

기사 원문: How to create, read, update and search through Excel files using Python
이 글은 파이썬으로 엑셀 파일을 작업하는 방법과 특정 데이터를 수정하는 방법을 자세하게 보여줄 것입니다.
먼저 우리는 CSV 파일들을 읽고 쓰고 업데이트하는 방법을 배울 것입니다. 그리고나서 엑셀(xlsx) 파일들을 읽거나 스프레드 시트로 필터링 하고, 행/열을 검색하고 셀(cell)을 업데이트 하는 방법을 살펴 볼 것입니다.
가장 간편한 스프레드시트(spreadsheet) 형태인 CSV로 시작해봅니다.
파트 1 - CSV 파일
CSV 파일은 쉼표로 구분된 값(comma-separated values)을 가진 파일로써 간단한 문자 데이터가 행열을 갖춘 형태(tabluar format)로 보여질 수 있습니다. 어떠한 스프레드시트 프로그램에서도 사용할 수 있는데 예를 들어 마이크로소프트 오피스 엑셀, 구글 스프레드시트, 또는 LibreOffice Calc 등이 있습니다.
하지만 CSV 파일들은 다른 스프레드시트 파일과 같진 않은데, 왜냐하면 사용자로 하여금 셀이나 행/열, 또는 수식을 저장하게 허용하지 않기 때문입니다. 이러한 한계는 파일 하나당 하나의 시트만 저장할 수 있게 허용하는 것으로도 나타납니다. 이 글의 첫번째 파트는 Python 3와 표준 라이브러리 모듈인 CSV를 이용해서 CSV 파일을 생성하는 방법을 보여드리고자 합니다.
이 튜토리얼은 두 개의 깃허브(GitHub) 리포들(repositories)과 이 튜토리얼 두번째 파트의 (특정 목적이 되도록 업데이트되고 수정된) 코드를 실제로 사용하는 라이브 웹 어플리케이션으로 끝나게 될 것입니다.
CSV 파일에 작성하기
첫번째로 새로운 파이썬 파일을 열고 파이썬 CSV 모듈을 불러오세요.
import csv
CSV 모듈
CSV 모듈은 모든 필수 메소드들을 내장(built in)하여 포함합니다. 그 안에는:
- csv.reader
- csv.writer
- csv.DictReader
- csv.DictWriter
- 그리고 기타 등등이 포함되어 있습니다.
이번 가이드에서 우리는 writer, DictWriter, DectReader 메소드에 초점을 맞출 것입니다. 이것들은 사용자들이 어떤 CSV 파일을 수정하고 변경하여 저장된 데이터를 조작하도록 허용합니다.
첫번째 단계에서 우리는 파일 이름을 정의하고 하나의 변수로 저장하는 것이 필요합니다. 반드시 헤더와 데이터 정보가 일치하게 해야 합니다.
filename = "imdb_top_4.csv"
header = ("Rank", "Rating", "Title")
data = [
(1, 9.2, "The Shawshank Redemption(1994)"),
(2, 9.2, "The Godfather(1972)"),
(3, 9, "The Godfather: Part II(1974)"),
(4, 8.9, "Pulp Fiction(1994)")
]
이제 우리는 세 개의 변수(header, data, filename)를 받아오게 될 writer라는 이름의 어떤 함수를 생성해야 합니다.
def writer(header, data, filename):
pass
그 다음 단계는 writer 함수를 수정하여 어떤 파일을 생성하고 header, data 변수에서 데이터를 가져오게 하는 방법입니다. 이것은 header 변수의 첫번째 행을 작성하고 이어서 그 다음 data 변수의 네 줄을 작성하는 것으로 완료됩니다 (네 줄이 있는 이유는 배열(list) 안에 네 개의 튜플(tuples)이 있기 때문입니다).
def writer(header, data, filename):
with open (filename, "w", newline = "") as csvfile:
movies = csv.writer(csvfile)
movies.writerow(header)
for x in data:
movies.writerow(x)
공식 파이썬 문서에서 csv.writer 메소드가 동작하는 방법을 설명하고 있습니다. 정말 시간을 내서 읽어보길 추천드려요.
짜잔! imdb_top_4.csv라는 첫번째 파일을 생성하였습니다. 선호하는 스프레트시트 도구로 이 파일을 열어보면 아래와 같이 보일 것입니다:
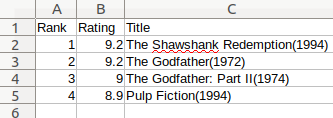
결과를 보기 위해 LebreOffice Calc를 사용한 모습.
