


Оригінальна публікація: Lexical Scope in JavaScript – Beginner's Guide
У цій статті ми дізнаємось, що таке лексична область видимості, розглянувши декілька корисних прикладів.
Також ми обговоримо, яким чином JavaScript компілює та виконує програми.
Вкінці ми поговоримо про те, яким чином можна використовувати лексичну область для пояснення помилок неоголошених змінних чи посилання.
Без зайвих слів, почнемо.
Зміст
- Як JavaScript виконує програми?
- Як JavaScript парсить/компілює та виконує код
- Розуміння помилки синтаксису
- Розуміння піднесення змінних та функцій
- Що таке лексична область?
- Розуміння лексичної області
- Підсумки
Як JavaScript виконує програми?
Перед тим як розбиратися, як JavaScript виконує код/програму, ми розглянемо різні кроки, що залучені у будь-якому процесі компіляції з точки зору теорії компілятора.
Для будь-якої мови компілятор виконує такі операції:
Токенізація/лексування
Під час цього процесу вся програма розділяється на ключові слова, які називаються токенами. Наприклад, розглянемо інструкцію let temp = 10: коли виконується токенізація, вона ділить інструкцію на такі ключові слова: let, temp, =, 10.
Лексування та токенізація є взаємозамінними термінами, але між ними є невелика різниця. Лексування — це процес токенізації, який також перевіряє, чи він сам має розглядатися як окремий токен. Ми можемо вважати лексування «розумною» версією токенізації.
Парсинг
Це процес збирання всіх токенів, згенерованих під час попереднього кроку та їх перетворення у структуру вкладеного дерева, що представляє код з граматичної точки зору.
Цю структуру дерева називають абстрактним синтаксичним деревом (AST).
Генерування коду
Цей процес конвертує AST у код, який може прочитати машина.
Це був короткий огляд того, як компілятор працює та генерує машинний код.
Звісно, в компіляції є більше кроків ніж описано вище, але опис інших кроків компіляції знаходиться поза темою цієї статті.
Найважливішим спостереженням щодо виконання коду JavaScript є той факт, що в межах виконання коду відбуваються дві фази:
- Парсинг
- Виконання
Перед тим, як ми перейдемо до лексичної області, важливо розуміти, як JavaScript виконує програму. У наступному розділі ми детальніше розберемо, як працюють ці дві фази.
Як JavaScript парсить/компілює та виконує код

Спочатку обговоримо фазу парсингу. Під час цієї фази двигун JavaScript оглядає всю програму, призначає змінні до відповідних областей та перевіряє наявність помилок. Якщо він знаходить помилку, виконання програми зупиняється.
Під час наступної фази відбувається виконання коду.
Для того, щоб краще зрозуміти цей процес, розглянемо детальніше два сценарії:
- Синтаксична помилка
- Піднесення змінної
Синтаксична помилка
Найкращий та найпростіший спосіб показати, як JS спочатку парсить, а потім виконує програму, — показати поведінку синтаксичної помилки.
