By Yan Cui
A funny moment (at 38:50) happened during Tim Bray’s session (SRV306) at re:invent 2017. Tim asked the audience if we should have many single-purposed functions, or fewer monolithic functions, and there was an equal split in opinions.
This was a moment that challenged my belief, as I’ve been brought up on the SOLID principles.
- Single Responsibility Principle
- Open/Closed Principle
- Liskov Substitution Principle
- Interface Segregation Principle
- Dependency Inversion Principle
I have, for a long time, believed that following the Single Responsibility Principle (SRP) is a no-brainer.
That prompted this closer examination of the arguments from both sides.
Full disclosure: I am biased in this debate. If you find flaws in my thinking, or disagree with my views, please point them out in the comments.
By “monolithic functions,” I mean functions that have internal branching logic. These functions can do one of several things based on the invocation event.
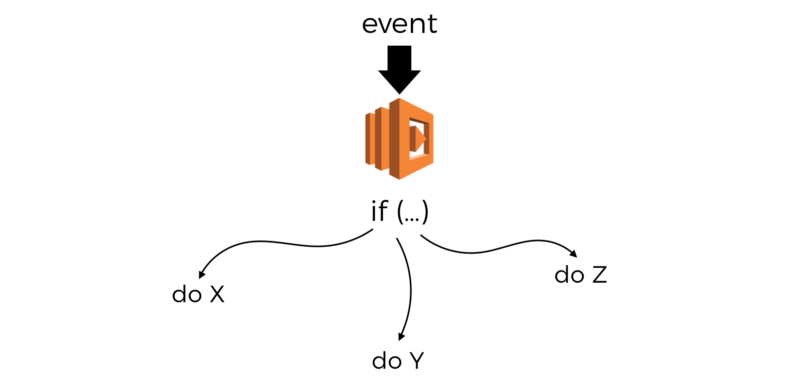
For example, you can have one function handle all the endpoints for an API. The function would perform a different action based on the path and method parameters.
module.exports.handler = (event, context, cb) => { const path = event.path; const method = event.httpMethod;
if (path === '/user' && method === 'GET') { .. // get user } else if (path === '/user' && method === 'DELETE') { .. // delete user } else if (path === '/user' && method === 'POST') { .. // create user } else if { .. // other endpoints & methods }}
You can’t rationally reason about and compare solutions without first understanding the problem and what qualities are most desirable in a solution.
And when I hear complaints such as that “having so many functions is hard to manage,” I wonder what does manage entail?
- Is it to find specific functions you’re looking for?
- Is it to discover what functions you have?
- Does this become a problem when you have 10 functions or 100 functions?
- Does it become a problem only when you have more developers working on them than you’re able to keep track of?
Drawing from my own experiences, the problem has less to do with what functions we have. Rather, it’s about discovering what features and capabilities we possess through these functions.
After all, a Lambda function, like a Docker container, is a conduit to deliver some business feature or capability.
You wouldn’t ask “Do we have a get-user-by-facebook-id function?” since you would need to know what the function was called without even knowing if the capability exists and if it’s captured by a Lambda function. Instead, you would probably ask, “Do we have a Lambda function that can find a user based on his/her facebook ID?”
So the real problem is that, given that we have a complex system that consists of many features and capabilities, that is maintained by many teams of developers, how do we organize these features and capabilities into Lambda functions so that it’s optimized towards:
- discoverability: how do I find out what features and capabilities exist in our system?
- debugging: how do I quickly identify and locate the code I need to look at to debug a problem? For example, there are errors in system X’s logs, where do I find the relevant code to start debugging the system?
- scaling the team: how do I minimize friction and grow the engineering team while maintaining the code?
Below are the qualities that are most important to me. With this knowledge, I can compare different approaches and see which is best suited for me.
