

You read that right – you can practice web scraping without leaving your happy place: Google Sheets.
Google Sheets has five built-in functions that help you import data from other sheets and other web pages. We'll walk through all of them in order from easiest (most limited) to hardest (most powerful).
Here they are, and you can click each function to skip down to its dedicated section. I've made a video as well that walks through everything:
Section Shortcuts
- How to use the IMPORTRANGE function
- How to use the IMPORTDATA function
- How to use the IMPORTFEED function
- How to use the IMPORTHTML function
- How to use the IMPORTXML function
Here's the Google Sheet we'll be using to demo each function.
If you'd like to edit it, make a copy by selecting File - Make a copy when you open it.
 screenshot of Google Sheet
screenshot of Google Sheet
How to use the IMPORTRANGE function
This is the only function that imports a range from another sheet rather than data from another web page. So, if you've got another Google Sheet, you can link the two sheets together and import the data you need from one sheet into the other sheet.
For instance, here's a sheet with a bunch of random Samsung Galaxy data in it.
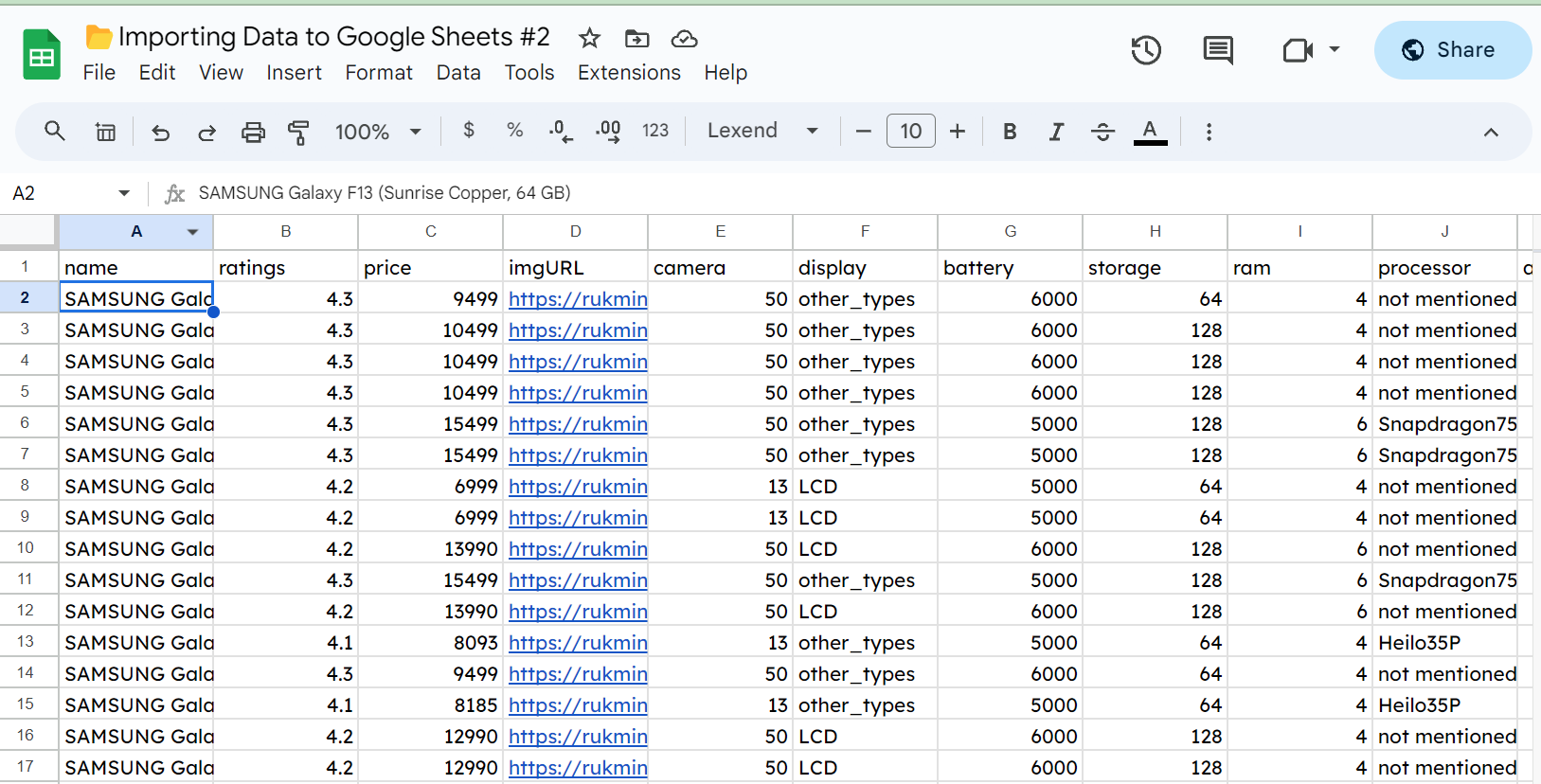
You can see that we have a few hundred rows of data about phones. If we want to import this data into another spreadsheet, we can use IMPORTRANGE(). This is the simplest to use of the five functions we'll look at. All it needs is a URL for a Google Sheet and the range we want to import.
