
In this article, I'll teach you about Machine Learning Operations, which is like DevOps for Machine Learning.
Until recently, all of us were learning about the standard software development lifecycle (SDLC). It goes from requirement elicitation to designing to development to testing to deployment, and all the way down to maintenance.
We were (and still are) studying the waterfall model, iterative model, and agile models of software development.
Now, we are at a stage where almost every organisation is trying to incorporate Machine Learning (ML) – often called Artificial Intelligence – into their product.
This new requirement of building ML systems adds to and reforms some principles of the SDLC, giving rise to a new engineering discipline called Machine Learning Operations, or MLOps. And this new term is creating a buzz and has given rise to new job profiles.
Here we’ll talk about:
What is MLOps?
What problems does MLOps solve?
What skills do you need for MLOps?
Keep reading and I'll explain each in detail.
What is MLOps?
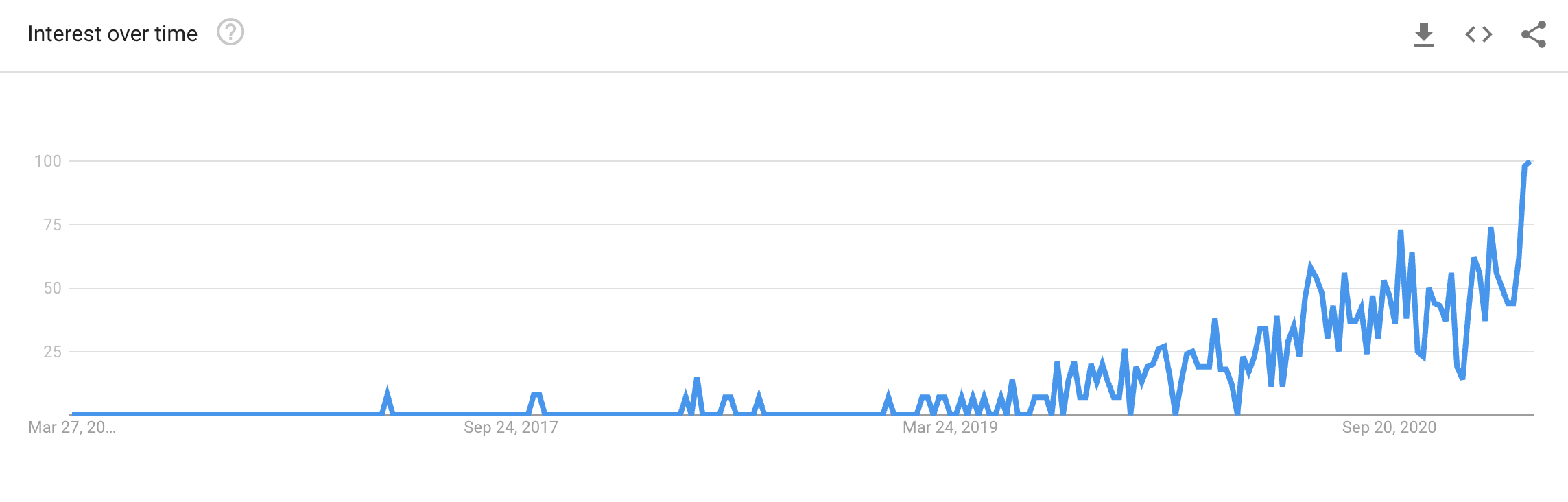
If you look MLOps up on Google trends, you'll see that it is a relatively new discipline. Again, it has come to be because more organizations are trying to integrate ML systems into their products and platforms.
Here’s how I’d define MLOps:
MLOps is an engineering discipline that aims to unify ML systems development (dev) and ML systems deployment (ops) in order to standardize and streamline the continuous delivery of high-performing models in production.
Why MLOps?
Until recently, we were dealing with manageable amounts of data and a very small number of models at a small scale.
The tables are turning now, and we are embedding decision automation in a wide range of applications. This generates a lot of technical challenges that come from building and deploying ML-based systems.