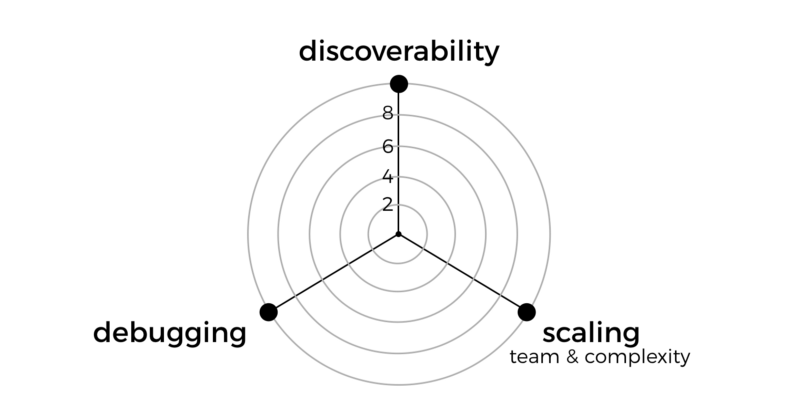
You might care about different qualities. For example, you might not care about scaling the team, but cost is an important consideration for you. Whatever they might be, it’s helpful to make those design goals explicit. You should also make sure they’re shared with and understood by your team.
Discoverability
The lack of discoverability is not a new problem. According to Simon Wardley, it’s rather rampant in both government as well as the private sector. Most organizations lack a systematic way for teams to share and discover each other’s work.
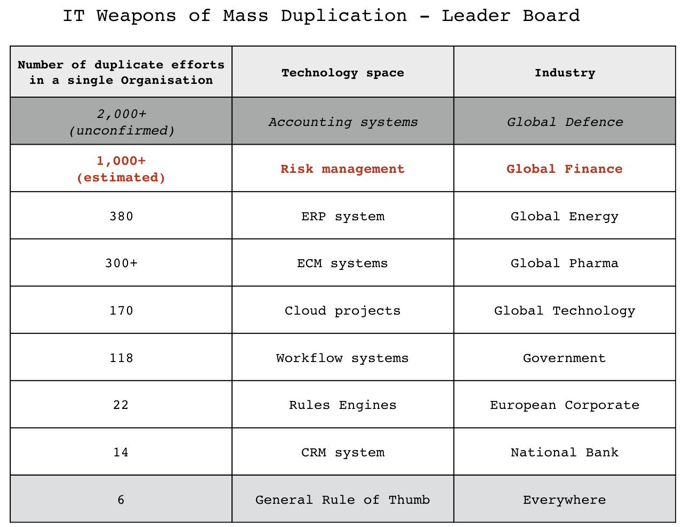 courtesy of Simon Wardley’s posts on Twitter
courtesy of Simon Wardley’s posts on Twitter
As stated earlier, discovery is about finding out what capabilities are available through your functions. Knowing what functions you have is not enough.
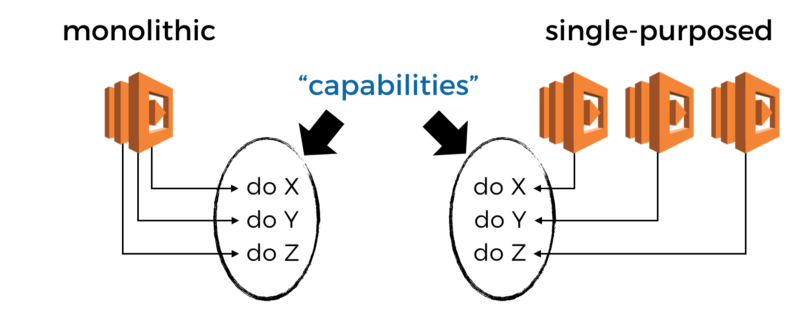 Ask not what functions you have, ask rather what your functions can do.
Ask not what functions you have, ask rather what your functions can do.
An argument I often hear for monolithic functions is that it reduces the number of functions, which makes them easier to manage.
On the surface, this seems to make sense. But the more I think about it, the more the argument appears flawed. The number of functions would only be an impediment IF we try to manage them by hand rather than using the tools available to us already.
After all, we are able to locate books by their content in a huge physical space with tens of thousands of books. Using the library analogy, with the tools available to us, we can catalogue our functions and make them easy to search.

For example, the Serverless framework enforces a simple naming convention of {service}-{stage}-{function}. This simple convention makes it easy to find related functions by prefix. If I want to find all the functions that are part of a user API, I can do that by searching for user-api.