Check out the tab for IMPORTRANGE in the Google Sheet here, and you'll see that in cell A5, we've got the function =IMPORTRANGE(B4,"data!a1:K"). This is pulling in the range A1:K from the data tab of our second spreadsheet whose URL is in cell B4.
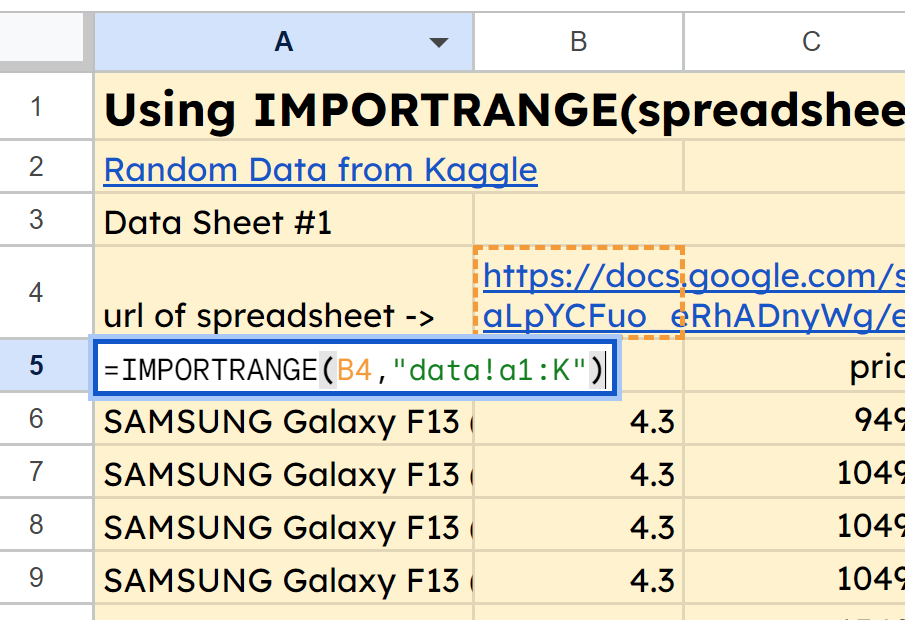 screenshot of IMPORTRANGE function
screenshot of IMPORTRANGE function
Once your data is pulled into your spreadsheet, you can do one of two things.
- Leave it linked through the
IMPORTRANGEfunction. This way, if your data source is going to be updated, you'll pull in the updated data. - Copy and CTRL+SHIFT+V to paste values only. This way, you have the raw data in your new spreadsheet and you won't have to be dependent on something changing with the URL down the road.
How to use the IMPORTDATA function
This is pretty straightforward. It'll import .csv or .tsv data from anywhere on the internet. These stand for Comma Separated Values and Tab Separated Values.
.csv is the most commonly used file type for financial data that needs to be imported into spreadsheets and other programs.
Like IMPORTRANGE, we only need a couple pieces of information for IMPORTDATA: the URL where the file lives, and the delimiter. There's also an optional variable for locale, but I found that it was unnecessary.
In fact, Google Sheets is pretty smart – you can leave off the delimiter too, and it will usually decipher what type of data (.csv or .tsv) lives at the URL.
You can see that I've found a New York government data website where there lives some winning lottery number data. I've put the URL for a .csv file in A5, and then used the function =IMPORTDATA(A5,",") to pull in the data from the .csv file.
 Screenshot of IMPORTDATA function
Screenshot of IMPORTDATA function
You could alternatively download the .csv file and then select File - Import to bring in this data. But in the event that you do not have download permissions or simply want to get it straight from a site, IMPORTDATA works great.
How to use the IMPORTFEED function
This imports RSS feed data. If you're familiar with podcasting, you may recognize the term. Every podcast has an RSS feed which is a structured file full of XML data.
Using the URL for the RSS feed, IMPORTFEED will pull in data about a podcast, news article, or blog from its RSS information.
This is the first function that begins to have a few more options at its disposal, too.
All that's required is the URL of a feed, and it'll bring in data from that feed. However, we can specify a few other parameters if we like. The options include:
- [query]: this specifies which pieces of data to pull from the feed. We can select from options like "feed " where type can be title, description, author or URL. Same deal with "items " where type can be title, summary, URL or created.
- [headers]: this will either bring in headers (TRUE) or not (FALSE)
- [num_items]: this will specify how many items to return when using Query. (The docs state that if this isn't specified, all items currently published are returned, but I did not find this to be the case. I had to specify a larger number to get back more than a dozen or so).
You can see from the screenshots below that I am querying one of my feeds to pull in the episode titles and URLs.
