
By Alex Olteanu
A data scientist investigates

Should you watch a movie? Well, there are a lot of factors to consider, such as the director, the actors, and the movie’s budget. Most of us base our decision off of a review, a short trailer, or just by checking the movie’s rating.
There are a few good reasons you would want to avoid reading reviews, or watching a trailer, although they bring much more information than a rating.
First, you may want to completely avoid spoilers, no matter how small. I understand that!
Second, it could be that you want an uninfluenced experience of watching that movie. This usually applies only to reviews, which are sprinkled with frames, like “this is a movie about the complexity of the universe” or “this movie is really not about love”. Once these frames get encoded in your short-term memory, it’s really hard to stop them from interfering with your own movie experience.
Another good reason is that if you’re tired or hurried, you might not want to read a review, let alone watch a 2-minute trailer.
So a numeric movie rating seems to be a good solution in quite a few situations, for quite a few people.
This article aims to recommend a single website to quickly get an accurate movie rating, and offers a robust, data-driven argumentation for it.
Criteria for “the best”
Making such a recommendation is a lot like saying “this is the best place to look for a movie rating,” which is an evaluative statement, resting on some criteria used to determine what is better, what is worse or worst, and what is best, in this case. For my recommendation, I will use one single criterion: a normal distribution.
The best place to look for a movie rating is to see whose ratings are distributed in a pattern which resembles the most, or is identical to, the pattern of a normal distribution, which is this: given a set of values lying in a certain interval, most of them are in the middle of it, and the few others at that interval’s extremes. Generally, this is how a normal (also called Gaussian) distribution looks like:
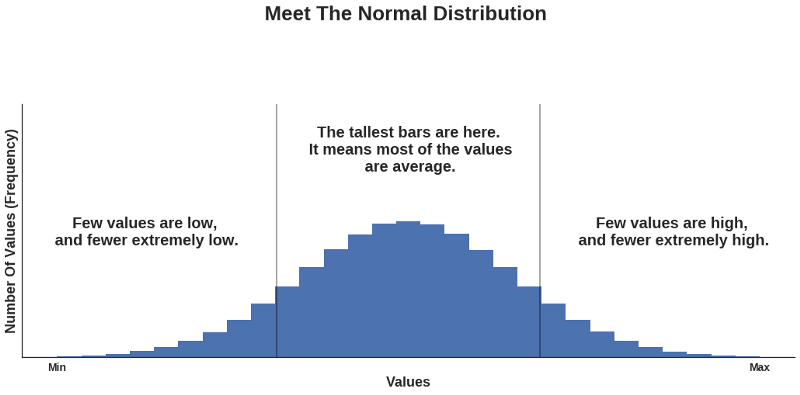
What’s the rationale behind this criterion? Well, from my own experience consisting of several hundred movies, I can tell that I’ve seen:
- a few outstanding ones that I’ve watched several times
- a couple that were really appalling, and made me regret the time spent watching them
- and a whole bunch of average ones, for most of which I can’t even remember the plot anymore.
I believe that most people — whether critics, cinephiles, or just regular moviegoers — have had a similar experience.
If movie ratings do indeed express movie quality, then we should see the same pattern for both.
Given that most of us assess the bulk of movies as being of an average quality, we should see the same pattern when we analyze movie ratings. A similar logic applies for bad and good movies.
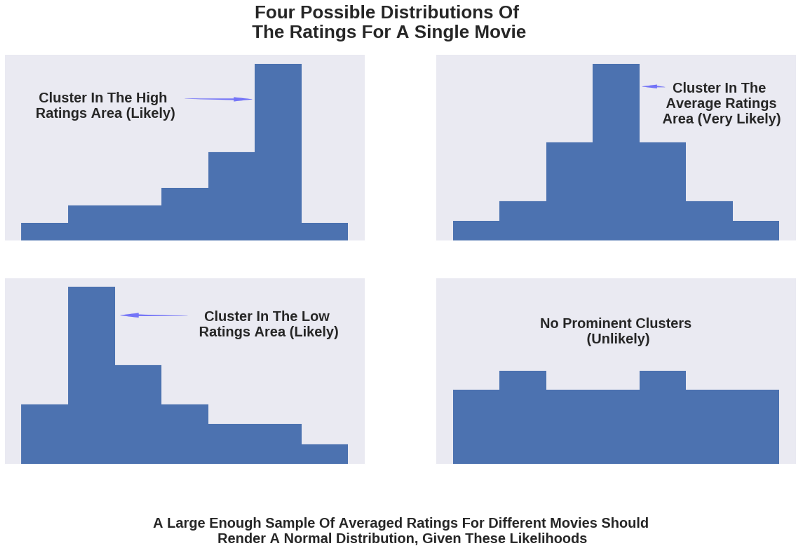
If you’re not yet persuaded that there should be such a correspondence between the patterns, think about the distribution of ratings for a single movie. As many people rate the movie, it’s not a leap of faith to assume that most often there will be many of them with similar preferences. They’ll generally agree that the movie is either bad, average, or good (I will quantify later these qualitative values). Also, there will be a few others who assess the movie with one of the other two qualitative values.