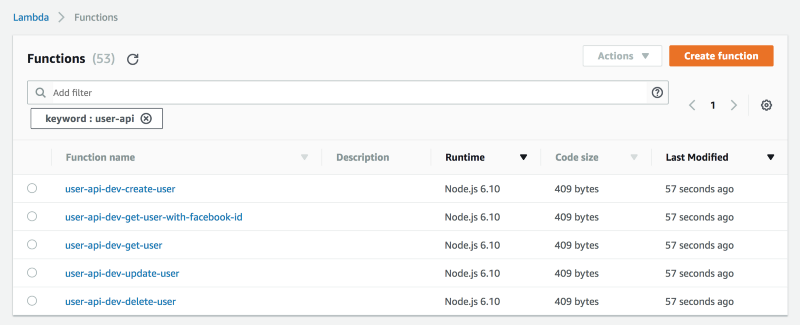
With tags, we can catalogue functions across multiple dimensions. For example, we can catalogue using environment, feature name, event source, author, and so on.
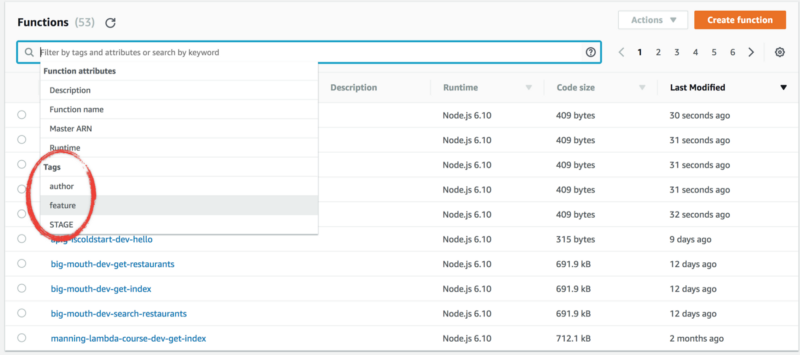 _By default, the Serverless framework adds the STAGE tag to all of your functions. You can also add your own tags as well, see [documentation](https://serverless.com/framework/docs/providers/aws/guide/functions/#tags" rel="noopener" target="blank" title=") on how to add tags.
_By default, the Serverless framework adds the STAGE tag to all of your functions. You can also add your own tags as well, see [documentation](https://serverless.com/framework/docs/providers/aws/guide/functions/#tags" rel="noopener" target="blank" title=") on how to add tags.
 The Lambda management console also gives you a handy dropdown list of the available values when you try to search by a tag.
The Lambda management console also gives you a handy dropdown list of the available values when you try to search by a tag.
If you have a rough idea of what you’re looking for, then the number of functions is not an impediment to your ability to discover what’s there.
With single-purposed functions, the capabilities of the user-api is immediately obvious. I can see from the relevant functions that I have the basic CRUD capabilities, because there are corresponding functions for each.
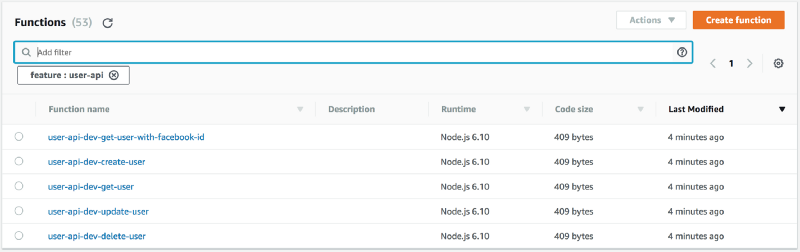 I can see what capabilities I have as part of the suite of functions that make up the user-api feature.
I can see what capabilities I have as part of the suite of functions that make up the user-api feature.
