

Is a public cloud like AWS or Microsoft's Azure the right place to host every deployment workload at every stage of its life? To be honest, I once thought that that was true – at least 95% of the time.
But things have changed. Even though new services are being added to AWS, for example, nearly every week, we've had loads of time to figure out how things generally work. So it makes sense to listen when admins and industry leaders share their experiences.
In this article, I plan to share some important rationales for assessing and, perhaps, rethinking your deployment strategies. There's certainly no single approach that'll work for everyone, but everyone needs to at least consider the big picture.
This article is excerpted from my Pluralsight course: The IT Ops Sessions: Why Some Companies Are Moving OUT of the Cloud.
What's the "Problem" with the Cloud?
So what are the experts telling us? Number one seems to be that once your company hits a certain scale, cloud operating costs start to matter a lot. And that whole abstracted "reduced complexity" thing everyone talks about? Not so much.
Let's dive a bit deeper.
When all you've got running is a website on a single Linux instance and some data stored in a couple of S3 buckets, you'll barely notice the monthly bills.
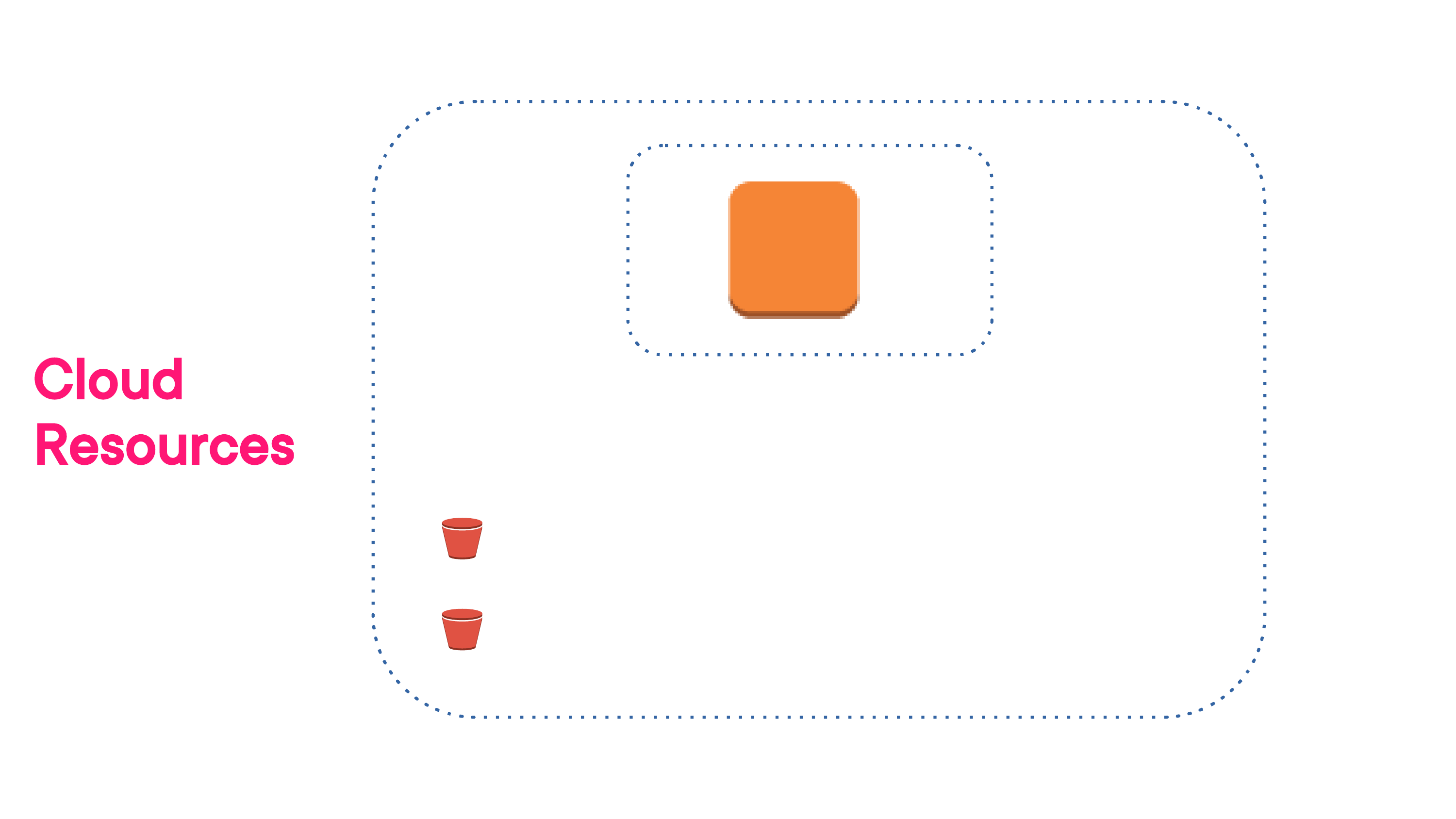 An AWS availability zone with a single EC2 instance and two S3 buckets
An AWS availability zone with a single EC2 instance and two S3 buckets
But once your user demand begins to rise and the possibility of losing some of your data or even a one hour outage keeps you up at night, then you'll need to give the numbers another look.
