

When you access a website like www.google.com, would it surprise you to learn that the URL isn't really the website address?
There is some work "under the hood" to ensure that, when you type in a human friendly name like Google, it takes you to the website you're expecting it to.
So, what's happening under the hood?
What are URLs?
You may be familiar with what a URL is. It's a simple link to a bit of content on the web. People use URL's daily to share videos, pictures, sites, articles – almost anything on the internet.
URL is an acronym for Uniform Resource Locator, and we can break them down into multiple smaller "pieces". Here's what makes up a standard URL:
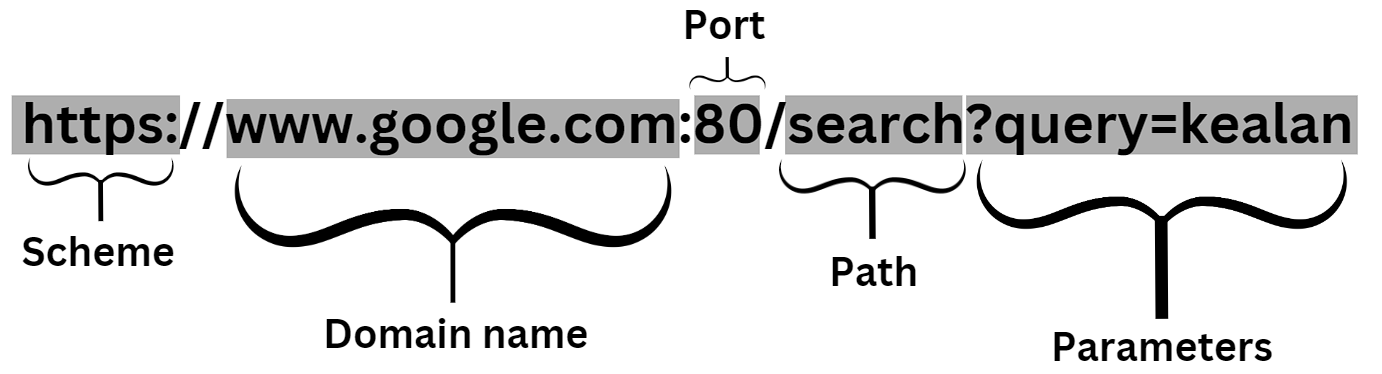 Anatomy of a URL showing the Scheme, Domain Name, Path, and Parameters
Anatomy of a URL showing the Scheme, Domain Name, Path, and Parameters
A URL is just an address for a resource. The resources differ like we discussed, but they're just pointers all over the internet to take you to content you want to view.
As you can see in the graphic above, the breakdown of a URL is often:
- Scheme: this is the protocol a browser uses to access your content. Normally for websites it's HTTP (insecure), or HTTPS (secure).
- Domain name: the website name ("www.google.com" here)
- Port: a network port (80 in this example)
- Path: a path to a particular resource on the server
- Parameters: often key-value pairs, to serve extra data to the web server.
What are IP Addresses?
Humans and computers navigate the web very differently. Whilst most humans use URL's like we just discussed, to communicate between computers, computers use the Internet Protocol (IP).
The IP is a set of rules that route and address data packets (all the data you want to view) to make sure it arrives to your computer.
The Internet Protocol relies on devices and domains, all having their own IP address to connect and identify all the different segments (packets!) of the internet.
An IP address is a series of standardised numbers that range from 0 to 255 – separated by dots.
If you want to see IP addresses in action, and are familiar with terminals, you can type ping google.com in whichever terminal you like and you can see the IP address of Google.com.
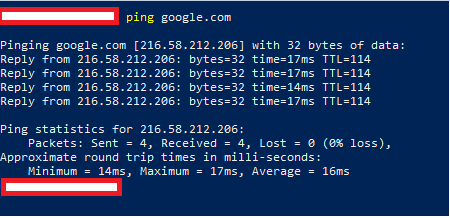 A screenshot from a PowerShell terminal, showing a ping command to 216.58.212.206, and 0% packet loss.