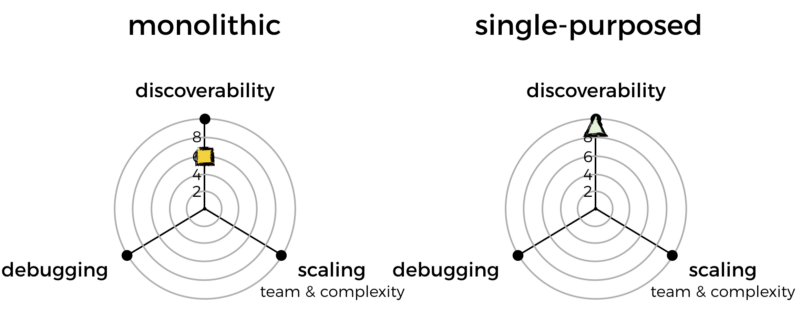
With a monolithic function, however, it’s not so straightforward. There is only one function, but what can this function do? I’ll have to either look at the code myself, or consult with the author of the function. For me, this makes for poor discoverability.

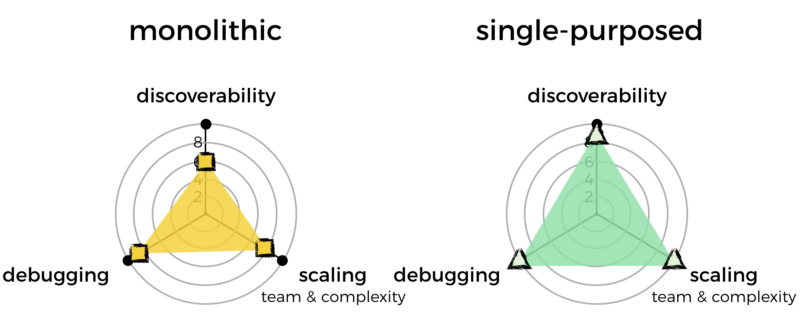
Because of this, I mark the monolithic approach down on discoverability.
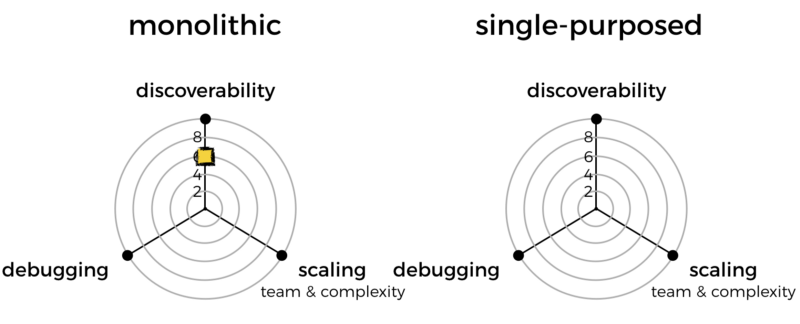
But, having more functions means there are more pages for you to scroll through. This can be laborious if you just want to browse and see what functions are there.
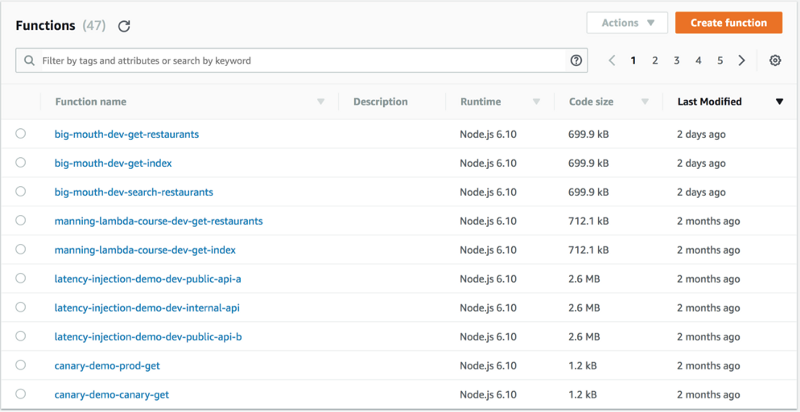
Although, in my experience, this has never been a problem per se. Thanks to the Serverless framework’s naming convention, all related functions are close together. It’s actually quite nice to see what each group of functions can do, rather than having to guess what goes on inside a monolithic function.
But, it can be a pain to scroll through everything when you have thousands of functions. So, I’m going to penalize single-purposed functions for that.