Розглянемо такий помилковий код:
const token = "ABC";
console.log(token);
//Синтаксична помилка:
const newToken = %((token);Програма вище видасть синтаксичну помилку в останньому рядку. Помилка буде виглядати ось так:
Uncaught SyntaxError: Unexpected token '%'
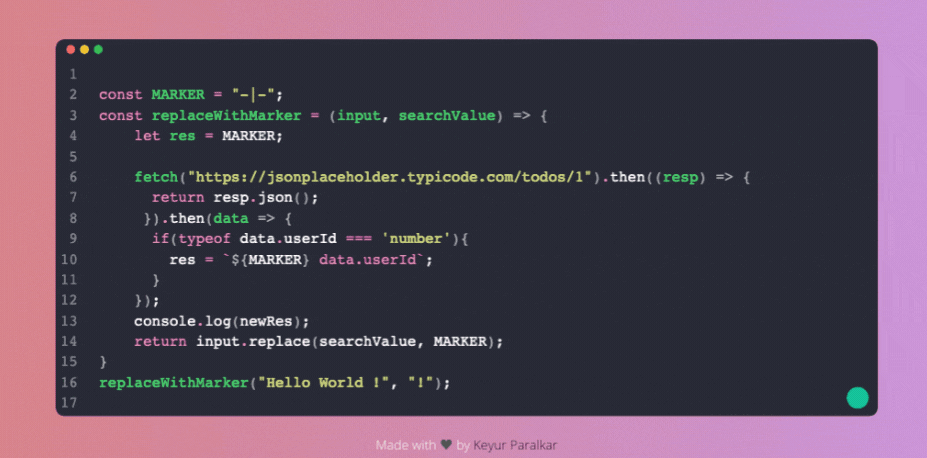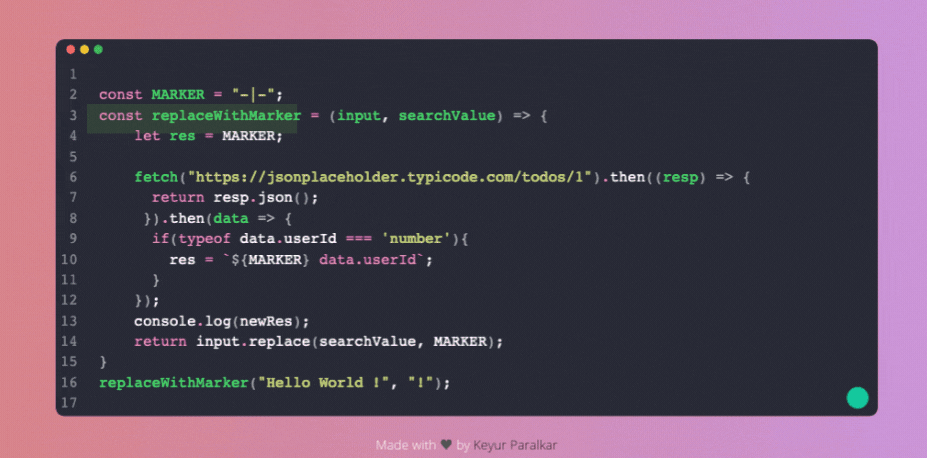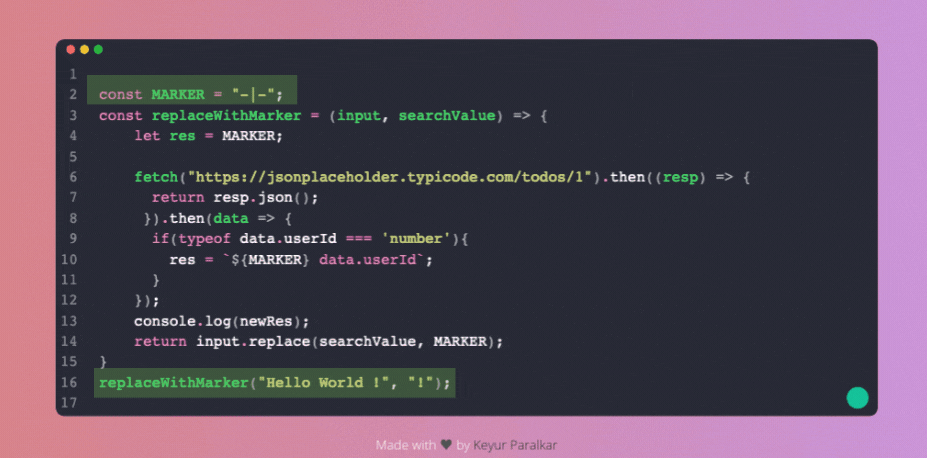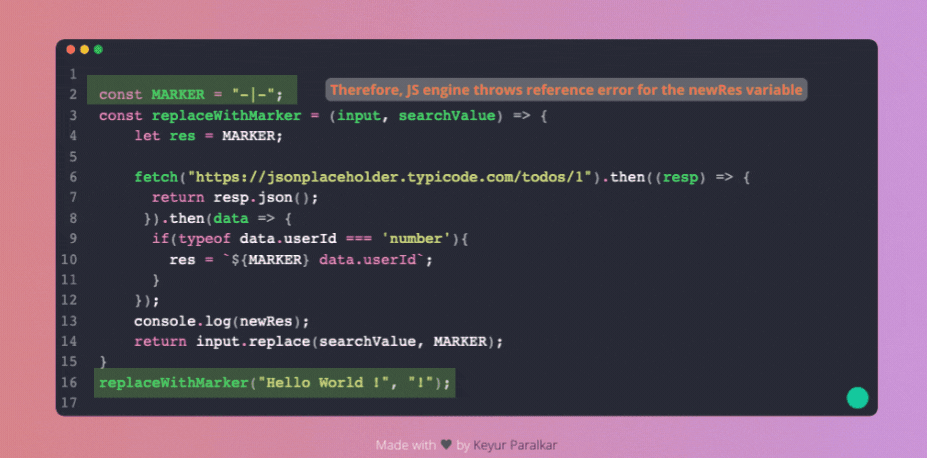
JavaScript не виконує console.log. Натомість він проходить через всю програму наступним чином:
- Рядок 1: знайдено оголошення та визначення змінної. Збережено посилання на змінну
tokenв поточній області, яка є глобальною. - Рядок 2: двигун JavaScript побачив, що змінна
tokenвикористовується. Спочатку він звертається до поточної області з метою перевірити, чи присутня зміннаtoken. Якщо вона присутня, то посилається на оголошення змінноїtoken. - Рядок 3: двигун побачив, що змінна
newTokenбула оголошена та визначена. Він перевірив, чи змінна під назвоюnewTokenвже існувала у поточній області. Якщо так, двигун видає помилку посилання. Якщо ні, двигун зберігає посилання на цю змінну в поточній області. - У тому ж рядку двигун побачив, що він намагався посилатися на змінну
%((token). Також він помітив, що назва почалася з символу%, а назви змінних не можуть починатися з резервованих ключових слів, тому двигун видав синтаксичну помилку.
Піднесення змінних та функцій
Піднесення — це механізм, завдяки якому всі змінні у своїх відповідних областях «підіймаються», тобто стають доступними зверху.
Поглянемо на приклад нижче, який покаже, що піднесення відбувається під час фази парсингу і потім відбувається виконання:
doSomething();
function doSomething(){
console.log("How you doing?");
}В прикладі вище, двигун проходить всю програму у такій послідовності:
- Рядок 1: двигун JavaScript потрапив нa функцію під назвою
doSomething. Він перевірив, чиdoSomethingдоступна в поточній області. Якщо так, він посилається на функцію, в інакшому випадку він видає помилку посилання. - Виявилось, що під час фази парсину двигун знайшов
