
By Jimmy Zhang
I once spent a couple of frustrating days at work learning how to properly deal with Unicode strings in Python. During those two days, I ate a lot of snacks — roughly one bag of goldfish per one of these errors encountered, which should be all too familiar to those who program with Python:
UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xf0 in position 0: ordinal not in range(128)
While solving my issue, I did a lot of googling, which pointed me to a few indispensable articles. But as great as they are, they were all written without the help of a crucial aspect of communication in today’s day and age.
That is: they were all written without the help of emoji.
So, in order to take advantage of this situation, I decided to write my own guide to understanding Unicode, with plenty of faces and icons rendered along the way ?✌?.
Before diving into technical details, let’s begin with a fun question. What is your favorite emoji?
Mine is the “face with open mouth”, which looks like this ?— with one major caveat. What you see is actually dependent on the platform you are using to read this post!
Viewed on my Mac, the emoji looks like a yellow bowling ball. On my Samsung tablet, the eyes are black and circular, accentuated by a white dot which betrays a greater depth of emotion.
Copy and paste the emoji (?) into Twitter, and you’ll see something completely different. Copy and paste it into messenger.com, however, and you’ll see why it is my favorite.
???? Why are they all different?



Note: As of July 9th, 2018: Messenger seems to have updated their emoji icons, so the icon at the top right no longer applies. ?
This fun little mystery is our segue into the world of Unicode, as emojis have been part of the Unicode Standard since 2010. Aside from giving us emoji, Unicode is important because it is the Internet’s preferred choice for the consistent “encoding, representation, and handling of text”.
Unicode & Encoding: A Brief Primer
As with many topics, the best way to understand Unicode is to know the context surrounding its creation — and for that, Joel Spolsky’s article is required reading.
Code Points
Since we’ve now entered the world of Unicode, we need to first dissociate emojis from the wonderfully expressive icons they are, and associate them with something much less exciting. So instead of thinking about emojis in terms of the things or the emotions that they represent, we will instead think about each emoji as a plain number. This number is known as a code point.
Code points are the key concept of Unicode, which was “designed to support the worldwide interchange, processing, and display of the written texts of the diverse languages…of the modern world.” It does so by associating virtually every printable character with an unique code point. Together, these characters comprise the Unicode character set.
Code points are typically written in hexadecimal and prefixed with U+ to denote the connection to Unicode, representing characters from:
- exotic languages such as Telugu [ఋ | code point: U+0C0B]
- chess symbols [♖ | code point: U+2656]
- and, of course, emojis [? | code point: U+1F64C]
Glyphs Are What You See
The actual on-screen representation of code points are called glyphs, (the complete mapping of code points to glyphs is known as a font).
As an example, take this letter A, which is code point U+0041 in Unicode. The “A” you see with your eyes is a glyph — it looks like the way it does because it is rendered with Medium’s font. If you were to change the font to, Times New Roman for example, only the glyph of “A” would change — the underlying code point would not.
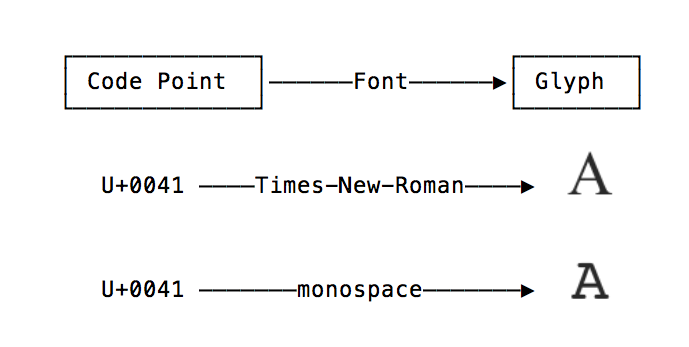
Glyphs are the answer to our little rendering mystery. Under the hood, all variations of the face with open mouth emoji point to the same code point, U+1F62E, but the glyph representing it varies by platform ?.
Code Points are Abstractions
Because they say nothing about how they are rendered visually (requiring a font and a glyph to “bring them to life”), code points are said to be an abstraction.