At that level of complexity, though, packing more capabilities into each function would only make the system more difficult to understand. Say you have a thousand functions, and you know what each does at a glance. Wouldn’t it be simpler if you replace them with a hundred functions, but you can’t tell what each does?
Debugging
For debugging, the relevant question is whether having fewer functions makes it easier to identify and locate the bug.
In my experience, the path from an error to the relevant function and repo is the same, regardless of whether the function does one thing or many things.
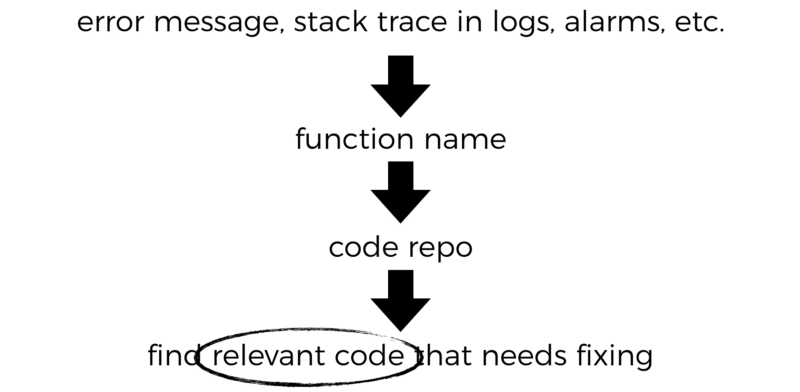
The difference is how to find the relevant code inside the repo for the problems you’re investigating.
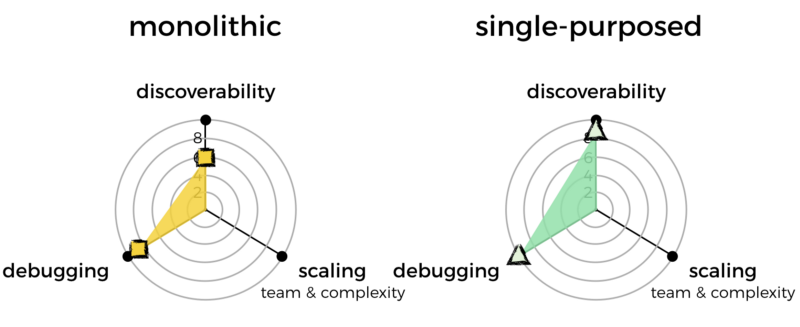
A monolithic function has more branching logic. So it would take more cognitive effort to follow through to the code that is relevant to the problem at hand.
For that, I’ll mark monolithic functions down slightly. Of course, we’re talking about a minimal difference here, which is why the penalty is also minimal.
Scaling
In the early days of microservices, one of the arguments for microservices was that it makes scaling easier.
But that’s not the case!
If you know how to scale a system, then you can scale a monolith as easily as you can scale a microservice.
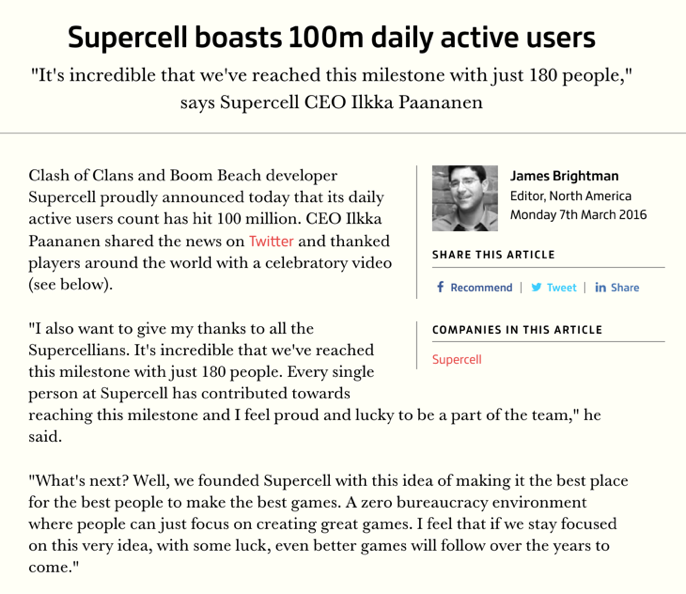
I say that as someone who has built monolithic backend systems for games that had a million Daily Active Users (DAU). Supercell, the creator of top grossing games like Clash of Clans and Clash Royale, have well over 100 million DAU. The backend systems for these games are all monoliths, and Supercell has no problems scaling these systems.