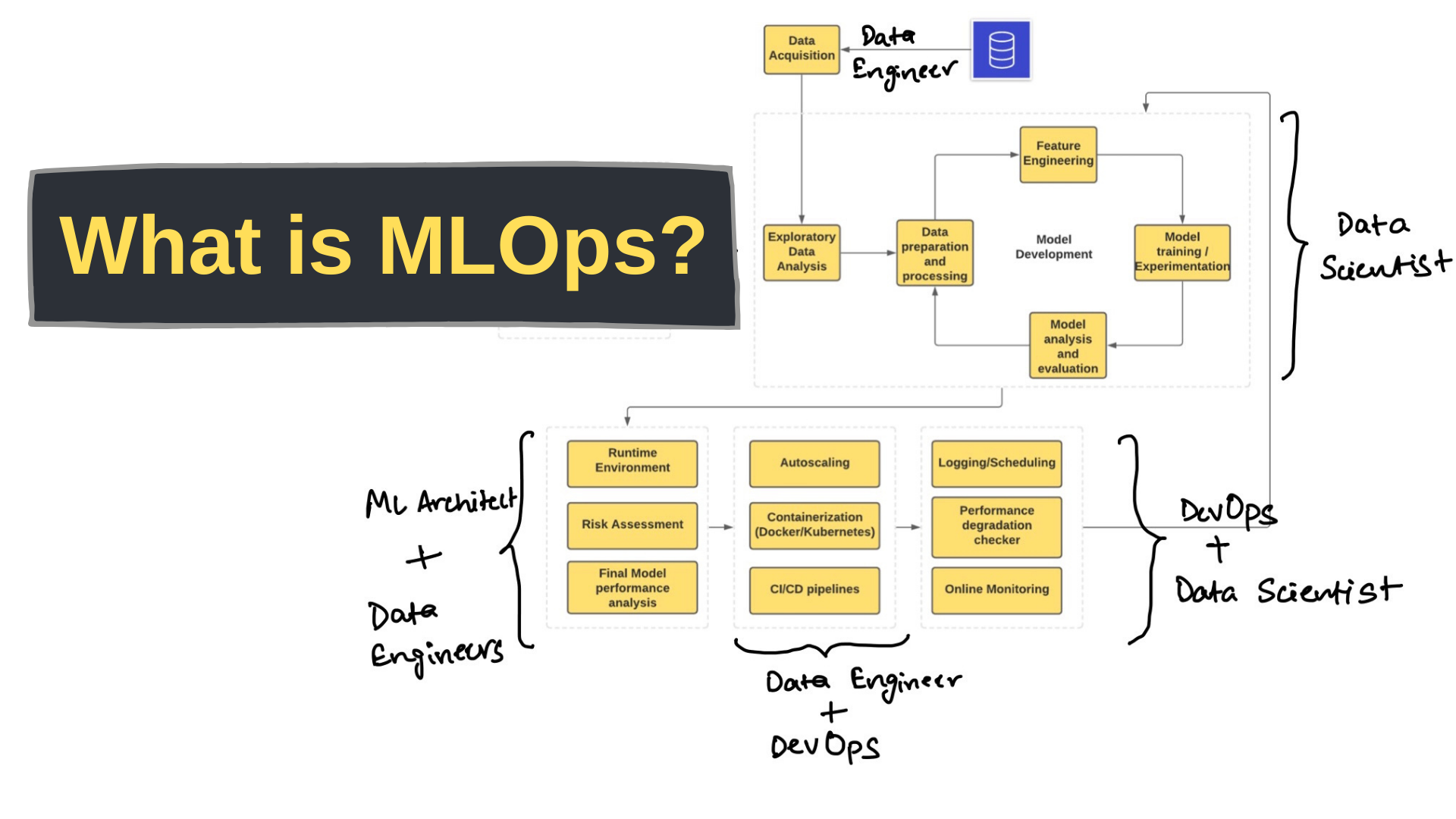
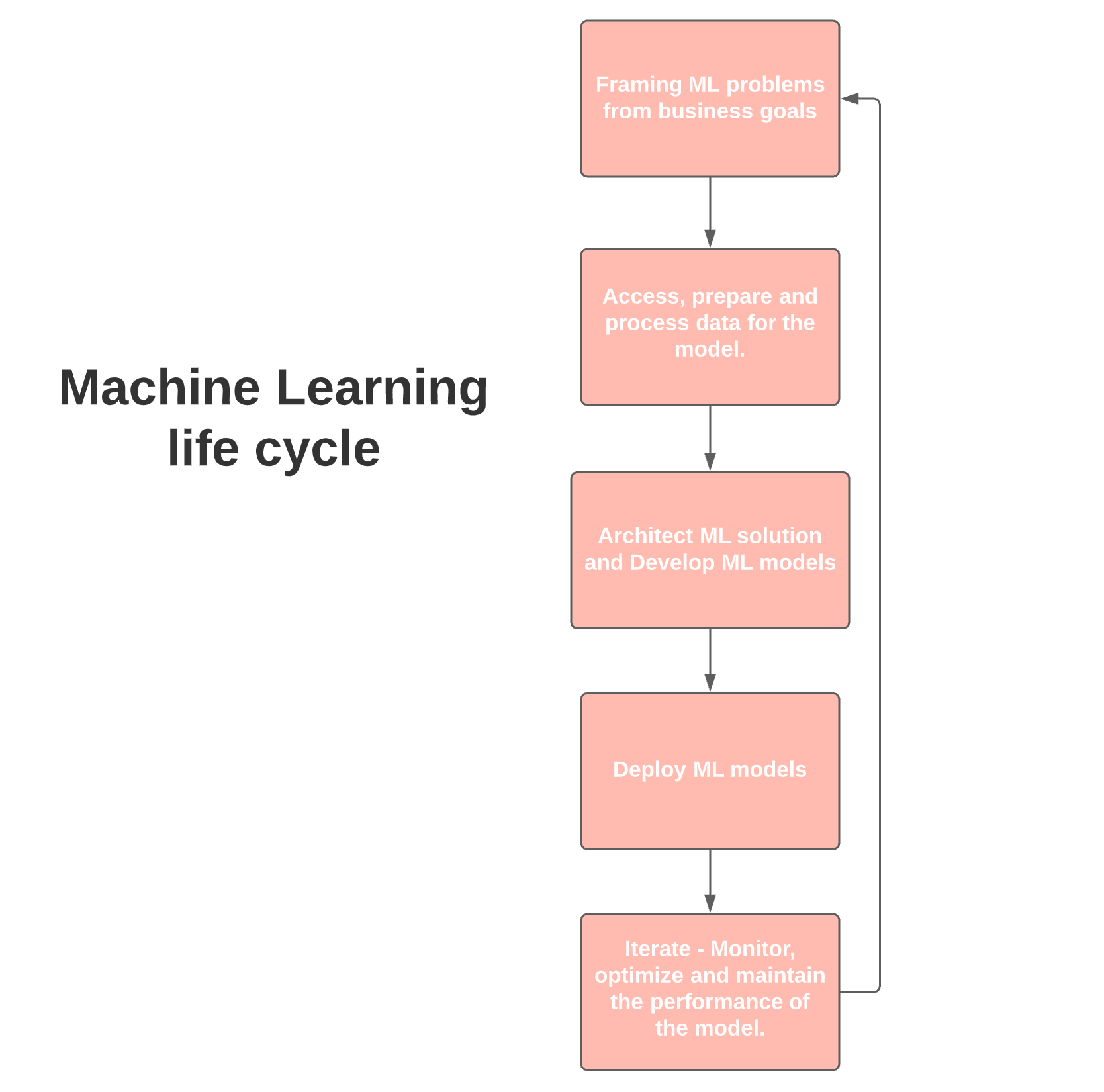
In order to understand MLOps, we must first understand the ML systems lifecycle. The lifecycle involves several different teams of a data-driven organization.
From start to bottom, the following teams chip in:
Business development or Product team — defining business objective(s) with KPIs
Data Engineering — data acquisition and preparation.
Data Science — architecting ML solutions and developing models.
IT or DevOps — complete deployment setup, monitoring alongside scientists.
Here is a very simplified representation of the ML lifecycle.
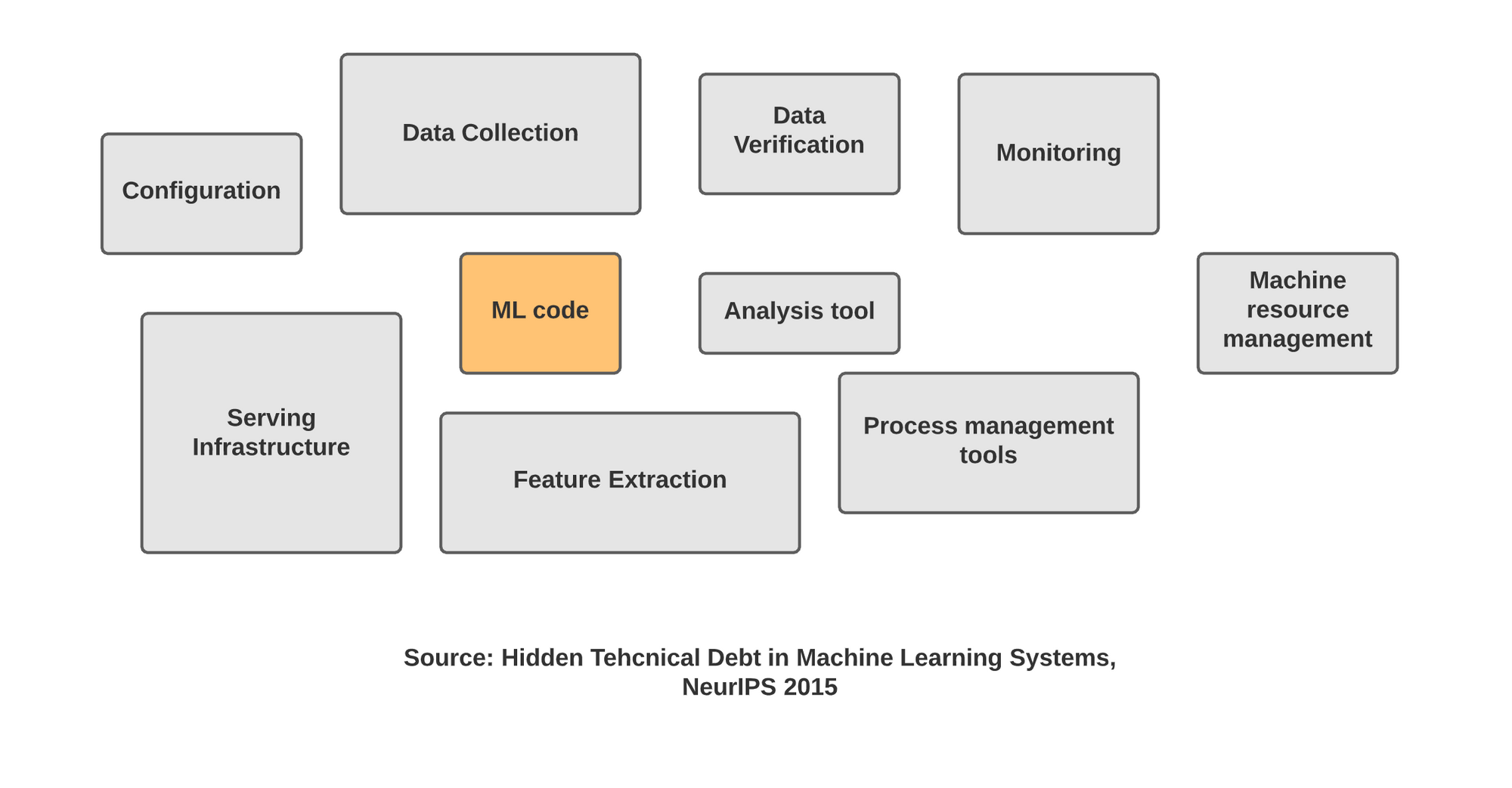
Teams at Google have been doing a lot of research on the technical challenges that come with building ML-based systems. A NeurIPS paper on hidden technical Debt in ML systems shows you developing models is just a very small part of the whole process. There are many other processes, configurations, and tools that are to be integrated into the system.
To streamline this entire system, we have this new Machine learning engineering culture. The system involves everyone from the higher management with minimal technical skills to Data Scientists to DevOps and ML Engineers.