function doSomethingу поточній області. Як наслідок, він додав посилання на змінну в поточну область та зробив її доступною в межах всієї програми. - Вкінці функція
doSomethingдрукує рядокHow you doing?.
Виходячи з пояснення вище, спочатку код парсувався, щоб згенерувати проміжний код, який забезпечує доступ до посилання на змінні та функції в поточній області.
В наступній фазі JavaScript знає про існування функції та починає її виконувати.
З прикладів наведених вище, ми можемо впевнено дійти до висновку, що двигун JavaScript робить наступні кроки перед виконанням коду:
- Парсить код.
- Генерує проміжний код, що описує доступні змінні та функції.
- Використовуючи цей проміжний код, двигун починає виконання програми.
Що таке лексична область?
Процес визначення областей змінних та функцій під час виконання називається лексичною областю. Слово лексична походить від лексичної фази/фази токенізації компіляції JavaScript.
Протягом часу виконання JavaScript робить дві дії: парсинг та виконання. Як ми дізналися в попередньому розділі, під час фази парсингу визначаються області змінних та функцій. Тому й було важливо спочатку зрозуміти, як працює фаза парсингу у виконанні коду, оскільки вона закладає фундамент для розуміння лексичної області.
Простими словами, під час фази парсингу відбувається створення лексичної області.
Тепер, коли ми знаємо основи, розглянемо основні характеристики лексичної області:
По-перше, під час фази парсингу, область призначається/посилається на змінну там, де вона оголошена.
Наприклад, розглянемо сценарій, коли змінна згадується у внутрішній функції, а її оголошення знаходиться в глобальній області. У цьому випадку внутрішня змінна призначена з зовнішньою областю, що є глобальною областю.

Потім, під час призначення області до змінної, двигун JavaScript перевіряє батьківські області на наявність змінної.
Якщо змінна присутня, батьківська область застосовується до змінної. Якщо змінна не знайдена в цих областях, двигун видає помилку посилання.