If we visualized the distribution of all the ratings for an individual movie, we would most likely see that one single cluster forms in one of the areas corresponding to a low, an average, or a high rating.
Provided most movies are considered average, the cluster around the average area has the greatest likelihood of occurring, and the other two clusters have a smaller (but still significant) likelihood. (Note that all these likelihoods can be quantified in principle, but this would require a lot of data, and would have the potential to turn this article into a book.)
The least likely would be a uniform distribution in which there are no clusters, and people’s preferences are split almost equally across the three qualitative values.
Given these likelihoods, the distribution of ratings for a large enough sample of movies should be one with a blunt cluster in the average area, bordered by bars of decreasing height (frequency), resembling, thus, a normal distribution.
If you have found all this hard to understand, consider this illustration:
IMDB, Rotten Tomatoes, Fandango, or Metacritic?
Now that we have a criterion to work with, let’s dive into the data.
There are a lot of websites out there that come up with their own movie ratings. I have chosen only four, mainly based on their popularity, so that I could get ratings for movies with an acceptable number of votes. The happy winners are IMDB, Fandango, Rotten Tomatoes, and Metacritic.
For the last two, I have focused only on their iconic rating types — namely the tomatometer, and the metascore — mainly because these are more visible to the user on each of the websites (meaning it’s quicker to find them). These are also shared on the other two websites (the metascore is shared on IMDB and the tomatometer on Fandango). Besides these iconic ratings, both websites also have a less-featured rating type where only users get to contribute.
I have collected ratings for some of the most voted and reviewed movies in 2016 and 2017. The cleaned dataset has ratings for 214 movies, and can be downloaded from this Github repo.
I haven’t collected ratings for movies released before 2016, simply because a slight change has occurred in Fandango’s rating system soon after Walt Hickey’s analysis, which I will refer to later in this article.
I’m aware that working with a small sample is risky, but at least this is compensated by getting the most recent snapshot of the ratings’ distributions.
Before plotting and interpreting the distributions, let me quantify the qualitative values I used earlier: on a 0 to 10 scale, a bad movie is somewhere between 0 and 3, an average one between 3 and 7, and a good one between 7 and 10.
Please take note of the distinction between quality and quantity. To keep it discernible in what follows, I will refer to ratings (quantity) as being low, average, or high. As before, the movie quality is expressed as bad, average, or good. If you worry about the “average” term being the same, don’t, because I will take care to avoid any ambiguity.