What Problems Does MLOps Solve?
Managing such systems at scale is not an easy task, and there are numerous bottlenecks that need to be taken care of. Following are the major challenges that teams are up against:
There is a shortage of Data Scientists who are good at developing and deploying scalable web applications. There is a new profile of ML Engineers on the market these days that aims to serve this need. It is a sweet spot at the intersection of Data Science and DevOps.
Changing business objectives in the model —There are many dependencies with the data continuously changing, maintaining performance standards of the model, and ensuring AI governance. It’s hard to keep up with the continuous model training and evolving business objectives.
Communication gaps between technical and business teams with a hard-to-find common language to collaborate. Most often, this gap becomes the reason that big projects fail.
Risk assessment — there is a lot of debate going on around the black-box nature of such ML/DL systems. Often models tend to drift away from what they were initially intended to do. Assessing the risk/cost of such failures is a very important and meticulous step.
For example, the cost of an inaccurate video recommendation on YouTube would be much lower compared to flagging an innocent person for fraud and blocking their account, and declining their loan applications.
What Skills Do You Need for MLOps?
At this point, I’ve already given a lot of insights into the bottlenecks of the system and how MLOps solves each of those. You can discover the skills you need to target from those challenges.
Following are the key skills you need to focus on:
1. Framing ML problems from business objectives
Machine learning systems development typically starts with a business goal or objective. It can be a simple goal of reducing the percentage of fraudulent transactions below 0.5%, or it can be building a system to detect skin cancer in images labeled by dermatologists.
These objectives often have certain performance measures, technical requirements, budgets for the project, and KPIs (Key Performance Indicators) that drive the process of monitoring the deployed models.