First, to get all the titles, I used IMPORTFEED(A3, "items title", TRUE, 50:
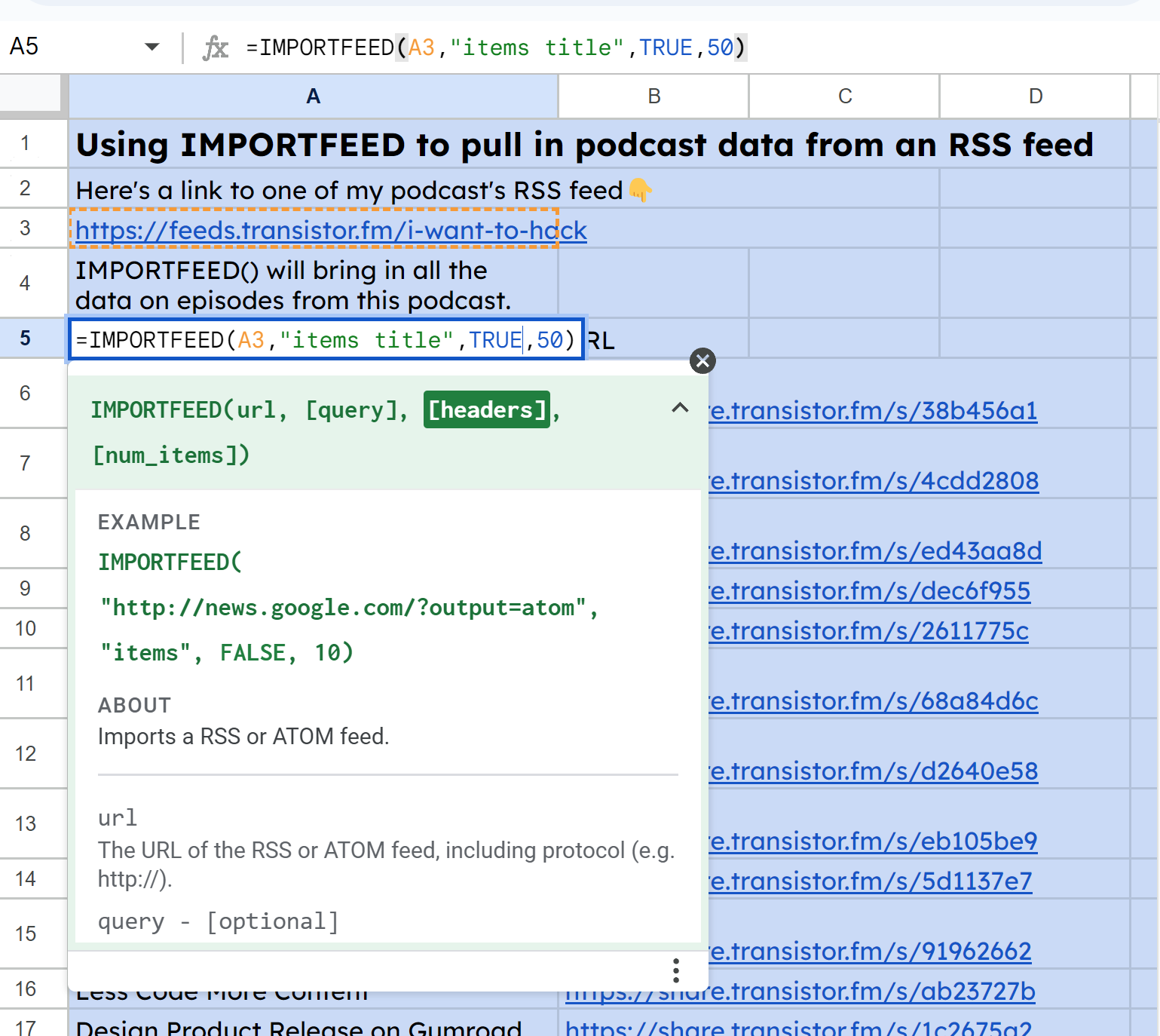 Screenshot of IMPORTFEED
Screenshot of IMPORTFEED
Then, similarly for the URLs, I used IMPORTFEED(A3, "items url", TRUE, 50):
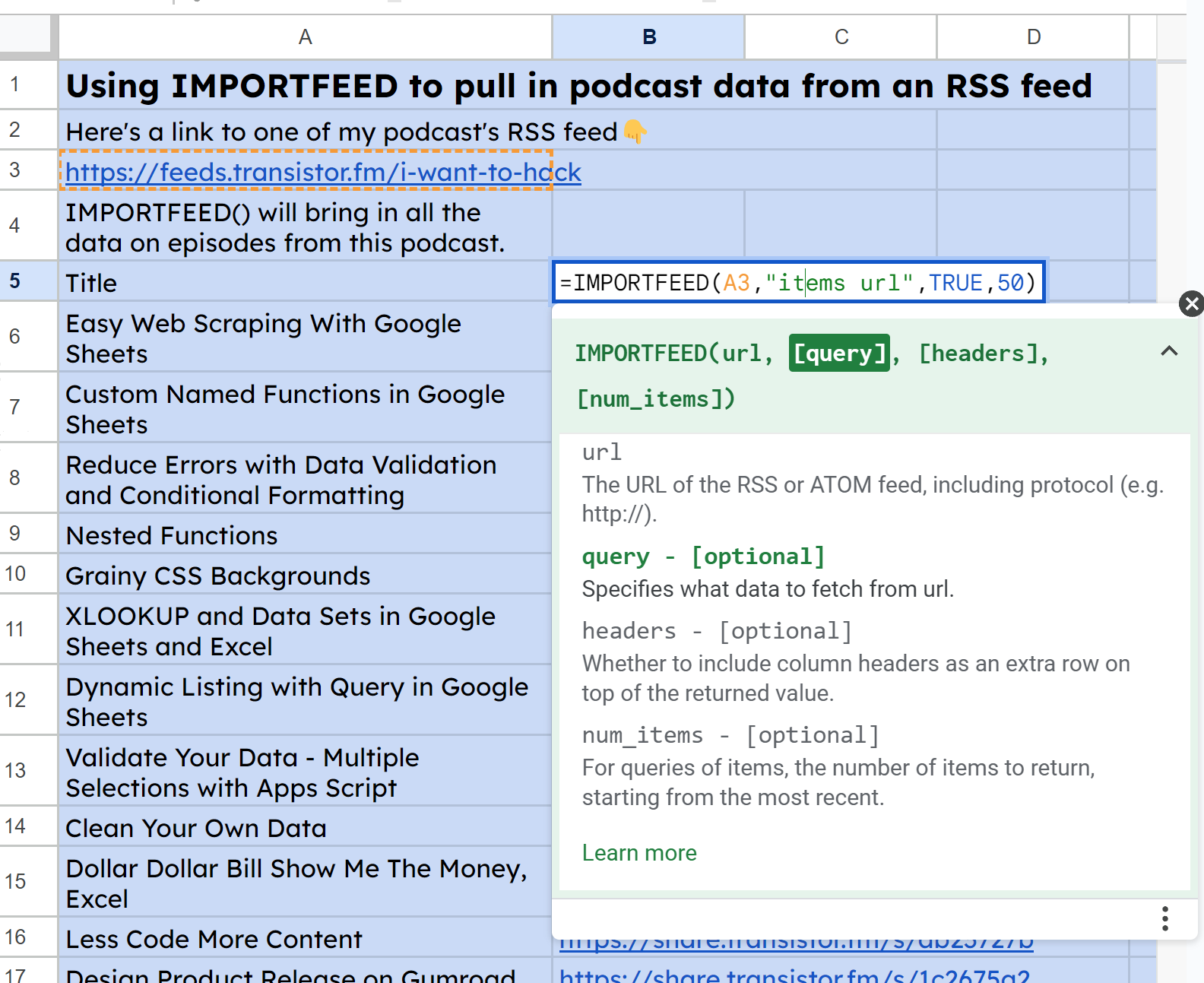 Screenshot of IMPORTFEED #2
Screenshot of IMPORTFEED #2
How to use the IMPORTHTML function
Now we're getting into scraping data straight off of a web site. This will take a URL and then a query parameter where we specify to look for either a "table" or a "list".
This is followed by an index value representing which table or list to look for if there are multiple on the page. It is zero indexed, so input zero if you're looking for the first one.
IMPORTHTML looks through the HTML code on a website for <table> and <list> HTML elements.
<!--Here's what a simple table looks like:-->
<table>
<thead>
<tr>
<th>table header 1</th>
<th>table header 2</th>
</tr>
</thead>
<tbody>
<tr>
<td>table data row 1 cell1</td>
<td>table data row 1 cell2</td>
</tr>
<tr>
<td>table data row 2 cell1</td>
<td>table data row 2 cell2</td>
</tr>
</tbody>
</table>
<!--Here's what an ordered list looks like:-->
<ol>
<li>ordered item 1</li>
<li>ordered item 2</li>
<li>ordered item 2</li>
</ol>
<!--Here's what an unordered list looks like:-->
<ul>
<li>unordered item 1</li>
<li>unordered item 2</li>
<li>unordered item 3</li>
</ul>
In the sample sheet, I've got the URL for some stats about the Barkley Marathons in cell B3 and am then referencing that in A4's function: =IMPORTHTML(B3,"table",0).