해당 결과는 다른 도구에서 파일을 열어본다면 아래와 같이 쓰여져 있을 수도 있습니다:
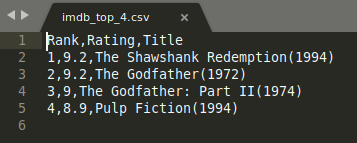
결과를 보기 위해 SublimeText를 사용한 모습.
CSV 파일 수정
이 파일을 수정하기 위해서는 updater라는 이름의 새로운 함수를 만들어서 filename이라는 하나의 변수만 받아오게 할 것입니다.
def updater(filename):
with open(filename, newline= "") as file:
readData = [row for row in csv.DictReader(file)]
# print(readData)
readData[0]['Rating'] = '9.4'
# print(readData)
readHeader = readData[0].keys()
writer(readHeader, readData, filename, "update")
이 함수는 먼저 filename 변수에 정의된 파일을을 열고 그 다음에 readData라고 이름된 변수 안에 파일로부터 읽어온 모든 데이터를 저장합니다. 두번째 단계는 새로운 변수를 강제로 입력하고 그것을 readData[0]['rating'] 위치에 있는 구 데이터 대신 바꿔 넣기 위한 방법입니다.
이 함수의 마지막 단계는 사용자가 어떤 수정을 하고 있다는 것을 말하는 새로운 변수 update를 더하여 writer 함수를 호출하는 것입니다.
csv.DictReader 관련 더 많은 내용은 여기 파이썬 공식 문서에 설명되어 있습니다.
writer가 새로운 변수로 작동하게 하려면 writer가 정의된 모든 곳에 새로운 변수를 추가 해줘야 합니다. writer 함수를 처음 호출한 지점으로 돌아가서 "write"를 새로운 변수로 더해주세요:
writer(header, data, filename, "write")
바로 아래 writer 함수가 updater를 호출하고 filename 변수를 그 안으로 넘겨 주는 것을 찾으세요:
writer(header, data, filename, "write")
updater(filename)
이제 우리는 writer 함수가 option이라는 이름의 새로운 변수를 받아오게 변경해야 합니다:
def writer(header, data, filename, option):
이제부터 우리는 writer 함수에서 서로 다른 두 개의 옵션들(write와 update)을 받아오길 예상하겠습니다. 이것 때문에 우리는 두 개의 if문을 더해서 이렇게 설정한 새로운 기능을 지원하도록 해야 합니다. if option == "write": 아래 함수 첫번째 부분은 이미 기존에 알고 있는 내용입니다. 코드의 elif option == "update": 영역과 바로 아래에 쓰여진 else 부분 코드를 더하기만 하면 됩니다:
def writer(header, data, filename, option):
with open (filename, "w", newline = "") as csvfile:
if option == "write":
movies = csv.writer(csvfile)
movies.writerow(header)
for x in data:
movies.writerow(x)
elif option == "update":
writer = csv.DictWriter(csvfile, fieldnames = header)
writer.writeheader()
writer.writerows(data)
else:
print("Option is not known")
만세! 완성했어요!
이제 코드는 아래와 같이 보일 것입니다:
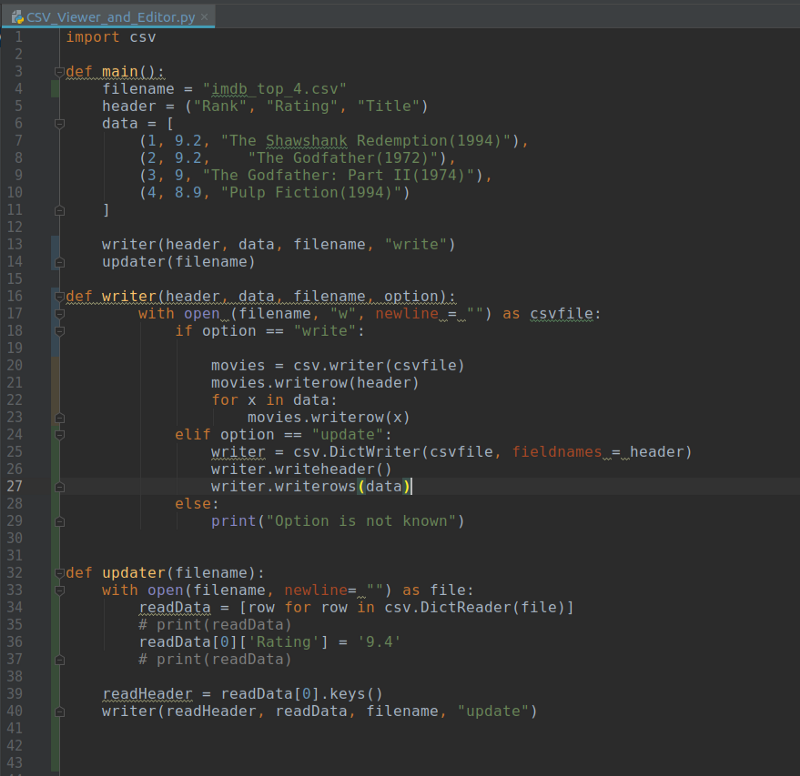
코드; 입출력을 담당하는 main 함수 아래 writer와 updater 함수가 있습니다. writer 함수는 csv 파일을 불러올 때 write와 update옵션을 같이 선택할 수 있도록 if-elif-else문을 사용합니다. 반면 updater 함수는 filename 변수 하나만 가지고 있으며 readData[0]['rating'] 위치에 있는 데이터를 강제로 변경합니다.
