Host: google.com: this is the only HTTP header mandatory in HTTP/1.1. Since the server might serve multiple domains (google.com,google.co.uk, etc) the client here mentions that the request was for that specific hostAccept: */*: an optional header, where the browser is telling the server that it will accept any kind of response back. The server could have a resource that’s available in JSON, XML or HTML formats, so it can pick whichever format it prefers
After the browser, which acts as a client, is done with its request, it’s the turn of the server to reply back. This is what a response looks like:
HTTP/1.1 200 OKCache-Control: private, max-age=0Content-Type: text/html; charset=ISO-8859-1Server: gwsX-XSS-Protection: 1; mode=blockX-Frame-Options: SAMEORIGINSet-Cookie: NID=1234; expires=Fri, 18-Jan-2019 18:25:04 GMT; path=/; domain=.google.com; HttpOnly
<!doctype html><html">......</html>
Whoa, that’s a lot of information to digest. The server lets us know that the request was successful (200 OK) and adds a few headers to the response, for example, it advertises what server processed our request (Server: gws), what’s the X-XSS-Protection policy of this response and so on and so forth.
Right now, you do not need to understand each and every single line in the response. We’ll be covering the HTTP protocol, its headers, and so on later on in this series.
For now, all you need to understand is that the client and the server are exchanging information and that they do so via HTTP.
Rendering
Last, but not least, the rendering process. How good would a browser be if the only thing it would show to the user is a list of funny characters?
<!doctype html><html">......</html>
In the body of the response, the server includes the representation of the response according to the Content-Type header. In our case, the content type was set to text/html, so we are expecting HTML markup in the response — which is exactly what we find in the body.
This is where a browser truly shines. It parses the HTML, loads additional resources included in the markup (for example, there could be JavaScript files or CSS documents to fetch) and presents them to the user as soon as possible.
Once more, the end result is something the average Joe can understand.
For a more detailed version of what really happens when we hit enter in the address bar of a browser I would suggest to read “What happens when…”, a very elaborate attempt at explaining the mechanics behind the process.
Since this is a series focused on security, I am going to drop a hint on what we’ve just learned: attackers easily make a living out of vulnerabilities in the HTTP exchange and rendering part. Vulnerabilities, and malicious users, lurk elsewhere as well, but a better security approach on those levels already allows you to make strides in improving your security posture.
Vendors
The 4 most popular browser out there belong to different vendors:
- Chrome by Google
- Firefox by Mozilla
- Safari by Apple
- Edge by Microsoft
Beside battling each other in order to increase their market penetration, vendors also engage with each other in order to improve web standards, which are a sort of “minimum requirements” for browsers.
The W3C is the body behind the development of the standards, but it’s not unusual for browsers to develop their own features that eventually make it as web standards, and security is no exception to that.
Chrome 51, for example, introduced SameSite cookies, a feature that would allow web applications to get rid of a particular type of vulnerability known as CSRF (more on this later). Other vendors decided this was a good idea and followed suit, leading to SameSite being a web standard: as of now, Safari is the only major browser without SameSite cookie support.

This tells us 2 things:
- Safari does not seem to care enough about their users’ security (just kidding: SameSite cookies will be available in Safari 12, which might have already been released by the time you’re reading this article)
- patching a vulnerability on one browser does not mean that all your users are safe
The first point is a shot at Safari (as I mentioned, just kidding!), while the second point is really important. When developing web applications, we don’t just need to make sure that they look the same across various browsers, but also that they ensure our users are protected in the same way across platforms.
Your strategy towards web security should vary according to what a browser’s vendor allows us to do. Nowadays, most browsers support the same set of features and rarely deviate from their common roadmap, but instances like the one above still happen, and it’s something we need to take into account when defining our security strategy.
In our case, if we decide that we’re going to mitigate CSRF attacks only through SameSite cookies, we should be aware that we’re putting our Safari users at risk. And our users should know that too.
Last but not least, you should remember that you can decide whether to support a browser version or not: supporting each and every browser version would be impractical (think of Internet Explorer 6). Making sure that the last few versions of the major browsers are supported, though, is generally a good decision. If you don’t plan to offer protection on a particular platform, though, it’s generally advisable to let your users know.
Pro Tip: You should never encourage your users to use outdated browsers, or actively support them. Even though you might have taken all the necessary precautions, other web developers may have not. Encourage users to use the latest supported version of one of the major browsers.
Vendor or standard bug?