But just as code points are an abstraction to end users, they are also abstractions to computers. This is because code points require a character encoding to convert them into the one thing which computers can interpret: bytes. Once converted to bytes, code points can be saved to files or sent over the network to another computer ?➡️?.
UTF-8 is currently the world’s most popular character encoding. UTF-8 uses a set of rules to convert a code point into an unique sequence of (1 to 4) bytes, and vice versa. Code points are said to be encoded into a sequence of bytes, and sequences of bytes are decoded into code points. This Stack Overflow post explains how the UTF-8 encoding algorithm works.
However, even though UTF-8 is the predominant character encoding in the world, it is far from the only one. For example, UTF-16 is an alternative character encoding of the Unicode character set. The image below compares the UTF-8 and UTF-16 encodings of our emoji ?.
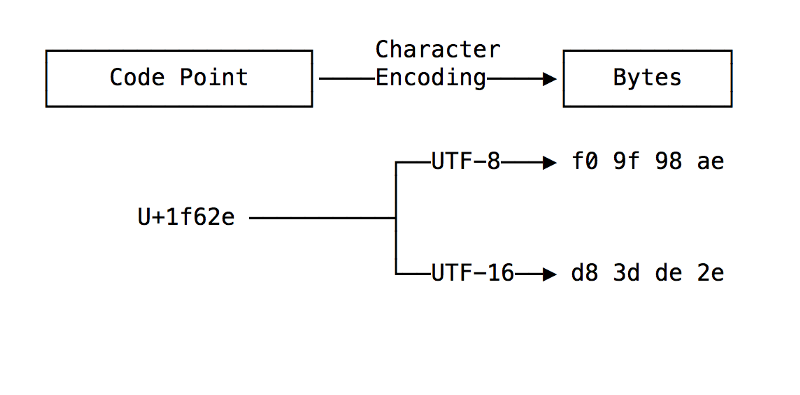
Problems arise when one computer encodes code points into bytes with one encoding, and another computer (or another process on the same computer) decodes those bytes with another.
Luckily, UTF-8 is ubiquitous enough that, for the most part, we don’t have to worry about mismatched character encodings. But when they do occur, a familiarity with the concepts mentioned above is required to extricate yourself from the mess.
Brief Recap
- Unicode is a collection of code points, which are plain numbers typically written in hexadecimal and prefixed with
U+. These code points map to virtually every printable character from the written languages around the world. - Glyphs are the physical manifestation of a character. This guy ? is a glyph. A font is a mapping of code points to glyphs.
- In order to send them across the network or save them in a file, characters and their underlying code points must be encoded into bytes. A character encoding contains the details of how a code point is embedded into a sequence of bytes.
- UTF-8 is currently the world’s must popular character encoding. Given a code point, UTF-8 encodes it into a sequence of bytes. Given a sequence of bytes, UTF-8 decodes it into a code point.
A Practical Example
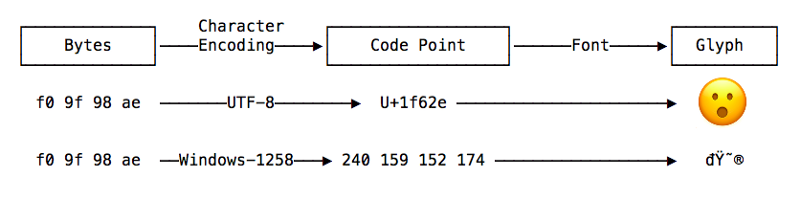
The correct rendering of Unicode characters involves traversing a chain, ranging from bytes to code points to glyphs.

Let’s now use a text editor to see a practical example of this chain — as well as the types of issues that can arise when things go awry. Text editors are perfect, because they involve all three parts of the rendering chain shown above.
Note: The following example was done on my MacOS using Sublime Text 3. And to give credit where credit is due: the beginning of this example is heavily inspired by this post from Philip Guo, which introduced me to the hexdump command (and a whole lot more).