Поглянемо на ілюстрацію знизу, яка показує, як відбувається пошук області змінної.
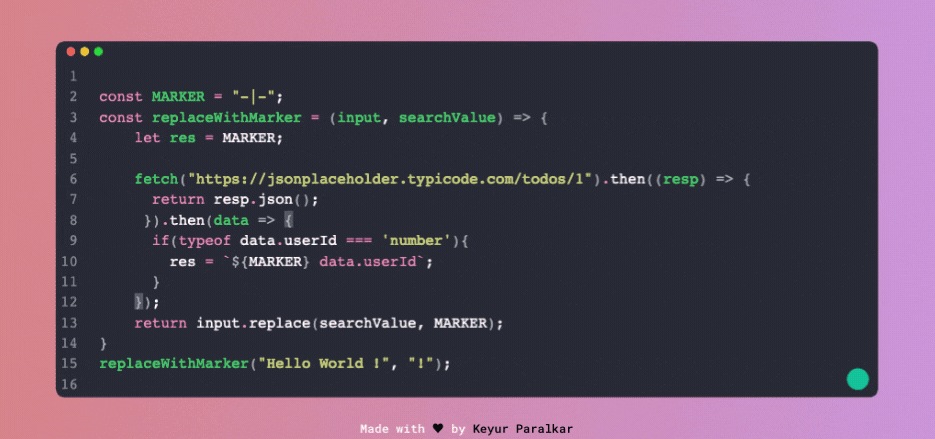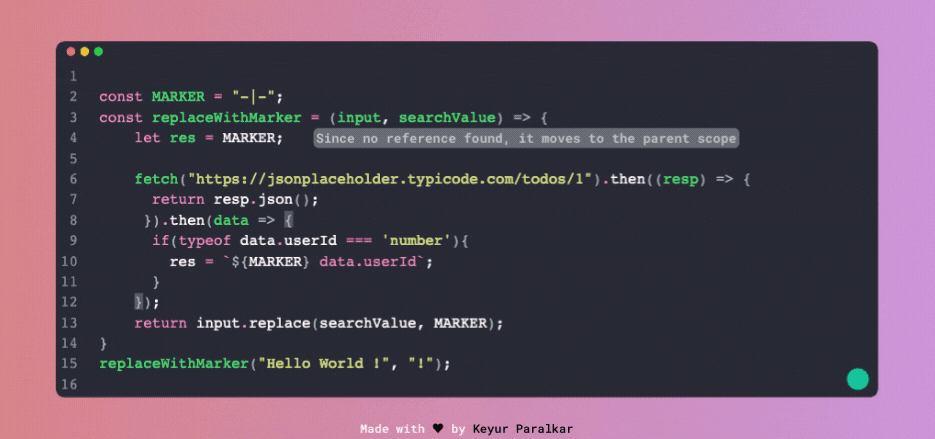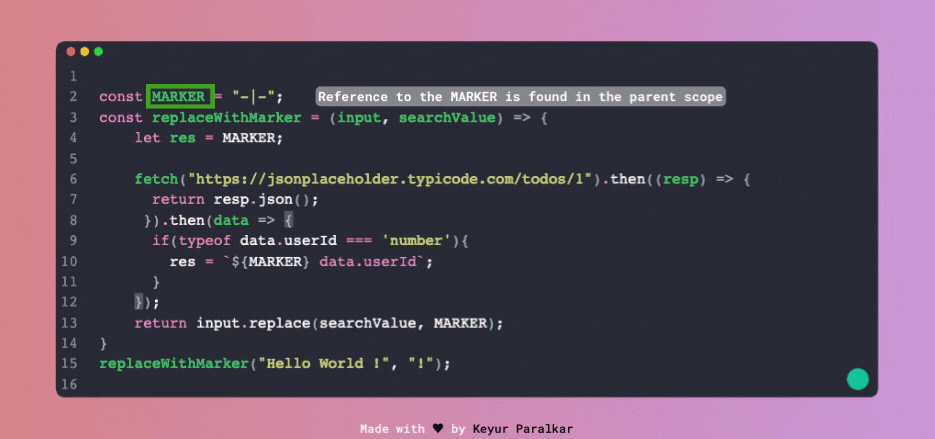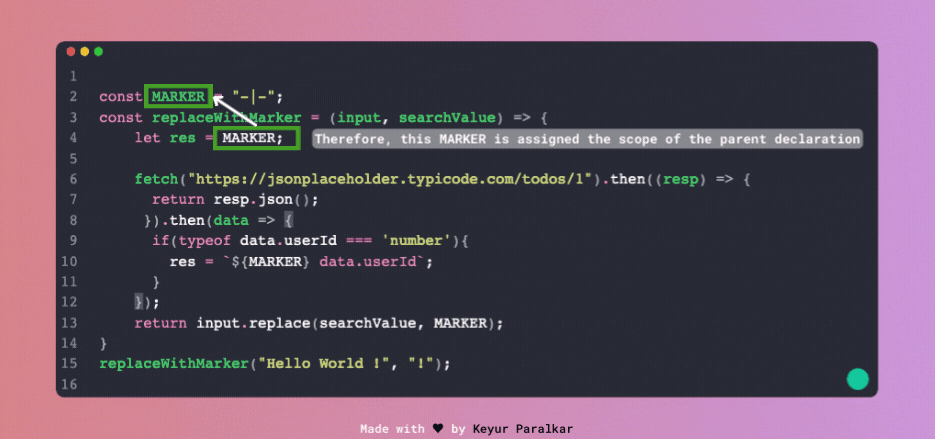
А ця ілюстрація показує, як двигун JS намагається знайти змінну, яка не існує в жодній області:
Розуміння лексичної області
У розділі вище ми дали визначення лексичній області. Також ми розібралися з її характеристиками.
У цьому розділі ми розглянемо лексичну область на прикладі. Як то кажуть, складні теми завжди легше зрозуміти на реальних прикладах.
Приклад, який ми розглянемо, полягає у забарвленні часток коду, які мають схожі області. Звучить незрозуміло, але дозвольте продемонструвати простою ілюстрацією.

Розберемо, що відбувається на цій ілюстрації.
У нашій програмі знаходяться:
empData: масив об’єктів.allPositions: масив рядків що описує посади працівників.- Інструкція, яка друкує змінні
allPositions.
Тепер поглянемо, що відбувається під час фази парсингу цієї програми:
- Двигун починає з першого рядка і він потрапляє на оголошення змінної
empData. - Потім двигун провіряє, чи
empDataдоступна в поточній області. Оскільки схожої змінної не знайдено, він шукає наявність цієї змінної в батьківських областях. - Двигун зупиняє свій пошук, оскільки немає доступних областей і поточна область є глобальною.
- Далі двигун призначає значення
undefinedдо змінноїempDataпід час фази парсингу, щоб у випадку, коли щось у внутрішніх областях намагається посилатися на змінну, її можна було викликати. - Права частина оператора присвоєння «розв’язується» під час фази виконання програми.