Instead, tech giants such as Amazon and Google taught us that microservices make it easier to scale in a different dimension — our engineering team.
This style of architecture allows us to create boundaries within our system, around features and capabilities. It allows our engineering teams to scale the complexity of what they build, because they can more easily build on top of the work that others have created before them.
Take Google’s Cloud Datastore as an example. The engineers in that team were able to produce a sophisticated service by building on top of many layers of services. Each layer provides a powerful abstractions the next layer can leverage.
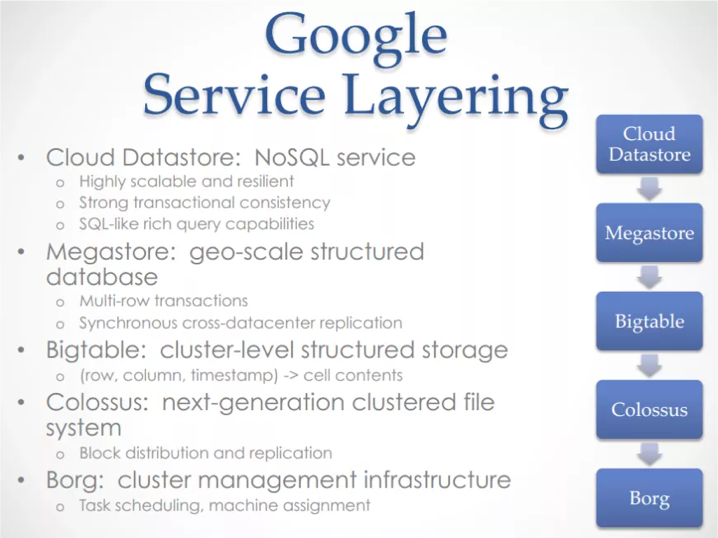 _[http://bit.ly/2CQx3C4](http://bit.ly/2CQx3C4" rel="noopener" target="blank" title=")
_[http://bit.ly/2CQx3C4](http://bit.ly/2CQx3C4" rel="noopener" target="blank" title=")
These boundaries give us a greater division of labour. Which allows more engineers to work on the system by giving them areas where they can work in relative isolation. This way, they don’t trip over each other with merge conflicts, integration problems, and so on.
Michael Nygard also wrote a nice article that explains this benefit from another angle: that these boundaries and isolation helps us reduce the overhead of sharing mental models.
“If you have a high coherence penalty and too many people, then the team as a whole moves slower… It’s about reducing the overhead of sharing mental models.”
- Michael Nygard
Having lots of single-purposed functions is perhaps the pinnacle of that division of tasks. You lose that division a little when you move to monolithic functions. Although in practice, you probably won’t have so many developers working on the same project that you feel the pain.
Restricting a function to doing one thing also helps limit how complex a function can become. To make something more complex, you would compose these simple functions together via other means, such as with AWS Step Functions.
I’ll mark monolithic functions down for losing some division of labour, and for raising the complexity ceiling of a function.
Conclusion
Based on the criteria that are important to me, having many single-purposed functions is the better way to go. But I do not see this as a hard and fast rule.
Like everyone else, I come preloaded with a set of predispositions and biases formed from my experiences, which likely do not exactly reflect yours. I’m not asking you to agree with me. Though I do hope you appreciate the process of working out what’s important to you so you can go about finding the right approach for you.
But what about cold starts? Wouldn’t monolithic functions help you reduce the number of cold starts?
The short answer is no, they don’t help you with cold starts in any meaningful way. It’s also the wrong place to optimize for cold starts. If you’re interested in the longer version of this answer, then please read my other post here.
And lastly, having smaller surface areas with single-purposed functions reduces the attack surface. You can give each function the exact permission it needs and nothing more. This is an important, but often underappreciated advantage of single-purposed functions.