We’ll start with a text file containing a single character — my favorite “face with open mouth” emoji. For those who want to follow along, I’ve hosted this file in a Github gist, which you get locally with curl.
curl https://gist.githubusercontent.com/jzhang621/d7d9eb167f25084420049cb47510c971/raw/e35f9669785d83db864f9d6b21faf03d9e51608d/emoji.txt > emoji.txt
As we learned, in order for it be saved to a file, the emoji was encoded into bytes using a character encoding. This particular file was encoded using UTF-8, and we can use the hexdump command to examine the actual byte contents of the file.
j|encoding: hexdump emoji.txt0000000 f0 9f 98 ae 0000004
The output of hexdump tells us the file contains 4 bytes total, each of which is written in hexadecimal. The actual byte sequence f0 9f 98 ae matches the expected UTF-8 encoded byte sequence, as shown below.
Now, let’s open our file in Sublime Text, where we should see our single ? character. Since we see the expected glyph, we can assume Sublime Text used the correct character encoding to decode those bytes into code points. Let’s confirm by opening up the console View -> Show Console, and inspecting th[e vi](https://www.sublimetext.com/docs/3/api_reference.html#sublime.View)ew object that Sublime Text exposes as part of its Python API.
>>> view<sublime.View object at 0x1112d7310>
# returns the encoding currently associated with the file>>> view.encoding()'UTF-8'
With a bit of Python knowledge, we can also find the Unicode code point associated with our emoji:
# Returns the character at the given position>>> view.substr(0)'?'
# ord returns an integer representing the Unicode code point of the character (docs)>>> ord(view.substr(0))128558
# convert code point to hexadecimal, and format with U+>>> print('U+%x' % ord(view.substr(0)))U+1f62e
Again, just as we expected. This illustrates a full traversal of the Unicode rendering chain, which involved:
- reading the file as a sequence of UTF-8 encoded bytes.
- decoding the bytes into a Unicode code point.
- rendering the glyph associated with the code point.

So far, so good ?.
Different Bytes, Same Emoji
Aside from being my favorite text editor, I chose Sublime Text for this example because it allows for easy experimentation with character encodings.
We can now save the file using a different character encoding. To do so, click File -> Save with Encoding -> UTF-16 BE. (Very briefly, UTF-16 is an alternative character encoding of the Unicode character set. Instead of encoding the most common characters using one byte, like UTF-8, UTF-16 encodes every point from 1–65536 using two bytes. Code points greater than 65536, like our emoji, are encoded using surrogate pairs. The BE stands for Big Endian).
When we use hexdump to inspect the file again, we see that byte contents have changed.
# (before: UTF-8)j|encoding: hexdump emoji.txt0000000 f0 9f 98 ae 0000004
# (after: UTF-16 BE)j|encoding: hexdump emoji.txt0000000 d8 3d de 2e0000004
Back in Sublime Text, we still see the same ? character staring at us. Saving the file with a different character encoding might have changed the actual contents of the file, but it also updated Sublime Text’s internal representation of how to interpret those bytes. We can confirm by firing up the console again.
>>> view.encoding()'UTF-16 BE'
From here on up, everything else is the same.
>>> view.substr(0)'?'
>>> ord(view.substr(0))128558
>>> print('U+%x' % ord(view.substr(0)))U+1f62e
The bytes may have changed, but the code point did not — and the emoji remains the same.
Same Bytes, But What The đŸ˜®
Time for some encoding “fun”. First, let’s re-encode our file using UTF-8, because it makes for a better example.
Let’s now go ahead use Sublime Text to re-open an existing file using a different character encoding. Under File -> Reopen with Encoding, click Vietnamese (Windows 1258), which turns our emoji character into the following four nonsensical characters: đŸ˜®.
When we click “Reopen with Encoding”, we aren’t changing the actual byte contents of the file, but rather, the way Sublime Text interprets those bytes. Hexdump confirms the bytes are the same:
j|encoding: hexdump emoji.txt0000000 f0 9f 98 ae0000004
To understand why we see these nonsensical characters, we need to consult the Windows-1258 code page, which is a mapping of bytes to a Vietnamese language character set. (Think of a code page as the table produced by a character encoding). As this code page contains a character set with less than 255 characters, each character’s code points can be expressed as a decimal number between 0 and 255, which in turn can all be encoded using 1 byte.