- Подібним чином двигун присвоює значення
undefinedдо змінноїallPositions. - Але на правій частині ми також посилаємось на змінну
empData. На цьому етапі двигун провіряє, чи змінна доступна в поточній області. Оскільки вона доступна, на неї далі йде посилання (тобто вона доступна у глобальній області). - Двигун досі на правій частині оператора присвоєння, бо він помітив стрілкову функцію всередині функції «map». Оскільки двигун натрапив на визначення функції, він створює нову область. В ілюстрації ця область позначена цифрою 2.
- Оскільки це нова область, ми даємо їй чорний колір.
- Ця стрілкова функція має аргумент
dataта повертаєdata.position. У фазі парсингу, двигун підіймає всі потрібні змінні, посилавшись на змінні, доступні в поточній області, а також батьківській. - Всередині цієї функції згадується змінна
data, тому двигун провіряє, чи поточна область має цю змінну. Оскільки змінна присутня в поточній області, посилання йде туди ж. - Коли двигун потрапляє на фігурну дужку
}, він покидає функціональну область. - Вкінці програми знаходиться інструкція, яка друкує змінні
allPositions. Оскільки згадується зміннаallPositions, двигун шукає її в поточній області (тобто глобальній області). Оскільки вона знайдена, вона посилається туди ж в інструкціїconsole.
Підсумки
У цій статті ми ознайомилися з лексичною областю та розібралися, як вона працює, розглянувши простий приклад з забарвленням.
Дякую, що прочитали!