Now let’s take a look at the distributions:
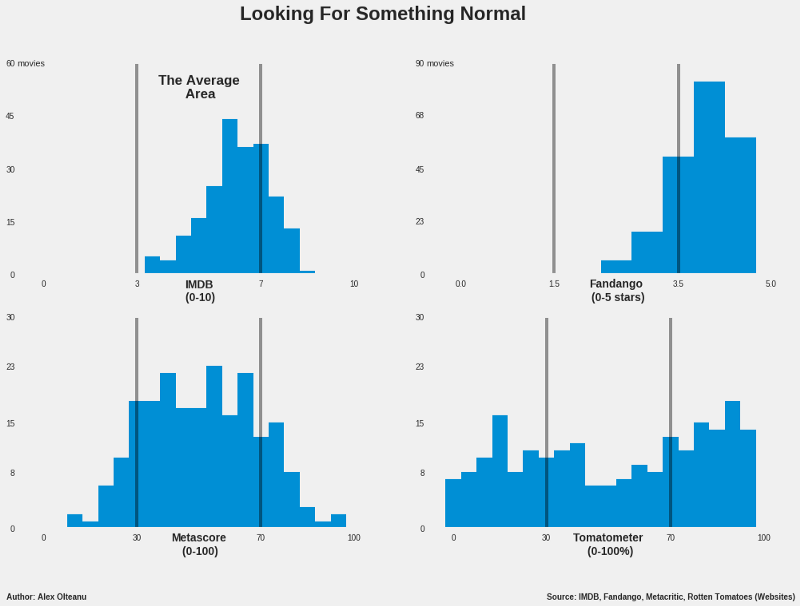
At a simple glance, it can be noticed that the metascore’s histogram (that’s what this kind of graph is called) most closely resembles a normal distribution. It has a thick cluster in the average area composed of bars of irregular heights, which makes the top neither blunt, neither sharp.
However, they are more numerous and taller than the bars in each of the other two areas, which decrease in height towards extremes, more or less gradually. All these clearly indicate that most of the metascores have an average value, which is pretty much what we’re looking for.
In the case of IMDB, the bulk of the distribution is in the average area as well, but there is an obvious skew towards the highest average values. The high ratings area looks similar to what would be expected to be seen for a normal distribution in that part of the histogram. However, the striking feature is that the area representing low movie ratings is completely empty, which raises a big question mark.
Initially, I put the blame on the small sample, thinking that a larger one would do more justice to IMDB. Luckily, I was able to find a ready-made dataset on Kaggle containing IMDB ratings for 4,917 different movies. To my great surprise, the distribution looked like this:
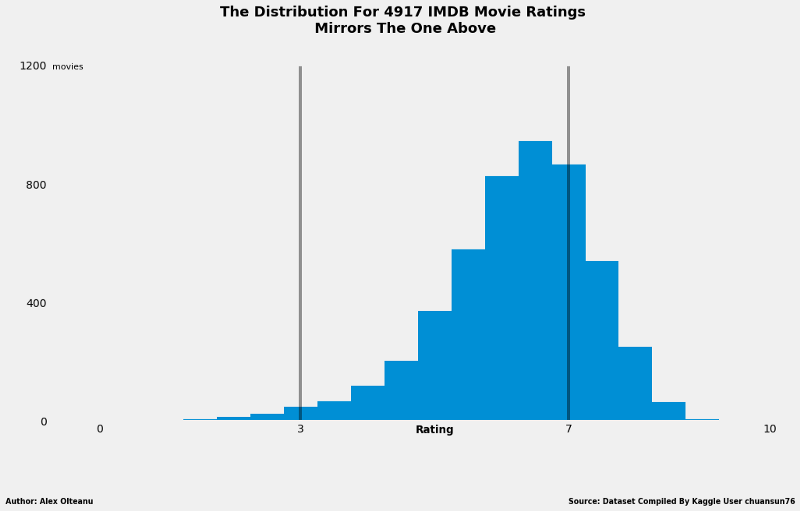
The shape of the distribution looks almost the same as that for the sample with 214 movies, except for the low ratings area, which is in this case feebly populated with 46 movies (out of 4917). The bulk of the values is still in the average area, which makes the IMDB rating worth considering further for a recommendation, although is clearly hard to rival the metascore, with that skew.
Anyway, what’s really great about this outcome is that it can be used as a strong argument to support the thesis that the 214-movies sample is fairly representative for the whole population. In other words, there’s a greater confidence now that the results of this analysis would be the same — or at least similar — to the results reached if absolutely all the movie ratings from all the four websites were analyzed.
With this increased confidence, let’s move on to examining the distribution of Fandango’s ratings, which doesn’t seem to have changed much since Hickey’s analysis. The skew is still visibly towards the higher part of the movie rating spectrum, where most of the ratings reside. The area for the lower half of the average ratings is completely empty, just like the one for low ratings. It can easily be concluded that the distribution is quite far from fitting my criterion. Consequently, I won’t consider it further for a possible recommendation.
(I promise that the torment of scrolling up will end soon. It’s much easier to compare the distributions if they are placed one near the other, rather than having them scattered across the article.)