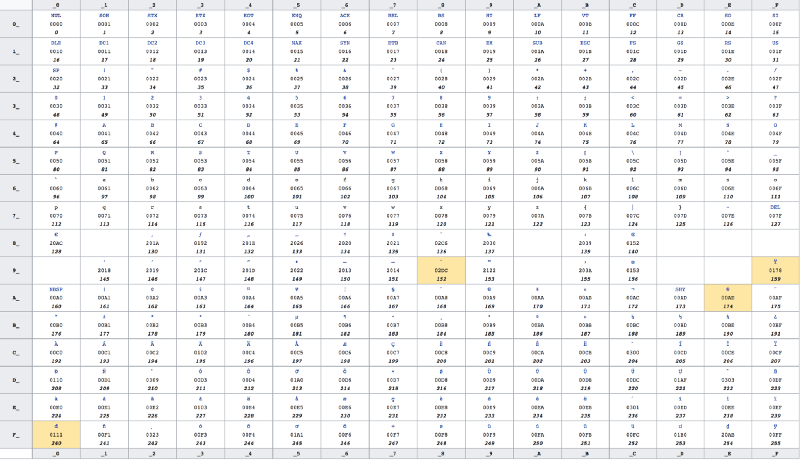
Because our single ? emoji requires 4 bytes to encode using UTF-8, we now see 4 characters when we interpret the file with the Windows-1258 encoding.
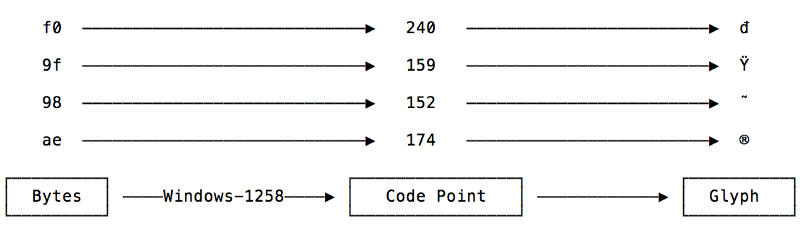
A wrong choice of character encoding has a direct impact on what we can see and comprehend by garbling characters into an incomprehensible mess.
Now, onto the “fun” part, which I include to add some color to Unicode and why it exists. Before Unicode, there were many different code pages such as Windows-1258 in existence, each with a different way of mapping 1 byte’s worth of data into 255 characters. Unicode was created in order to incorporate all the different characters of the all the different code pages into one system. In other words, Unicode is a superset of Windows-1258, and each character in the Windows-1258 code page has a Unicode counterpart.

In fact, these Unicode counterparts are what allows Sublime Text to convert between different character encodings with a click of a button. Internally, Sublime Text still represents each of our “Windows-1258 decoded” characters as a Unicode code point, as we see below when we fire up the console:
>>> view.encoding()'Vietnamese (Windows 1258)'
# Python 3 strings are "immutable sequences of Unicode code points">>> type(view.substr(0))<class 'str'>
>>> view.substr(0)'đ'>>> view.substr(1)'Ÿ'>>> view.substr(2)'˜'>>> view.substr(3)'®'
>>> ['U+%04x' % ord(view.substr(x)) for x in range(0, 4)]['U+0111', 'U+0178', 'U+02dc', 'U+00ae']
This means that we can re-save our 4 nonsensical characters using UTF-8. I’ll leave this one up to you — if you do so, and can correctly predict the resulting hexdump of the file, then you’ve successfully understood the key concepts behind Unicode, code points, and character encodings. (Use this UTF-8 code page. Answer can be found at the very end of this article. ).
Wrapping up
Working effectively with Unicode involves always knowing what level of the rendering chain you are operating on. It means always asking yourself: what do I have? Under the hood, glyphs are nothing but code points. If you are working with code points, know that those code points must be encoded into bytes with a character encoding. If you have a sequence of bytes representing text, know that those bytes are meaningless without knowing the character encoding that was used create those bytes.
As with any computer science topic, the best way to learn about Unicode is to experiment. Enter characters, play with character encodings, and make predictions that you verify using hexdump. While I hope this article explains everything you need to know about Unicode, I will be more than happy if it merely sets you up to run your own experiments.
Thanks for reading! ?
Answer:
j|encoding: $ hexdump emoji.txt0000000 c4 91 c5 b8 cb 9c c2 ae0000008