이곳에서 코드를 찾으실 수도 있습니다: https://github.com/GoranAviani/CSV-Viewer-and-Editor
이 글을 첫번째 파트에서 우리는 CSV 파일을 어떻게 다루는지 보았습니다. 파일 하나를 생성해서 수정해 보았습니다.
파트 2 - 엑셀(xlsx) 파일
주말 몇 번에 이어 이 프로젝트를 진행하고 있습니다. 처음 시작은 저희 회사에 이와 같은 솔루션이 필요해서였습니다. 첫번째 생각은 이 해결책을 직접 저희 회사 시스템에 구축하는 것이었으나, 그러면 저는 글에 아무것도 쓰지 못하겠네요 그렇죠?
저는 Python 3와 openpyxl 라이브러리를 사용해 솔루션을 만들었습니다. 제가 openpyxl 을 선택한 이유는 워크시트(worksheets)를 생성하고 불러와 업데이트하고 이름을 변경하거나 삭제하는 데 있어서 완벽한 솔루션이기 때문입니다. 또한 우리가 행렬을 읽고 쓰고, 셀을 병합하거나 병합 해제하고, 파이썬 엑셀 차트를 만드는 등의 기능을 허용하는 방법입니다.
Openpyxl 용어와 기본 정보
- Workbook은 Openpyxl에서 엑셀 파일 이름입니다.
- 하나의 workbook은 기본 하나 (이상 여러개) sheet로 구성됩니다. sheet는 이름으로 참조됩니다.
- 하나의 sheet는 숫자 1부터 시작하는 행(가로 선)과 문자 A로 시작하는 열(세로 선)로 구성됩니다.
- 행렬은 격자 구조를 이루어 셀을 형성하고 그 안에 어떤 데이터 (수치 또는 문자 값) 또는 공식을 담을 수 있습니다.
Openpyxl은 문서화가 잘 되어 있으니 여기를 한번 살펴보시길 추천드립니다.
첫번째 단계는 파이썬 환경을 열고 터미널 안에 openpyxl 을 설치하는 것입니다:
pip install openpyxl
다음으로 openpyxl 을 프로젝트 안에 불러와서 theFile 변수로 workbook을 실행합니다.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
print(theFile.sheetnames)
currentSheet = theFile['customers 1']
print(currentSheet['B4'].value)
보시다시피 이 코드는 모든 sheet를 이름으로 출력합니다. 그리고나서 "customers 1"이라고 이름 붙여진 sheet를 선택해 currentSheet 변수로 저장합니다. 마지막 줄에서 코드는 "customers 1" sheet의 B4 자리에 위치하는 값을 출력합니다.
이 코드는 의도한 대로 동작하긴 하지만 매우 하드 코딩(hard coded)되어 있습니다. 좀 더 동적으로 만들기 위해 우리는 이러한 기능을 하는 코드를 작성하게 될 것입니다:
- 파일을 읽는다
- 모든 sheet의 이름을 가져온다
- 모든 sheet를 돌아 순환한다
- 마지막 단계에서 코드는 workbook 안에서 각각 찾아낸 sheet의 B4 영역에 위치한 값을 출력한다.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
for x in allSheetNames:
print("Current sheet name is {}" .format(x))
currentSheet = theFile[x]
print(currentSheet['B4'].value)
이전보다는 나아졌지만 여전히 하드 코딩된 솔루션이고 여전히 우리가 B4 셀을 찾아볼 것이라는 걸 가정하고 있습니다, 바보같이 말이죠.