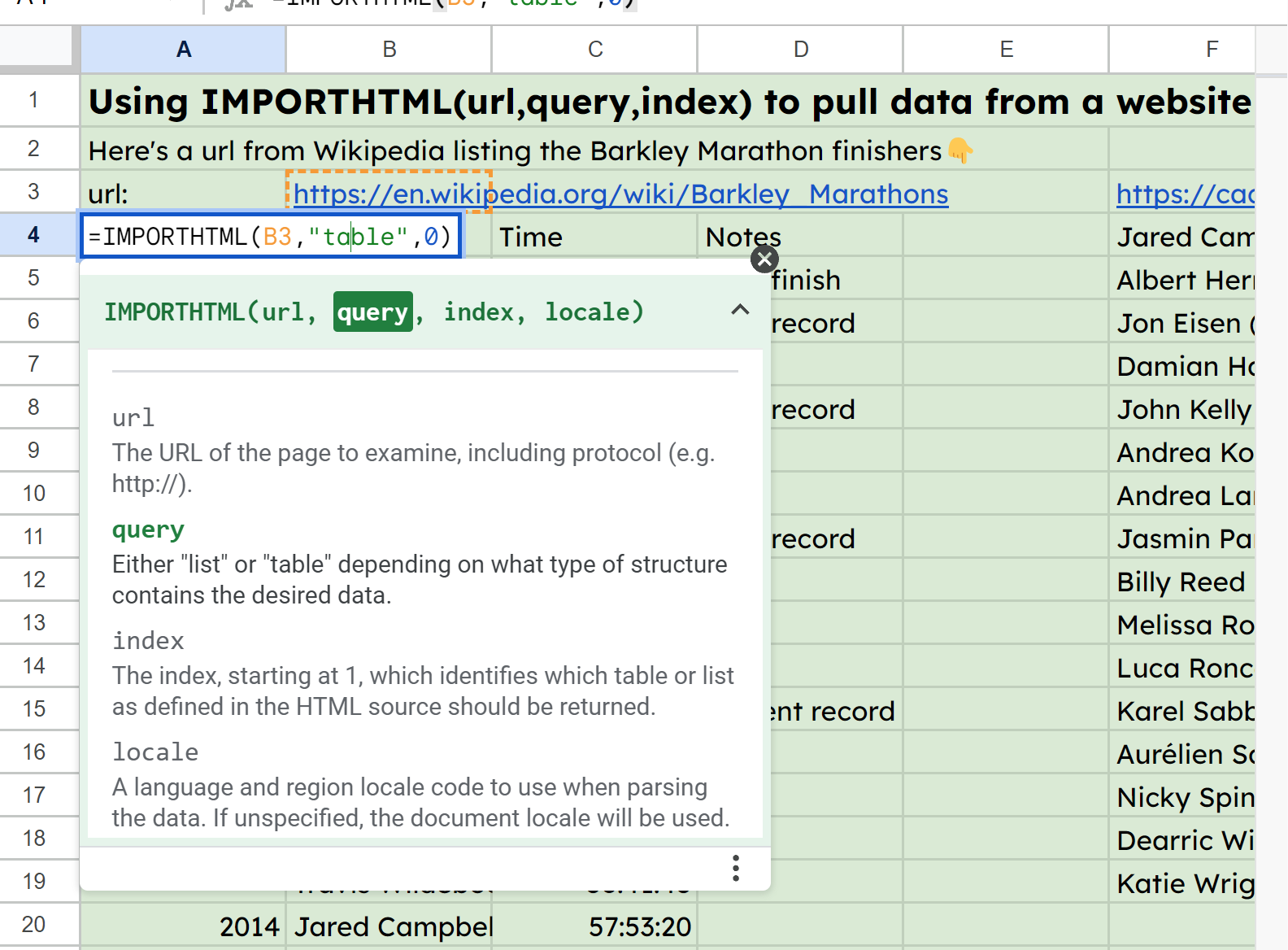 Screenshot of IMPORTHTML
Screenshot of IMPORTHTML
FYI, freeCodeCamp created ScrapePark as a place to practice web scraping, so you can use it for IMPORTHTML and IMPORTXML coming up next👇.
How to use the IMPORTXML function
We saved the best for last. This will look through websites and scrape darn near anything we want it too. It's complicated, though, because instead of importing all the table or list data like with IMPORTHTML, we write our queries using what's called XPath.
XPath is an expression language itself used to query XML documents. We can write XPath expressions to have IMPORTXML scrape all kinds of things from an HTML page.
There are many resources to find the proper XPath expressions. Here's one that I used for this project.