You see, once your application requires high availability, that single instance won't cut it any more. You'll need at least a second instance hosted in a different availability zone.
But now that your front-end is distributed, you'll need a dedicated high availability database running somewhere that each of your instances can access in real time. On AWS, that'll mean an RDS instance. And they're not free.
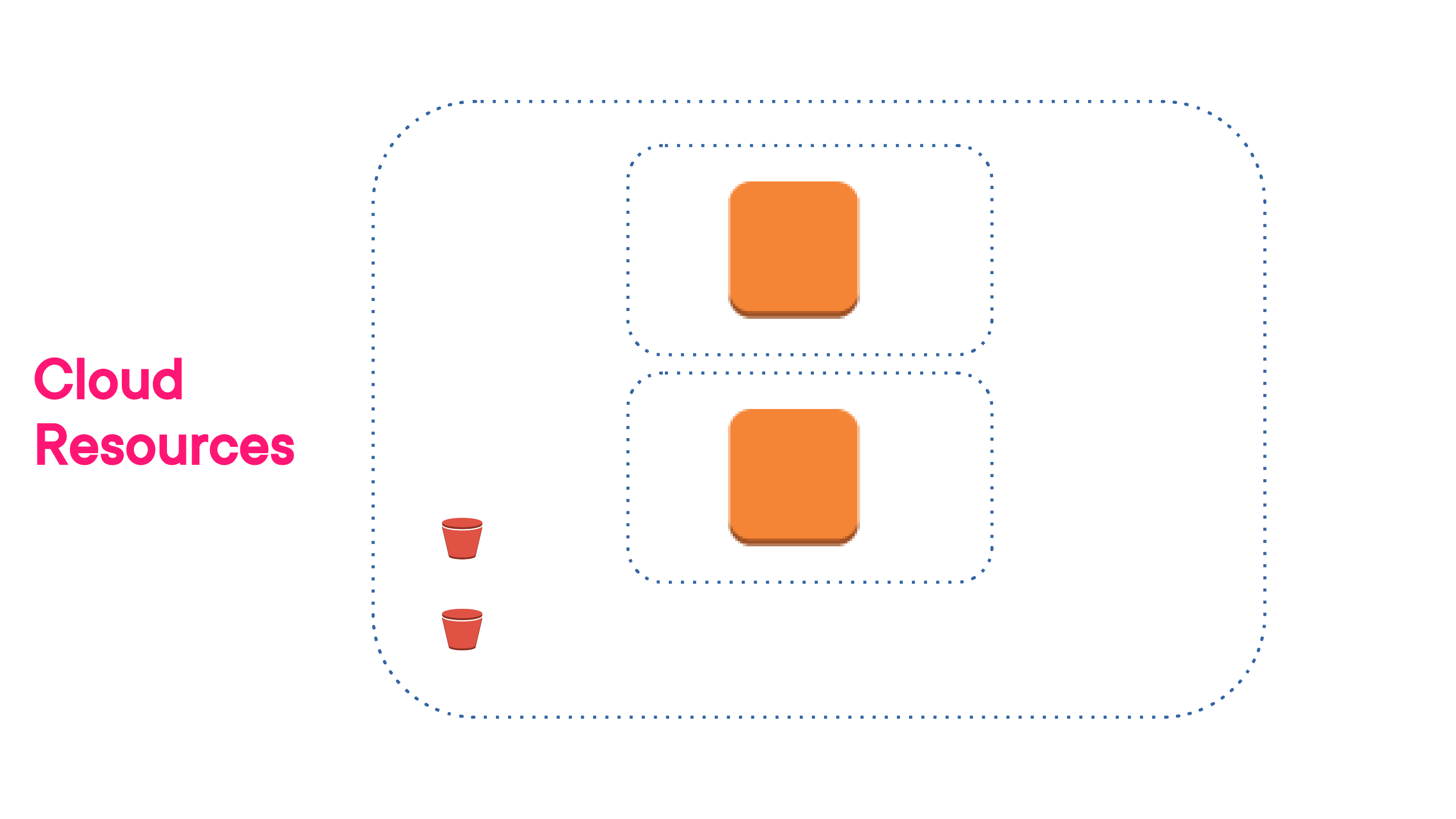 Two AWS availability zones with replicated EC2 instances
Two AWS availability zones with replicated EC2 instances
Planning significant data transfers between your servers and users? Count on extra network costs and on more expensive network-optimized instance types. Sharing your instances with other AWS clients not good enough for your security requirements? Then you can add the ongoing costs of Dedicated Hosts.
You can try it out for yourself on the handy AWS Pricing Calculator: it won't take long before your costs hit tens or even hundreds of thousands of dollars each month.
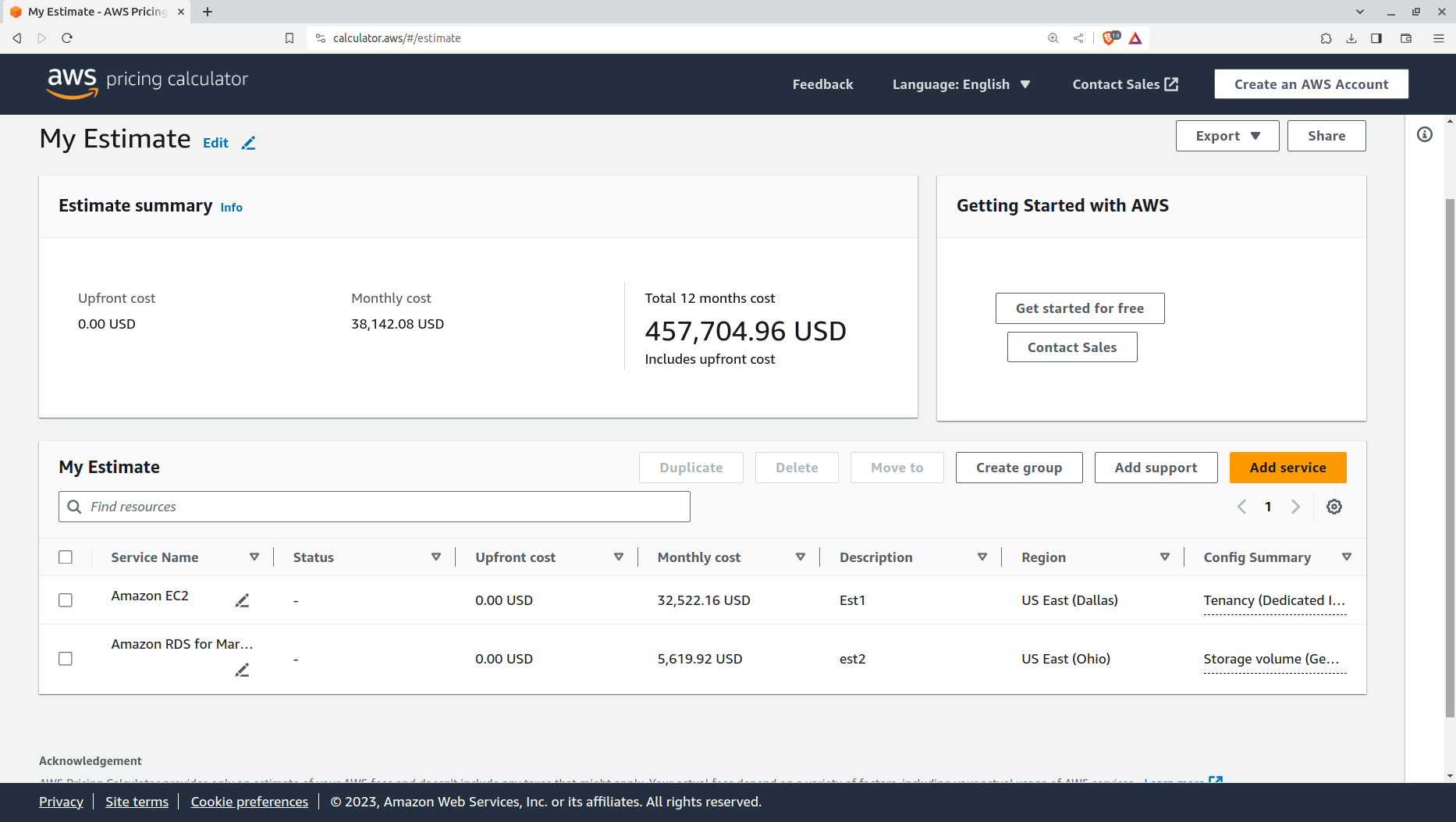 The output of a typical AWS Pricing Calculator estimate
The output of a typical AWS Pricing Calculator estimate
Now I'm certainly not suggesting that those costs are unfair or that they're not justified. AWS and other big cloud providers work very hard to give you as much information as you'll need to understand what you'll be spending and even how you can spend less. But there's no hiding the fact that renting a lot of compute resources can get very expensive.