A screenshot from a PowerShell terminal, showing a ping command to 216.58.212.206, and 0% packet loss.
You can test this further by typing 216.58.212.206 directly into your browser and seeing if it takes you to Google.
Hopefully this small example highlights why we use URL's. If both addresses (IP address and domain name) took you to the same place, would you rather be asked to remember Google.com or 216.58.212.206?
Note that some IP addresses change day to day (called dynamic IP addresses) – so the above IP address may not work, depending on if the IP address is dynamic or static.
Static IP addresses are ones that don't change – but to assign a single IP address to every machine would be impractical. It would be a logistical nightmare, too, as some people only log onto computers once a month to send an email, for example.
We could very realistically run out of IP addresses on today's current technology if we gave every device a unique IP address (if you want to read how IP addresses are allocated in greater detail, read here).
What is a DNS?
If we know computers communicate via the Internet Protocol and communicate using IP Addresses, how do we turn google.com into the website we use so regularly?
The answer is using a Domain Name System (DNS). The job of the Domain Name System is to transform human readable domain names into IP addresses.
There are four servers specifically that we'll discuss.
DNS Recursor
A DNS Recursor is like a waiter in a restaurant. It acts like a "front facing" part of the system to receive orders (normally from browsers) where the waiter then heads into the back to get what is needed.
In reality, it's just a server that receives DNS queries from browsers and returns information.
There are 3 different places the DNS recursor can generally get the information from depending on if any data has been cached:
- Root nameserver
- TLD nameserver
- Authoritative nameserver
So let's discuss them one by one.
What is a Root Nameserver?
The root nameserver's main job is to return the Top-Level Domain (TLD) server. **
This is an important step to map hostnames into IP addresses.
The root nameserver essentially acts like a catalogue that points to more specific locations.
What is a Top-Level Domain (TLD) Server?
If the root nameserver acts like a catalogue, the TLD server acts like a page in a catalogue.