제가 예상하기에 당신의 프로젝트는 어떤 특정 값을 위해 엑셀 파일에 있는 모든 sheet 내부를 검색할 필요가 있을 것입니다. 이를 위해 우리는 "ABCDEF" 범위 안에 하나의 for 반복문을 더한 다음 셀 이름과 값을 간단히 출력하게 할 것입니다.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
for sheet in allSheetNames:
print("Current sheet name is {}" .format(sheet))
currentSheet = theFile[sheet]
# print(currentSheet['B4'].value)
#print max numbers of wors and colums for each sheet
#print(currentSheet.max_row)
#print(currentSheet.max_column)
for row in range(1, currentSheet.max_row + 1):
#print(row)
for column in "ABCDEF": # Here you can add or reduce the columns
cell_name = "{}{}".format(column, row)
#print(cell_name)
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
우리는 "for row in range.." 반복문을 도입하여 이를 실행했습니다. for 반복문 안에 범위는 1번 행에 있는 셀에서부터 시작해서 sheet에 있는 최대 값 행까지로 정의되었습니다. 두번째 for 반복문은 사전에 정해진 열 이름 "ABCDEF" 안에서 검색을 수행합니다. 두번째 구문 안에서 우리는 셀의 위치(열 이름과 행 번호 모두)와 그 값을 보여주게 될 것입니다.
그러나, 이 글에서 저의 과제는 "telephone"이라 이름지어진 특정 열을 찾아서 해당 열의 모든 행을 훑어 가는 것입니다. 이를 위해 우리는 코드를 아래와 같이 수정할 필요가 있습니다.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
def find_specific_cell():
for row in range(1, currentSheet.max_row + 1):
for column in "ABCDEFGHIJKL": # Here you can add or reduce the columns
cell_name = "{}{}".format(column, row)
if currentSheet[cell_name].value == "telephone":
#print("{1} cell is located on {0}" .format(cell_name, currentSheet[cell_name].value))
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
return cell_name
for sheet in allSheetNames:
print("Current sheet name is {}" .format(sheet))
currentSheet = theFile[sheet]
이 수정된 코드는 모든 sheet에 모든 값을 훑어 보고 바로 전에 한 것과 같이 행의 범위가 동적이며 열의 범위가 정적입니다. 이 코드는 셀을 통해 반복되고 어떤 문자 값 "telephone"을 가지고 있는 셀을 찾게 됩니다. 한번 코드가 특정 값을 찾고 나면 사용자에게 어느 셀 안에 그 문자가 위치하고 있는지 알려줍니다. 코드는 이와 같은 행동을 그 엑셀 파일 안 모든 sheet 안에 있는 모든 셀에게 수행합니다.
다음 단계는 특정 값이 있는 모든 행을 훑고 값을 출력하는 법입니다.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
def find_specific_cell():
for row in range(1, currentSheet.max_row + 1):
for column in "ABCDEFGHIJKL": # Here you can add or reduce the columns
cell_name = "{}{}".format(column, row)
if currentSheet[cell_name].value == "telephone":
#print("{1} cell is located on {0}" .format(cell_name, currentSheet[cell_name].value))
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
return cell_name
def get_column_letter(specificCellLetter):
letter = specificCellLetter[0:-1]
print(letter)
return letter
def get_all_values_by_cell_letter(letter):
for row in range(1, currentSheet.max_row + 1):
for column in letter:
cell_name = "{}{}".format(column, row)
#print(cell_name)
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
for sheet in allSheetNames:
print("Current sheet name is {}" .format(sheet))
currentSheet = theFile[sheet]
specificCellLetter = (find_specific_cell())
letter = get_column_letter(specificCellLetter)
get_all_values_by_cell_letter(letter)
어떤 열의 문자를 찾는 get_column_letter 라는 이름의 함수를 더하여 완성되었습니다. 어떤 열의 문자를 찾은 다음에는 해당 특정 열의 모든 행을 돌아 순환합니다. 해당 셀들의 모든 값을 출력하게 될 get_all_values_by_cell_letter 함수를 통해 완성되었습니다.
마무리하며
아주 잘 했어요! 이 다음에 할 수 있는 많은 것들이 있습니다. 저의 계획은 어떤 온라인 앱을 만들어서 어떤 문자 박스에서 가져온 모든 스웨덴 전화번호를 표준화 하고 사용자에게는 같은 문자 박스에서 결과를 단지 복사만 할 수 있는 가능성을 제공하는 것이었습니다. 제 계획의 두번째 단계는 엑셀 파일을 업로드를 지원하는 웹 어플리케이션 기능을 확장해서 그 파일들 안에 있는 전화번호를 가공(즉, 스웨덴 양식으로 표준화)하고 가공된 파일을 사용자에게 되돌려 주는 것을 제안하는 것이었습니다.
읽어주셔서 감사합니다! 개인 Medium 프로필에서 더 많은 글을 확인하세요:https://medium.com/@goranaviani 그리고 깃허브 페이지에서는 제가 만든 다른 재미있는 것들을 찾을 수 있습니다: https://github.com/GoranAviani