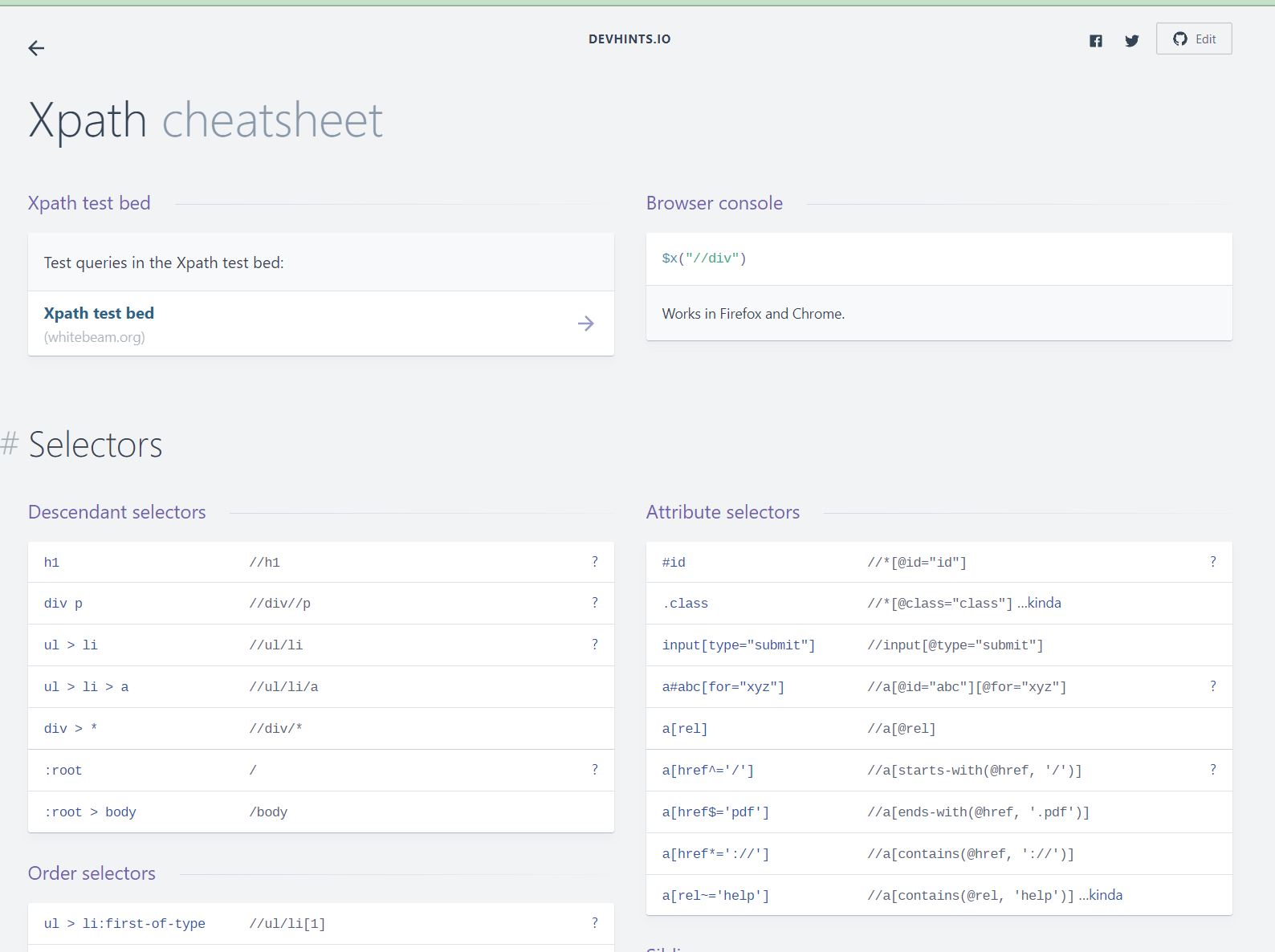 screenshot of XPath cheat sheet
screenshot of XPath cheat sheet
In the sheet for IMPORTHTML, I have several examples that I encourage you to click through and check out.
For example, using the function =IMPORTXML(A11,"//*[@class='post-card-title']") allows us to bring in all the titles of my articles because from inspecting the HTML on my author page here, I found that they all have the class post-card-title.