2. Architect ML and data solutions for the problem
After the objectives are clearly translated into ML problems, the next step is to start searching for appropriate input data and the kinds of models to try for that kind of data.
Searching for data is one of the most strenuous tasks. It is a process with several parts:
You need to look for any available relevant dataset,
Check the credibility of the data and its source.
Is the data source compliant with regulations like GDPR?
How to make the dataset accessible?
What is the type of source — static (files) or real-time streaming (sensors)?
How many sources are to be used?
How to build a data pipeline that can drive both training and optimization once the model is deployed in the production environment?
What cloud services will you use?
3. Data preparation and processing — part of data engineering.
Data preparation includes tasks like feature engineering, cleaning (formatting, checking for outliers, imputations, rebalancing, and so on), and then selecting the set of features that contribute to the output of the underlying problem.
You need to design a complete pipeline and then code it to produce clean and compatible data that'll be fed to the next phase of model development.
An important part of deploying such pipelines is to choose the right combination of cloud services and architecture that is performant and cost-effective. For example, if you have a lot of data movement and huge amounts of data to store, you can look to build data lakes using AWS S3 and AWS Glue.
You might want to practice building a few different kinds of pipelines (Batch vs Streaming) and try to deploy those pipelines on the cloud.
4. Model training and experimentation — data science
As soon as your data is prepared, you move on to the next step of training your ML model.
Now, the initial phase of training is iterative with a bunch of different types of models. You will be narrowing down to the best solution using several quantitative measures like accuracy, precision, recall, and more.
You can also use qualitative analysis of the model which accounts for the mathematics that drives that model or, simply put, the explainability of the model.
I have this complete list of tasks that you can read on training ML models:
Now, you’ll be running a lot of experiments with different types of data and parameters. Another challenge that data scientists face while training models is reproducibility. This can be solved by versioning your models and data.
You can add version control to all the components of your ML systems (mainly data and models) along with the parameters.
This is now very easy to accomplish with the development of open-source tools like DVC and CML.
Other tasks include:
Testing a model by writing unit tests for model training.
Checking the model against baselines, simpler models, and across different dimensions.
Scaling the model training using distributed systems, hardware accelerators, and scalable analysis.
5. Building and automating ML pipelines
You should build your ML pipelines keeping in mind the following tasks:
Identify system requirements — parameters, compute needs, triggers.
Choose an appropriate cloud architecture — hybrid or multi-cloud.
Construct training and testing pipelines.
Track and audit the pipeline runs.
Perform data validation.
6. Deploying models to the production system
There are mainly two ways of deploying an ML model:
Static deployment or embedded model — where the model is packaged into installable application software and is then deployed. For example, an application that offers batch-scoring of requests.
Dynamic deployment — where the model is deployed using a web framework like FastAPI or Flask and is offered as an API endpoint that responds to user requests.
Within dynamic deployment, you can use different methods:
deploying on a server (a virtual machine)
deploying in a container
serverless deployment
model streaming — instead of REST APIs, all of the models and application code are registered on a stream processing engine like Apache Spark, Apache Storm, and Apache Flink.
Following are the considerations:
Ensuring that proper documentation and testing scores are met.
Revalidating the model's accuracy.
Performing explainability checks.
Ensuring that all governance requirements have been met.
Checking the quality of any data artifacts
Load testing — compute resource usage.
7. Monitor, optimize and maintain models
Not only do you need to keep an eye on the performance of the models in production but you also need to ensure good and fair governance.
Governance here means adding control measures to ensure that the models deliver on their responsibilities to all the stakeholders, employees, and users that are affected by them.
As part of this phase, we need data scientists and DevOps engineers to maintain the whole system in production by performing the following tasks:
Keeping track of performance degradation and business quality of model predictions.
Setting up logging strategies and establishing continuous evaluation metrics.
Troubleshooting system failures and introduction of biases.
Tuning the model performance in both training and serving pipelines deployed in production.
Further recommended reading
This article was all about MLOps which is not a job profile but an ecosystem of several stakeholders.
If you are someone who works at the crossover of ML and Software Engineering (DevOps), you might be a good fit for startups and mid-size organizations that are looking for people who can handle such systems end-to-end.
ML Engineer is the position that serves this sweet spot and it's what aspiring candidates should be targeting. Following are a few resources that you can look at:
[Book]: Andriy Burkov’s book on Machine Learning Engineering.
You can also aim for certification programs like the ones below:
You can also watch the video version of this blog here:
If this tutorial was helpful, you should check out my data science and machine learning courses on Wiplane Academy. They are comprehensive yet compact and helps you build a solid foundation of work to showcase.