Lastly, the tomatometer’s distribution is unexpectedly uniform, and would look even flatter under a different binning strategy (a binning strategy is defined by the total number of bars and their ranges; you can play with these two parameters when you’re generating a histogram).
This distribution is not easy to interpret in context, because the tomatometer it’s not a classical rating, but rather represents the percentage of critics who gave a positive review to a movie. This makes it unfit for the bad-average-good qualitative framework, because it makes movies either good, either bad. Anyway, I guess it should still boil down to the same normal distribution, with most of the movies having a moderate difference between the number of positive reviews and the negative ones (rendering many ratings of 30% — 70% positive reviews), and a few movies having a significantly bigger difference, in one way or the other.
Given the last consideration and the shape of the distribution, the tomatometer doesn’t meet my criterion. It could be that a larger sample would do it more justice, but even so, if I were to recommend it, I would do it with some reserves because of the vague positive or negative rating system.
At this point of the analysis, I could say that by looking at the distributions, my recommendation is the metascore.
However, the IMDB’s distribution seems to be worth considering as well, especially if you tweak a little the rating intervals for the three qualitative categories (intervals which I defined myself, more or less arbitrarily). From this perspective, recommending the metascore by mostly doing a visual examination is clearly not enough.
So, I will try to delimit between these two by using a quantitative method.
The idea is to use the Fandango variable as a negative reference, and then determine which variable, from the IMDB rating and the metascore, is the least correlated with it (I call these variables because they can take different values — for example, the metascore is a variable because it takes different values, depending on the movie).
I will simply compute some correlation coefficients, and the variable with the smallest value will be my recommendation (I will explain then how these correlation coefficients work). But before that, let me briefly justify choosing the Fandango variable as a negative reference.
Fandango’s users love movies too much
One reason for this choice is that the distribution of Fandango’s movie ratings is the furthest from that of a normal one, having that obvious skew towards the higher part of the movie ratings spectrum.
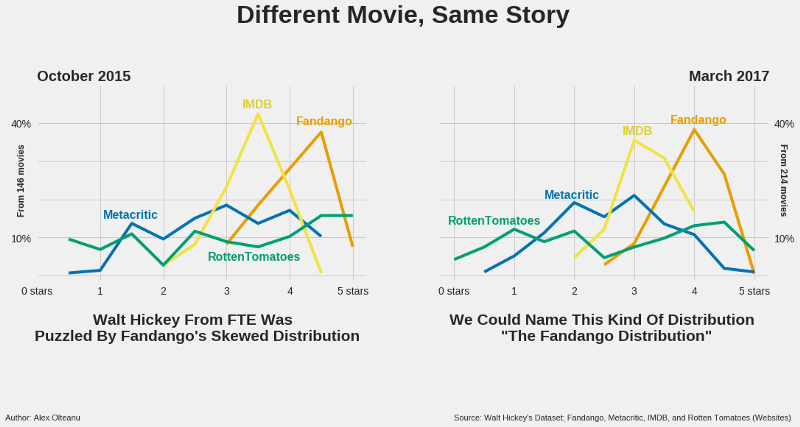
The other reason is the cloud of suspicion around Fandango left by Walt Hickey’s analysis. On October 2015, he was also puzzled by a similar distribution, and discovered that on Fandango’s website the numerical ratings were always rounded to the next highest half-star, not to the nearest one (for example, a 4.1 average rating for a movie would have been rounded to 4.5 stars, instead of 4.0).
The Fandango team fixed the biased rating system, and told Hickey that the rating logic was rather a “software glitch” on their website, pointing towards an unbiased system on their mobile app. (More about this on Hickey’s article.) The adjustment did change some statistical parameters for the better, but not enough to convince me not to work with the Fandango variable as a negative reference.