The fact that the average user accesses our application through a 3rd party client (the browser) adds another level of indirection towards a clear, secure browsing experience: the browser itself might present a security vulnerability.
Vendors generally provide rewards (aka bug bounties) to security researchers who can find a vulnerability on the browser itself. These bugs are not tied to your implementation, but rather to how the browser handles security on its own.
The Chrome reward program, for example, lets security engineers reach out to the Chrome security team to report vulnerabilities they have found. If these vulnerabilities are confirmed, a patch is issued, a security advisory notice is generally released to the public, and the researcher receives a (usually financial) reward from the program.
Companies like Google invest a relatively good amount of capital into their Bug Bounty programs, as it allows them to attract researchers by promising a financial benefit should they find any problem with the application.
In a Bug Bounty program, everyone wins: the vendor manages to improve the security of its software, and researchers get paid for their findings. We will discuss these programs later on, as I believe Bug Bounty initiatives deserve their own section in the security landscape.
Jake Archibald is a developer advocate at Google who recently discovered a vulnerability impacting more than one browser. He documented his efforts, how he approached different vendors, and their reactions in an interesting blog post that I’d recommend you read.
A browser for developers
By now, we should have understood a very simple but rather important concept: browsers are simply HTTP clients built for the average internet surfer.
They are definitely more powerful than a platform’s bare HTTP client (think of NodeJS’s require('http'), for example), but at the end of the day, they’re “just” a natural evolution of simpler HTTP clients.
As developers, our HTTP client of choice is probably cURL by Daniel Stenberg, one of the most popular software programs web developers use on a daily basis. It allows us to do an HTTP exchange on-the-fly, by sending an HTTP request from our command line:
$ curl -I localhost:8080
HTTP/1.1 200 OKserver: ecstatic-2.2.1Content-Type: text/htmletag: "23724049-4096-"2018-07-20T11:20:35.526Z""last-modified: Fri, 20 Jul 2018 11:20:35 GMTcache-control: max-age=3600Date: Fri, 20 Jul 2018 11:21:02 GMTConnection: keep-alive
In the example above, we have requested the document at localhost:8080/, and a local server replied successfully.
Rather than dumping the response’s body to the command line, here we’ve used the -I flag which tells cURL we’re only interested in the response headers. Taking it one step forward, we can instruct cURL to dump a little more information, including the actual request it performs, so that we can have a better look at this whole HTTP exchange. The option we need to use is -v (verbose):
$ curl -I -v localhost:8080* Rebuilt URL to: localhost:8080/* Trying 127.0.0.1...* Connected to localhost (127.0.0.1) port 8080 (#0)> HEAD / HTTP/1.1> Host: localhost:8080> User-Agent: curl/7.47.0> Accept: */*>< HTTP/1.1 200 OKHTTP/1.1 200 OK< server: ecstatic-2.2.1server: ecstatic-2.2.1< Content-Type: text/htmlContent-Type: text/html< etag: "23724049-4096-"2018-07-20T11:20:35.526Z""etag: "23724049-4096-"2018-07-20T11:20:35.526Z""< last-modified: Fri, 20 Jul 2018 11:20:35 GMTlast-modified: Fri, 20 Jul 2018 11:20:35 GMT< cache-control: max-age=3600cache-control: max-age=3600< Date: Fri, 20 Jul 2018 11:25:55 GMTDate: Fri, 20 Jul 2018 11:25:55 GMT< Connection: keep-aliveConnection: keep-alive
<* Connection #0 to host localhost left intact
Just about the same information is available in mainstream browsers through their DevTools.
As we’ve seen, browsers are nothing more than elaborate HTTP clients. Sure, they add an enormous amount of features (think of credential management, bookmarking, history, etc) but the truth is that they were born as HTTP clients for humans. This is important, as in most cases you don’t need a browser to test your web application’s security, as you can simply “curl it” and have a look at the response.
One final thing that I’d like to point out, is that anything can be a browser. If you have a mobile application that consumes APIs through the HTTP protocol, then the app is your browser — it just happens to be a highly customized one you built yourself, one that only understands a specific type of HTTP responses (from your own API).
Into the HTTP protocol
As we mentioned, the HTTP exchange and rendering phases are the ones that we’re mostly going to cover, as they provide the largest number of attack vectors for malicious users.
In the next article, we’re going to take a deeper look at the HTTP protocol and try to understand what measures we should take in order to secure HTTP exchanges.
Originally published at odino.org (29 July 2018).
_You can follow me on Twitter - rants are welcome!_ ?