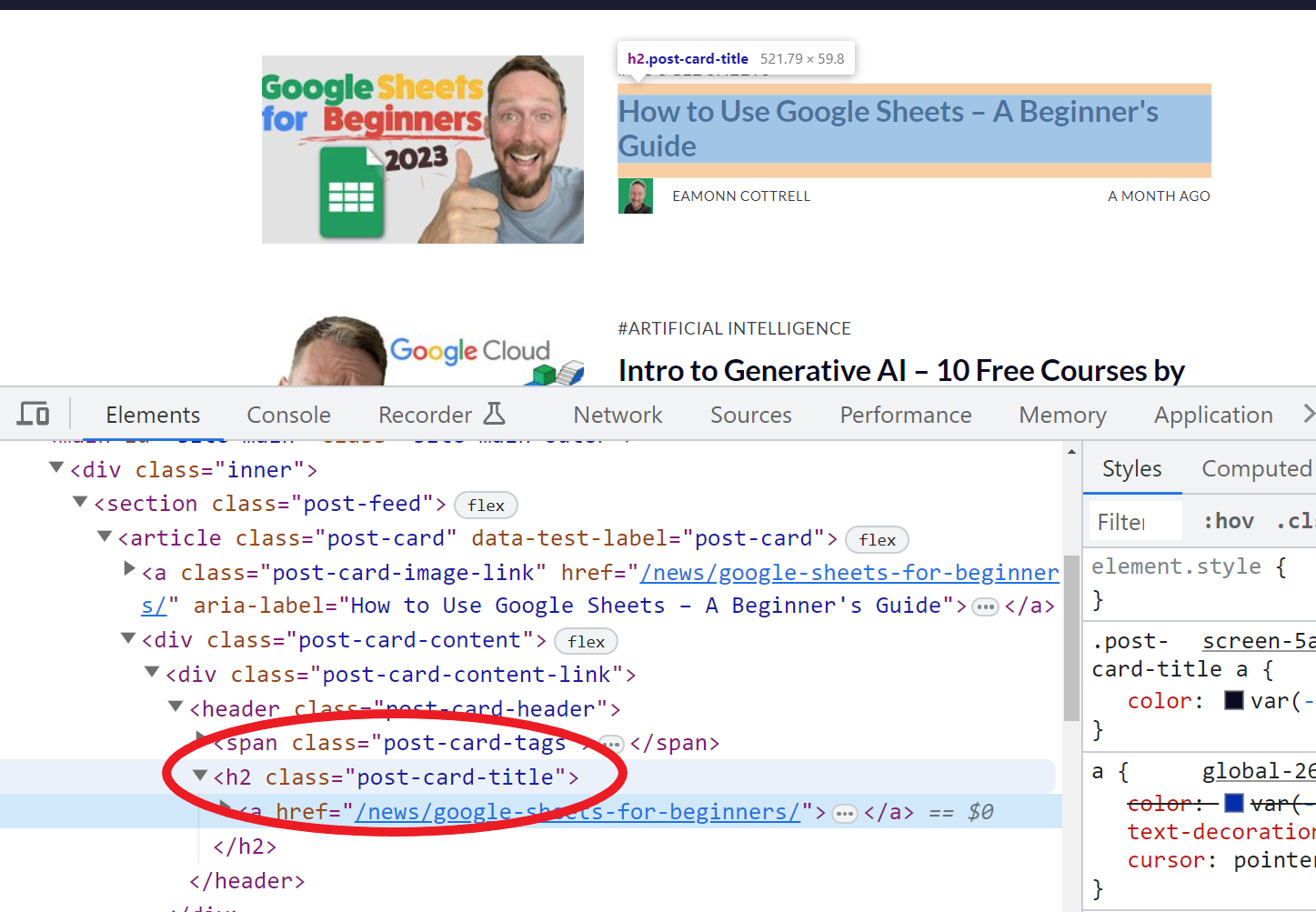 screenshot of inspecting a web page with dev tools
screenshot of inspecting a web page with dev tools
In the same way, we can use the function =IMPORTXML(A11,"//*[@class='post-card-title']//a/@href") to grab the URL slug of each of those articles.
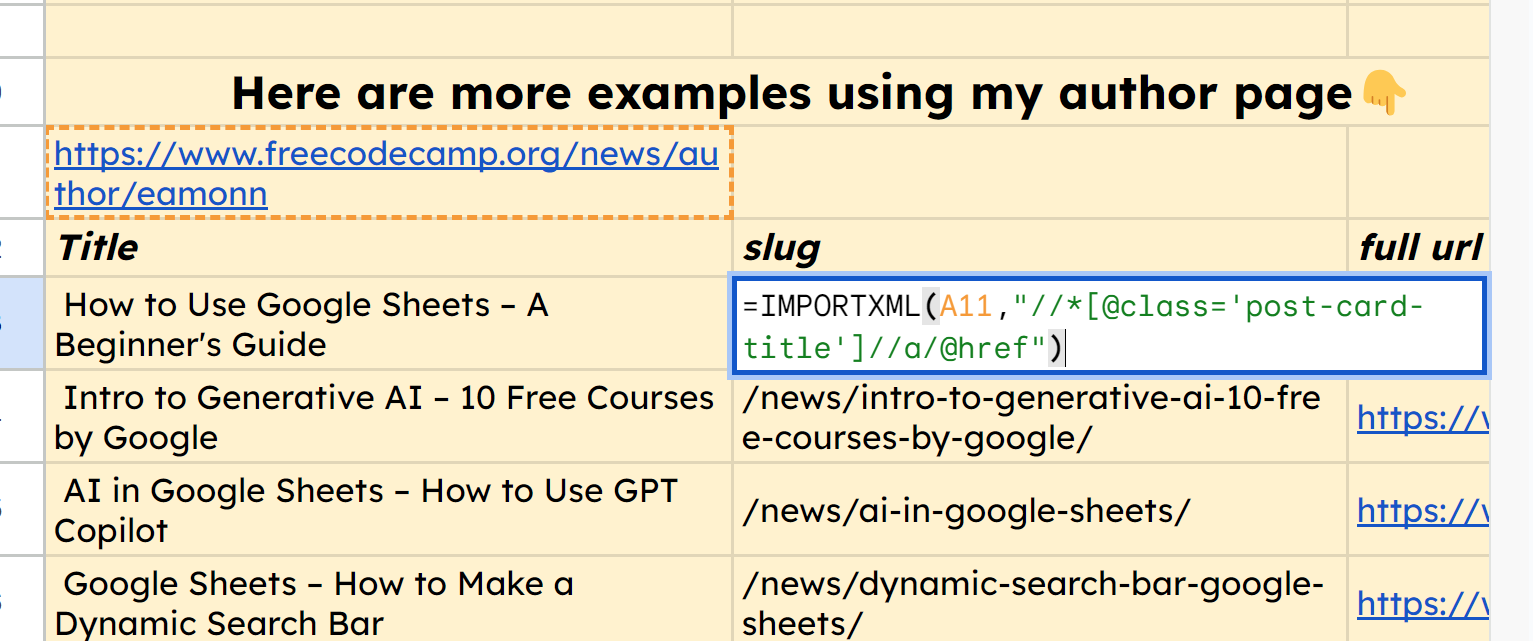 screenshot of IMPORTXML
screenshot of IMPORTXML
You'll notice that it does bring in the full URL, so as a bonus, we can simply prepend the domain to each of these. Here's