What Does Cloud Repatriation Look Like?
Now think what it might mean to apply all of those requirements to meet the needs of a company of the scale of Dropbox or even X – by which, of course, I mean Twitter – both of which have repatriated at least some of their cloud infrastructure.
Say what you like about Twitter (and everyone's got something to say), but they very recently announced that their cloud reorganization led to a drop of 60% in their cloud-based media storage and that their cloud data processing costs dropped by 75%. Overall, estimates suggest that they're now spending around 60 million dollars less each year on AWS services.
But that's not even the impressive part. Because they made those changes at the same time they were reducing their employee count by 75%. And, while there's been plenty of entertaining chaos and mayhem on the platform, there were few if any notable service outages.
So not only did they cut their cloud usage, but they seem to have done it without incurring any "complexity" penalty – which of course would have required them to increase their hiring and other expenses. As an example, they claim to be saving another 13.9 million dollars a year through reconfiguring their network backbone.
Naturally, I couldn't throw such ideas at you without the earnest warning that you should never try this yourself at home. Or possibly even at work. What seems to have worked for X might not be a good fit for your organization.
But I can definitely tell you that it's not just X that we're talking about here. 37 Signals – the creators of Basecamp and Hey – expect to save around 7 million dollars over the five years following their 2022 pull-back from AWS.
The market intelligence firm IDC has noted that, in its experience, cloud repatriation has been visible since all the way back in the cloud's early days. They claim to have seen repatriation on some level within around 70 or 80 percent of companies each year.
But we're not necessarily talking about completely abandoning the cloud. Rather, it's a matter of understanding which workloads belong in the cloud and which on-premises or in colocation facilities.
As a rule, the cloud is a great place to test new workloads and smooth out the kinds of unpredictable demand you see in early deployments. But as you grow, cloud costs could increase to the point where, for at least some services, you can do it cheaper "at home".
And keep in mind that cloud migrations that weren't sufficiently planned and executed or went all-in rather than some form of a hybrid deployment are likely to fail over time. Proper preparation and planning are crucial.
As an Andreessen Horowitz report put it: "You're crazy if you don’t start in the cloud; you're crazy if you stay on it."
From here, your job will be to assess your current deployment profile and, if there are elements that need improving, begin mapping out your repatriation plan.
_T_here's much more technology goodness available__ for you through the books and courses available at bootstrap-it.com