This is what the change looks like:
Now, let’s zoom in on Fandango:
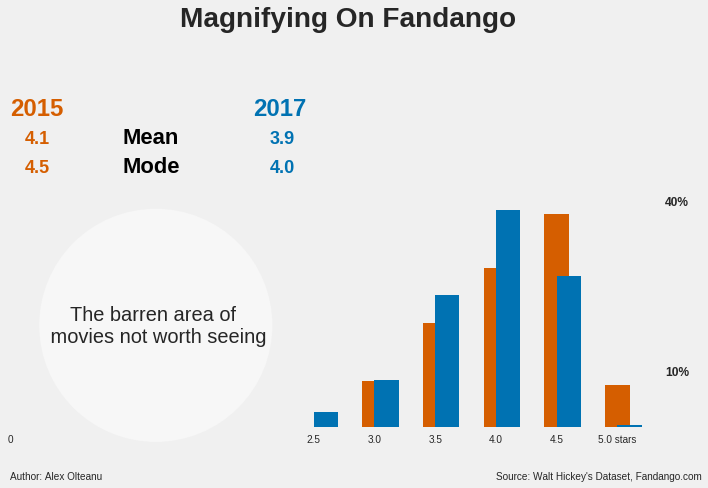
Between the metascore and the IMDB rating, which is the least correlated with the Fandango rating?
The least correlated with the Fandango rating is the metascore. It has a Pearson’s r value of 0.38 with respect to Fandango, while the IMDB rating has a value of 0.63.
Now let me explain all this.
As two variables change, taking different values, they are correlated if there’s a pattern corresponding to both changes. Measuring correlation simply means measuring the extent to which there is such a pattern.
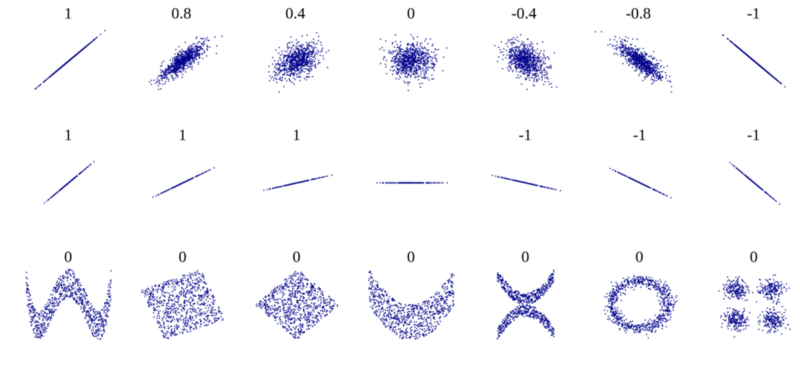
One of the ways to perform this measure is to compute the Pearson’s r. If the value is +1.0, it means there’s a perfect positive correlation, and if it’s -1.0, it means there’s a perfect negative correlation.
The extent to which the variables are correlated decrease as the Pearson’s r approaches 0, from both the negative and the positive side.
Let’s better visualize this:
Now, to put the abstraction above into context, if we compare how the values for two rating types change — say Fandango’s and IMDB’s — we can determine the degree to which there’s a pattern corresponding to both changes.
Given the correlation coefficients just mentioned, there is a pattern between Fandango and IMDB to a greater extent than is for Fandango and the metascore. Both coefficients are positive, and, as such, the correlation is said to be positive, which means that as Fandango’s ratings go up, IMDB’s ratings tend to go up as well, more than the metascores do.
Put differently, for any given movie rating on Fandango, it is more probable that the metascore is going to be more different from it than the IMDB rating.
The verdict: use Metacritic’s metascore
All in all, I recommend checking the metascore whenever you are looking for a movie rating. Here’s how it works, and its downsides.
In a nutshell, the metascore is a weighted average of many reviews coming from reputed critics. The Metacritic team reads the reviews and assigns each a 0–100 score, which is then given a weight, mainly based on the review’s quality and source. You can find more about their rating system here.
Now, I just want to point out a few downsides of the metascore:
- The weighting coefficients are confidential, so you won’t get to see the extent to which each review counted in the metascore.
- You’ll have a rough time finding metascores for less-known movies that appeared before 1999, the year Metacritic was created.
- Some recent movies whose main language is not English aren’t even listed on Metacritic. For example, the Romanian movies Two Lottery Tickets (2016) and Eastern Business (2016) are not listed on Metacritic, while they are on IMDB, with ratings.
Few more words
To sum up, in this article I made a single recommendation of where to look for a movie rating. I recommended the metascore, based on two arguments: its distribution resembles the most a normal one, and it is the least correlated with the Fandango rating.
All the quantitative and the visual elements of the article are reproducible in Python, as it is shown here.
Thanks for reading! And happy movie-going!