The TLD server generally returns the final part of the host-name, like com for example, in "google.com".
What is an Authoritative Nameserver?
This server is like a row entry on the specific page of the catalogue.
The authoritative nameserver now can return the IP address for the requested hostname from the browser, back to the DNS recursor – which can hand it back to the browser.
DNS can be super confusing, and to understand the whole process may take a little while, so let's tie it together with a final example.
Example Request
Let's break down an example request from a user, and hopefully tie together this pretty complex process.
Each step in the flow starts to point closer and closer to the final address the user will eventually end up hitting.
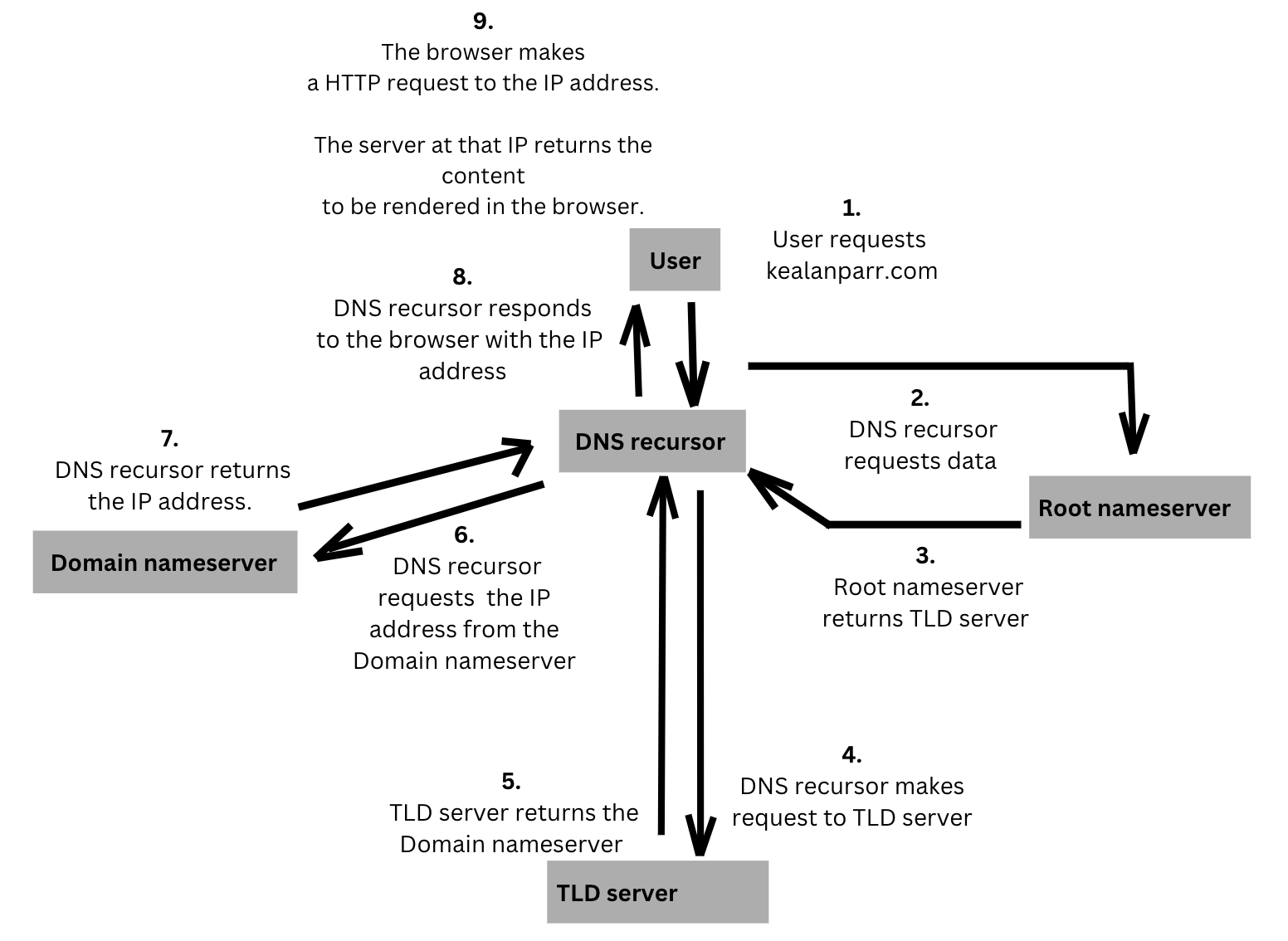 Diagram showing the steps in the request process
Diagram showing the steps in the request process
Let's break down what's going on in this graphic:
Step 1:
A user types 'kealanparr.com' into their browser, and the query hits the DNS recursor.
Step 2:
The DNS recursor then queries a Root nameserver
Step 3:
The Root nameserver then responds to the DNS recursor with the address of a Top Level Domain server (TLD) such as .com.
Step 4:
The DNS recursor then makes a request to the .com TLD.
Step 5:
The .com TLD server then responds with the IP address of the Domain’s nameserver, kealanparr.com.
Step 6:
The DNS recursor sends a query to the domain’s nameserver.
Step 7:
The IP address for kealanparr.com is then returned to the resolver from the Domain nameserver.
Step 8:
The DNS recursor responds to the web browser request with the IP address of the domain requested.
Step 9:
At this point, the DNS lookup has returned enough data for the browser to make the request for the web page.
- The browser makes a HTTP request to the IP address.
- The server at that IP returns the webpage content to be rendered in the browser.
Conclusion
I hope this article has helped you to understand a few networking principles that affect the websites you use everyday.
IP addresses, DNS, and more are all technologies most people use daily but may not be very familiar with.
Cloudflare has an article that was helpful as I researched for this article, which you can read here.
I tweet my articles here if you would like to read more.