the function for the first row which we can drag down to get all those proper URLs: ="https://www.freecodecamp.org"&B13
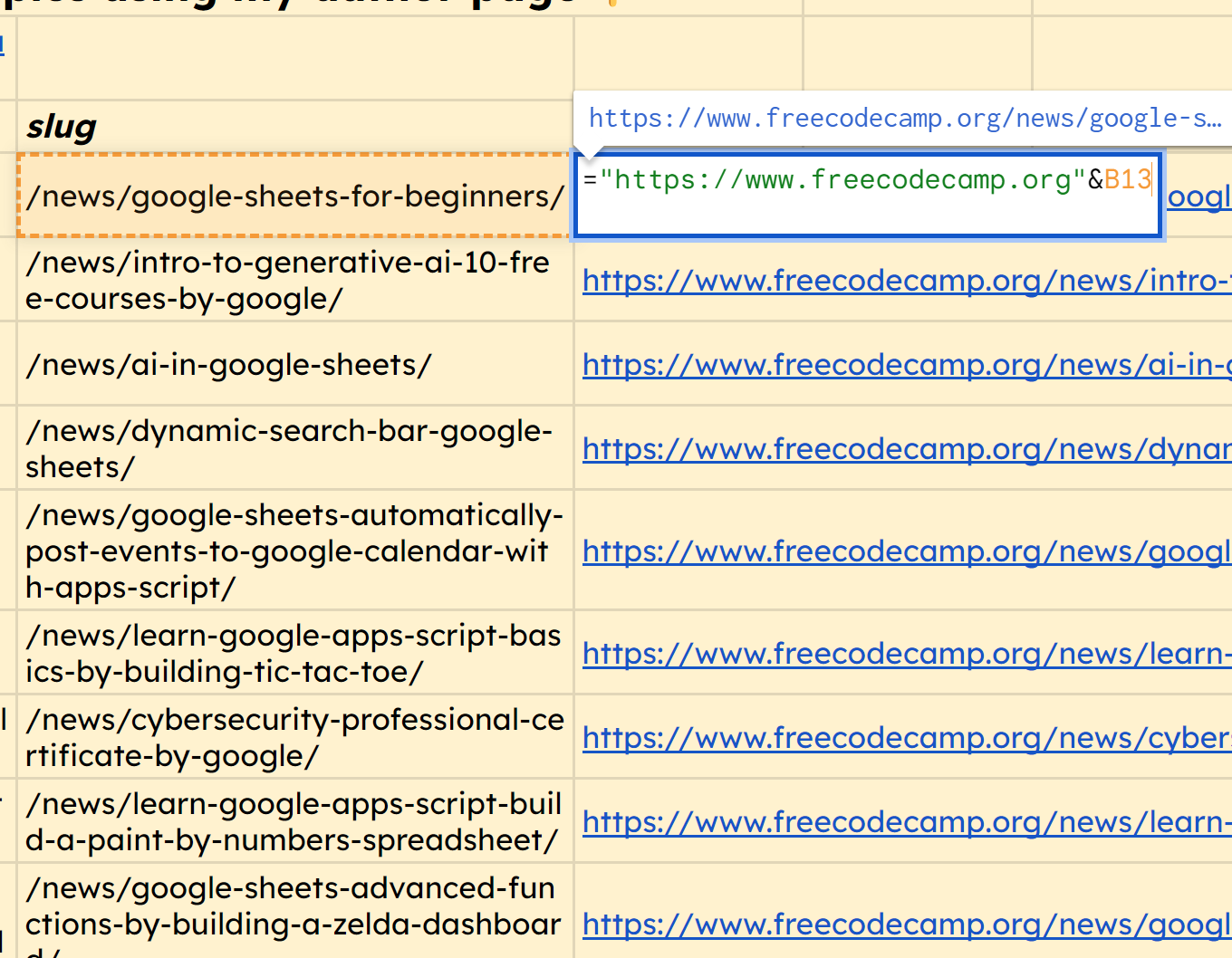 screenshot of prepending domain to slug
screenshot of prepending domain to slug
Follow Me
I hope this was helpful for you! I learned a lot myself, and enjoyed putting the video together.
You can find me on YouTube: https://www.youtube.com/@eamonncottrell
And, I've got a newsletter here: https://got-sheet.beehiiv.com/